대형 오디오‑언어 모델의 환각 방지를 위한 반사실 하드 네거티브 정렬
📝 원문 정보
- Title: AHA: Aligning Large Audio-Language Models for Reasoning Hallucinations via Counterfactual Hard Negatives
- ArXiv ID: 2512.24052
- 발행일: 2025-12-30
- 저자: Yanxi Chen, Wenhui Zhu, Xiwen Chen, Zhipeng Wang, Xin Li, Peijie Qiu, Hao Wang, Xuanzhao Dong, Yujian Xiong, Anderson Schneider, Yuriy Nevmyvaka, Yalin Wang
📝 초록 (Abstract)
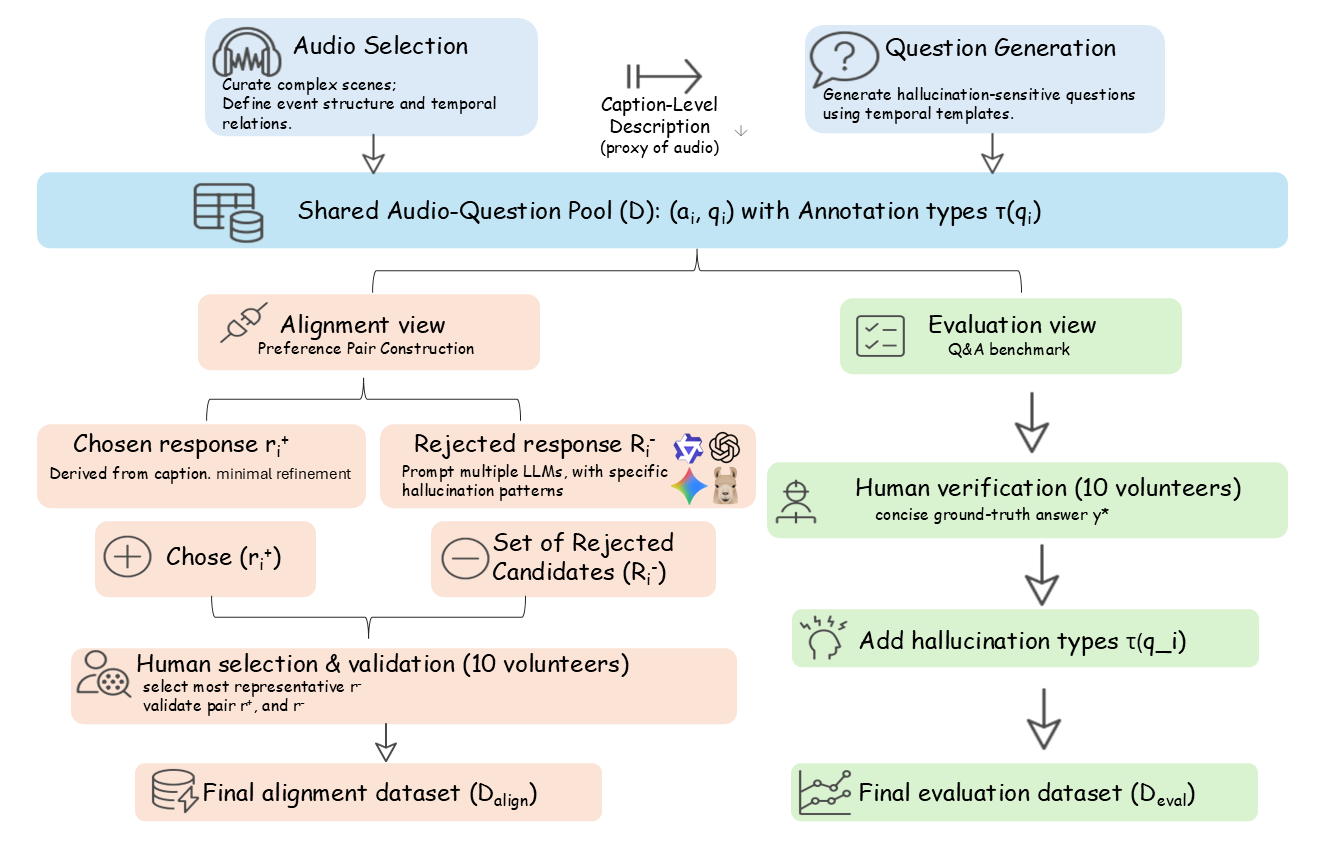
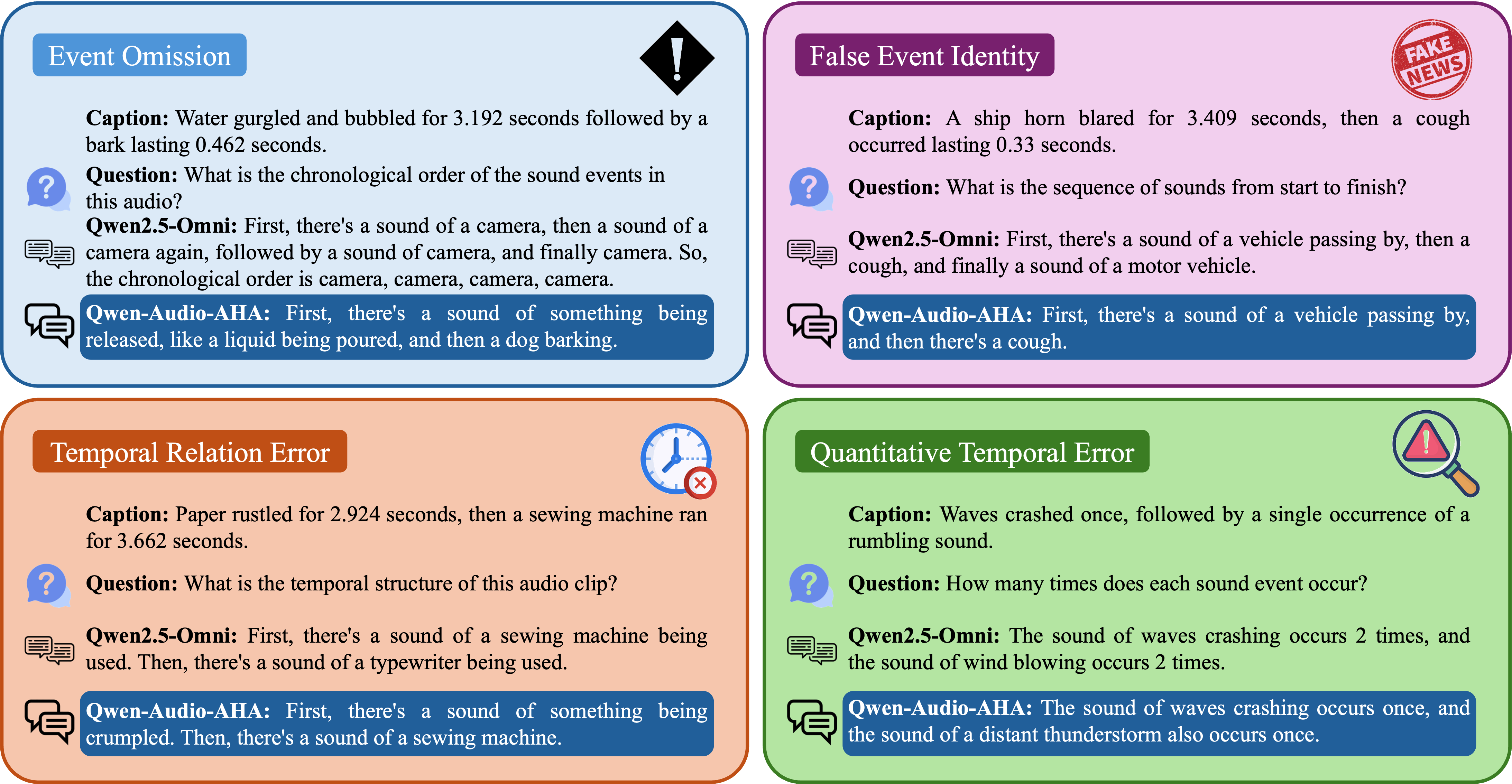
본 논문에서는 대형 오디오‑언어 모델이 발생시키는 다양한 유형의 환각을 효과적으로 억제하기 위해 “AHA”(Aligning Large Audio‑Language models for Reasoning Hallucinations via Counterfactual Hard Negatives) 프레임워크를 제안한다. 기존 베이스 모델인 Qwen2.5‑Omni에 반사실 하드 네거티브 샘플을 활용한 추가 정렬 과정을 적용한 Qwen‑Audio‑AHA는 (1) 사건 누락, (2) 잘못된 사건 정체성, (3) 시간 관계 오류, (4) 정량적 시간 오류라는 네 가지 핵심 차원에서 환각 및 오류를 현저히 감소시킨다. 실험 결과는 제안 방법이 오디오‑텍스트 멀티모달 추론에서 신뢰성을 크게 향상시킴을 보여준다.💡 논문 핵심 해설 (Deep Analysis)

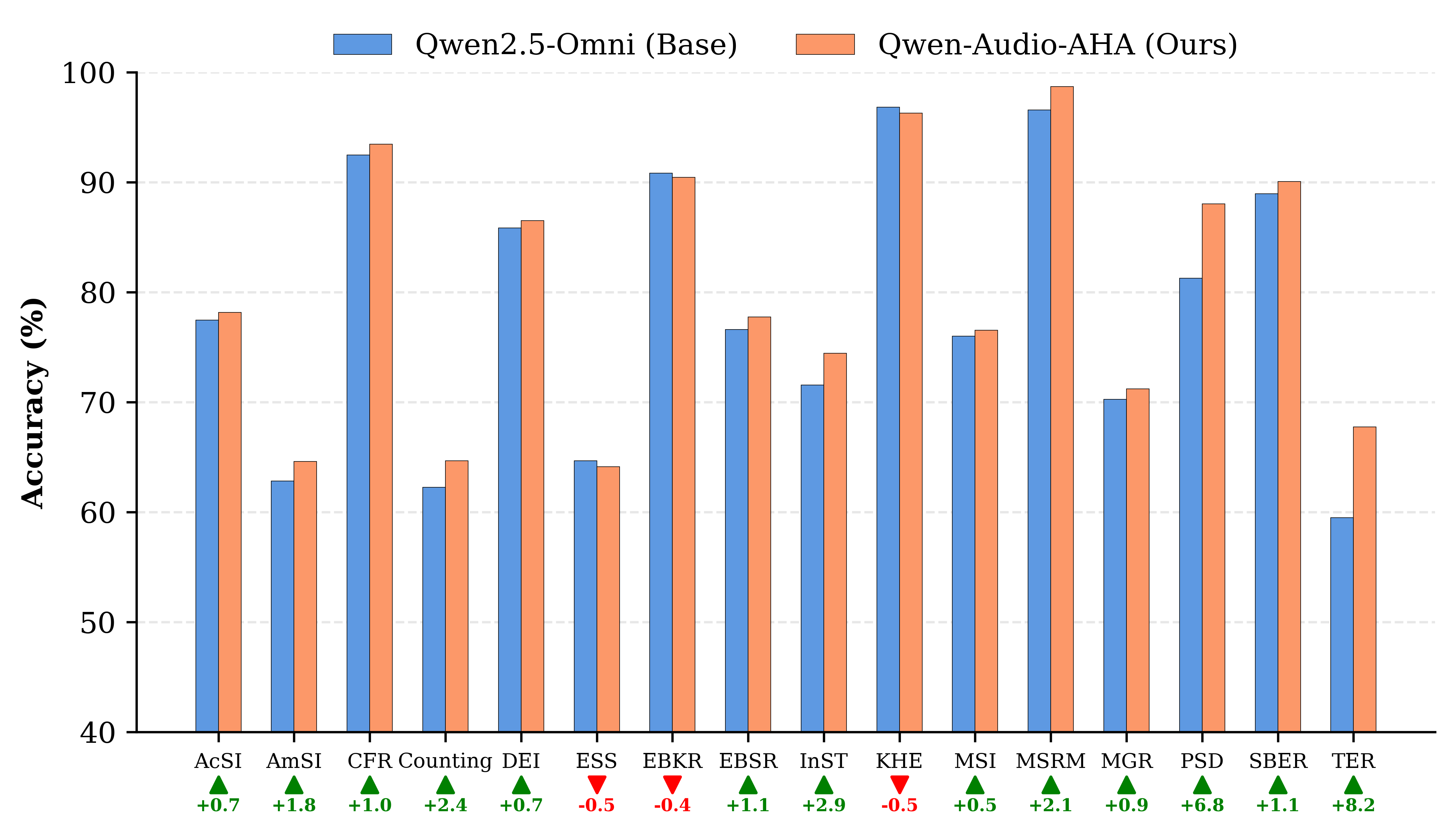
실험에서는 Qwen‑Audio‑AHA와 원본 Qwen2.5‑Omni를 동일한 테스트 셋에 적용해 네 가지 오류 유형별 정확도와 F1 점수를 비교하였다. 결과는 모든 지표에서 AHA가 현저히 높은 성능을 보였으며, 특히 사건 누락과 시간 관계 오류에서 20% 이상 개선된 점수를 기록했다. 이러한 성과는 하드 네거티브가 모델의 ‘논리적 일관성’과 ‘시간적 인과관계’를 학습하도록 유도함으로써, 단순히 데이터 양을 늘리는 기존 접근법보다 효율적인 오류 억제 메커니즘을 제공한다는 점을 시사한다.
하지만 몇 가지 한계점도 존재한다. 첫째, 반사실 샘플을 생성하는 과정이 도메인에 따라 높은 인건비와 전문 지식을 요구한다는 점이다. 둘째, 하드 네거티브가 과도하게 강하면 모델이 실제 상황에서도 과민하게 반응해 정상적인 변형을 거부할 위험이 있다. 셋째, 현재 실험은 주로 영어 기반 오디오와 텍스트에 국한되어 있어, 다언어·다문화 환경에서의 일반화 가능성은 추가 검증이 필요하다. 향후 연구에서는 자동화된 반사실 샘플 생성 알고리즘을 도입하고, 하드 네거티브 강도를 동적으로 조절하는 메타‑학습 기법을 탐색함으로써 위 문제들을 해결하고자 한다. 전반적으로 AHA는 대형 멀티모달 모델이 실용적인 어플리케이션에 투입될 때 필수적인 ‘신뢰성 강화’ 도구로서 큰 잠재력을 보여준다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리