RSAgent 텍스트 기반 분할을 위한 다중 턴 도구 호출 기반 추론과 행동 학습
📝 원문 정보
- Title: RSAgent: Learning to Reason and Act for Text-Guided Segmentation via Multi-Turn Tool Invocations
- ArXiv ID: 2512.24023
- 발행일: 2025-12-30
- 저자: Xingqi He, Yujie Zhang, Shuyong Gao, Wenjie Li, Lingyi Hong, Mingxi Chen, Kaixun Jiang, Jiyuan Fu, Wenqiang Zhang
📝 초록 (Abstract)
텍스트 기반 객체 분할은 교차 모달 추론 능력과 픽셀 수준의 위치 지정 능력을 동시에 요구한다. 기존 대부분의 방법은 텍스트‑이미지 매칭을 한 번의 전방향 패스로 수행해 외부 세그멘터에 전달할 픽셀 프롬프트를 예측하는 일회성 접근법을 사용한다. 이러한 방식은 초기 위치 추정이 부정확할 경우 검증·재초점·정제 과정을 수행하기 어렵다는 한계가 있다. 이를 극복하기 위해 우리는 RSAgent라는 에이전시형 멀티모달 대형 언어 모델(MLLM)을 제안한다. RSAgent는 분할 툴박스를 반복적으로 호출하고, 시각적 피드백을 관찰하며, 과거 관찰을 활용해 공간 가설을 수정함으로써 목표를 재위치하고 마스크를 점진적으로 정제한다. 또한 다중 턴 추론·분할 궤적을 합성하는 데이터 파이프라인을 구축하고, 두 단계 학습 프레임워크(초기 감독 미세조정 → 세부 보상 기반 에이전시 강화학습)를 적용한다. 광범위한 실험 결과, RSAgent는 ReasonSeg 테스트에서 66.5 % gIoU의 제로샷 성능을 달성해 Seg‑Zero‑7B 대비 9 %p 향상했으며, RefCOCOg에서는 81.5 % cIoU를 기록해 인‑도메인·아웃‑도메인 벤치마크 모두에서 최첨단 성능을 보였다.💡 논문 핵심 해설 (Deep Analysis)
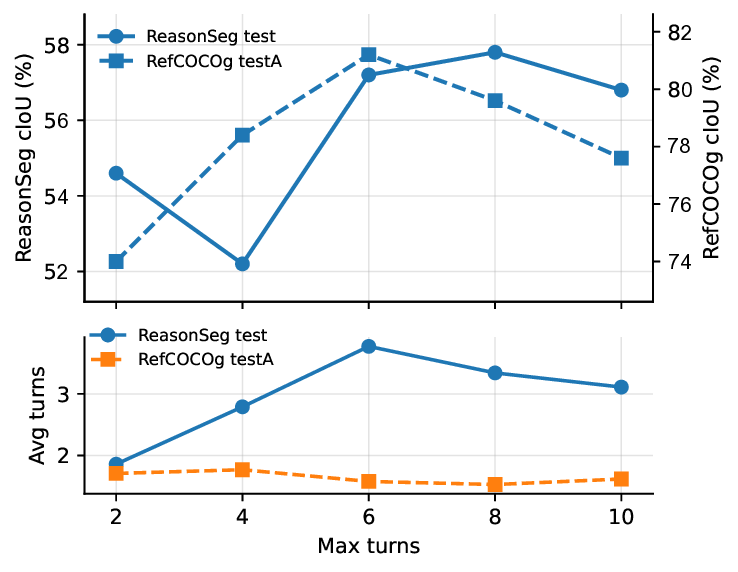
학습 측면에서는 두 단계 전략을 채택한다. 첫 번째 단계는 대규모 멀티모달 LLM을 기반으로 한 “콜드 스타트” 감독 학습으로, 합성된 다중 턴 데이터(텍스트‑이미지‑툴 호출‑피드백 시퀀스)를 이용해 기본 추론·행동 정책을 학습한다. 두 번째 단계는 에이전시 강화학습으로, 각 턴마다 얻은 마스크와 정답 마스크 간의 gIoU·cIoU 등 세분화된 보상을 설계한다. 이렇게 하면 모델은 “정확한 마스크를 얻는 것이 보상”이라는 명시적 목표를 학습하면서, 불필요한 호출을 최소화하고 효율적인 탐색 전략을 습득한다.
실험 결과는 두 가지 주요 벤치마크에서 눈에 띄는 향상을 보여준다. ReasonSeg은 텍스트‑이미지 기반 분할을 위한 새로운 테스트셋으로, RSAgent는 66.5 % gIoU를 기록해 기존 최첨단 모델인 Seg‑Zero‑7B(≈57.5 %)보다 9 %p 높은 성능을 달성했다. RefCOCOg는 기존 RefCOCO 시리즈의 확장판으로, 여기서 81.5 % cIoU를 얻어 인‑도메인(훈련 데이터와 유사)과 아웃‑도메인(새로운 텍스트·시각 조합) 모두에서 강인함을 입증했다. 이는 다중 턴 상호작용이 초기 오류를 자동으로 교정하고, 복잡한 언어‑시각 관계를 단계적으로 해석하는 데 효과적임을 시사한다.
하지만 몇 가지 제한점도 존재한다. 첫째, 툴 호출 비용이 누적될 경우 실시간 응용에 부정적인 영향을 미칠 수 있다. 현재 논문에서는 호출 횟수를 보상에 포함시켰지만, 실제 하드웨어 환경에서의 지연(latency)과 메모리 사용량을 정량화한 분석이 부족하다. 둘째, 합성된 다중 턴 데이터가 실제 인간 사용자와의 인터랙션을 완벽히 대체하지 못한다는 점이다. 인간은 종종 모호한 텍스트를 보완하기 위해 추가 질문을 하거나, 시각적 힌트를 제공하는데, 이러한 “자연스러운 대화”를 모델이 학습하도록 하는 추가 연구가 필요하다. 셋째, 현재는 외부 세그멘터가 고정된 형태(예: SAM)로 가정하고 있으나, 툴 자체가 가변적이거나 사용자 정의 가능한 경우 에이전시가 어떻게 적응할지에 대한 탐구가 부족하다.
향후 연구 방향으로는 (1) 호출 효율성을 극대화하기 위한 “조기 종료” 전략, (2) 인간‑모델 협업을 위한 인터페이스 설계, (3) 다양한 세그멘터와의 호환성을 확보하기 위한 메타‑툴 학습, (4) 멀티모달 강화학습에서 장기 보상 설계와 탐험‑활용 균형을 위한 새로운 알고리즘 개발 등을 제시할 수 있다. 전반적으로 RSAgent는 텍스트‑가이드드 분할에 에이전시적 사고와 행동을 도입함으로써, 기존 일회성 접근법의 한계를 뛰어넘는 새로운 패러다임을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리