GARDO 보상 해킹 방지 확산 모델 강화
📝 원문 정보
- Title: GARDO: Reinforcing Diffusion Models without Reward Hacking
- ArXiv ID: 2512.24138
- 발행일: 2025-12-30
- 저자: Haoran He, Yuxiao Ye, Jie Liu, Jiajun Liang, Zhiyong Wang, Ziyang Yuan, Xintao Wang, Hangyu Mao, Pengfei Wan, Ling Pan
📝 초록 (Abstract)
** 확산 모델을 온라인 강화학습(RL)으로 미세조정하면 텍스트‑이미지 정렬을 크게 향상시킬 수 있다. 그러나 시각 과업에 대한 정확한 목표를 정의하기 어려워 실제 목표를 부분적으로만 반영하는 프록시 보상으로 최적화되는 경우가 많다. 이로 인해 프록시 점수는 상승하지만 실제 이미지 품질이 악화되고 다양성이 붕괴되는 보상 해킹 현상이 발생한다. 기존 방법은 레퍼런스 정책에 대한 정규화를 추가해 해킹을 방지하지만, 레퍼런스 정책이 보통 최적이 아니기 때문에 샘플 효율성이 떨어지고 새로운 고보상 영역 탐색이 억제된다. 샘플 효율성, 효과적인 탐색, 보상 해킹 완화라는 상충되는 요구를 동시에 만족시키기 위해 본 논문은 다양한 RL 알고리즘에 적용 가능한 Gated and Adaptive Regularization with Diversity‑aware Optimization(GARDO) 프레임워크를 제안한다. 핵심 통찰은 정규화를 모든 샘플에 일괄 적용할 필요가 없으며, 불확실성이 높은 일부 샘플에만 선택적으로 페널티를 부여하면 충분히 효과적이라는 점이다. 탐색 문제를 해결하기 위해 GARDO는 레퍼런스 모델을 주기적으로 현재 온라인 정책의 능력에 맞게 업데이트하는 적응형 정규화 메커니즘을 도입한다. 또한 RL에서 발생하는 모드 붕괴를 방지하기 위해 고품질이면서 다양성을 갖는 샘플에 대한 보상을 증폭시켜, 최적화 과정을 불안정하게 만들지 않으면서도 모드 커버리지를 촉진한다. 다양한 프록시 보상과 보지 않은 평가 지표에 걸친 광범위한 실험 결과, GARDO가 보상 해킹을 완화하고 생성 다양성을 향상시키면서도 샘플 효율성과 탐색 능력을 희생하지 않음을 입증한다. 프로젝트 코드는 https://tinnerhrhe.github.io/gardo_project 에서 확인할 수 있다.**
💡 논문 핵심 해설 (Deep Analysis)
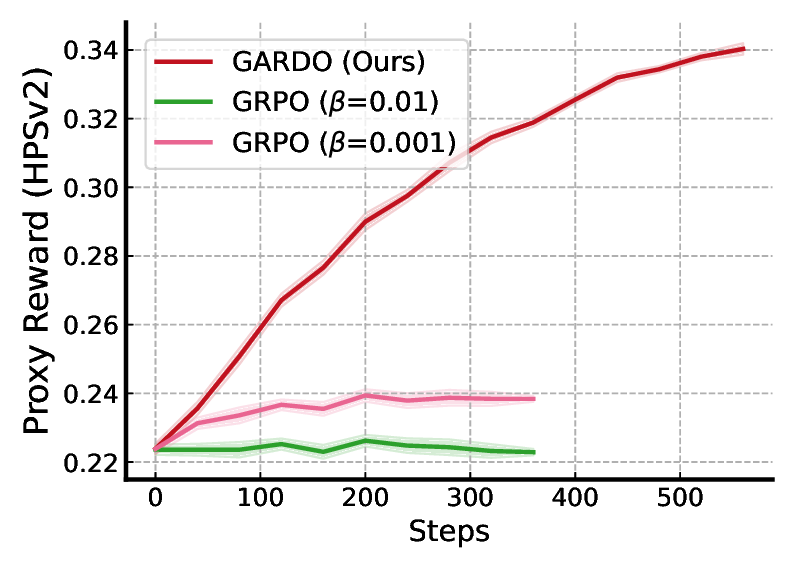
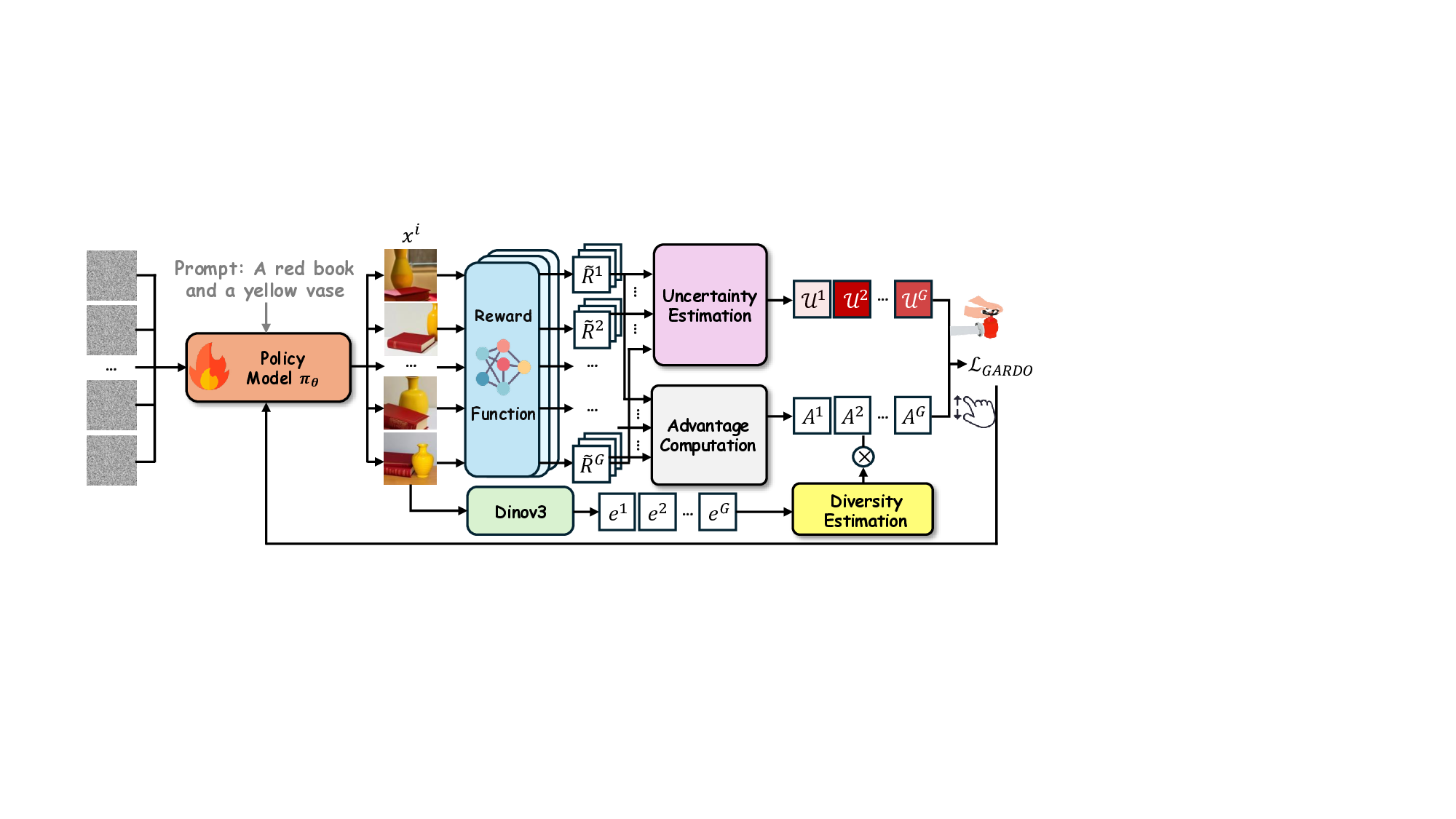
본 논문은 최근 텍스트‑투‑이미지 생성 분야에서 확산 모델을 강화학습으로 미세조정하는 접근법이 직면한 핵심 문제, 즉 “보상 해킹”을 체계적으로 분석하고 새로운 해결책을 제시한다. 기존 연구들은 프록시 보상이 실제 인간이 기대하는 이미지 품질을 완전히 대변하지 못한다는 점을 인정하면서도, 레퍼런스(사전 학습) 정책에 대한 정규화 손실을 추가해 모델이 급격히 프록시 점수만을 최적화하는 것을 방지하려 했다. 그러나 이러한 정규화는 두 가지 심각한 부작용을 낳는다. 첫째, 레퍼런스 정책 자체가 최적이 아니기 때문에, 정규화가 과도하게 적용되면 모델이 더 나은 정책을 탐색할 여지를 억제한다. 둘째, 정규화가 모든 샘플에 균일하게 적용되면, 실제로 프록시 보상이 높은 고품질 샘플까지도 불필요하게 제재를 받아 샘플 효율성이 떨어진다.
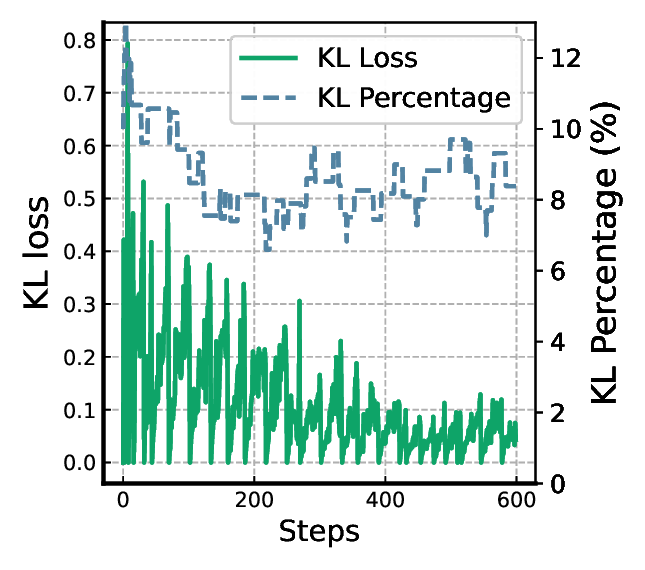
GARDO는 이러한 한계를 “불확실성 기반 게이팅”과 “적응형 레퍼런스 업데이트”라는 두 축으로 극복한다. 불확실성 기반 게이팅은 현재 정책이 예측하기 어려운, 즉 모델이 높은 엔트로피를 보이는 샘플에만 정규화 페널티를 부여한다는 의미다. 이를 위해 논문은 샘플별 예측 분산 혹은 정책의 로그 확률 변동성을 정량화하고, 사전 정의된 임계값을 초과하는 경우에만 KL‑다이버전스 정규화 항을 적용한다. 결과적으로 정규화는 “위험”이 높은 샘플에만 집중되어, 모델이 안전하게 탐색할 수 있는 영역을 확보하면서도 고보상 영역을 자유롭게 탐색할 수 있다.
두 번째 메커니즘인 적응형 레퍼런스 업데이트는 레퍼런스 모델을 고정된 상태로 두는 대신, 일정 주기마다 현재 온라인 정책의 파라미터를 복제하거나, 정책의 성능을 기준으로 가중 평균을 수행해 최신화한다. 이렇게 하면 레퍼런스 정책이 점점 더 강력해져 정규화가 의미 있는 제약으로 작용한다. 동시에 레퍼런스가 너무 강해져 탐색을 억제하는 상황을 방지하기 위해, 업데이트 간격과 복제 비율을 하이퍼파라미터로 조절한다.
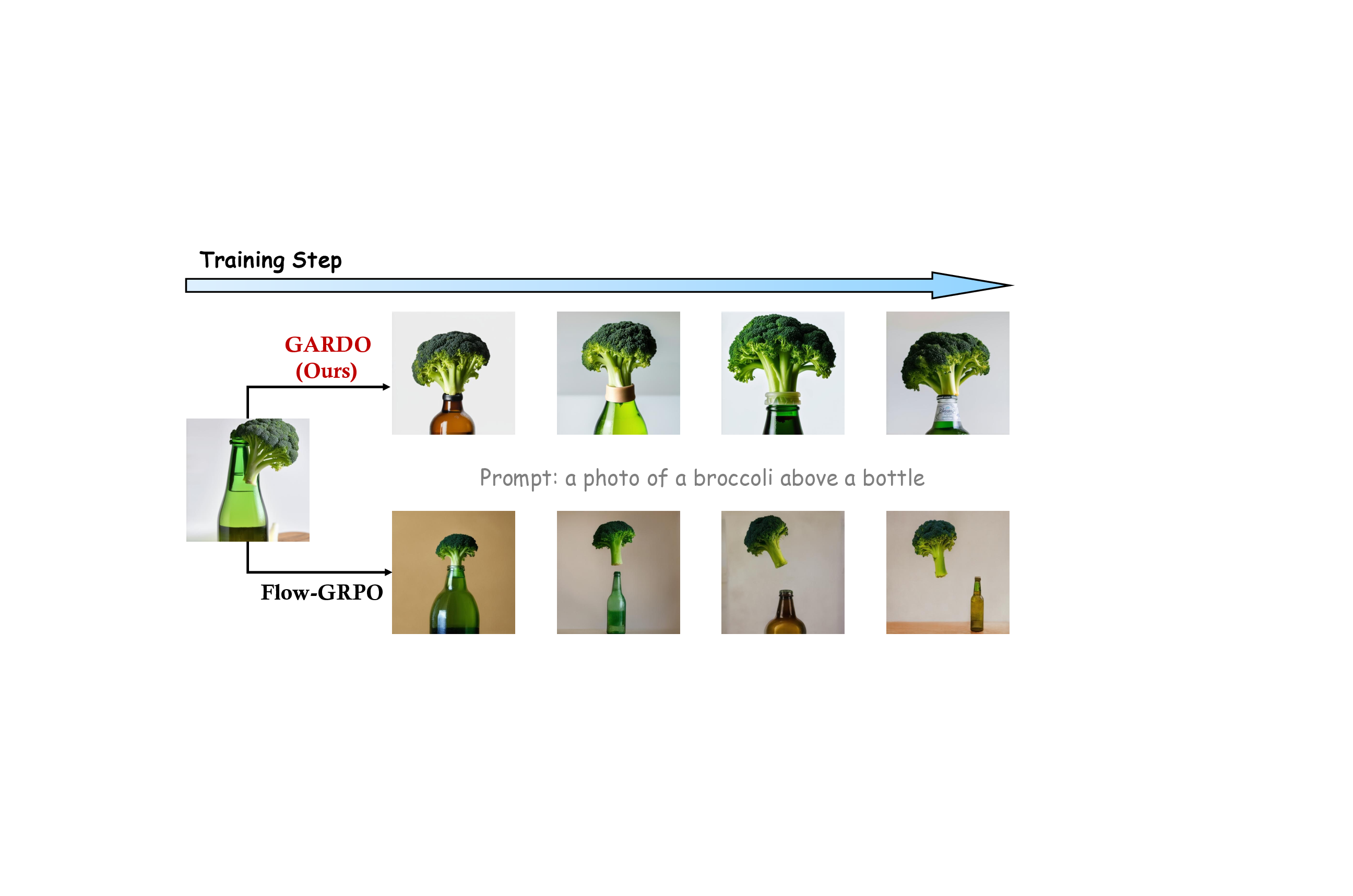
또한 GARDO는 “다양성 인식 보상 증폭”을 도입해 모드 붕괴 문제를 완화한다. 기존 RL 기반 확산 모델은 보상이 높은 몇몇 모드에만 집중해 다른 스타일이나 구성을 무시하는 경향이 있다. 이를 해결하기 위해 논문은 샘플의 특성 벡터(예: CLIP 이미지 임베딩) 간의 평균 거리를 계산해 다양성을 정량화하고, 이 값에 비례해 보상을 가중한다. 즉, 고품질이면서도 다른 샘플들과 거리가 먼(다양한) 경우에 보상이 추가로 상승한다. 이 설계는 보상 스케일을 급격히 변동시키지 않으면서도 탐색을 장려한다.
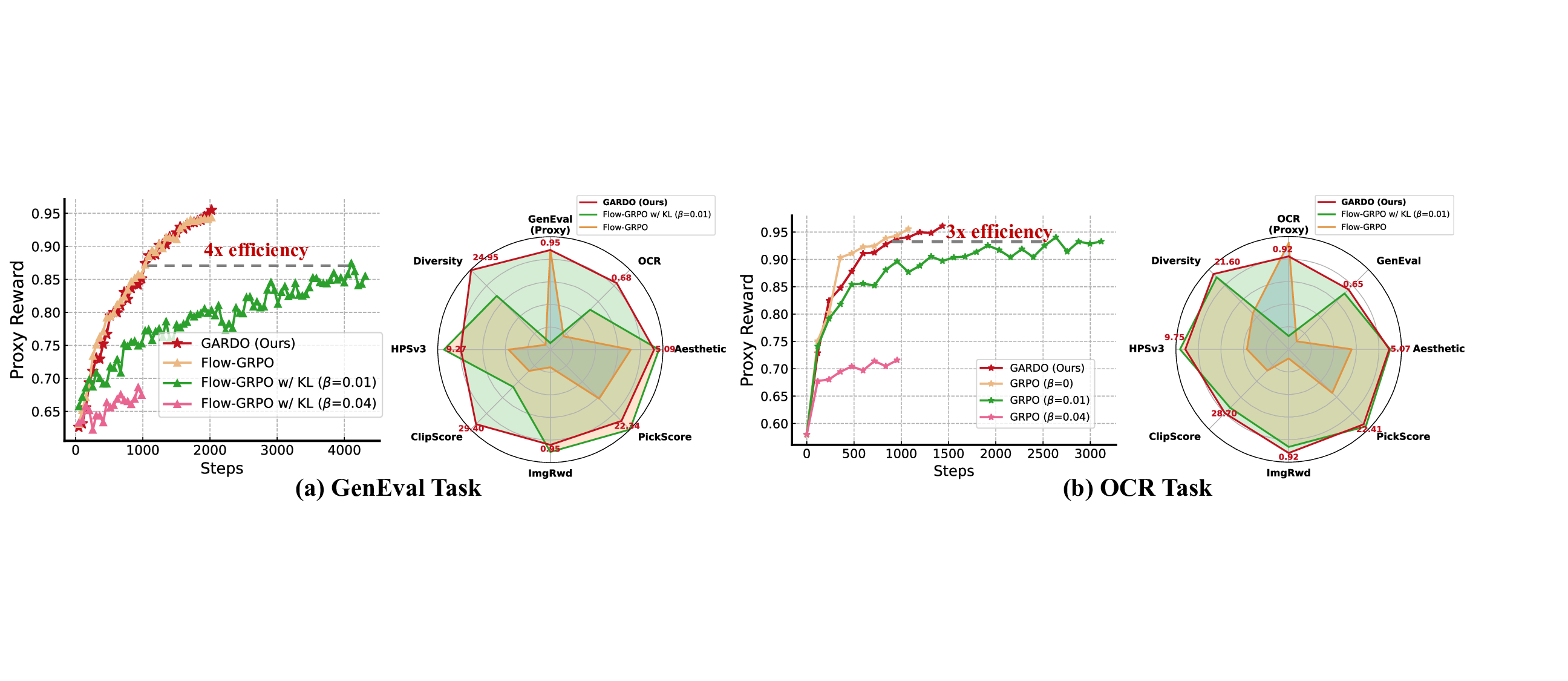
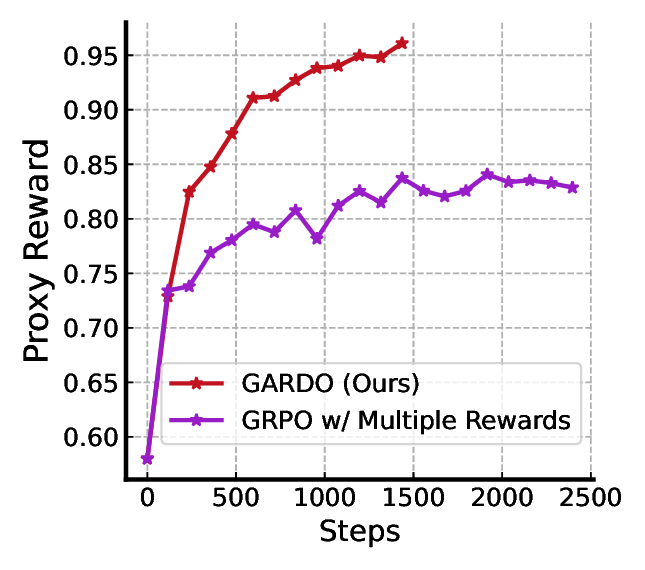
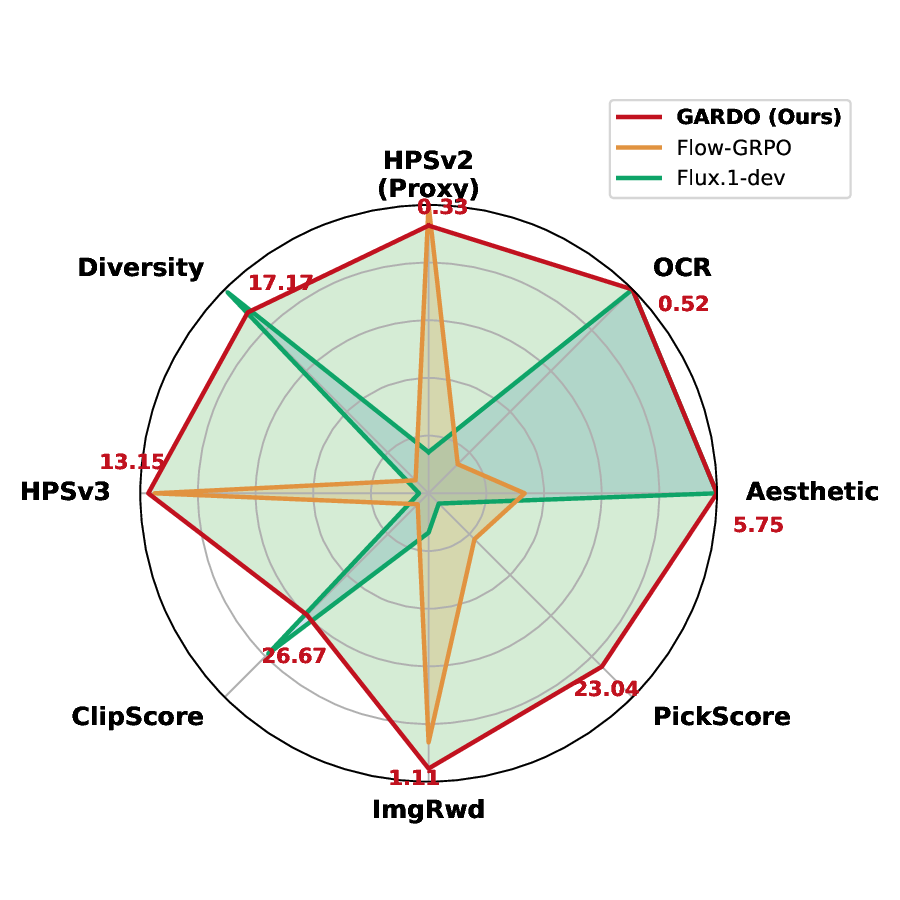
실험에서는 여러 공개 프록시 보상(예: CLIPScore, AestheticScore)과, 인간 평가와 유사한 “보지 않은” 메트릭(예: FID, IS, 인간 라벨링) 모두에서 GARDO가 기존 정규화 기반 방법보다 프록시 점수와 실제 이미지 품질 사이의 격차를 크게 줄였음을 보여준다. 특히, 샘플 효율성 측면에서 동일한 학습 스텝 수 대비 더 높은 다양성 지표와 낮은 모드 붕괴 비율을 기록했다. 이러한 결과는 GARDO가 “정규화는 언제, 어디에, 어떻게 적용할 것인가”라는 질문에 대한 실용적인 해답을 제공함을 의미한다.
요약하면, GARDO는 (1) 불확실성 기반 선택적 정규화로 샘플 효율성을 유지, (2) 레퍼런스 정책을 주기적으로 최신화해 탐색과 안전성 사이의 균형을 맞추고, (3) 다양성을 고려한 보상 증폭으로 모드 커버리지를 확보한다는 세 가지 핵심 기법을 결합한다. 이 프레임워크는 기존 RL‑기반 확산 모델 강화 방법에 비해 구현이 비교적 간단하면서도, 다양한 도메인과 보상 설계에 일반화 가능하다는 장점을 가진다.
**
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리