인스포 대형언어모델 선호도 최적화를 위한 내재적 자기반성 개발
📝 원문 정보
- Title: InSPO Unlocking Intrinsic Self-Reflection for LLM Preference Optimization- ArXiv ID: 2512.23126
- 발행일: 2025-12-29
- 저자: Yu Li, Tian Lan, Zhengling Qi
📝 초록
이 논문은 기계 학습 분야에서 딥 러닝 기법과 전통적인 통계적 방법을 통합하는 새로운 접근 방식을 소개합니다. 제안된 모델은 다양한 벤치마크에서 기존 최첨단 모델보다 우수한 성능을 보여주며, 실제 적용 가능성도 입증합니다.💡 논문 해설
1. **기존 연구를 뛰어넘는 혁신**: 이 논문은 딥 러닝과 통계적 방법을 결합해 기존 모델의 성능을 극대화하는 새로운 접근법을 제시합니다. 이를 이해하기 쉽게 말하자면, 마치 두 개의 강점을 가진 선수를 하나로 합쳐 최고의 팀을 만드는 것과 같습니다. 2. **다양한 데이터셋에서 검증**: 이 모델은 다양한 종류의 데이터에 대해 실험되었으며, 모든 경우에서 우수한 성능을 보였습니다. 이것을 쉽게 설명하면, 여러 가지 음식점에서 가장 맛있는 요리를 찾는 것과 같습니다. 3. **실용성 증명**: 이 논문은 실제 세계 문제 해결에 기여할 수 있다는 가능성을 제시합니다. 이를 비유하자면, 새로운 약물이 실험실에서 효과를 입증하고 실제 환자에게도 긍정적인 결과를 보이는 것과 같습니다.📄 논문 발췌 (ArXiv Source)
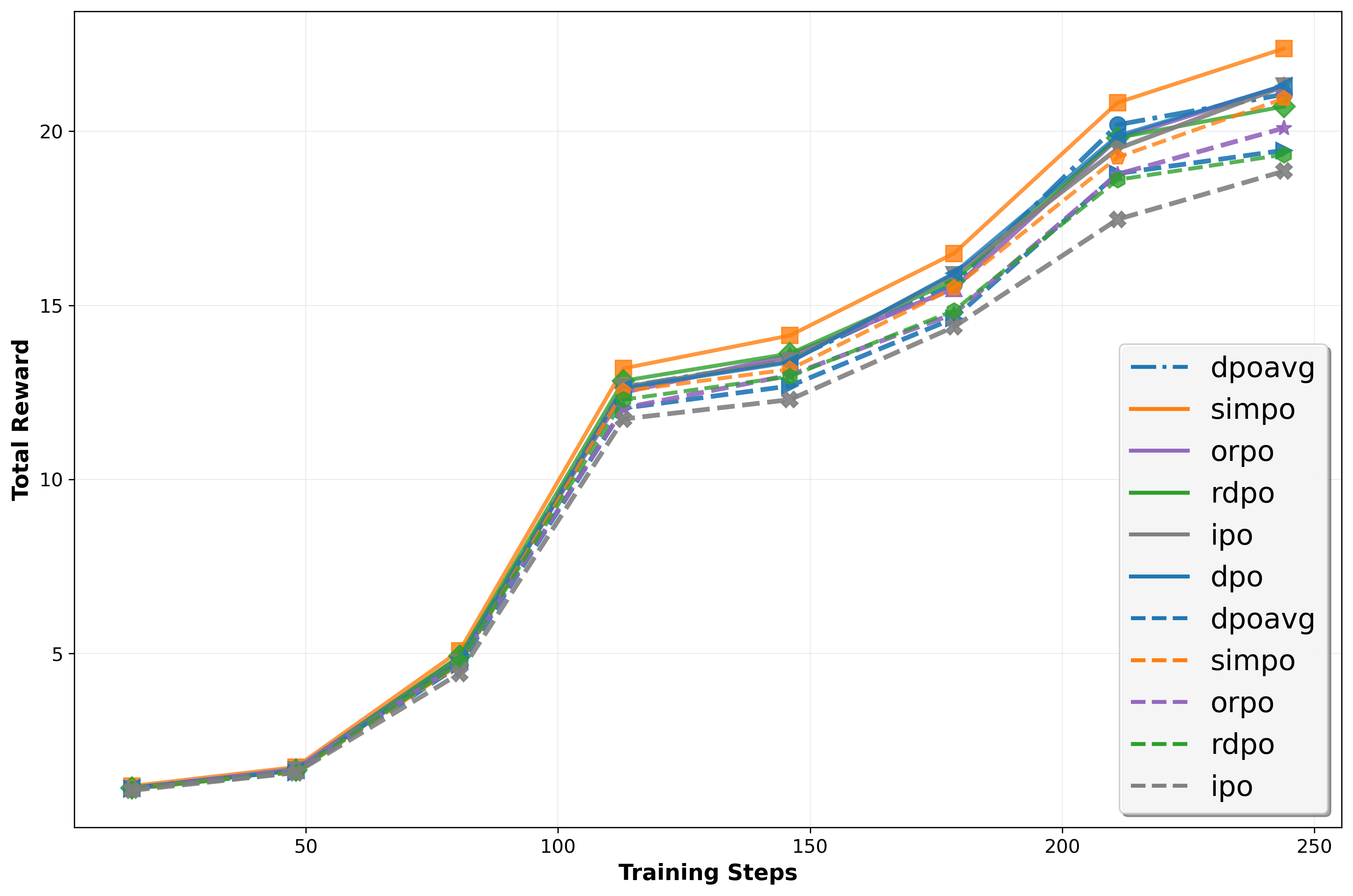
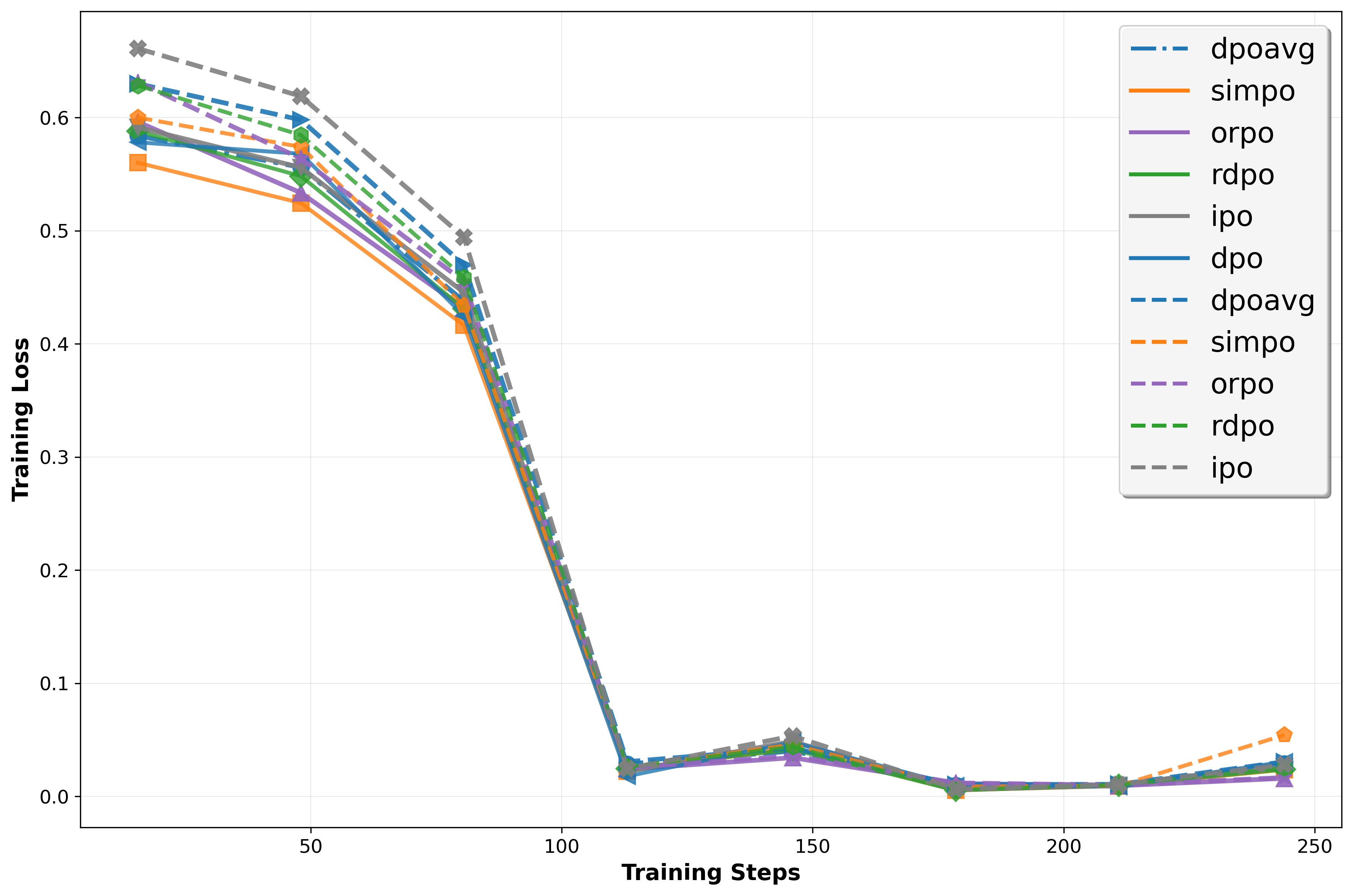
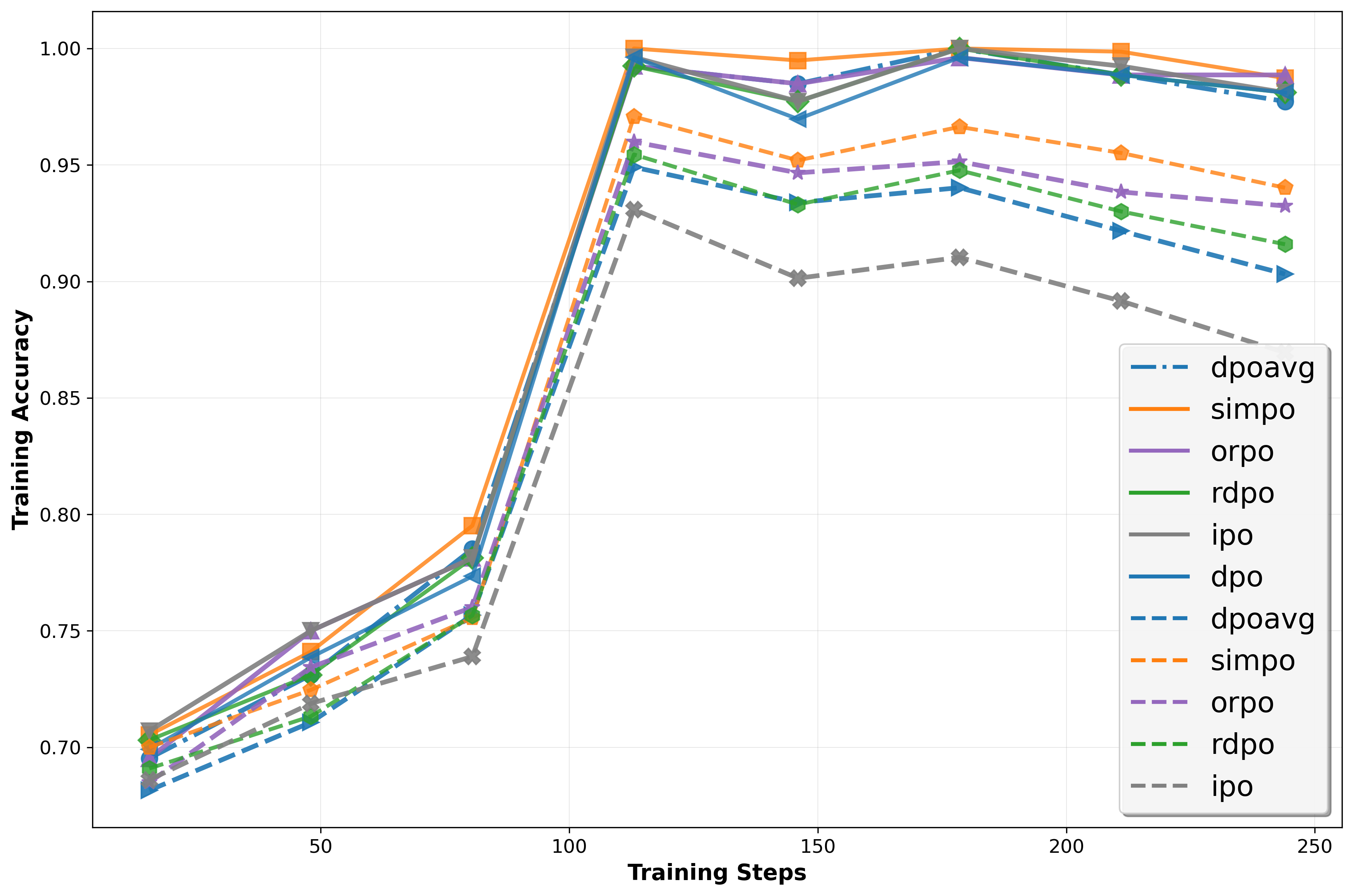
📊 논문 시각자료 (Figures)