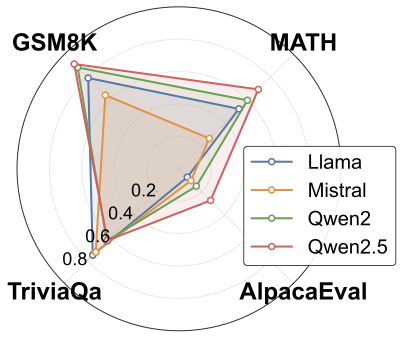
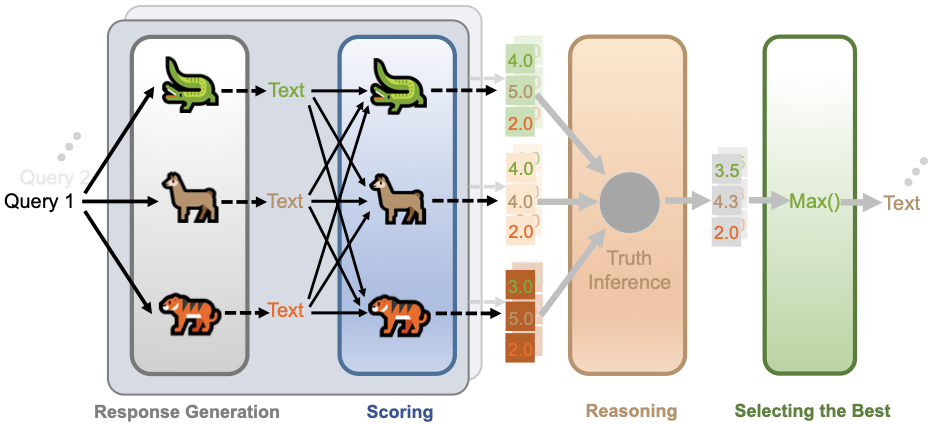
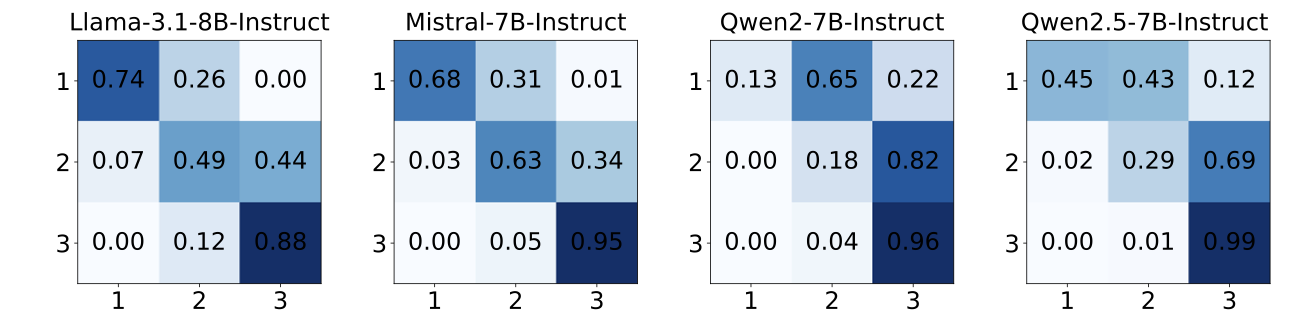
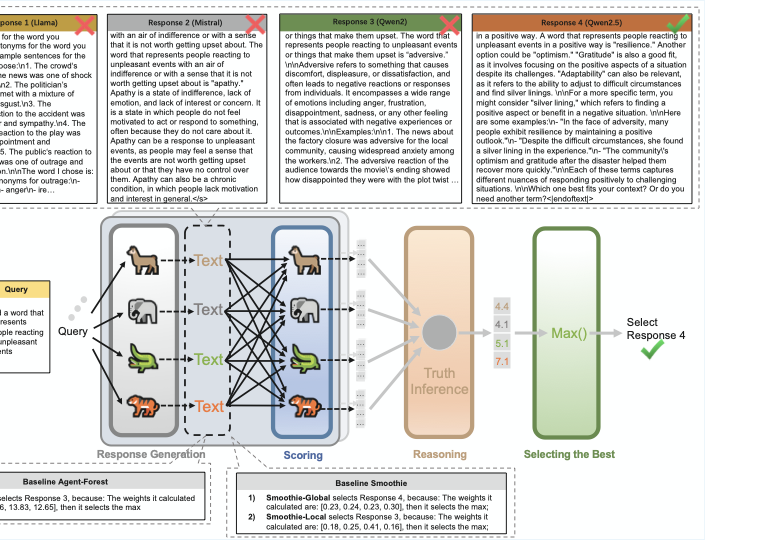
LLM 피어리뷰 최고 응답 선발 시스템
📝 원문 정보
- Title: Scoring, Reasoning, and Selecting the Best! Ensembling Large Language Models via a Peer-Review Process- ArXiv ID: 2512.23213
- 발행일: 2025-12-29
- 저자: Zhijun Chen, Zeyu Ji, Qianren Mao, Junhang Cheng, Bangjie Qin, Hao Wu, Zhuoran Li, Jingzheng Li, Kai Sun, Zizhe Wang, Yikun Ban, Zhu Sun, Xiangyang Ji, Hailong Sun
📝 초록
이 논문은 다양한 데이터셋을 사용하여 세 가지 다른 CNN 기반 학습 방식을 체계적으로 비교한다. 이 연구는 커스텀 모델, 트랜스퍼 러닝 및 사전 훈련된 모델의 성능을 분석하고, 각 방법이 어떤 상황에서 가장 효과적임을 알아본다.💡 논문 해설
1. **기여 1: 체계적인 비교** - 이 연구는 다양한 데이터셋에 대한 세 가지 학습 방식의 성능을 정확하게 측정함으로써, 어떤 상황에서 각 방법이 가장 효과적인지 명확히 한다. 2. **기여 2: 실제 적용 가능성 향상** - 트랜스퍼 러닝과 사전 훈련된 모델의 성능을 분석하여, 작은 규모의 데이터셋에서도 효과적으로 AI를 활용하는 방법을 제시한다. 3. **기여 3: 최적화 전략 개발** - 커스텀 모델과 트랜스퍼 러닝의 비교는, 특정 상황에 따라 어떤 학습 방식이 더 효율적인지 알아내는 최적화 전략을 제시한다.📄 논문 발췌 (ArXiv Source)
📊 논문 시각자료 (Figures)