스킴 인식 대비 학습을 통한 효율적인 문서 표현
📝 원문 정보
- Title: Skim-Aware Contrastive Learning for Efficient Document Representation
- ArXiv ID: 2512.24373
- 발행일: 2025-12-30
- 저자: Waheed Ahmed Abro, Zied Bouraoui
📝 초록 (Abstract)
Transformer 기반 모델이 단어·문장 수준 과제에서 뛰어난 성능을 보이지만, 법률·의료와 같이 길이가 긴 문서를 효과적으로 표현하는 데는 한계가 있다. Sparse attention 메커니즘은 긴 입력을 처리할 수 있으나 연산 비용이 크고 전체 문맥을 충분히 포착하지 못한다. 계층적 Transformer는 효율성을 개선하지만, 문서의 서로 다른 섹션 간 관계를 명확히 설명하지 못한다. 인간은 텍스트를 스킴(요약) 방식으로 훑어 중요한 부분에 집중해 전체 의미를 파악한다. 이러한 인간의 전략을 모방하여, 우리는 섹션을 무작위로 마스킹하고, 자연어 추론(NLI) 기반 대비 학습 목표를 사용해 마스크된 섹션을 관련된 부분과 정렬하고 무관한 부분과는 거리두기 하는 자체 지도식 대비 학습 프레임워크를 제안한다. 이 방법은 인간이 정보를 종합하는 방식을 모방함으로써, 표현이 풍부하면서도 계산 효율이 높은 문서 임베딩을 만든다. 법률 및 생물의학 텍스트에 대한 실험 결과, 정확도와 효율성 모두에서 유의미한 향상을 확인하였다.💡 논문 핵심 해설 (Deep Analysis)
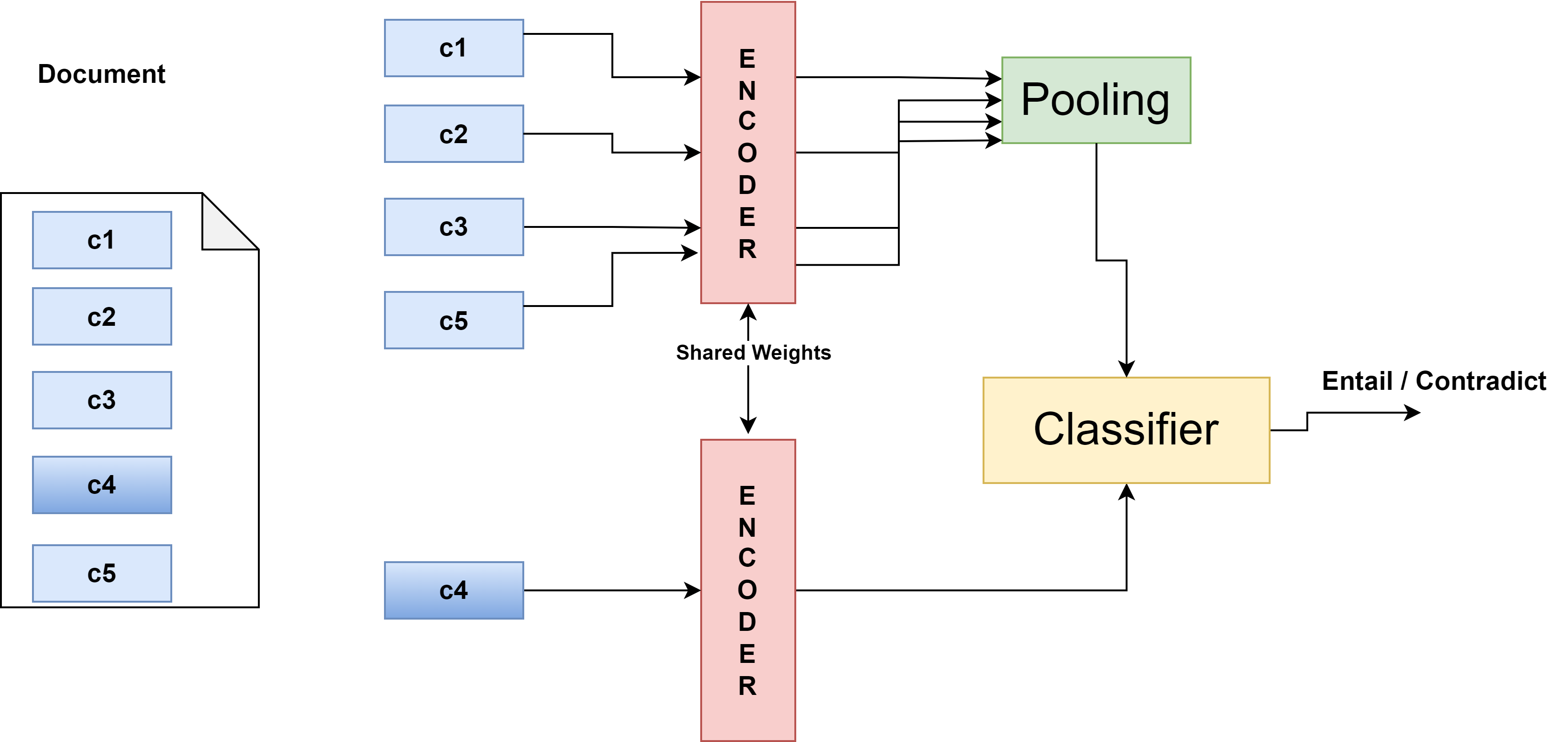
이에 저자들은 인간이 텍스트를 읽을 때 핵심 문장을 선택하고, 선택된 부분을 중심으로 전체 의미를 재구성한다는 인지적 메커니즘을 차용한다. 구체적으로, 문서를 일정 길이의 섹션(예: 문단) 단위로 분할하고, 무작위로 하나의 섹션을 마스크한다. 마스크된 섹션은 텍스트 자체에서 완전히 제거되는 것이 아니라, 토큰 레벨에서
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리
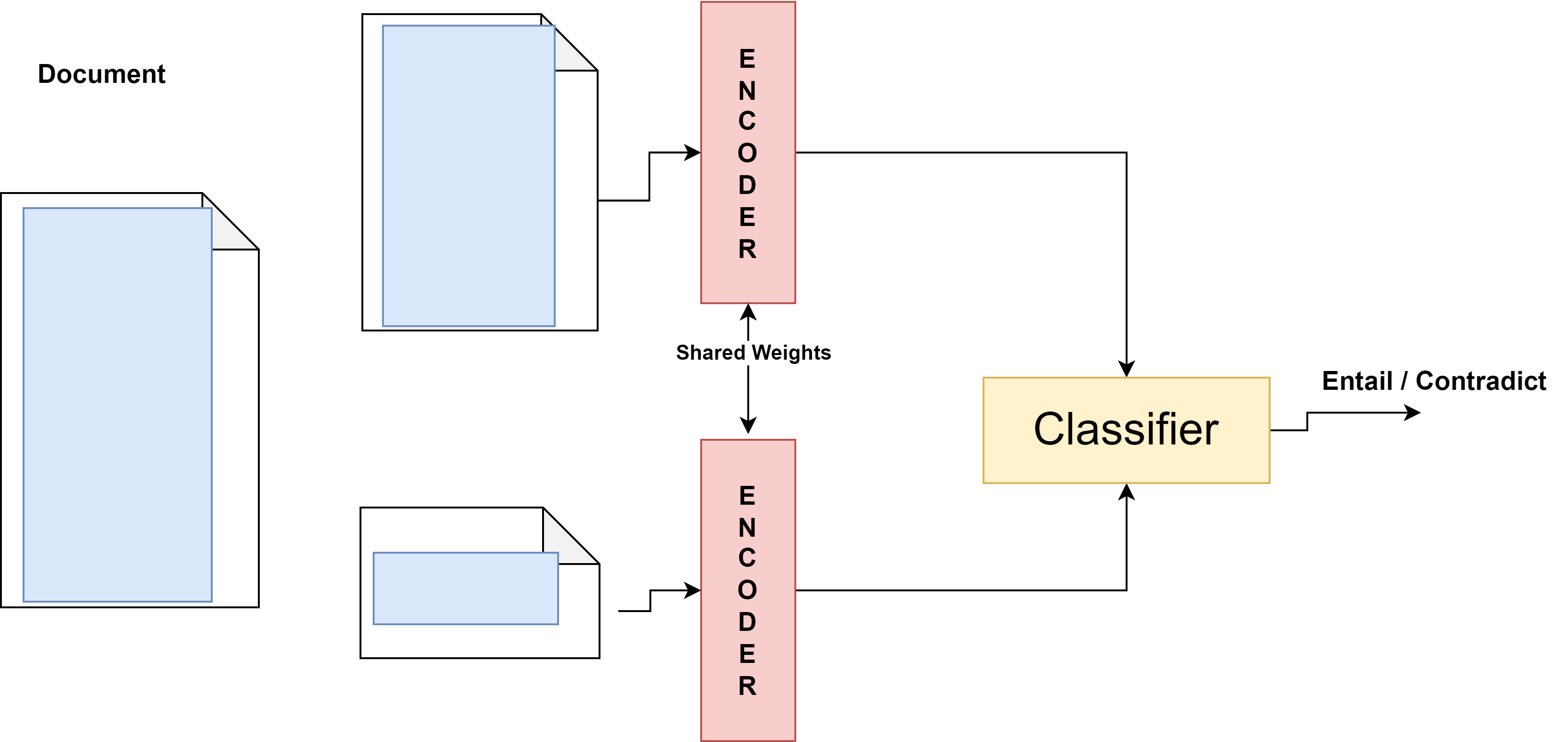
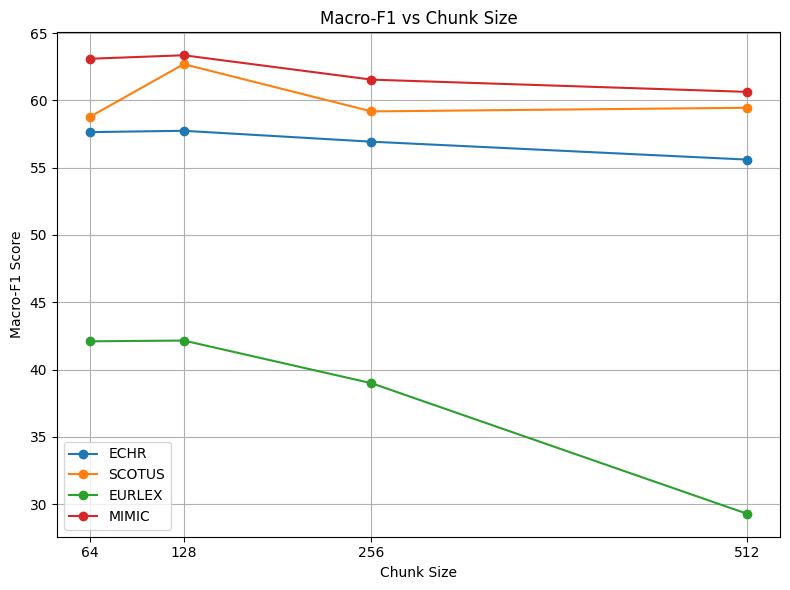
Reference
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.