알파-R1 강화학습을 통한 LLM 추론으로 이루어진 알파 필터링
📝 원문 정보
- Title: Alpha-R1 Alpha Screening with LLM Reasoning via Reinforcement Learning- ArXiv ID: 2512.23515
- 발행일: 2025-12-29
- 저자: Zuoyou Jiang, Li Zhao, Rui Sun, Ruohan Sun, Zhongjian Li, Jing Li, Daxin Jiang, Zuo Bai, Cheng Hua
📝 초록
기계 학습의 급속한 발전은 의료 분야에 새로운 진단과 치료 방법을 제공하고 있습니다. 이 리뷰는 의료 애플리케이션에서 사용되는 다양한 기계 학습 기법, 특히 감독 학습, 비감독 학습 및 강화 학습 방법을 탐색합니다. 각 기법의 장점과 한계를 분석하고 미래 방향성을 제시합니다.💡 논문 해설
1. **기계 학습의 의료 적용**: 기계 학습은 대규모 데이터 처리에 뛰어나며, 이는 의료 데이터에서 중요한 패턴을 찾는 데 유용합니다. 이를 간단히 설명하자면, 기계 학습이 의료 분야에서는 병원의 의사와 같은 역할을 하는 것이라고 할 수 있습니다. 2. **감독 학습과 비감독 학습**: 감독 학습은 정답이 있는 데이터에서 학습하며, 비감독 학습은 정답 없는 데이터에서도 유용합니다. 이는 마치 기계가 스스로 문제를 해결하는 방법을 배우는 것과 같습니다. 3. **강화 학습의 미래 가능성**: 강화 학습은 반복적인 피드백을 통해 최적의 치료 계획을 찾는데 효과적이며, 미래에는 더 많은 적용이 예상됩니다.📄 논문 발췌 (ArXiv Source)
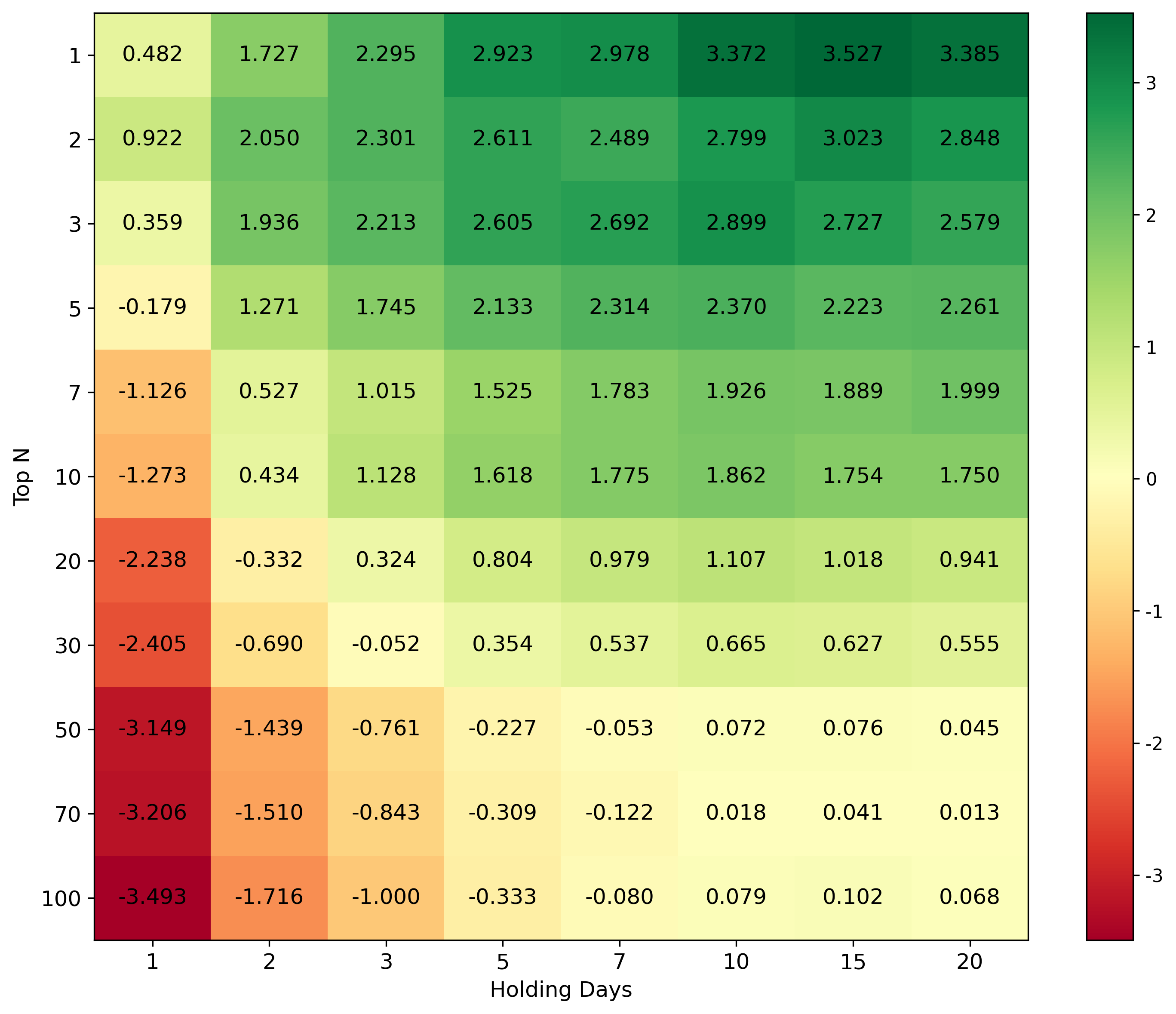
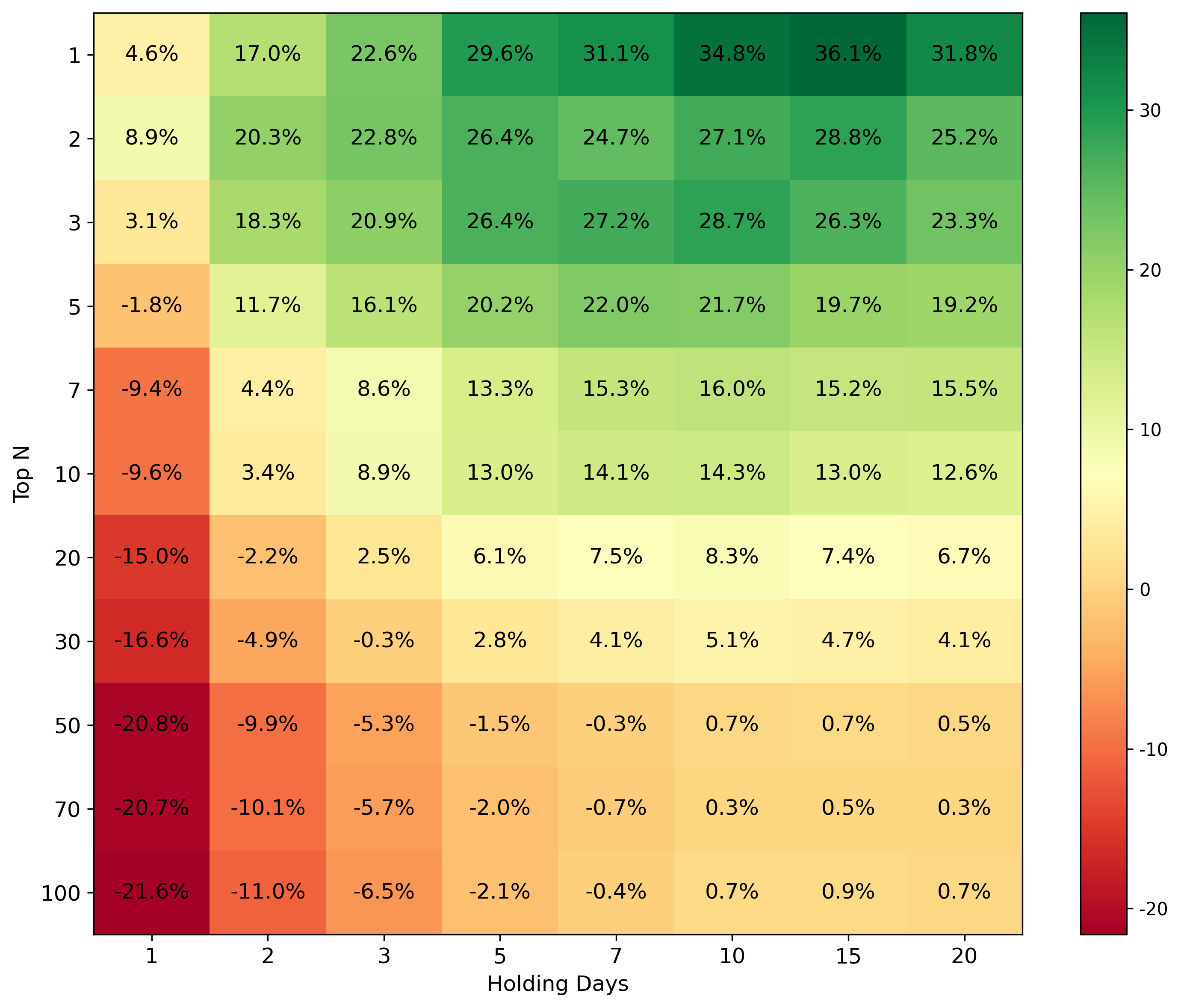
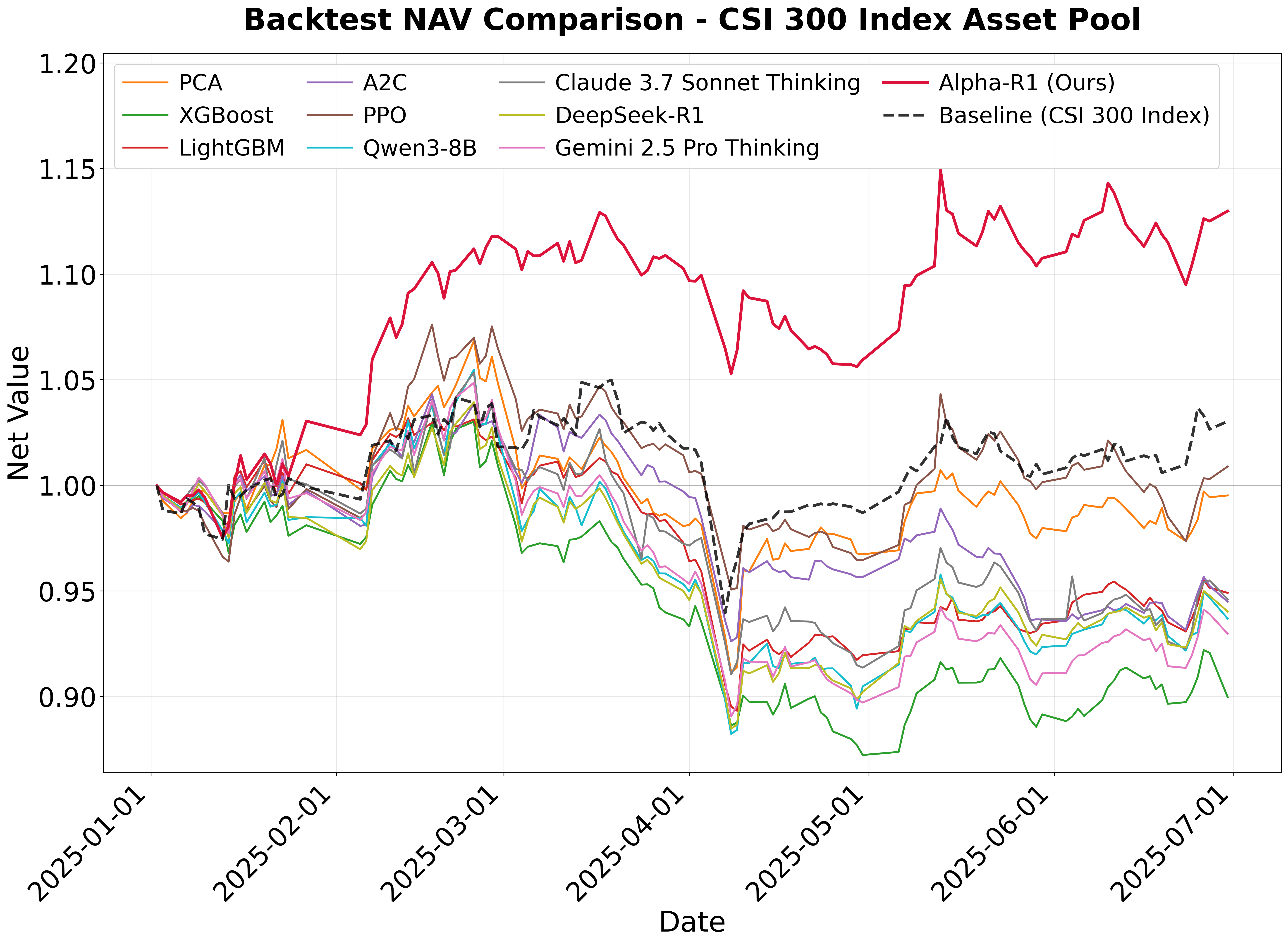
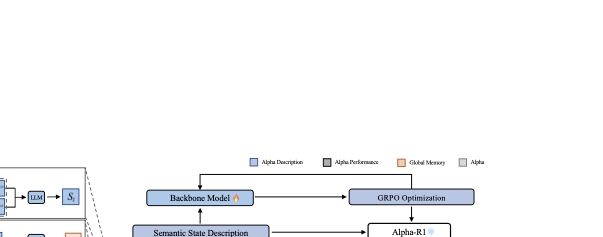
📊 논문 시각자료 (Figures)