소규모 학습으로 데이터 정제 방향을 정확히 잡을 수 있을까
📝 원문 정보
- Title: Can Small Training Runs Reliably Guide Data Curation? Rethinking Proxy-Model Practice
- ArXiv ID: 2512.24503
- 발행일: 2025-12-30
- 저자: Jiachen T. Wang, Tong Wu, Kaifeng Lyu, James Zou, Dawn Song, Ruoxi Jia, Prateek Mittal
📝 초록 (Abstract)
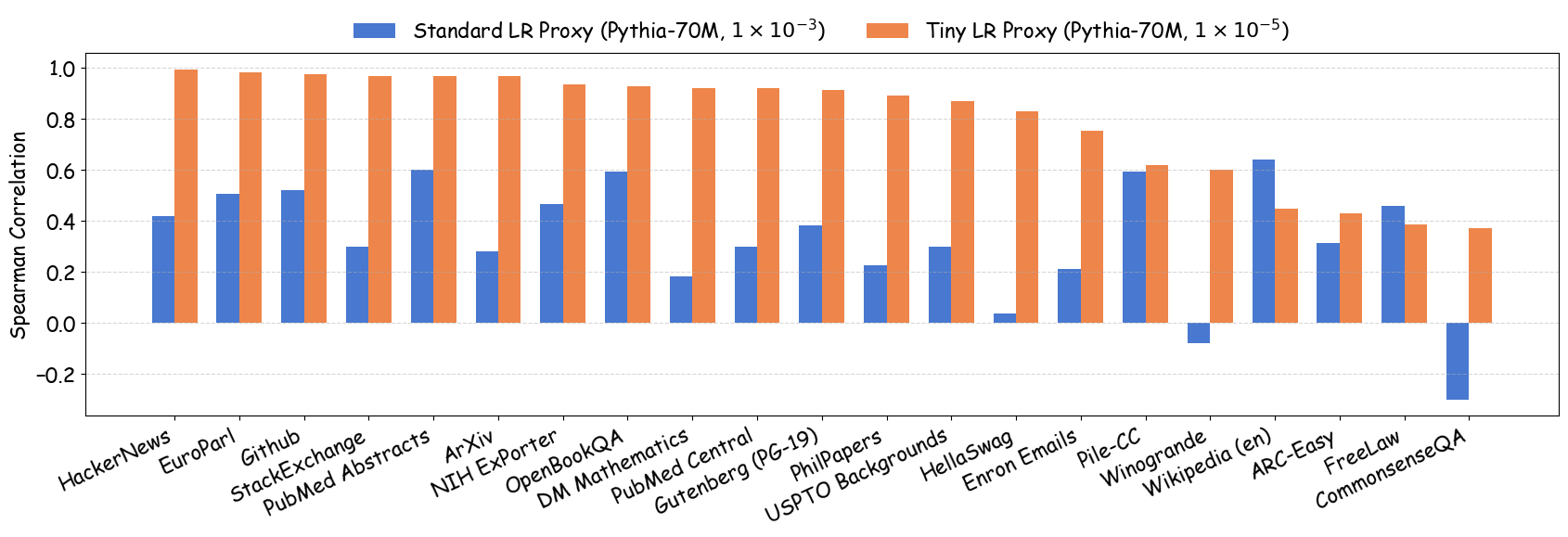
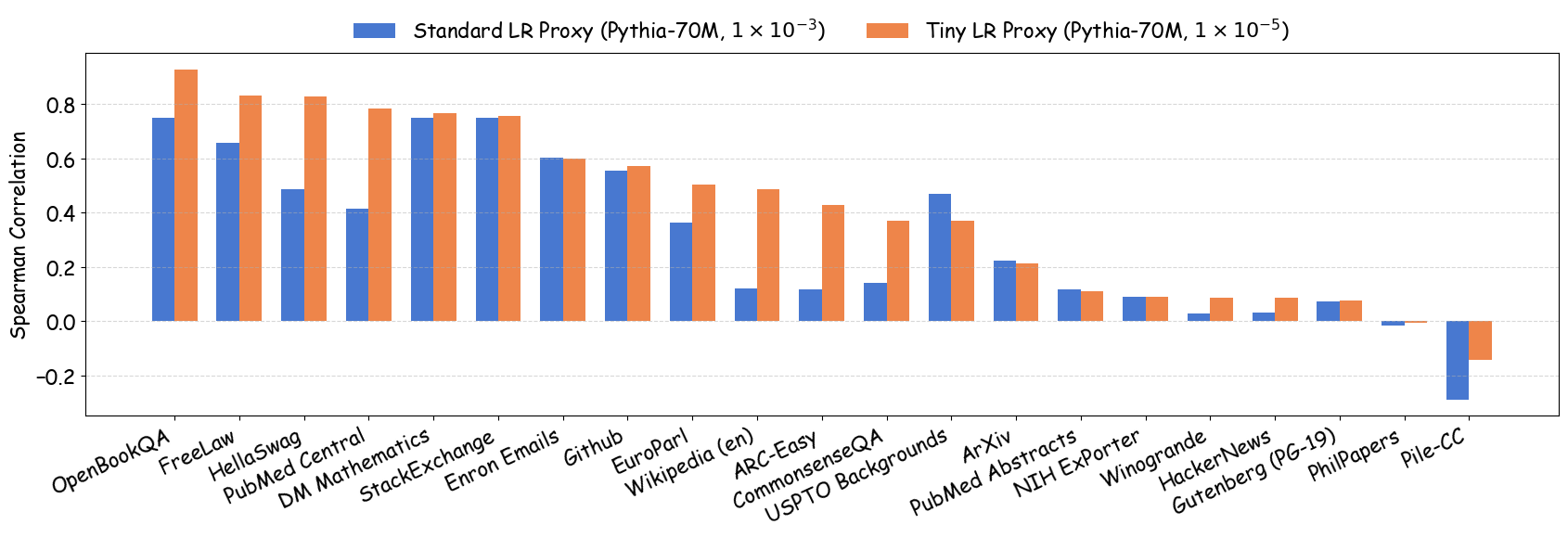
최신 AI 기업의 데이터 팀은 대규모 학습을 위한 데이터 레시피를 결정하기 위해 작은 프록시 모델을 자주 훈련한다. 그러나 작은 규모 실험 결과가 전체 규모 모델에 그대로 적용될 수 있는지에 대한 이해는 아직 부족하다. 본 연구는 데이터 레시피 평가에 흔히 사용되는 “모든 레시피에 동일한 소규모 학습 설정을 적용한다”는 표준 프로토콜에 숨겨진 문제점을 밝혀낸다. 최적의 학습 설정은 데이터에 따라 달라야 함에도 불구하고, 고정된 설정을 사용하면 하이퍼파라미터가 약간만 바뀌어도 데이터 품질에 대한 결론이 뒤바뀔 수 있다. 이는 전체 규모 모델 개발 파이프라인에서 하이퍼파라미터 최적화가 필수적인 점과도 일치한다. 따라서 데이터 레시피 평가는 “데이터별 최적 튜닝 하에 가장 좋은 성능을 내는 레시피”를 찾는 것이 목표가 되어야 한다. 하이퍼파라미터 탐색 비용을 낮추기 위해, 우리는 프록시 모델 훈련 시 학습률을 낮추는 간단한 패치를 제안한다. 이 방법은 대규모 LLM 사전학습에서 완전 튜닝된 결과와 강한 상관관계를 보인다. 이론적으로는 랜덤 피처 모델에 대해 최적 손실을 달성할 수 있는 데이터 순서를 보존함을 증명했으며, 실험적으로는 데이터 품질의 네 가지 핵심 차원을 아우르는 23개의 레시피에 대해 신뢰성을 크게 향상시켰다.💡 논문 핵심 해설 (Deep Analysis)
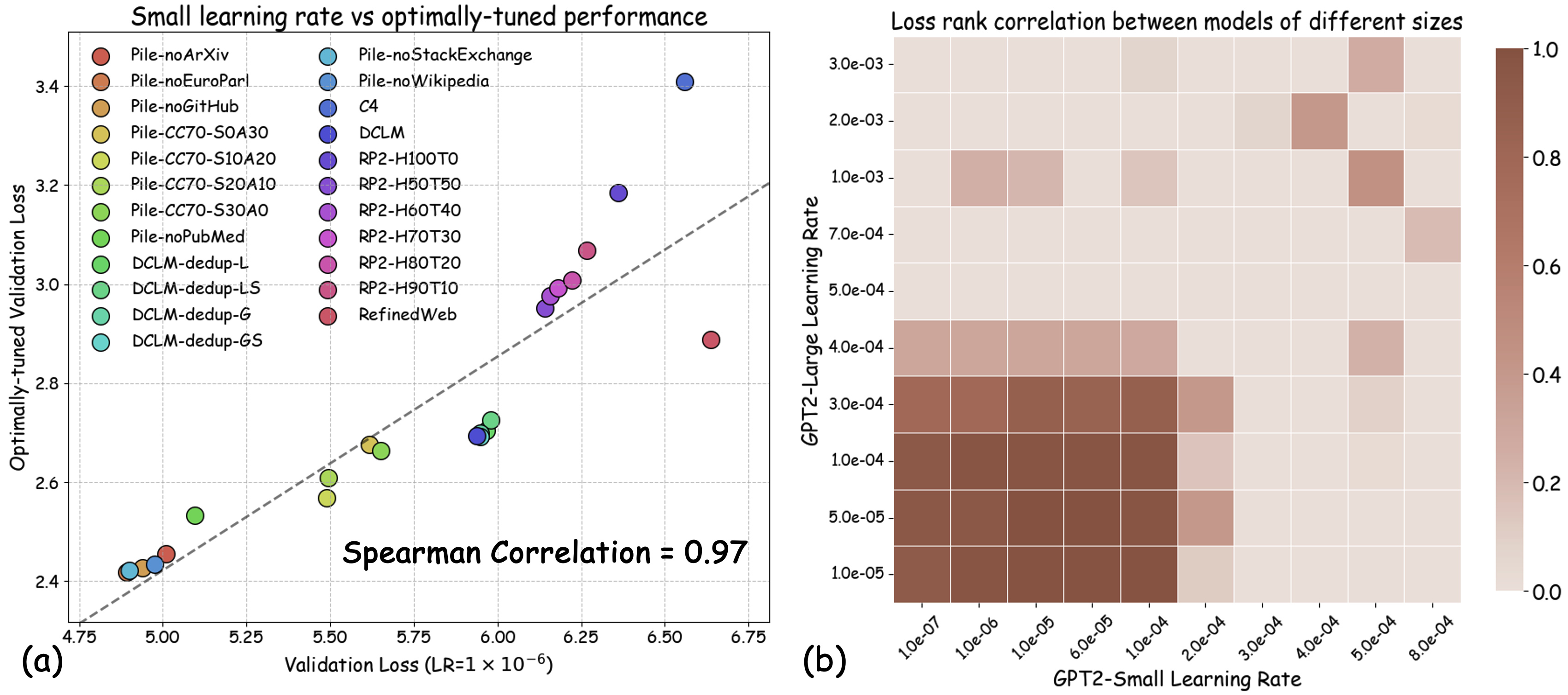
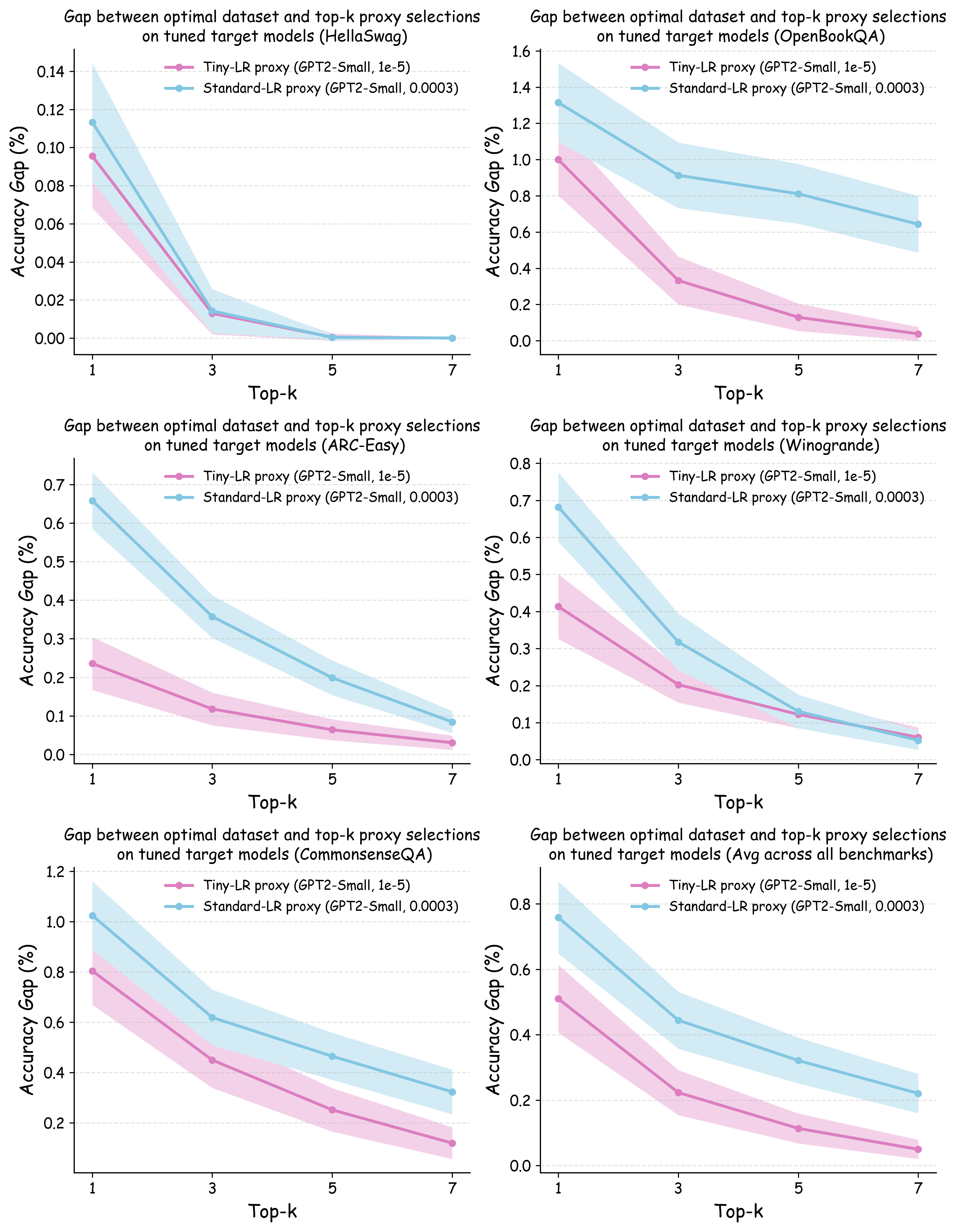
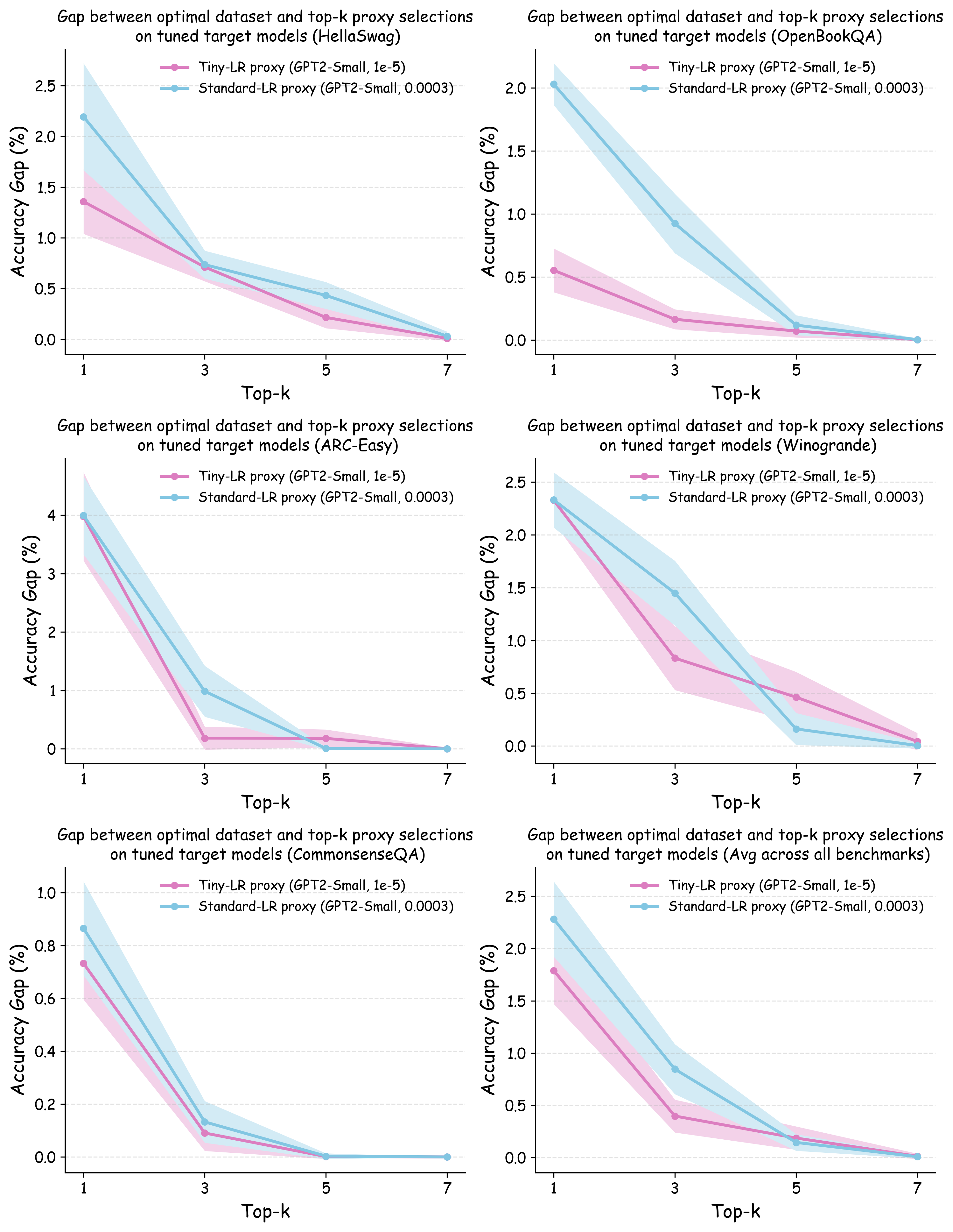
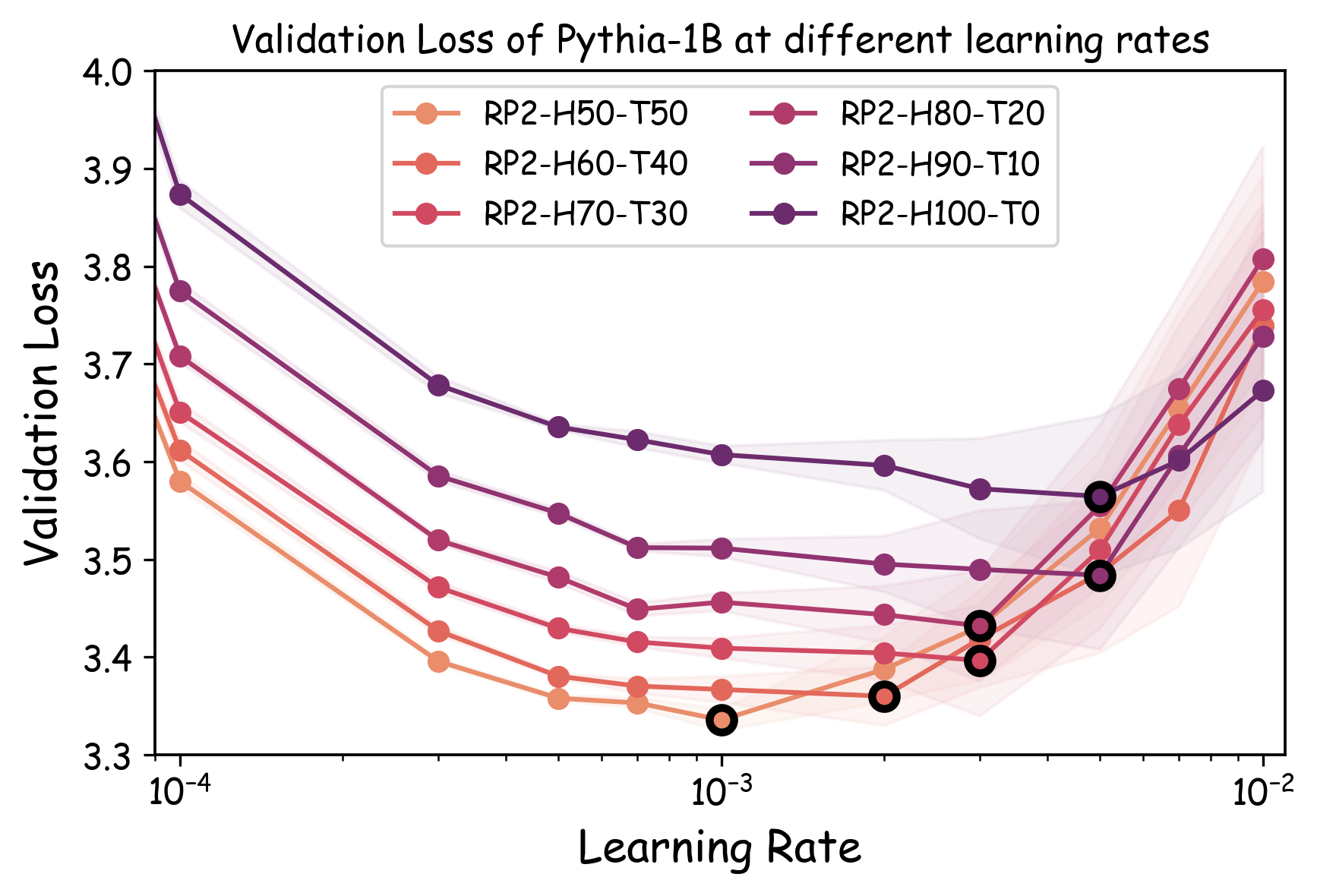
또한, 실제 대규모 모델 개발 파이프라인에서는 각 데이터셋에 맞는 하이퍼파라미터 튜닝이 필수적인 단계이다. 따라서 프록시 실험이 “실제와 동일한 조건”을 재현하려면, 데이터별 최적화된 설정을 찾아야 한다는 논리적 귀결이 나온다. 하지만 전통적인 그리드 서치나 베이지안 최적화는 비용이 많이 들기 때문에, 저자는 학습률을 낮추는 간단한 “패치”를 제안한다. 학습률을 감소시키면 모델이 더 오래 수렴하고, 데이터마다 최적에 가까운 손실 지점을 탐색하게 된다.
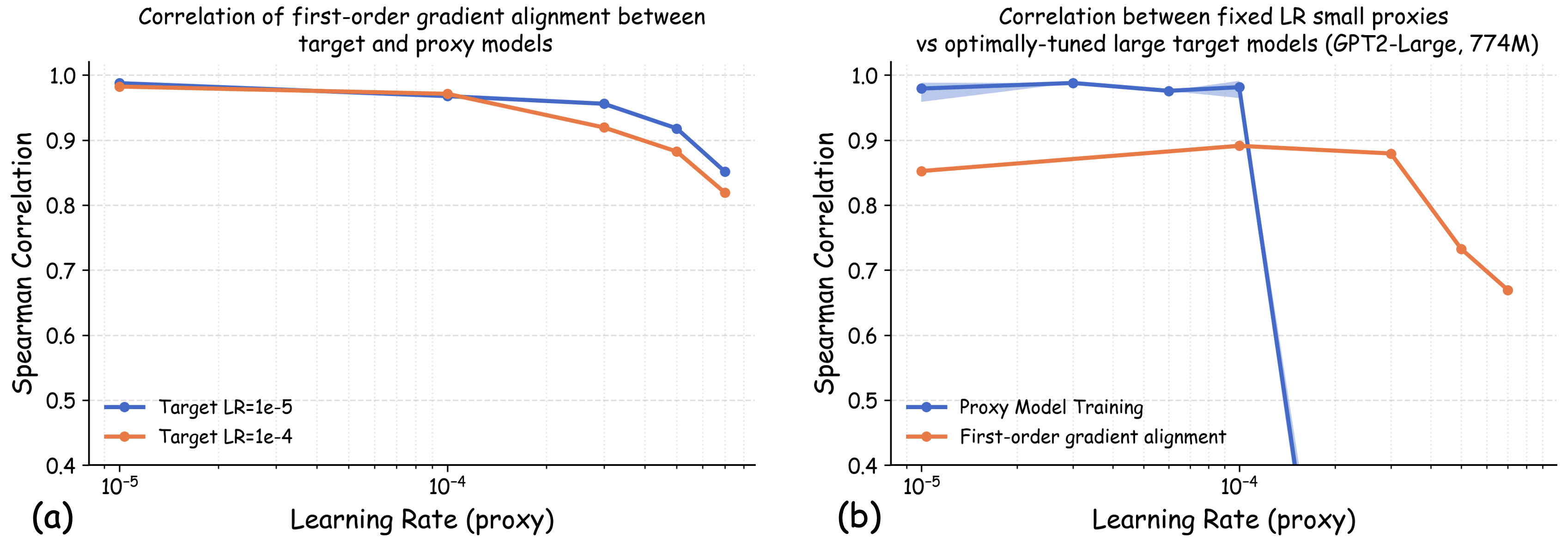
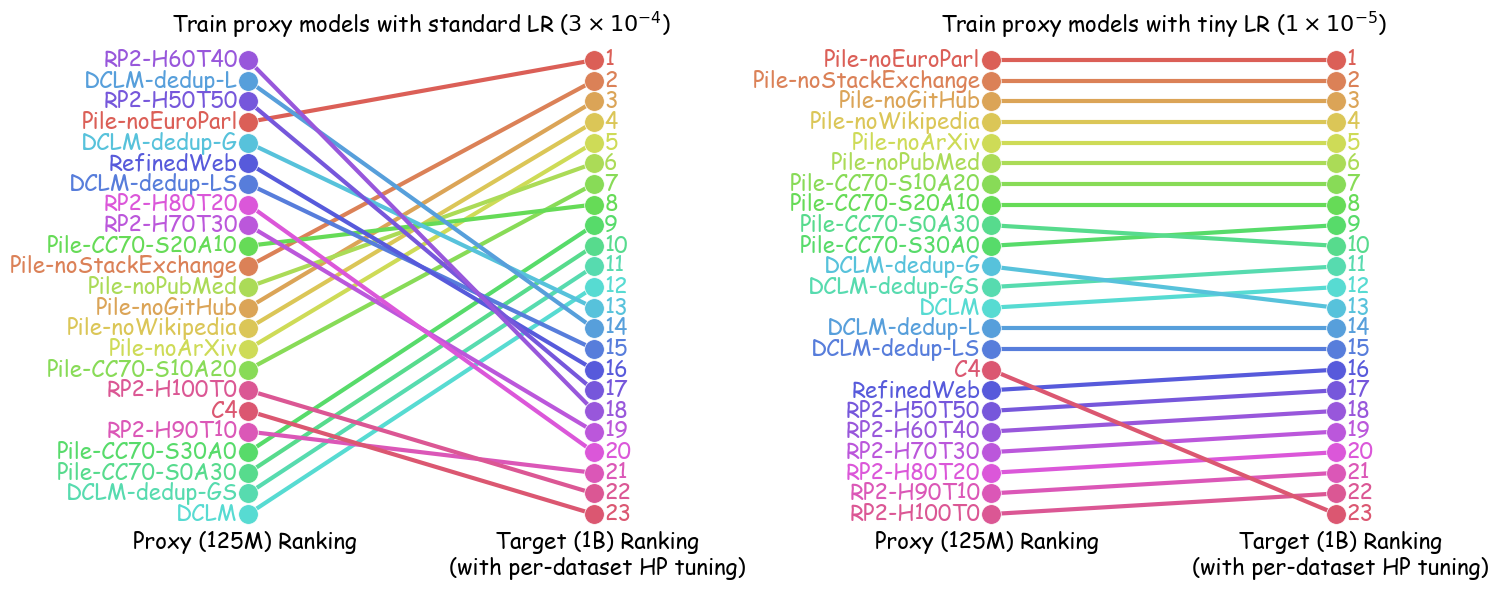
이론적 측면에서 저자는 랜덤 피처 모델을 이용해, 학습률 감소가 데이터 순서를 보존한다는 정리를 증명한다. 즉, 어떤 데이터 레시피가 최적 손실이 낮은지를 판단하는 순서는 학습률을 낮춘 프록시 모델에서도 변하지 않는다. 이는 복잡한 비선형 모델에서도 비슷한 현상이 기대된다는 직관적 근거를 제공한다.
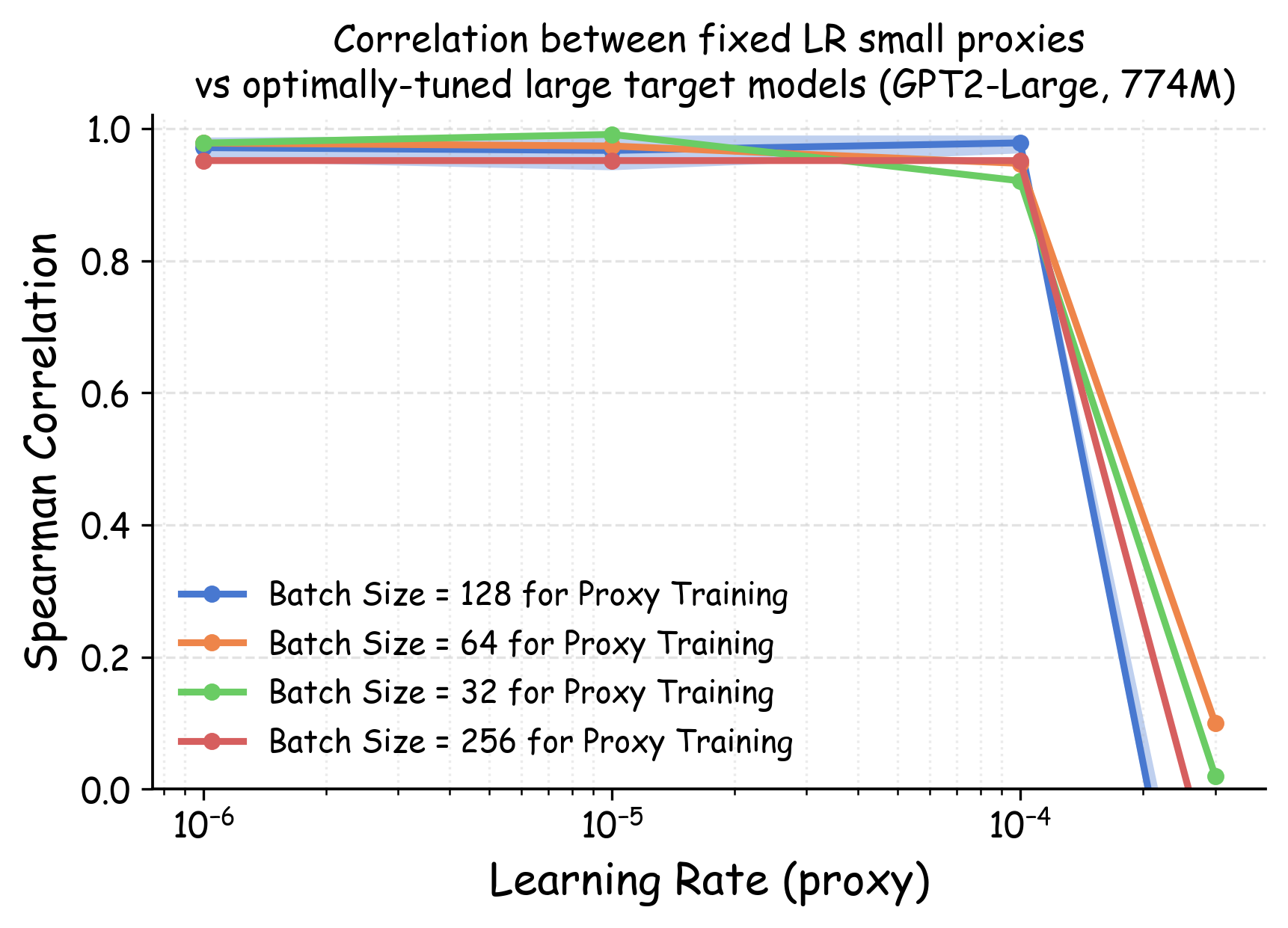
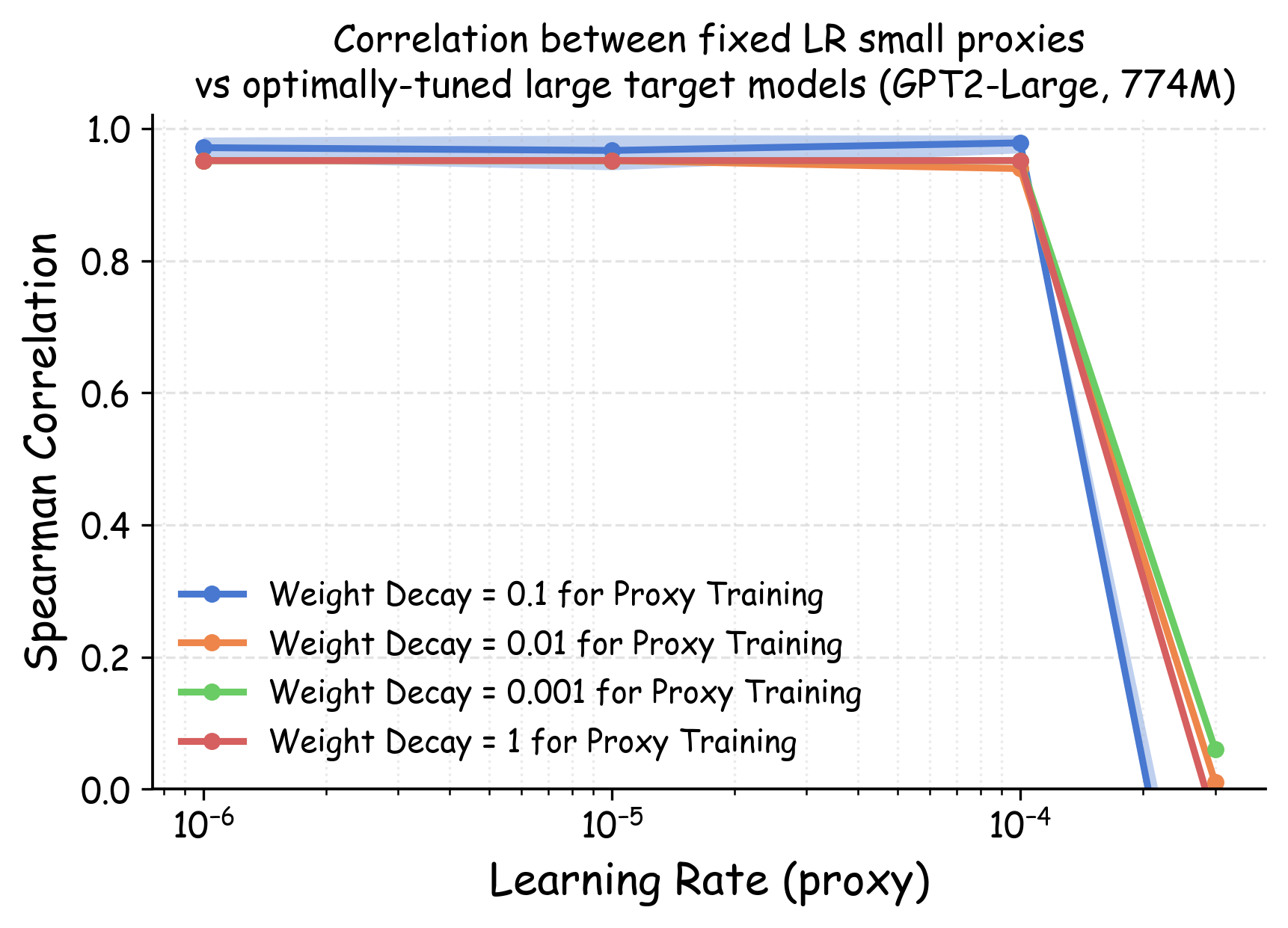
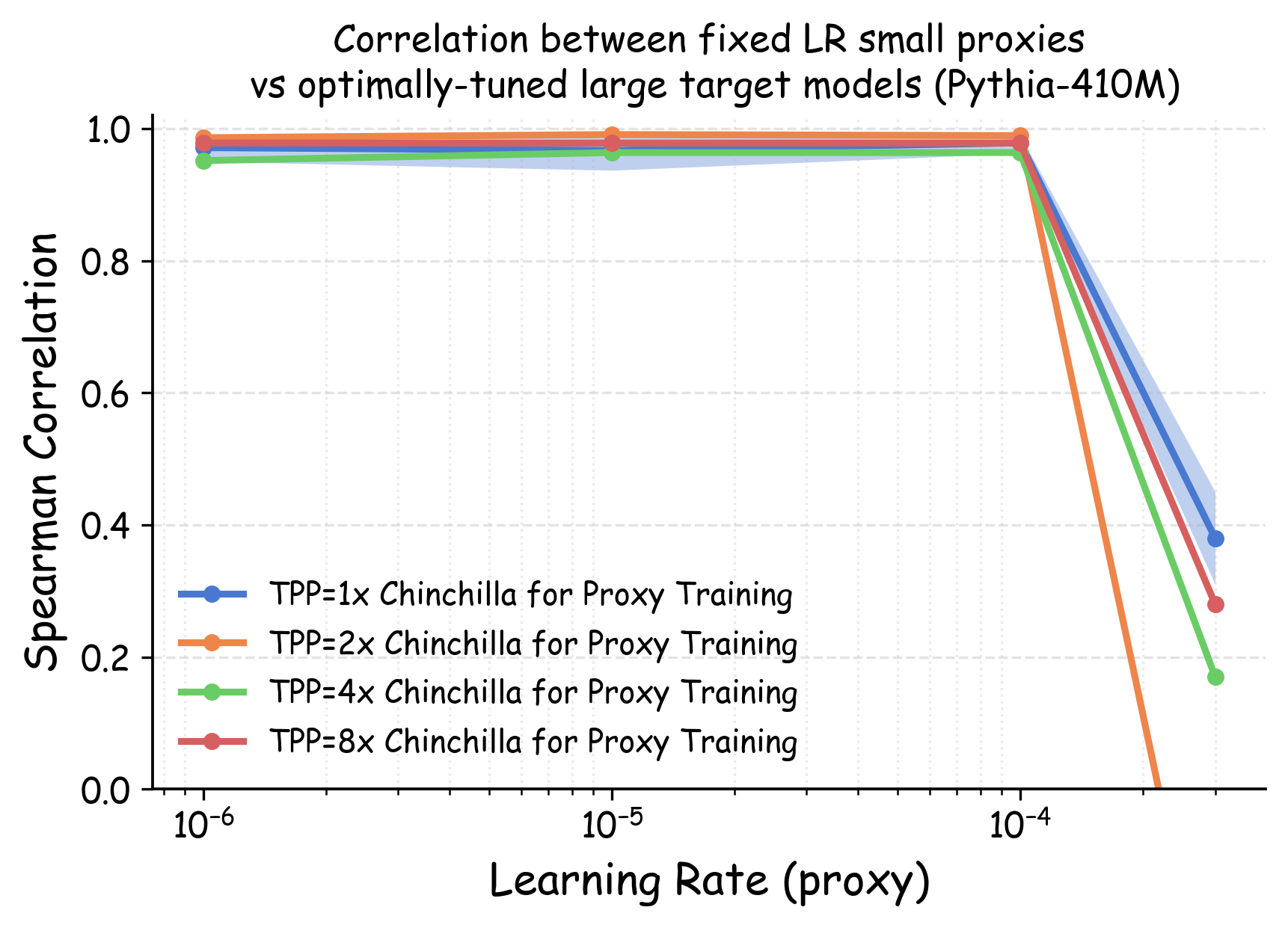
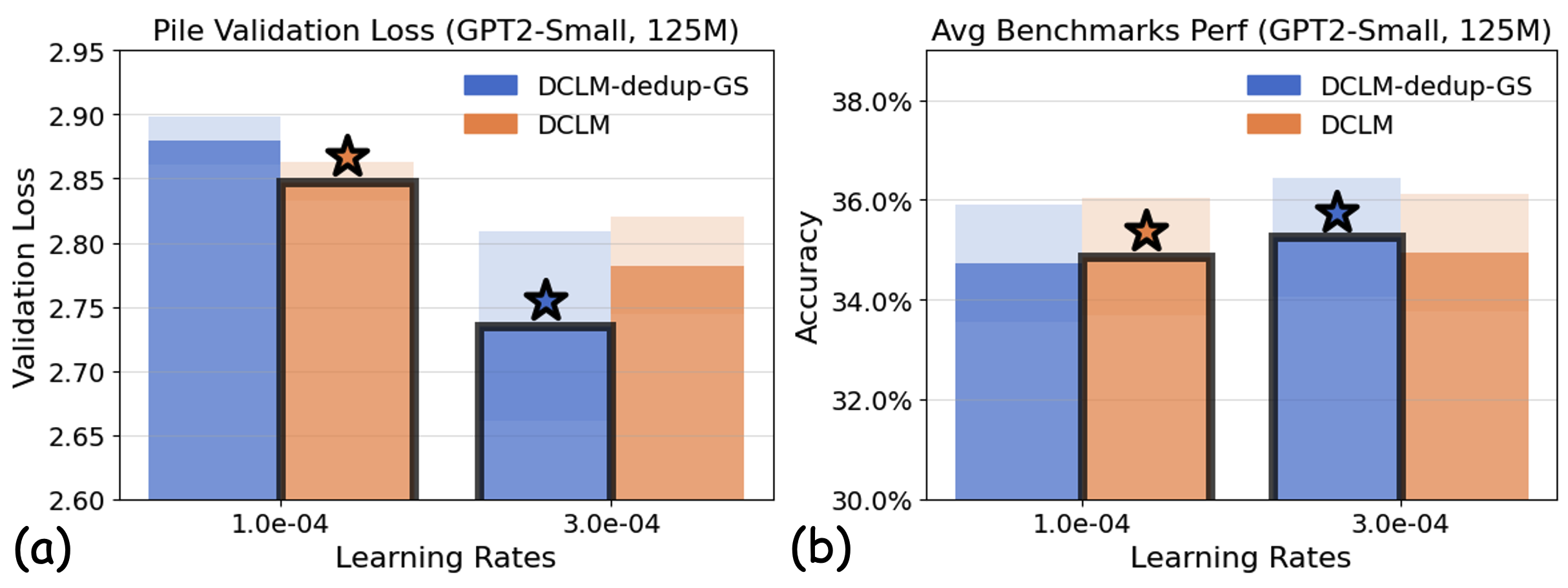
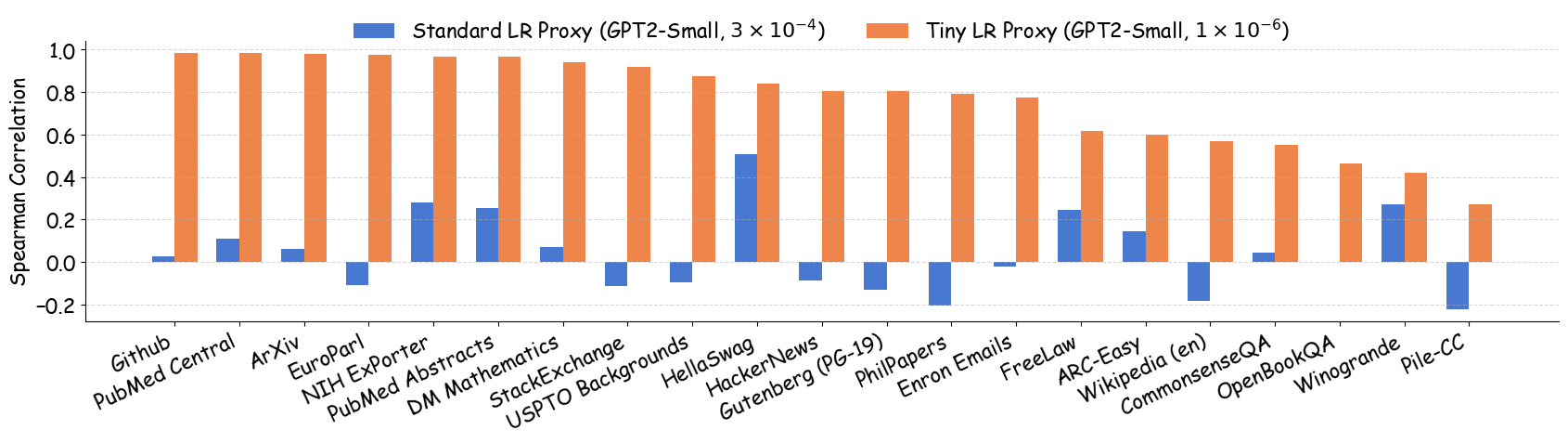
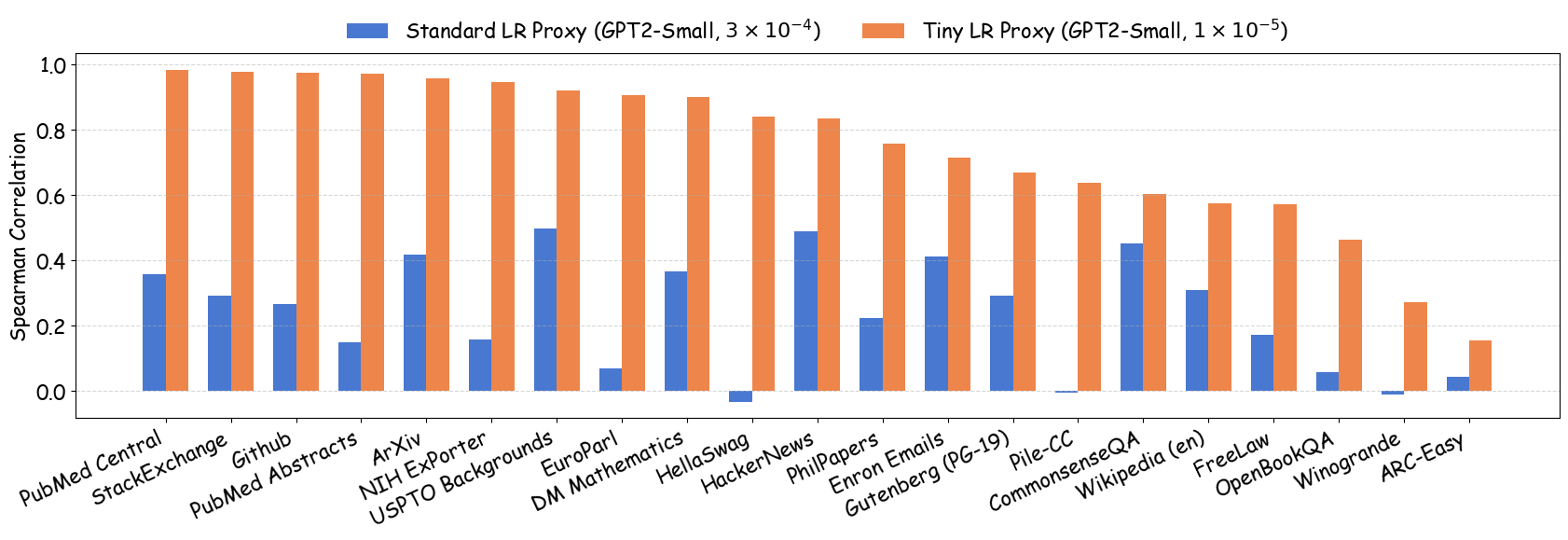
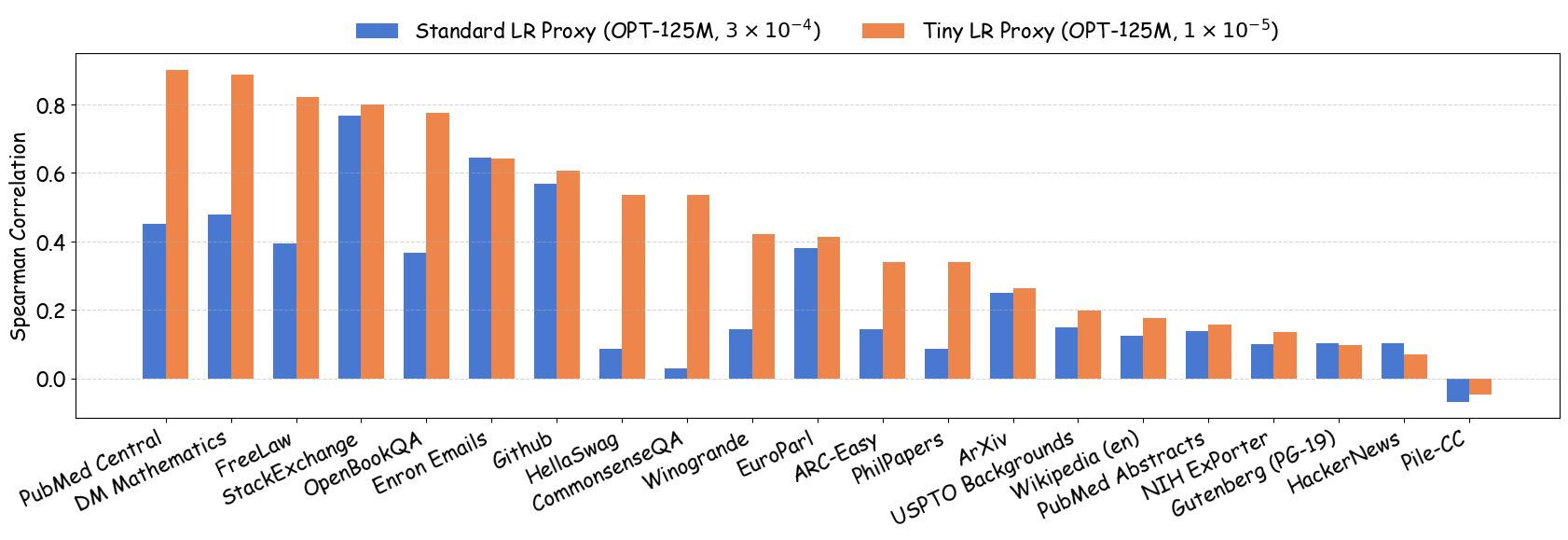
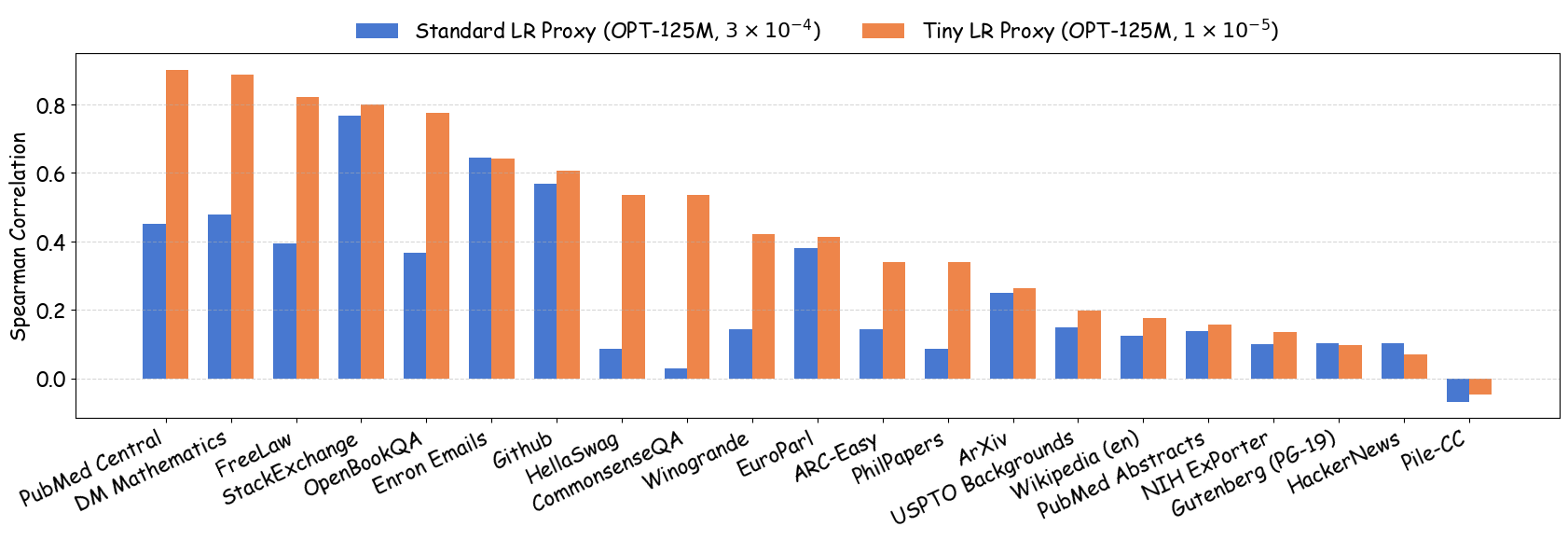
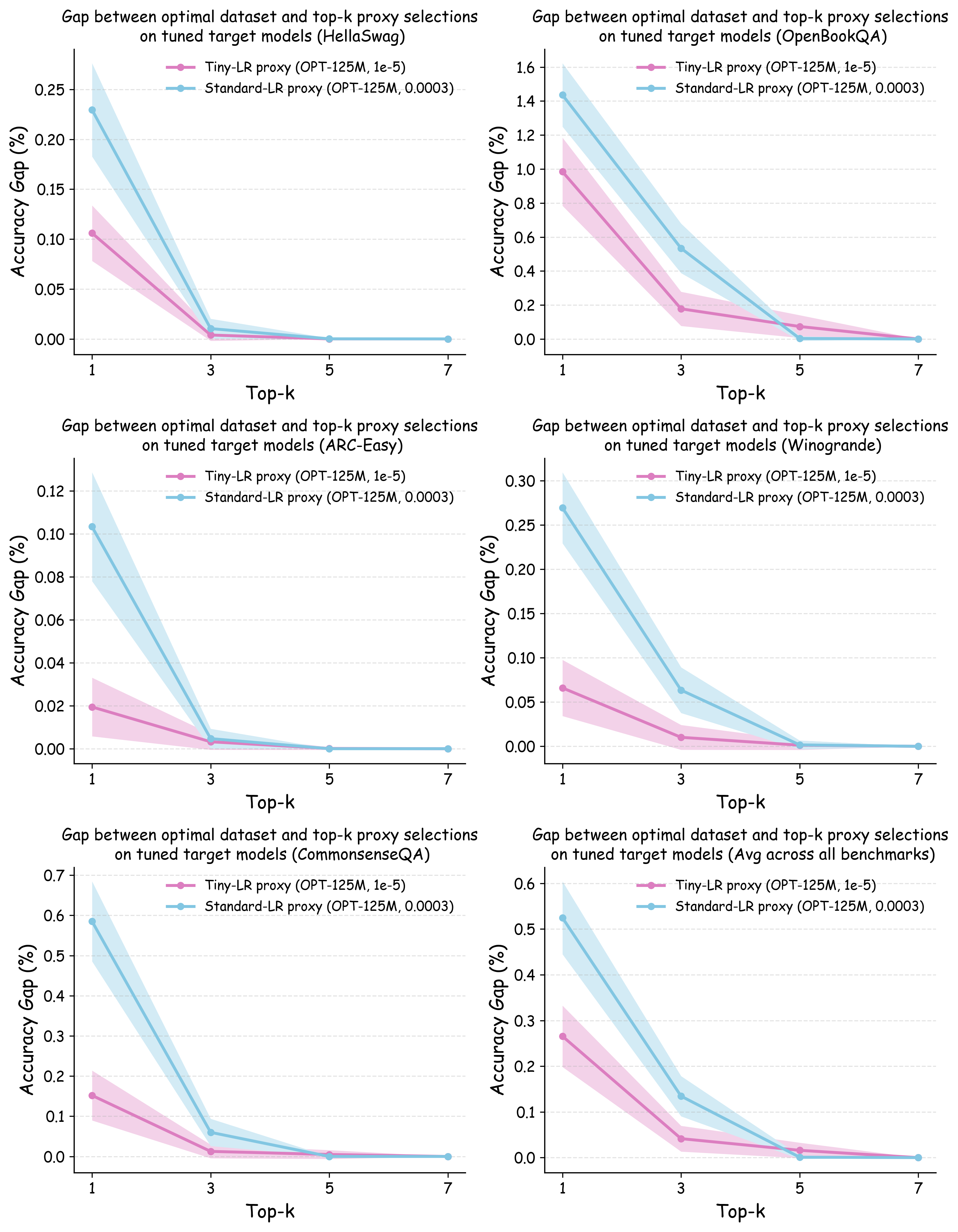
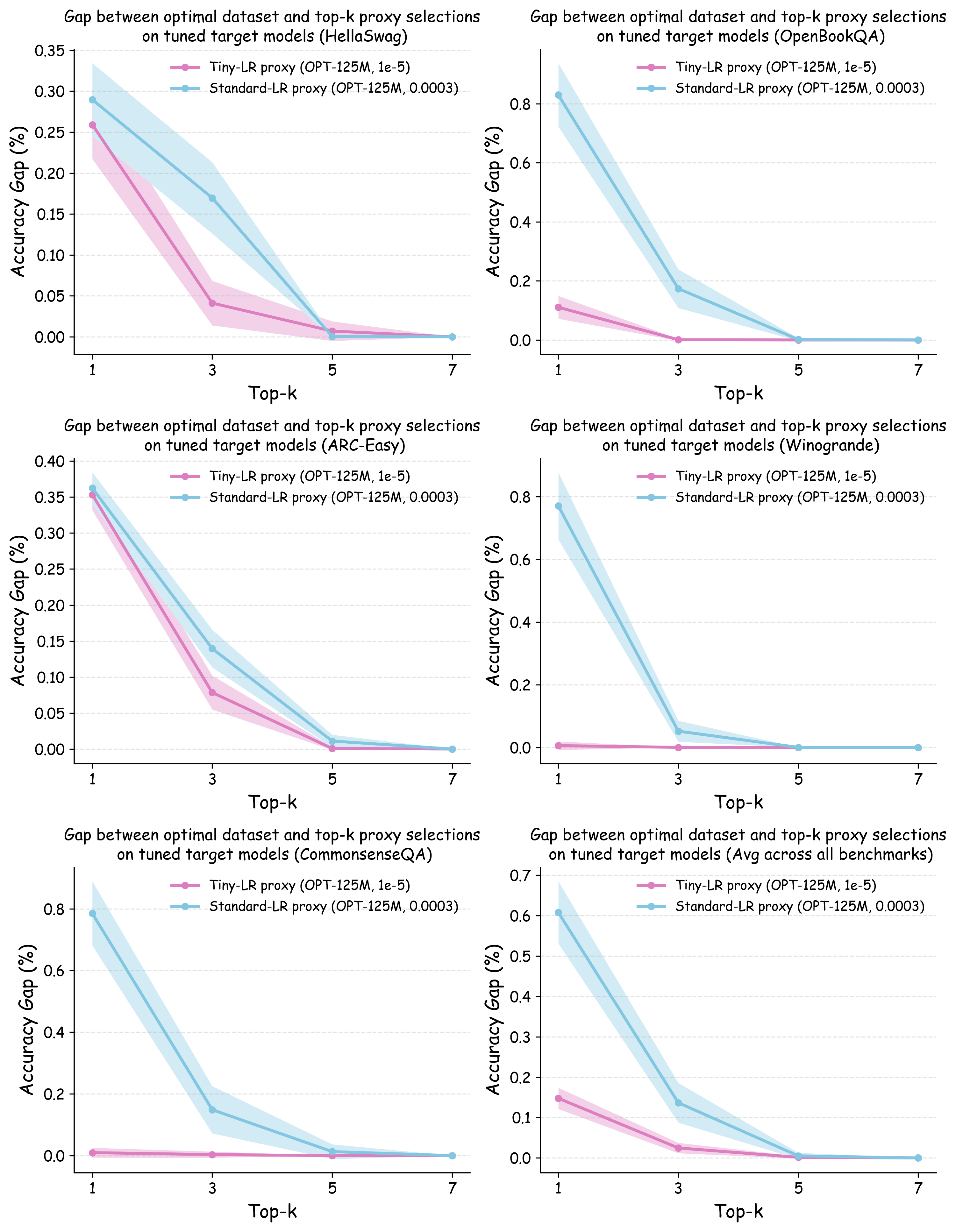
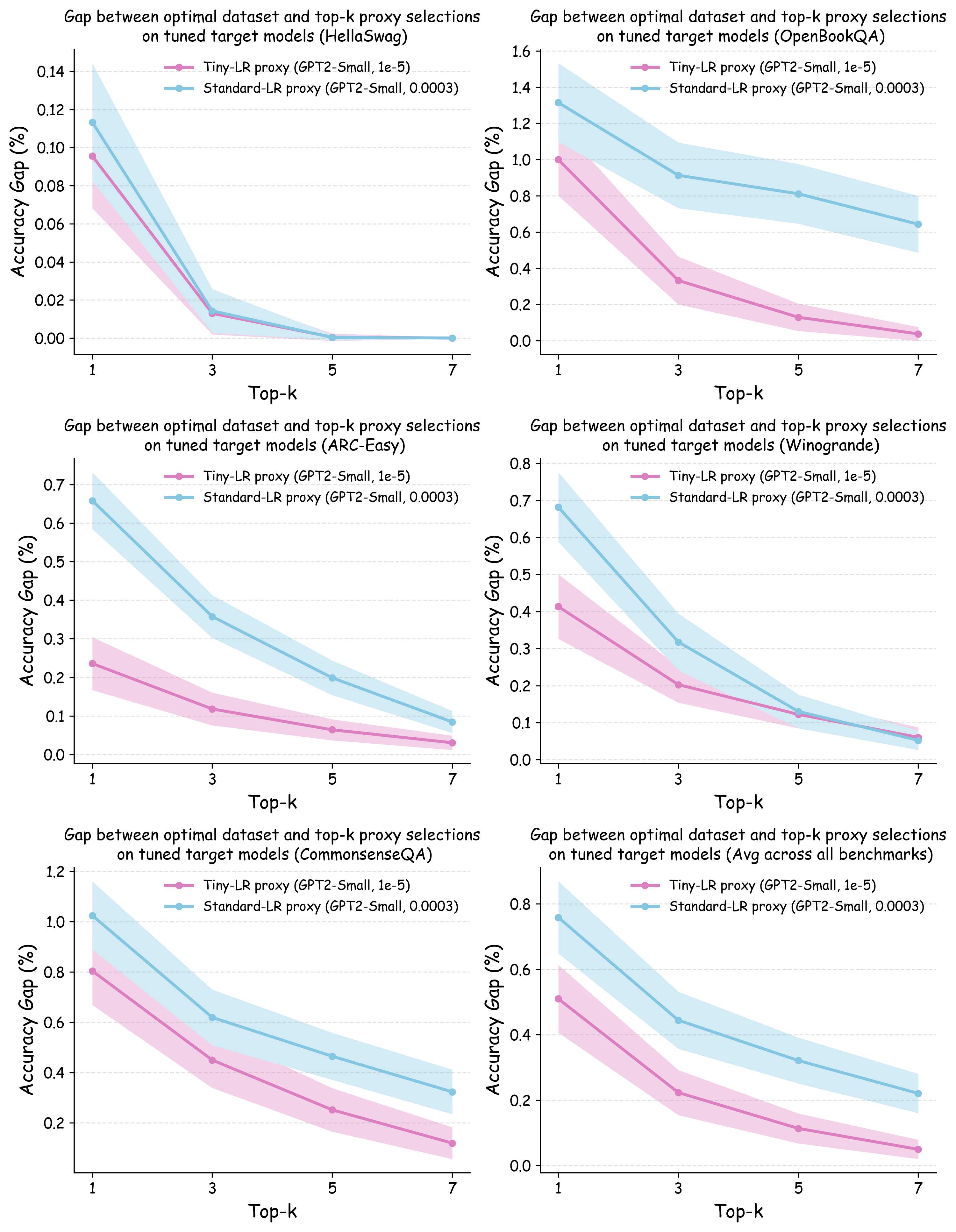
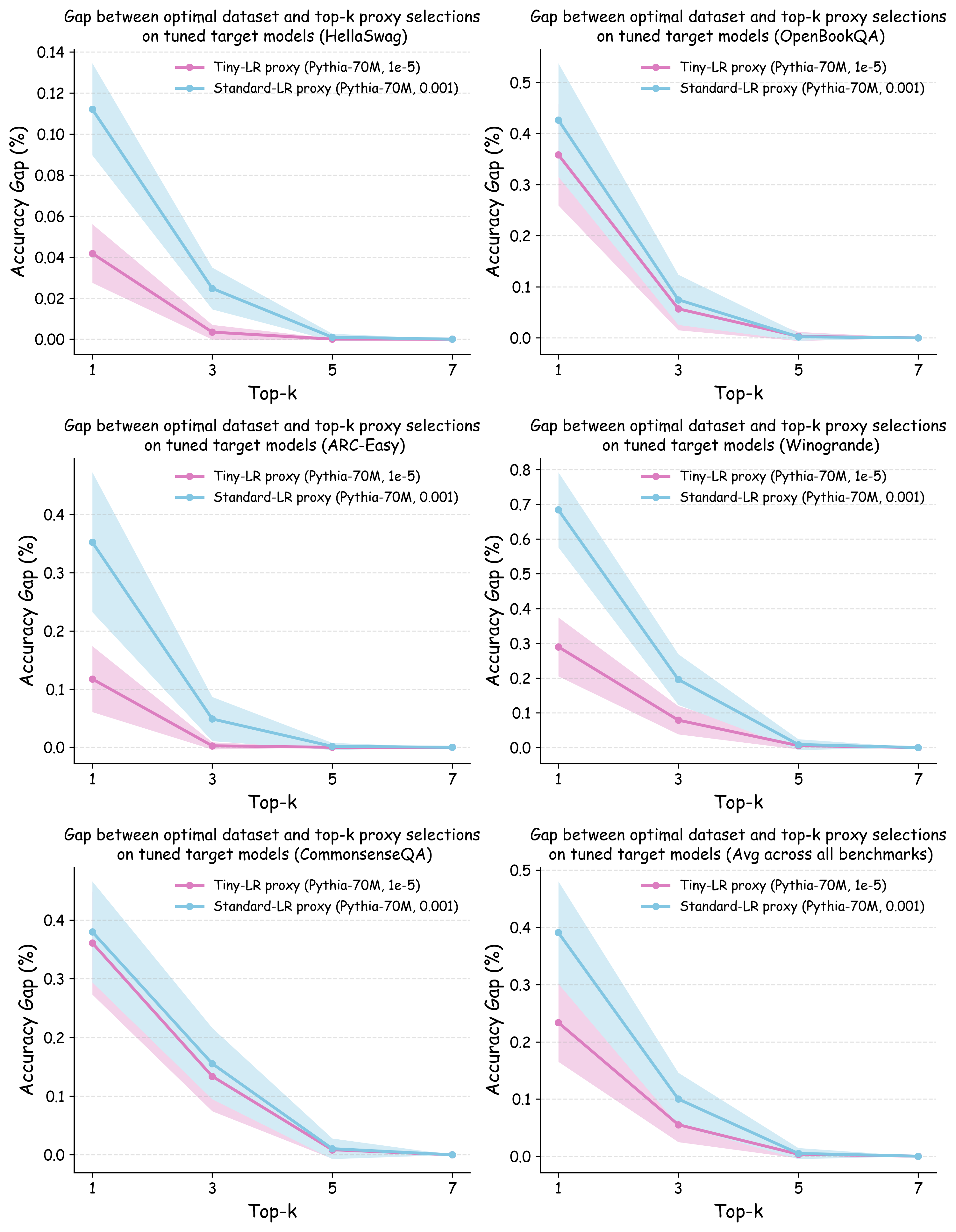
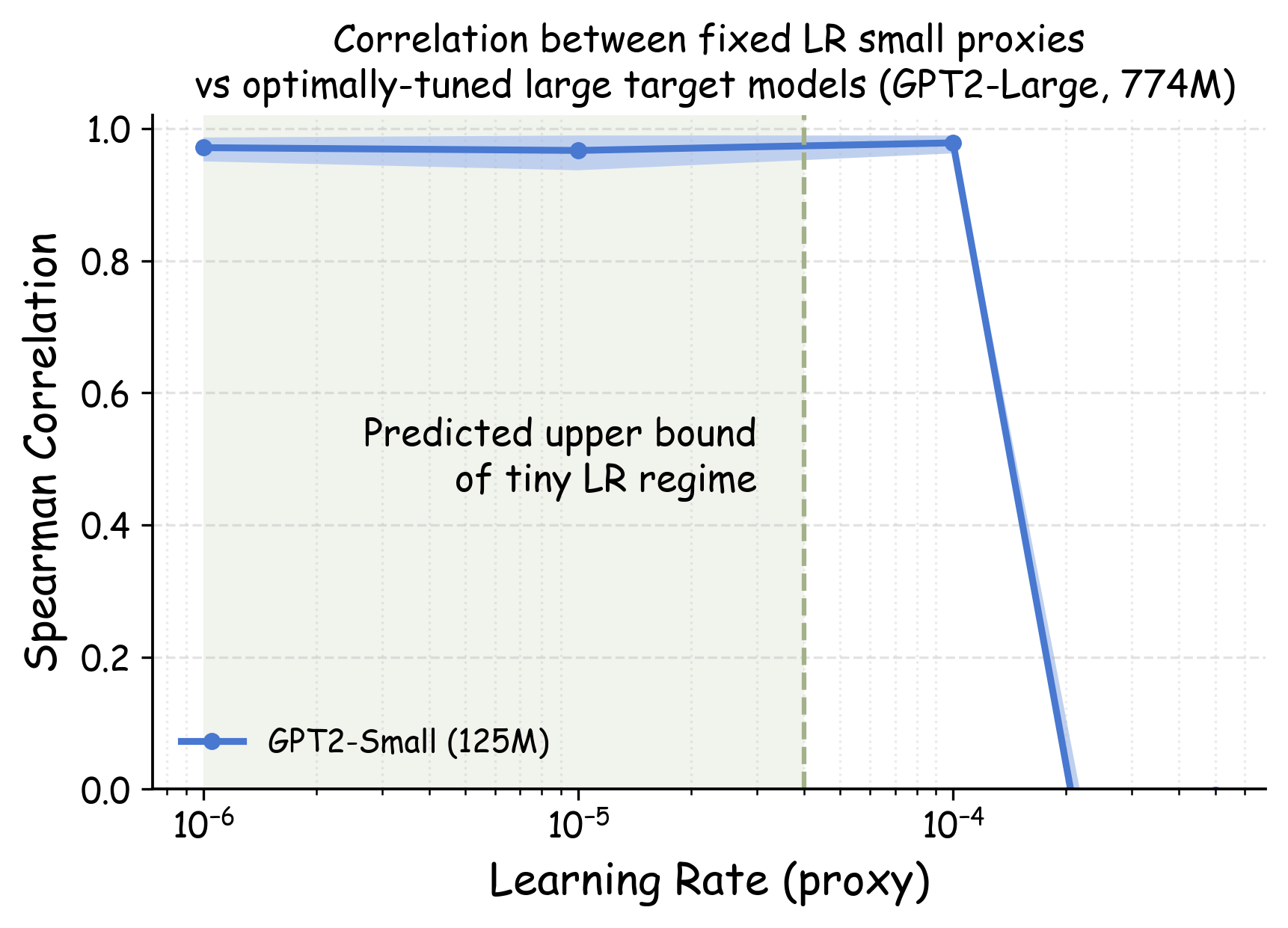
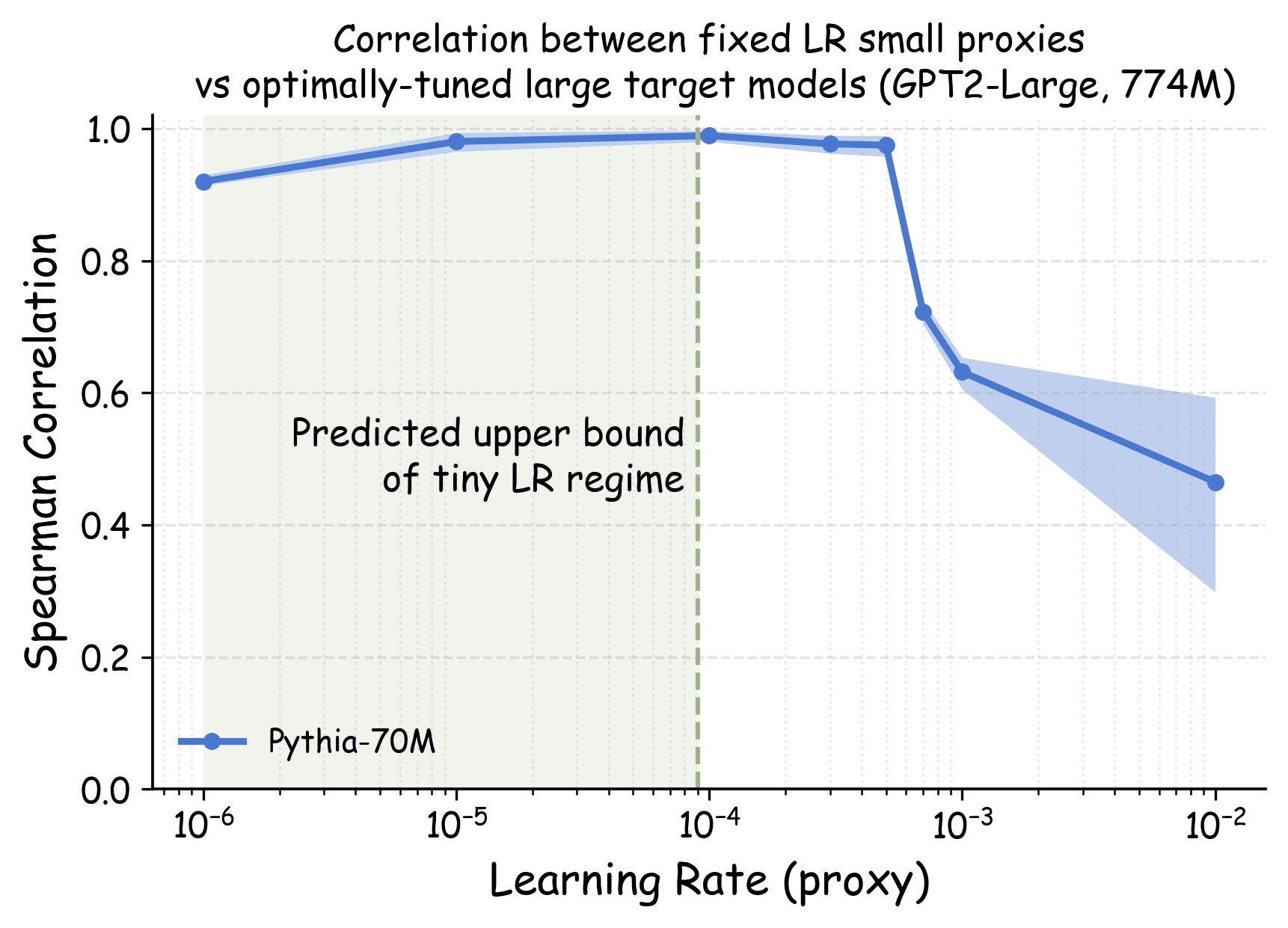
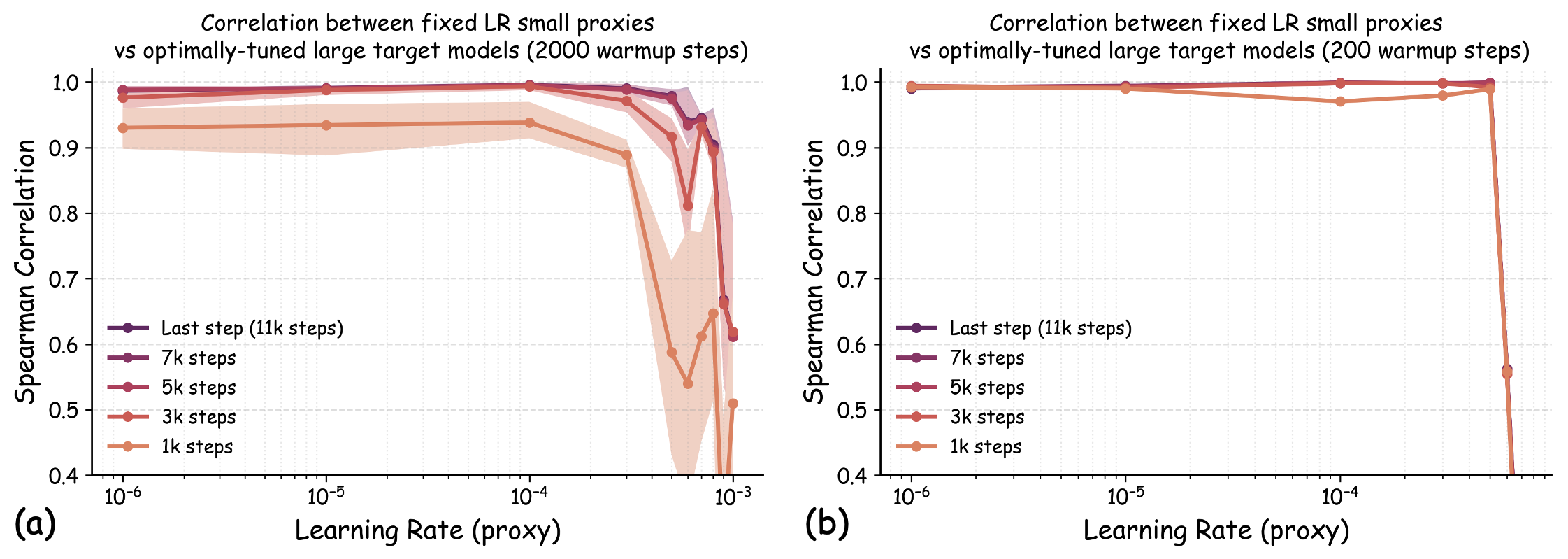
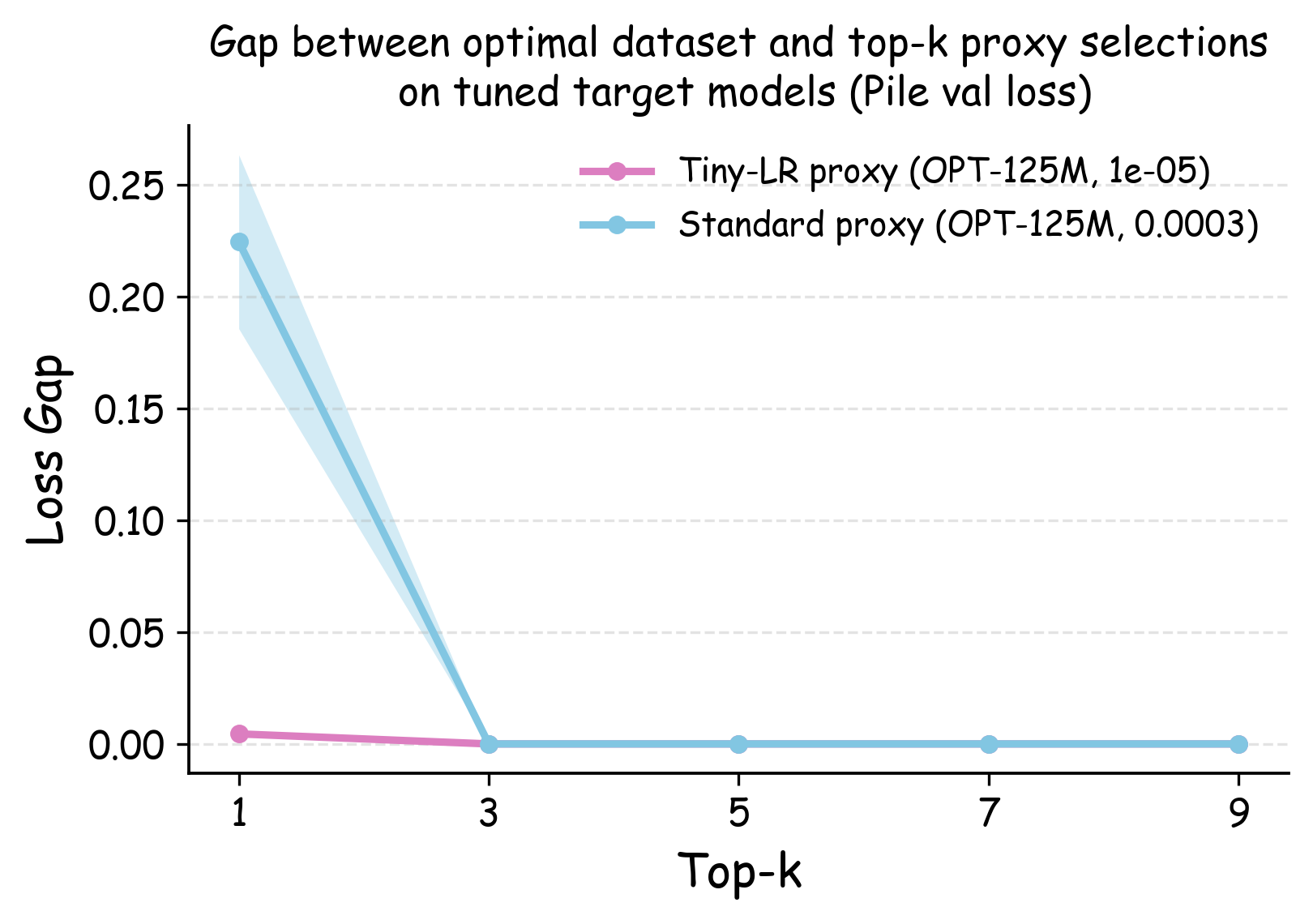
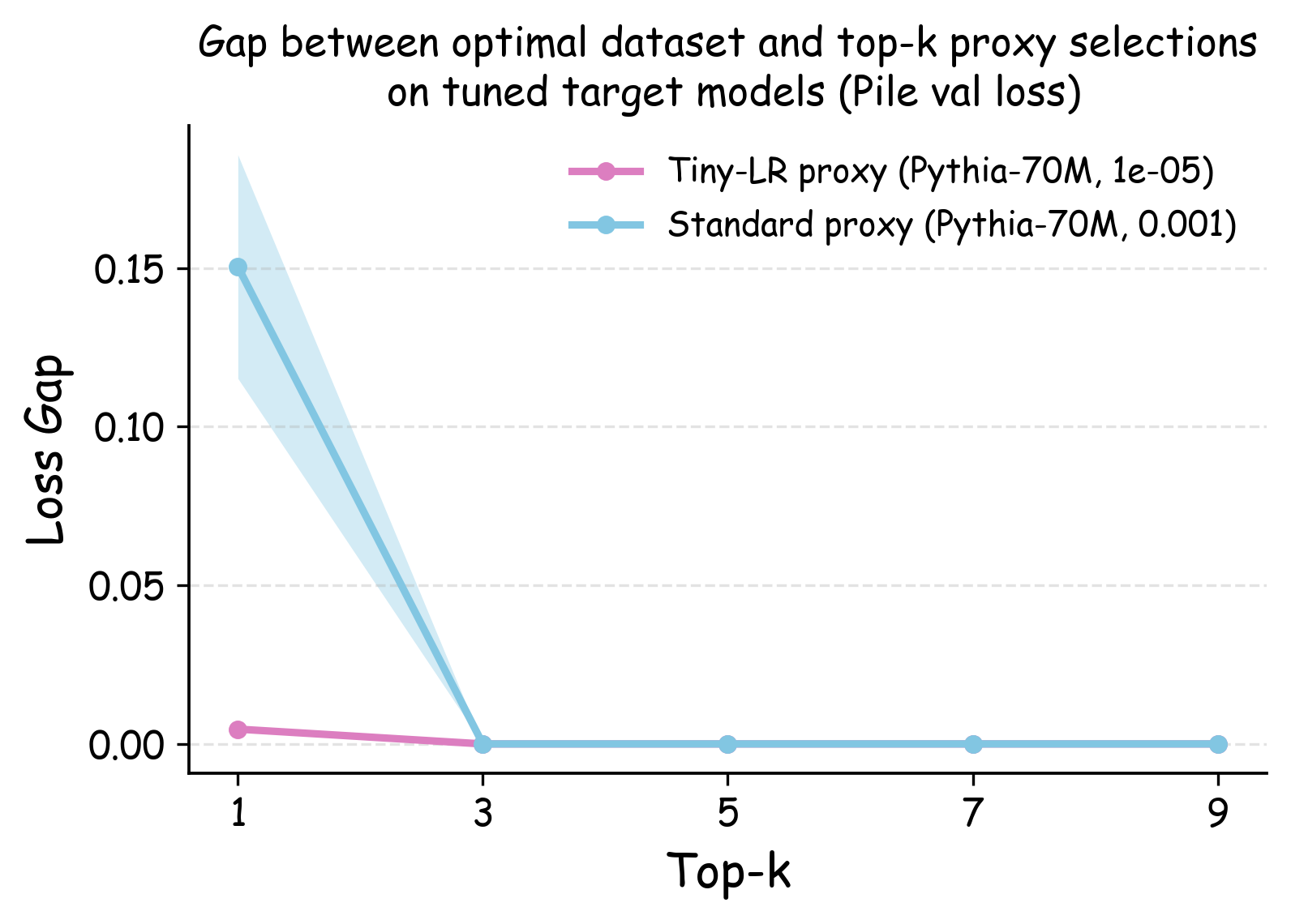
실험에서는 4가지 데이터 품질 차원(예: 중복 제거, 필터링 기준, 언어 다양성, 토큰 품질)과 23개의 레시피를 대상으로, 기존 고정 설정과 학습률 감소 설정을 비교하였다. 결과는 학습률 감소가 전체 대규모 사전학습 결과와의 상관계수를 크게 끌어올렸으며, 레시피 순위가 일관되게 유지되는 것을 보여준다. 특히, 기존 프로토콜에서는 서로 상반된 결론이 도출되던 경우가 학습률 감소 후에는 동일한 결론을 내렸다.
이 연구가 시사하는 바는 두fold이다. 첫째, 데이터 레시피 평가 시 “공정성”을 위해 모든 레시피에 동일한 설정을 강요하는 것이 오히려 비공정한 결과를 초래한다는 점이다. 둘째, 비용 효율적인 방법으로 학습률을 낮추는 간단한 조정만으로도 프록시 실험의 신뢰성을 크게 향상시킬 수 있다는 점이다. 앞으로 데이터 팀은 프록시 모델을 사용할 때, 데이터별 최적화된 하이퍼파라미터 탐색을 최소한 학습률 수준에서라도 고려해야 할 것이며, 이는 대규모 모델 개발 비용 절감과 품질 향상에 직접적인 영향을 미칠 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리