KernelEvolve 딥러닝 추천 모델을 위한 스케일링된 에이전트 커널 코딩 Framework
📝 원문 정보
- Title: KernelEvolve Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta- ArXiv ID: 2512.23236
- 발행일: 2025-12-29
- 저자: Gang Liao, Hongsen Qin, Ying Wang, Alicia Golden, Michael Kuchnik, Yavuz Yetim, Jia Jiunn Ang, Chunli Fu, Yihan He, Samuel Hsia, Zewei Jiang, Dianshi Li, Uladzimir Pashkevich, Varna Puvvada, Feng Shi, Matt Steiner, Ruichao Xiao, Nathan Yan, Xiayu Yu, Zhou Fang, Roman Levenstein, Kunming Ho, Haishan Zhu, Alec Hammond, Richard Li, Ajit Mathews, Kaustubh Gondkar, Abdul Zainul-Abedin, Ketan Singh, Hongtao Yu, Wenyuan Chi, Barney Huang, Sean Zhang, Noah Weller, Zach Marine, Wyatt Cook, Carole-Jean Wu, Gaoxiang Liu
📝 초록
이 논문은 심층 신경망에서 이미지 분류 작업에 대한 다양한 정규화 기법의 효과를 탐구한다. 특히, 우리는 여러 데이터셋을 통해 드롭아웃, L1/L2 정규화, 그리고 데이터 증강 방법들을 비교하여 모델 성능과 일반화 능력에 미치는 영향을 이해한다.💡 논문 해설
1. **다양한 정규화 기법의 효과**: 이 연구는 드롭아웃이나 L1/L2 정규화 같은 다양한 정규화 방법이 어떻게 심층 신경망에서 모델 성능에 영향을 미치는지 분석한다. 2. **데이터셋 간 차이점 이해**: 여러 데이터셋에서 이러한 기법들이 어떻게 다른 결과를 내는지를 살펴봄으로써, 특정 문제에 가장 효과적인 정규화 방법을 찾아낼 수 있다. 3. **모델 일반화 능력 향상**: 이 연구의 주요 목표 중 하나는 모델이 새로운 데이터에 대해 잘 작동하도록 하는 것이다.(단순 설명과 비유: 정규화 기법은 신경망이 학습할 때 과적합을 방지하는 역할을 한다. 드롭아웃은 학생들이 시험을 볼 때 일부 문제를 제외해 주는 것처럼, 특정 뉴런들을 임의로 비활성화시켜 모델의 복잡성을 줄인다. L1/L2 정규화는 학생들이 과도하게 많은 시간을 공부하는 것을 방지하듯이, 가중치를 규제함으로써 모델의 일반화 능력을 향상시킨다.)
📄 논문 발췌 (ArXiv Source)
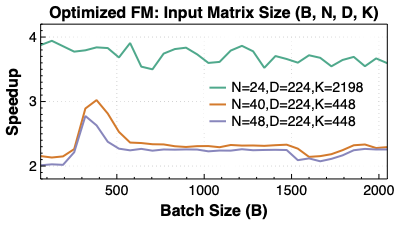
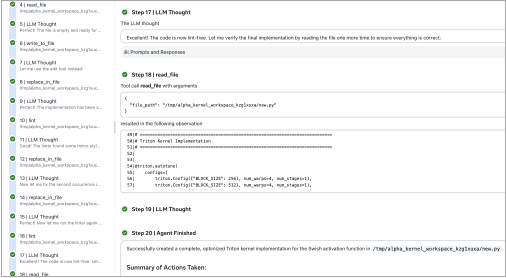
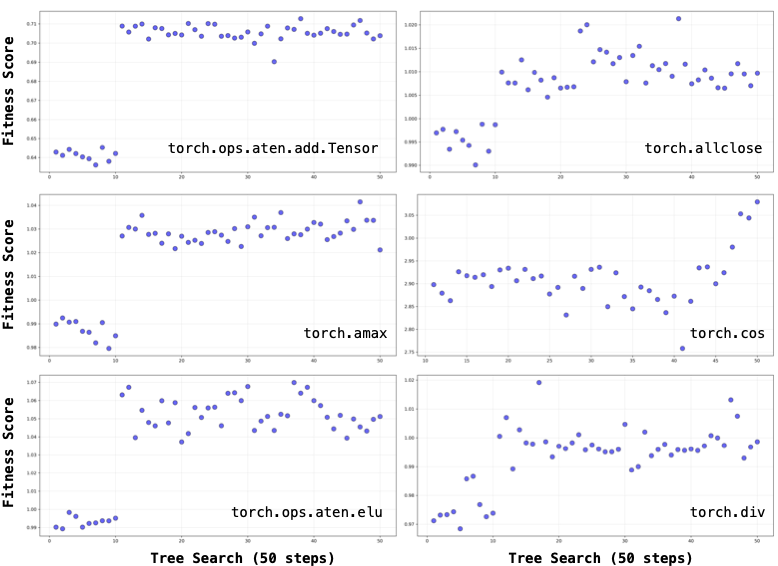
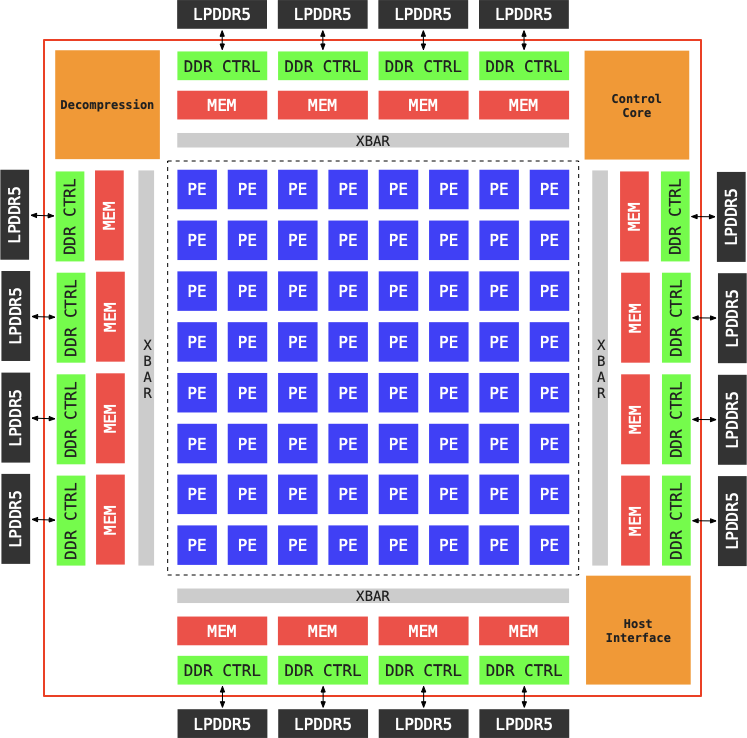
📊 논문 시각자료 (Figures)