덜 자원된 언어에서 자동 요약 접근법 비교
📝 원문 정보
- Title: Comparing Approaches to Automatic Summarization in Less-Resourced Languages
- ArXiv ID: 2512.24410
- 발행일: 2025-12-30
- 저자: Chester Palen-Michel, Constantine Lignos
📝 초록 (Abstract)
자동 텍스트 요약은 영어와 같은 고자원 언어에서 높은 성능을 보였지만, 자원이 부족한 언어에 대한 연구는 상대적으로 적다. 본 연구는 대형·소형 LLM의 제로샷 프롬프트, 데이터 증강을 적용한 mT5 파인튜닝, 다국어 전이 학습, 그리고 “번역‑요약‑역번역” 파이프라인 등 다양한 접근법을 비교한다. 다섯 가지 평가 지표를 사용한 결과, 비슷한 파라미터 규모의 LLM들 간에도 성능 차이가 존재함을 확인했으며, 다국어 파인튜닝된 mT5 베이스라인이 대부분의 지표에서 제로샷 LLM을 능가한다는 점을 발견했다. 또한, LLM을 평가자로 사용할 경우, 자원이 부족한 언어에서는 신뢰도가 낮을 수 있음을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
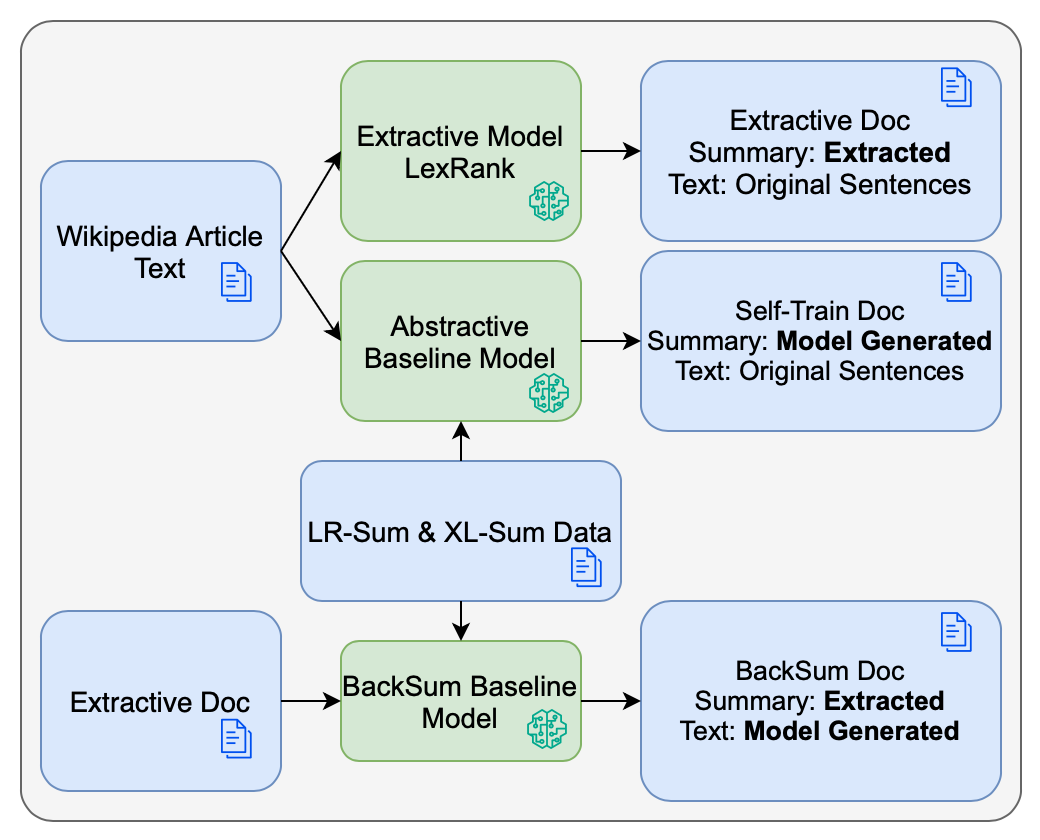
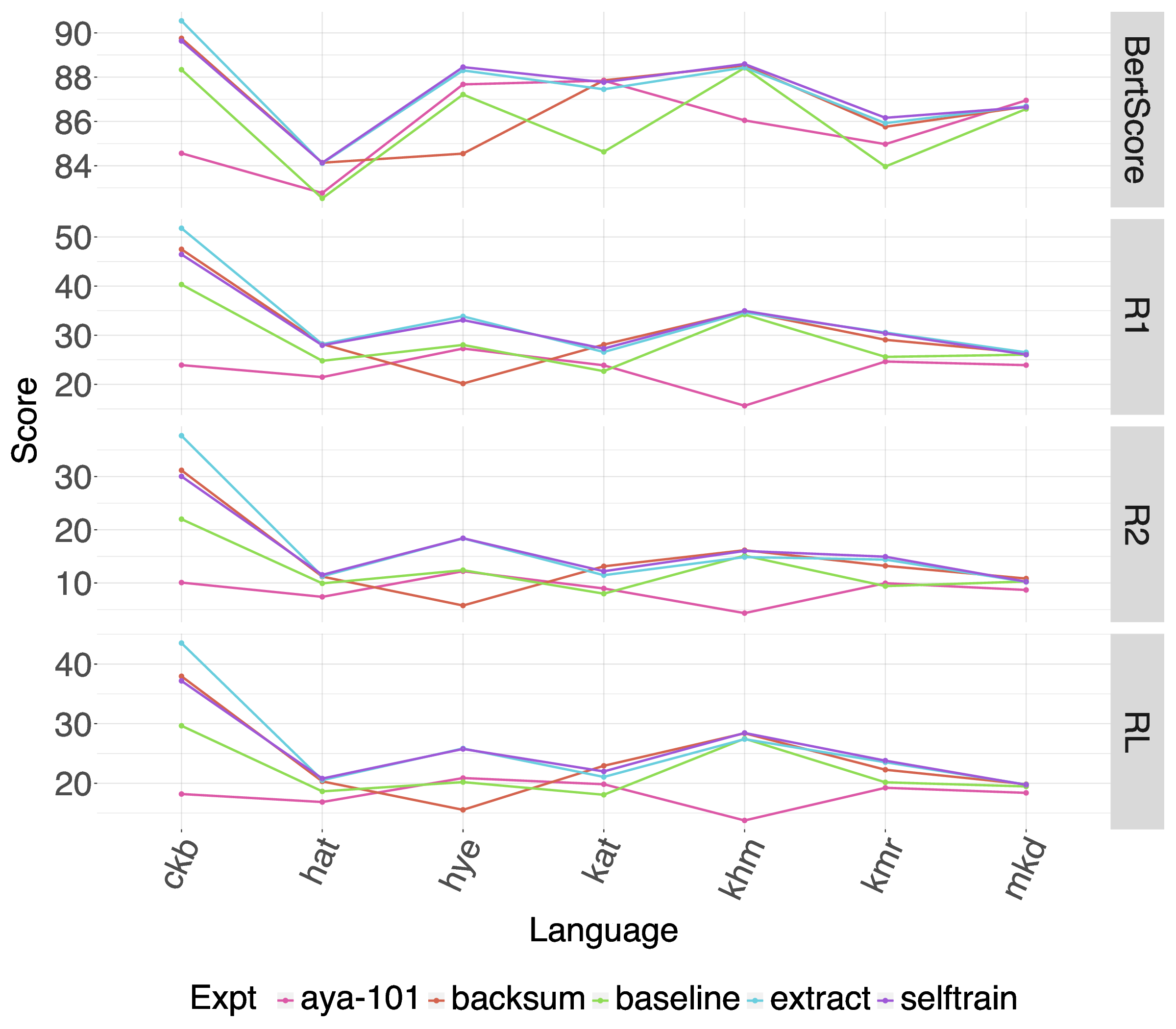
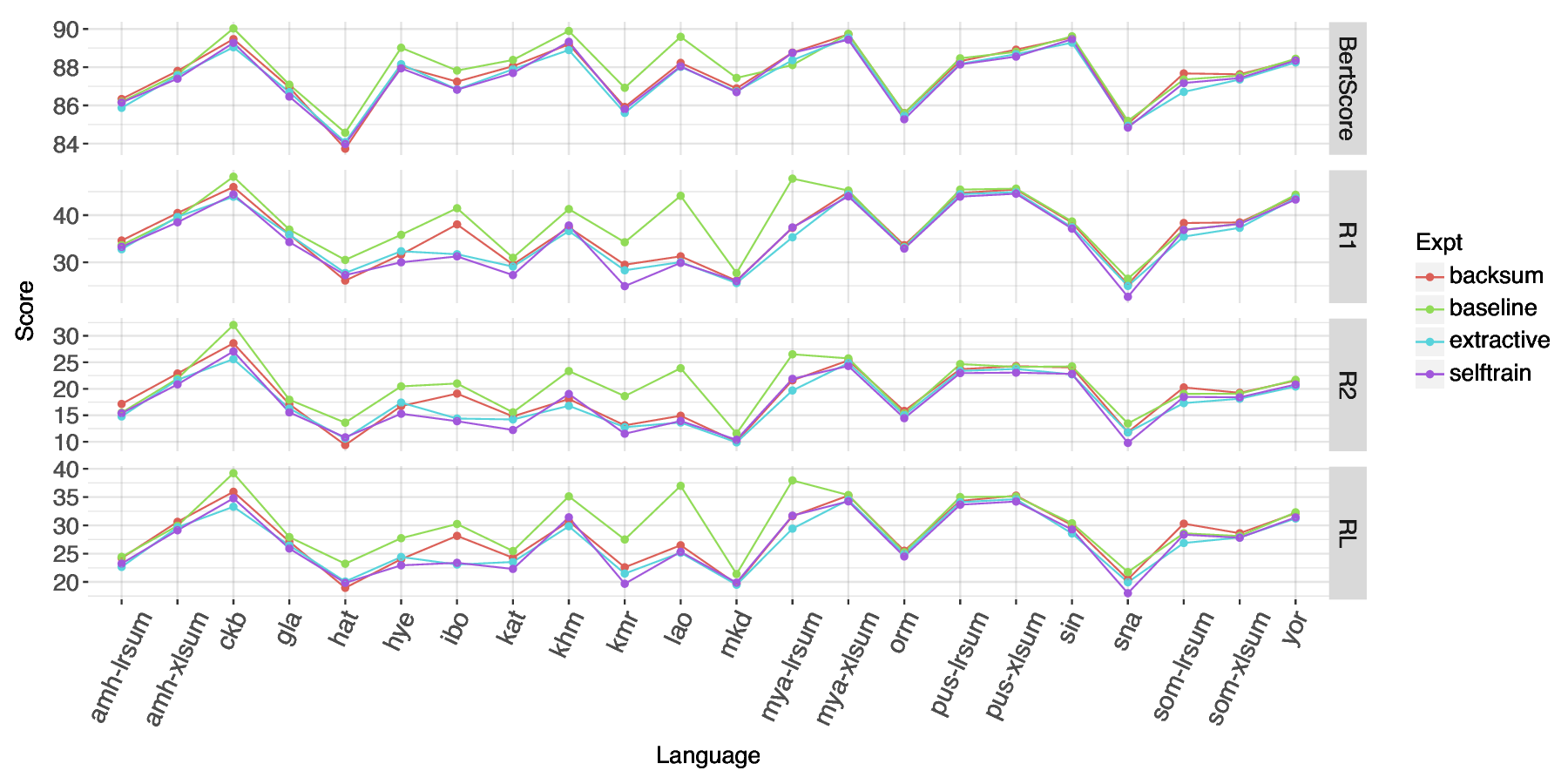
다음으로, 다국어 사전 학습 모델인 mT5를 소규모 데이터셋에 파인튜닝하는 접근법을 세 가지 데이터 증강 기법(역번역, 문장 삽입·삭제, 그리고 교차 언어 요약)과 결합하였다. 실험 결과, 증강된 데이터가 모델의 일반화 능력을 현저히 향상시켰으며, 특히 역번역 기반 증강이 가장 큰 성능 상승을 보였다. 이는 LRL에서 학습 데이터가 부족할 때, 인위적인 다양성을 부여하는 것이 모델에게 유용한 언어 패턴을 학습하게 만든다는 점을 뒷받침한다.
또한, 다국어 전이 학습을 활용해 고자원 언어(주로 영어)에서 학습된 요약 모델을 LRL에 직접 적용하거나, 소량의 LRL 데이터와 함께 미세조정하는 방식을 비교하였다. 전이 학습만으로는 제한적인 성능 향상에 그쳤지만, 고자원 언어와 LRL을 혼합 학습시킬 경우, 특히 문체와 도메인이 유사한 경우에 유의미한 개선이 관찰되었다.
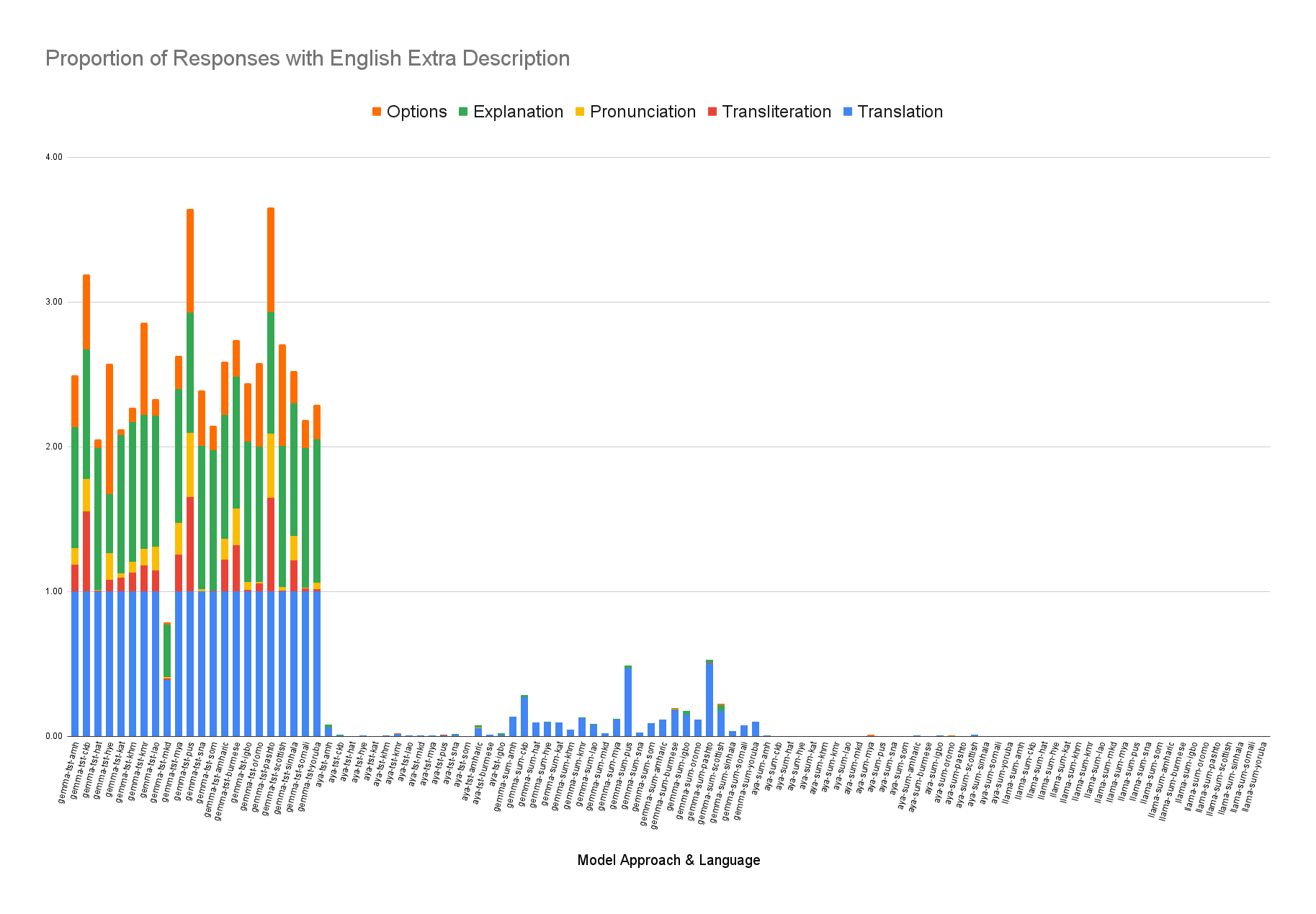
특이하게, “번역‑요약‑역번역” 파이프라인을 도입해 LRL 텍스트를 영어로 번역한 뒤, 영어 전용 요약 모델을 적용하고 다시 LRL로 번역하는 방식을 실험했다. 이 방법은 번역 품질에 크게 의존하며, 번역 단계에서 발생하는 의미 손실이 최종 요약 품질에 직접적인 악영향을 미치는 것으로 나타났다. 특히, 문화적·전문화된 용어가 포함된 문서에서는 번역 오류가 요약의 핵심 정보를 왜곡시키는 경우가 빈번했다.
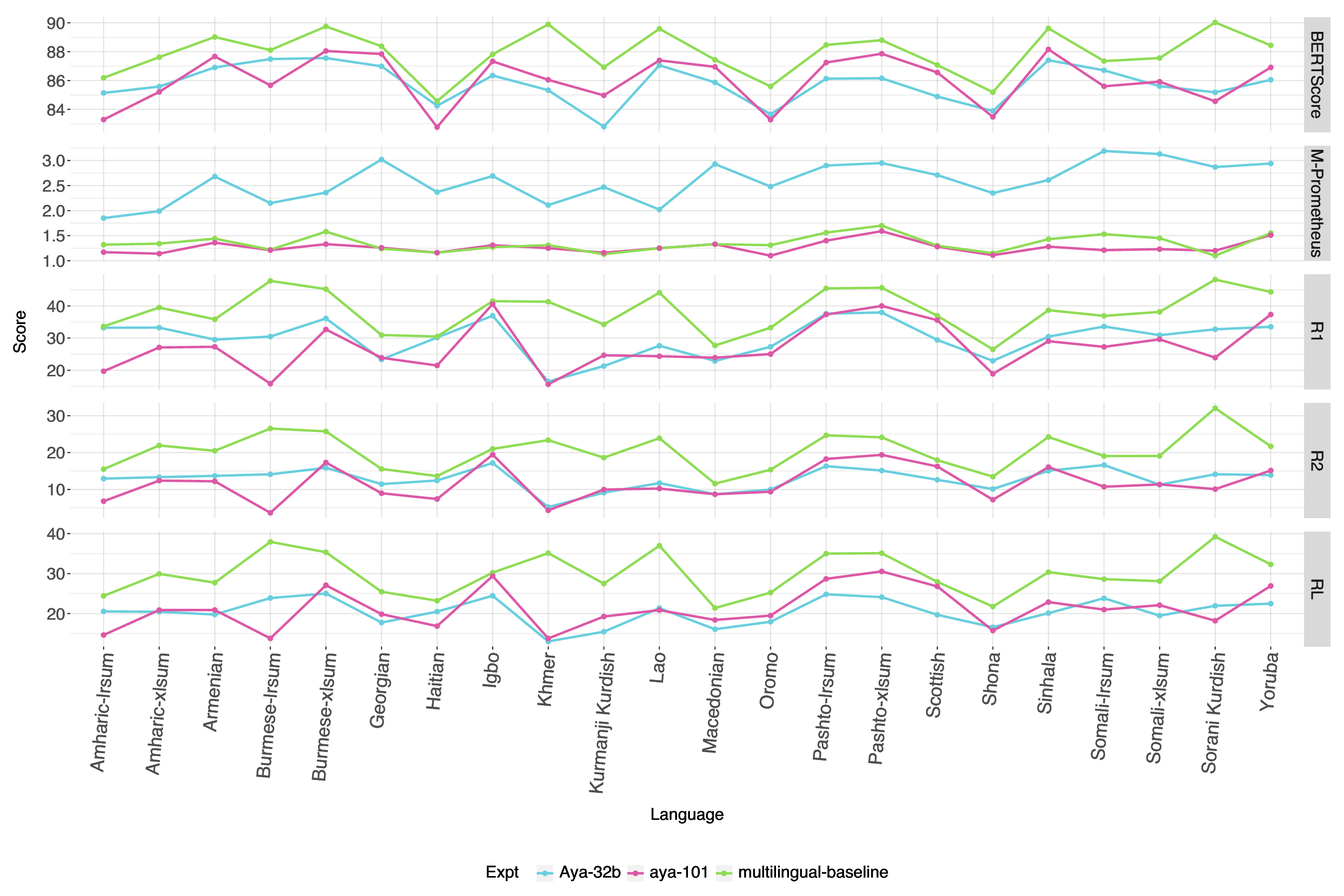
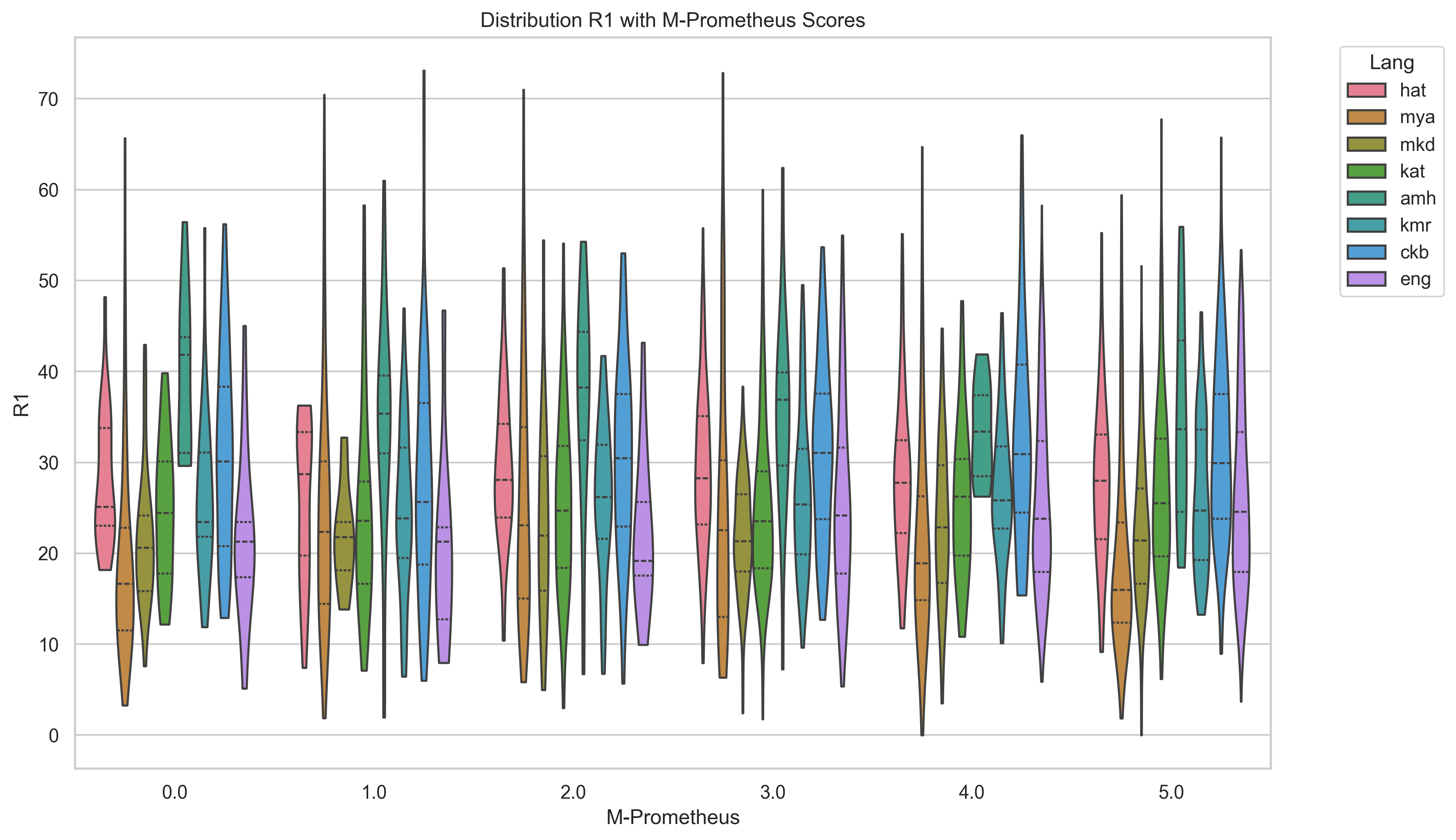
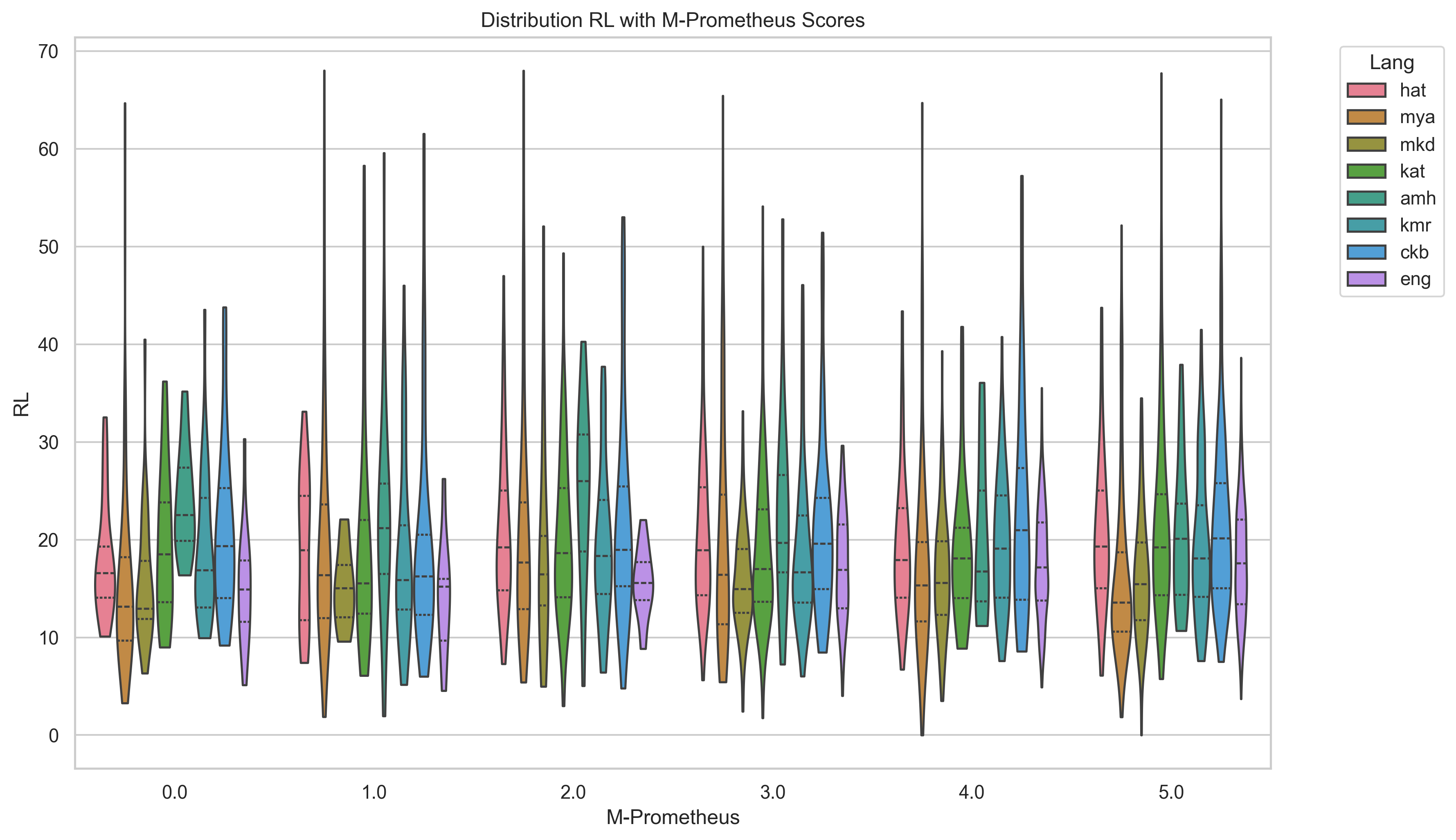
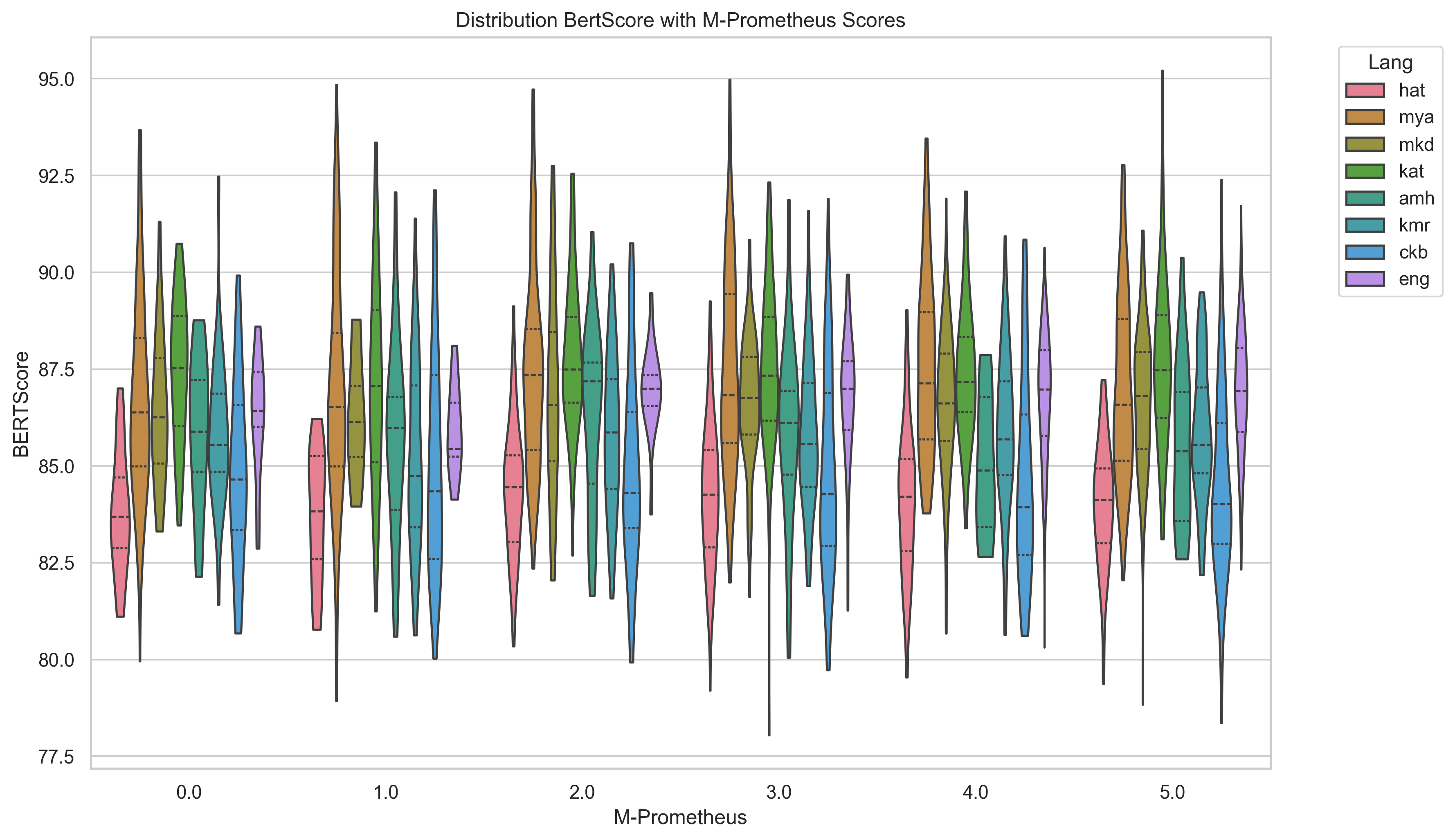
평가 측면에서는 ROUGE, BERTScore, METEOR, chrF, 그리고 LLM‑based 평가(LLaMA‑judge) 등 다섯 가지 지표를 사용했으며, LLM‑judge가 LRL에 대해 일관된 점수를 제공하지 못한다는 점을 발견했다. 이는 LLM‑judge 자체가 고자원 언어 데이터에 기반해 학습되었기 때문에, LRL의 어휘·문법 특성을 충분히 반영하지 못함을 의미한다. 따라서 LRL 요약 성능을 객관적으로 측정하려면 전통적인 n‑gram 기반 지표와 인간 평가를 병행하는 것이 필요하다.
종합하면, 본 연구는 LRL 요약에서 “작은 모델 + 데이터 증강 + 다국어 파인튜닝” 전략이 현재 가장 실용적인 접근법임을 입증한다. 대형 LLM의 제로샷 성능이 매력적이지만, 파라미터 규모와 무관하게 LRL 특화 데이터가 부족한 경우에는 기대 이하의 결과를 보인다. 향후 연구는 더 정교한 증강 기법, 언어‑특화 토크나이저 개발, 그리고 LRL에 특화된 평가 프레임워크 구축을 통해 성능 격차를 줄이는 방향으로 진행될 필요가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리