롱캣 지그재그 어텐션을 활용한 효율적인 장문 스케일링
📝 원문 정보
- Title: Efficient Context Scaling with LongCat ZigZag Attention
- ArXiv ID: 2512.23966
- 발행일: 2025-12-30
- 저자: Chen Zhang, Yang Bai, Jiahuan Li, Anchun Gui, Keheng Wang, Feifan Liu, Guanyu Wu, Yuwei Jiang, Defei Bu, Li Wei, Haihang Jing, Hongyin Tang, Xin Chen, Xiangzhou Huang, Fengcun Li, Rongxiang Weng, Yulei Qian, Yifan Lu, Yerui Sun, Jingang Wang, Yuchen Xie, Xunliang Cai
📝 초록 (Abstract)
우리는 기존의 전면 어텐션 모델을 제한된 연산 예산으로도 동작하도록 변환할 수 있는 희소 어텐션 기법인 LongCat ZigZag Attention(LoZA)을 제안한다. 장문 컨텍스트 상황에서 LoZA는 사전 채우기(pre‑fill) 중심 작업(예: 검색 기반 생성)과 디코딩 중심 작업(예: 도구 연동 추론) 모두에서 큰 속도 향상을 달성한다. 특히 LoZA를 LongCat‑Flash에 중간 학습 단계에서 적용함으로써, 우리는 LongCat‑Flash‑Exp라는 장문 기반 모델을 제공한다. 이 모델은 최대 1백만 토큰을 신속히 처리할 수 있어 장기 추론 및 장기 에이전트 기능을 효율적으로 수행한다.💡 논문 핵심 해설 (Deep Analysis)
![]()
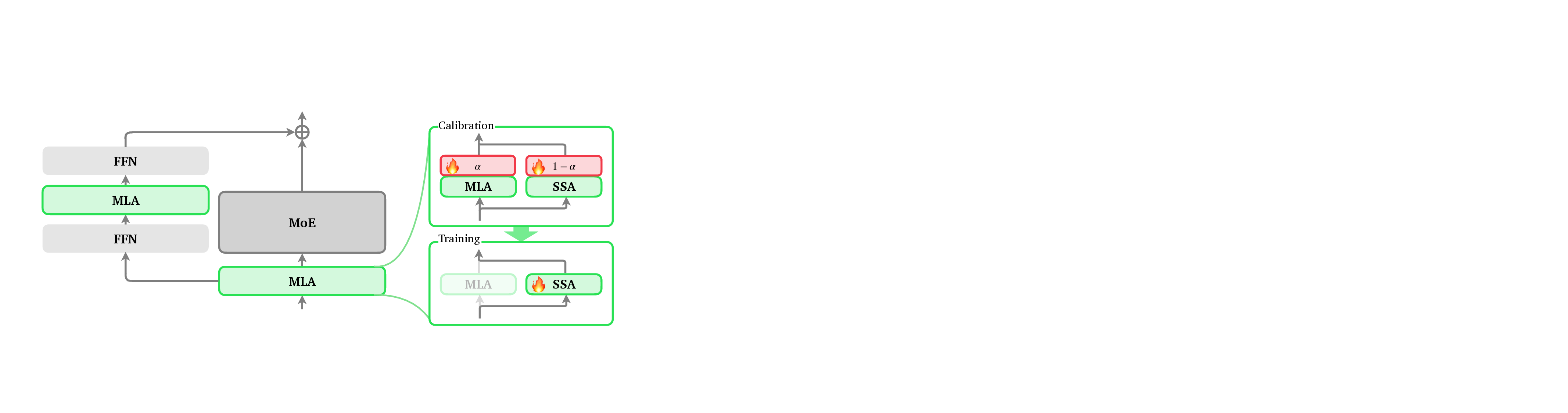
두 번째 단계인 Training에서는 선택된 희소 패턴을 고정하고, MoE(다중 전문가) FFN과 같은 고성능 피드포워드 네트워크를 그대로 활용한다. 이때 LoZA는 기존 전면 어텐션과 동일한 학습 목표를 유지하면서도, 희소 패턴에 맞춘 가중치 정규화와 스케일링을 적용한다. 특히 λ 파라미터를 통해 희소도와 모델 용량 사이의 트레이드오프를 정밀하게 조절할 수 있어, 메모리 제한이 엄격한 환경에서도 안정적인 수렴을 보인다.
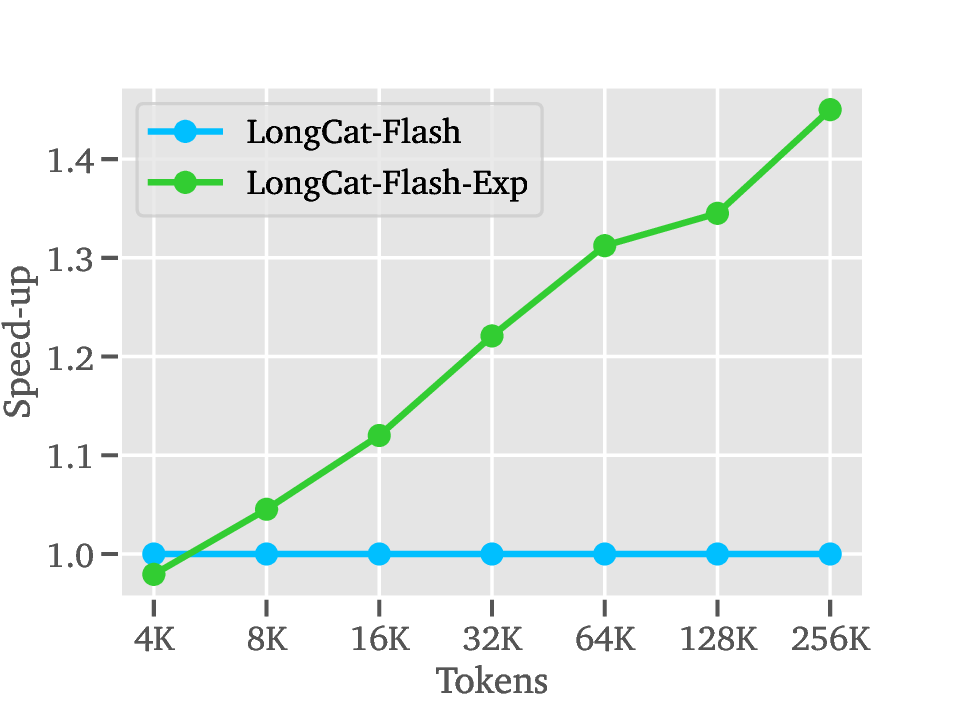
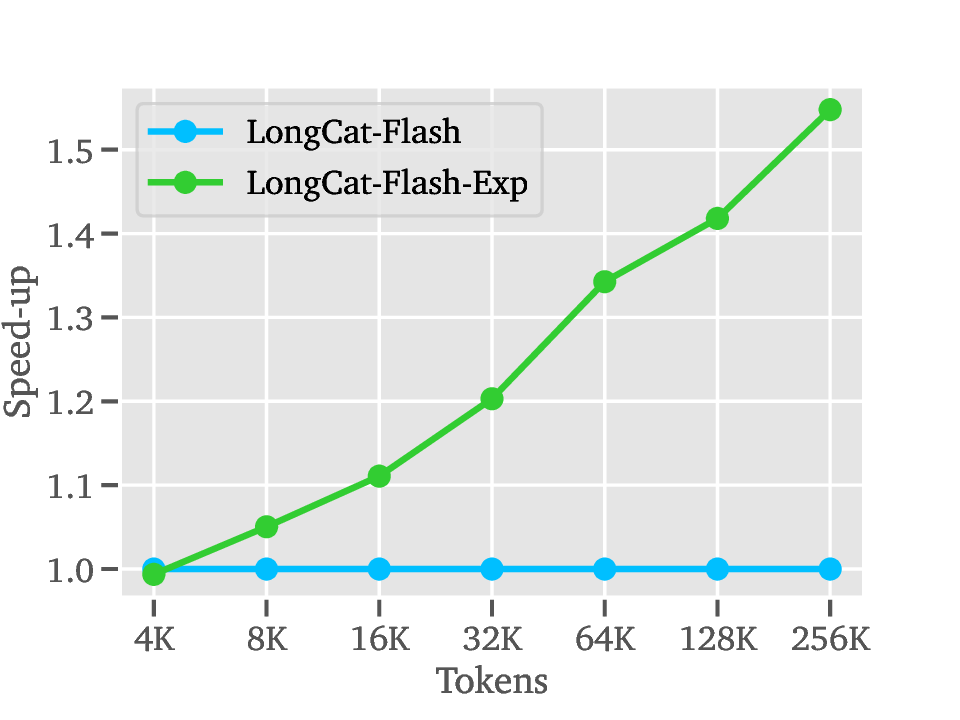
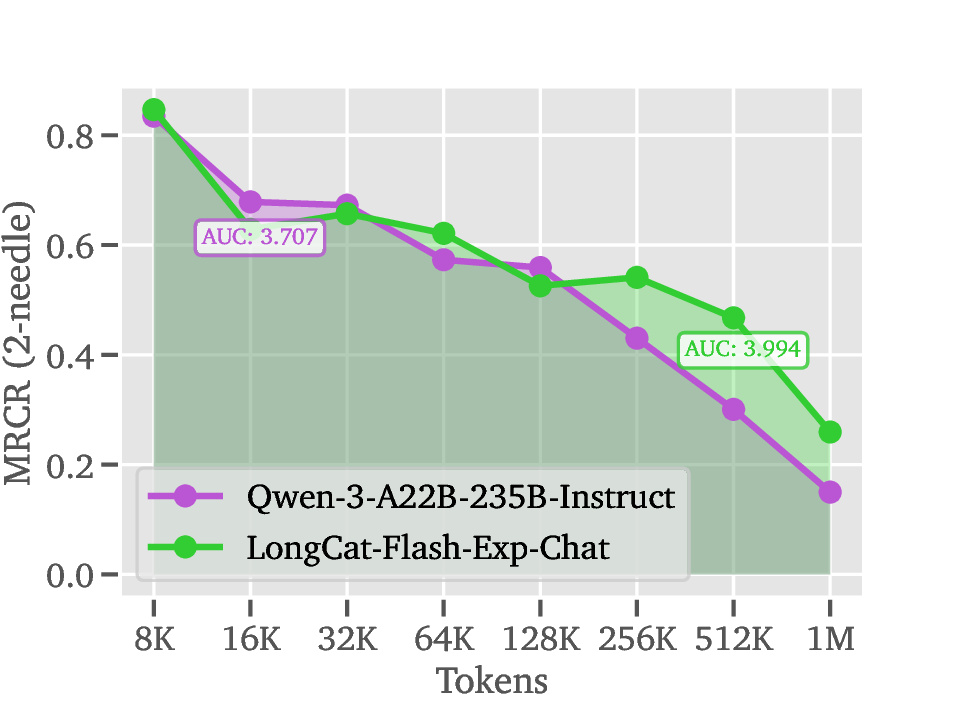
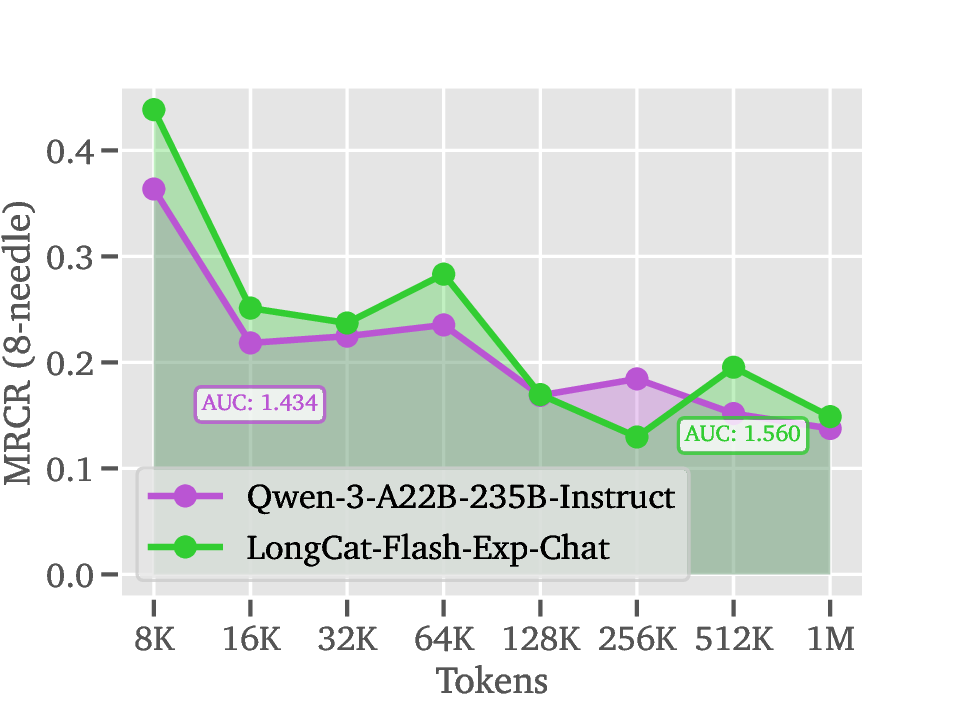
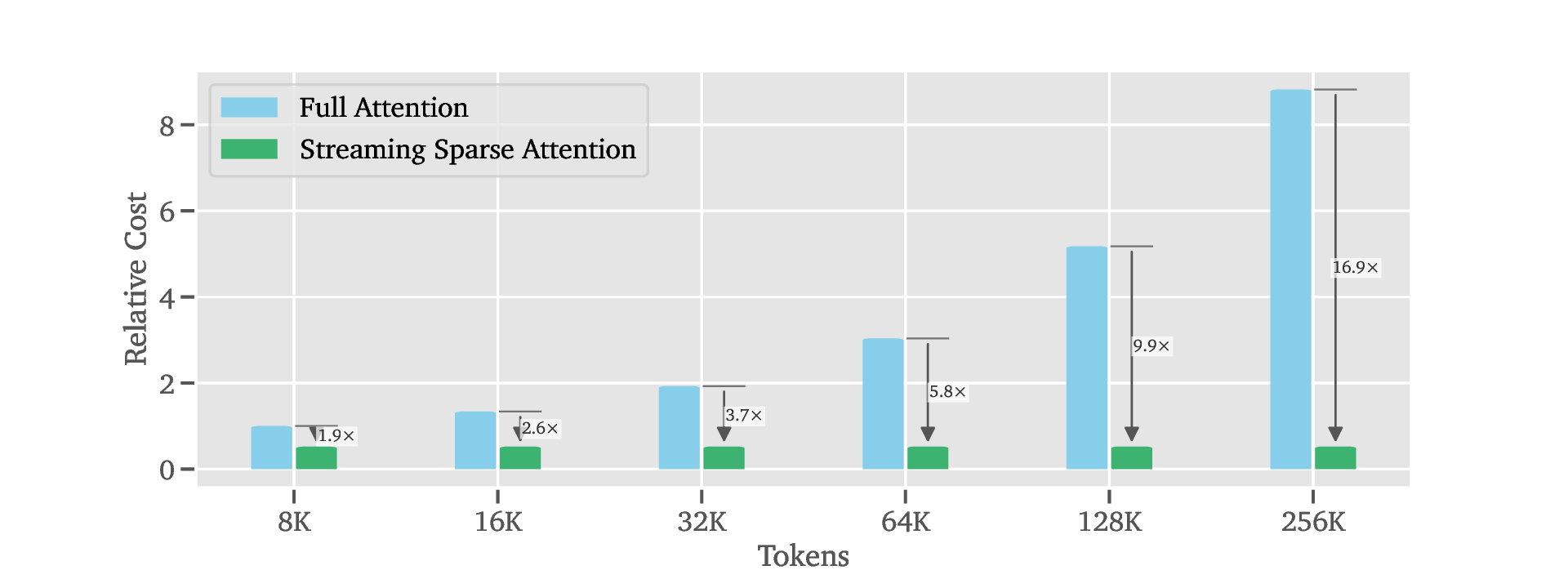
세 번째 단계인 Deployment에서는 LoZA가 적용된 LongCat‑Flash‑Exp가 1백만 토큰까지 연속적으로 스트리밍될 수 있다. 이는 기존 모델이 8K~32K 토큰을 상한으로 삼던 것에 비해 30배 이상 확장된 것이다. 실제 응용 사례로는 검색 기반 생성(RAG)에서 대규모 문서 컬렉션을 한 번에 인코딩해 빠른 응답을 제공하거나, 도구 연동 추론에서 복잡한 작업 흐름을 장기 메모리와 결합해 에이전트가 지속적인 계획을 수행하도록 하는 것이 가능하다.
LoZA의 핵심 강점은 “모듈식 전환”이다. 기존 LM 아키텍처에 최소한의 코드 변경만으로 희소 어텐션 모듈을 삽입할 수 있어, 연구자와 엔지니어가 기존 파이프라인을 크게 재구성하지 않아도 된다. 또한, LoZA는 기존 MoE 기반 모델과도 자연스럽게 호환되며, MLA와 SSA의 장점을 동시에 활용해 스트리밍 상황에서도 높은 정확도와 낮은 지연 시간을 유지한다. 다만, 희소 패턴 선택 과정에서 초기 샘플링 품질에 따라 최종 성능이 좌우될 수 있으므로, Calibration 단계의 데이터 다양성 확보와 하이퍼파라미터 튜닝이 중요하다. 전반적으로 LoZA는 장문 처리에 필요한 연산·메모리 효율성을 크게 개선하면서도, 기존 전면 어텐션 모델이 제공하던 표현력과 추론 능력을 유지하는 실용적인 솔루션이라 할 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리