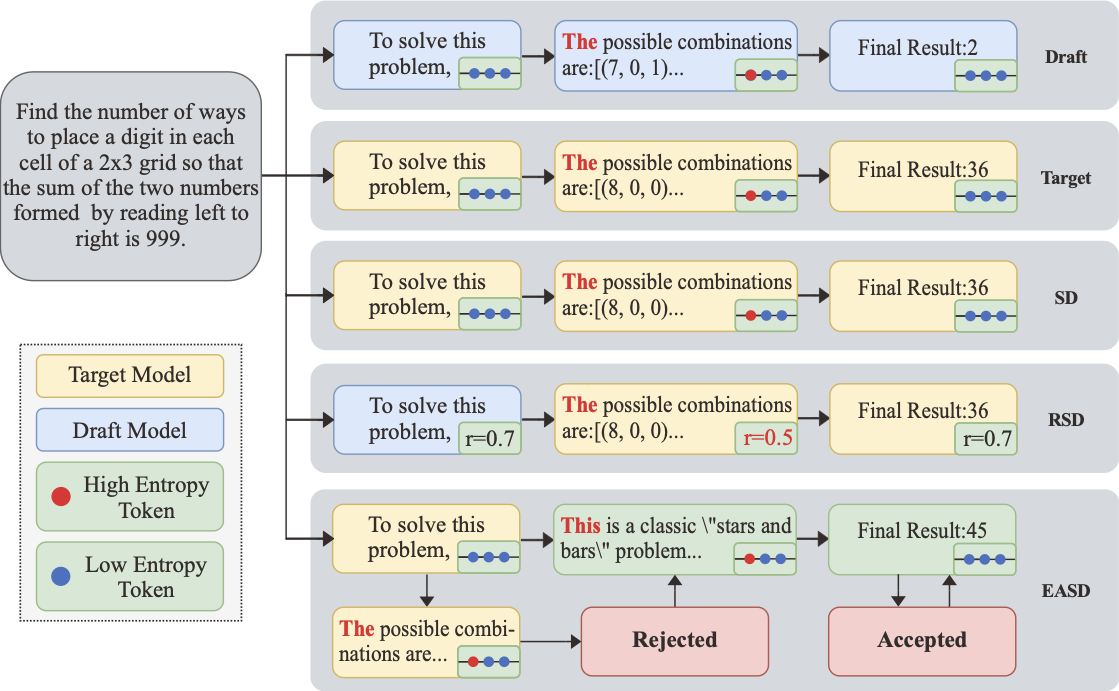
엔트로피 인식 예측 디코딩으로 향상된 대형 언어 모델 추론
📝 원문 정보
- Title: Entropy-Aware Speculative Decoding Toward Improved LLM Reasoning- ArXiv ID: 2512.23765
- 발행일: 2025-12-29
- 저자: Tiancheng Su, Meicong Zhang, Guoxiu He
📝 초록
이 연구는 다양한 데이터셋에서 서로 다른 학습 방법이 CNN 성능에 미치는 영향을 조사합니다. 커스텀 모델 생성, 트랜스퍼 러닝, 사전 훈련된 모델의 파인튜닝 등 세 가지 패러다임을 비교했습니다. 결과적으로 각 방법은 강점이 있지만, 트랜스퍼 러닝이 정확성과 계산 효율성을 가장 잘 균형 있게 제공한다는 것을 나타냅니다.💡 논문 해설
1. **컨트리뷰션 1**: 커스텀 모델 생성의 장단점을 이해하고, 트랜스퍼 러닝 및 파인튜닝 방법이 얼마나 효율적인지 설명합니다. 2. **컨트리뷰션 2**: 데이터셋에 따라 각 학습 방법의 성능 차이를 분석하며, 다양한 환경에서 최적의 선택을 제시합니다. 3. **컨트리부션 3**: CNN 아키텍처 수정과 평가 지표 적용 방식을 설명합니다.간단한 설명 및 비유:
- 커스텀 모델 생성은 집에서 직접 만드는 건축물처럼, 완벽하게 맞춤화할 수 있지만 시간과 자원이 많이 듭니다. (고급)
- 트랜스퍼 러닝은 이미 만들어진 건물을 바탕으로 필요한 부분만 수정하는 것처럼, 효율적이지만 전체적인 설계는 기존에 의존합니다. (중급)
- 파인튜닝은 가구를 교체하거나 내부 디자인을 변경하는 수준의 수정을 의미하며, 트랜스퍼 러닝보다 좀 더 세밀한 조정이 가능합니다. (초급)
Sci-Tube 스타일 스크립트: “오늘은 CNN 학습 방법 3가지를 비교해보겠습니다! 커스텀 모델 생성, 트랜스퍼 러닝, 파인튜닝 중 어떤 게 가장 효과적일까요? 각 방법의 장단점과 실제 데이터셋에서 어떻게 적용되는지 자세히 살펴볼게요.”
📄 논문 발췌 (ArXiv Source)
📊 논문 시각자료 (Figures)