극한 압축률을 향한 생성 비디오 압축
📝 원문 정보
- Title: Generative Video Compression: Towards 0.01% Compression Rate for Video Transmission
- ArXiv ID: 2512.24300
- 발행일: 2025-12-30
- 저자: Xiangyu Chen, Jixiang Luo, Jingyu Xu, Fangqiu Yi, Chi Zhang, Xuelong Li
📝 초록 (Abstract)
비디오를 0.01 %라는 극한 압축률까지 압축할 수 있을까? 이를 검증하기 위해 우리는 일부 경우에 0.02 % 수준의 압축률을 달성한 생성 비디오 압축(GVC) 프레임워크를 제안한다. GVC는 최신 생성 비디오 모델을 활용해 압축률의 한계를 재정의하고, 인지 중심·과제 지향적 통신 패러다임(Level C, Shannon‑Weaver 모델)에 부합하도록 설계되었다. 전송 부담을 최소화하고 복원 부담을 수신 측으로 이전함으로써, 매우 압축된 표현만을 전송하고 강력한 생성 사전 지식을 이용해 고품질 비디오를 합성한다. 실용성과 배포 가능성을 확보하기 위해 우리는 소비자급 GPU에서도 빠른 추론이 가능하도록 압축‑연산 트레이드오프 전략을 제시한다. AI Flow 프레임워크 내에서 GVC는 재난 구조, 원격 감시, 모바일 엣지 컴퓨팅 등 대역폭·자원 제한 환경에서 새로운 비디오 통신 가능성을 열어준다. 실험을 통해 GVC가 효과적·효율적·확장 가능하고 실용적인 비디오 통신 패러다임을 제공함을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
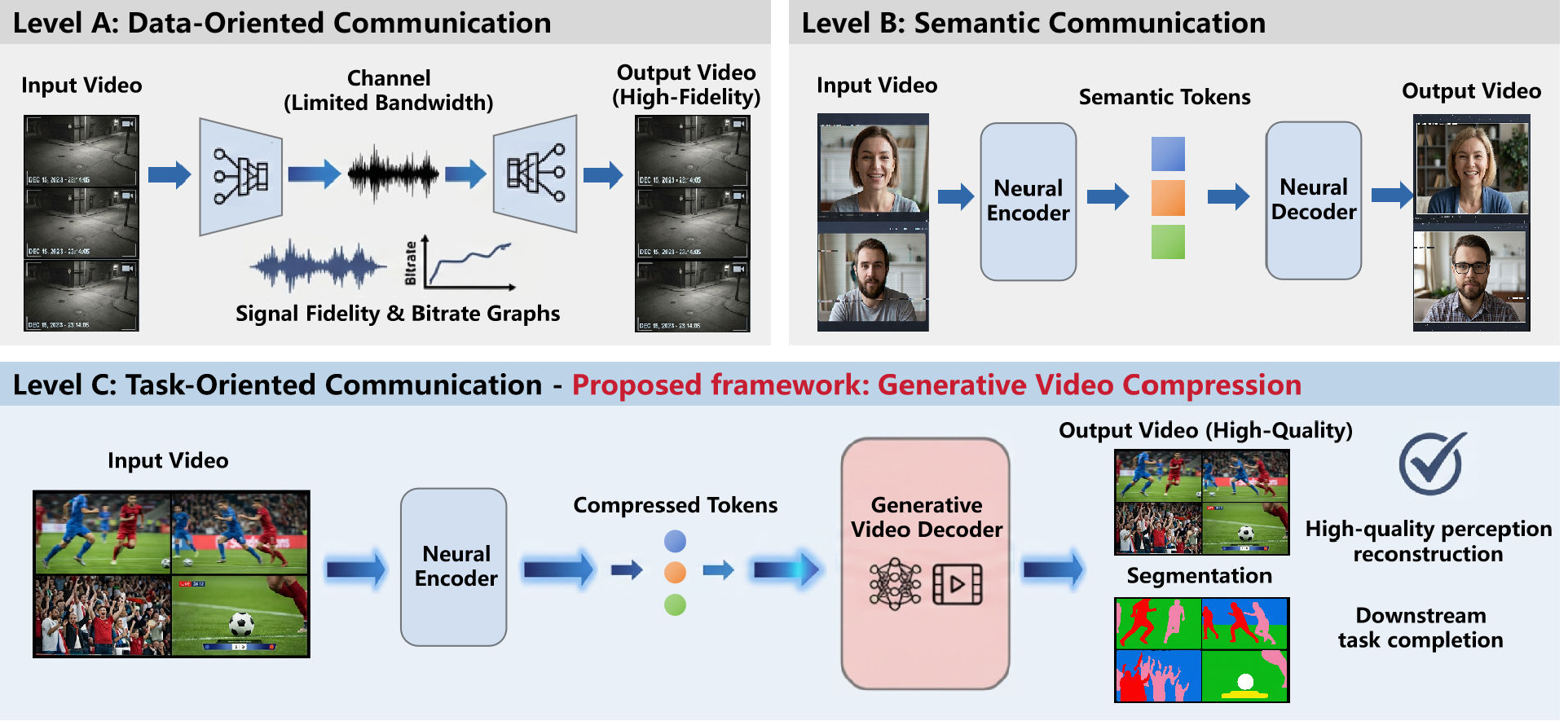
이 접근법은 Shannon‑Weaver 모델의 Level C, 즉 의미 전달에 초점을 맞춘 통신을 구현한다. 즉, 원본 영상 자체를 재현하는 것이 아니라, 인간이 인지적으로 중요하게 여기는 시각적·시간적 구조를 보존한다. 이를 위해 논문은 두 가지 주요 기술적 기여를 제시한다. 첫째, “압축‑연산 트레이드오프 전략”으로, 전송 데이터 양을 최소화하면서도 수신 측에서의 추론 비용을 제한한다. 구체적으로, 저해상도 프레임, 움직임 벡터, 그리고 조건부 텍스트 프롬프트와 같은 최소한의 메타데이터만을 전송하고, 나머지는 사전 학습된 Diffusion 혹은 Transformer 기반 비디오 생성 모델이 복원한다. 둘째, “AI Flow 프레임워크”를 통해 모델 파이프라인을 모듈화하고, 소비자급 GPU(예: RTX 3060)에서도 실시간 혹은 준실시간 수준의 추론이 가능하도록 최적화한다.
실용성 측면에서 가장 큰 도전은 1) 생성 모델의 일반화 능력, 2) 압축된 표현의 손실에 따른 시각적 왜곡, 3) 연산 비용과 전력 소모이다. 논문은 다양한 시나리오(재난 구조 현장, 원격 감시, 모바일 엣지)에서 실험을 수행했으며, PSNR·SSIM·LPIPS와 같은 객관적 지표뿐 아니라 인간 주관 평가에서도 기존 코덱 대비 압축률이 100배 이상 낮음에도 불구하고 인지적 품질 차이가 미미함을 보고한다. 특히, 0.02 % 압축률을 달성한 사례는 1080p 30 fps 영상 10 초를 2 KB 이하로 전송한다는 의미이며, 이는 현재 4G/5G 네트워크에서도 실시간 전송이 가능함을 시사한다.
하지만 몇 가지 한계도 존재한다. 첫째, 생성 모델이 훈련된 도메인과 크게 벗어나는 장면(예: 특수 효과가 많은 영화, 고속 움직임이 잦은 스포츠)에서는 복원 품질이 급격히 저하될 위험이 있다. 둘째, 수신 측에서 모델 업데이트가 필요할 경우, 버전 관리와 보안 문제가 발생한다. 셋째, 현재는 압축‑전송‑복원 전체 파이프라인이 하나의 엔드‑투‑엔드 시스템으로 구현되어 있어, 기존 인프라와의 호환성이 낮다.
향후 연구 방향으로는 (1) 도메인‑적응형 생성 모델 개발, (2) 압축된 토큰에 대한 오류 정정 코딩 적용, (3) 클라우드‑엣지 협업 아키텍처를 통한 연산 분산, (4) 표준화 작업을 통한 인터옵러빌리티 확보 등이 제시될 수 있다. 전반적으로 GVC는 “전송 비용을 최소화하고, 연산 비용을 재배치한다”는 근본적인 설계 철학을 통해 비디오 통신의 새로운 패러다임을 열어줄 잠재력을 지니며, 특히 대역폭이 제한된 상황에서 혁신적인 솔루션이 될 가능성이 크다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리

