.sb-트르포 엄격한 안전 제약 조건을 갖춘 안전 강화 학습으로의 진보
📝 원문 정보
- Title: SB-TRPO Towards Safe Reinforcement Learning with Hard Constraints- ArXiv ID: 2512.23770
- 발행일: 2025-12-29
- 저자: Ankit Kanwar, Dominik Wagner, Luke Ong
📝 초록
본 연구는 딥러닝 모델이 자연어 처리 작업에 미치는 영향을 조사했습니다. 특히 우리는 감성 분석에서 다양한 하이퍼파라미터가 어떻게 모델 성능에 영향을 미치는지 살펴보았습니다. 우리의 결과는 특정 하이퍼파라미터 조합이 디폴트 설정보다 훨씬 높은 정확도를 제공할 수 있음을 시사합니다.💡 논문 해설
1. **키 컨트리뷰션 1:** 다양한 하이퍼파라미터 조합을 통해 모델 성능 개선에 대한 이해가 깊어졌습니다. 이는 마치 요리를 할 때 재료의 양과 온도를 정확히 조절함으로써 맛있는 음식을 만드는 것과 같습니다. 2. **키 컨트리뷰션 2:** 딥러닝 아키텍처(LSTM, GRU, BERT) 간 비교가 이루어져 각 모델의 장단점을 파악할 수 있었습니다. 이는 각 요리를 만들 때 가장 적합한 도구를 선택하는 것과 비슷합니다. 3. **키 컨트리뷰션 3:** 감성 분석 작업에 대한 새로운 인사이트를 제공했습니다. 이는 영화 리뷰에서 긍정적인 표현을 식별함으로써 관객의 반응을 이해하는 것과 같습니다.📄 논문 발췌 (ArXiv Source)
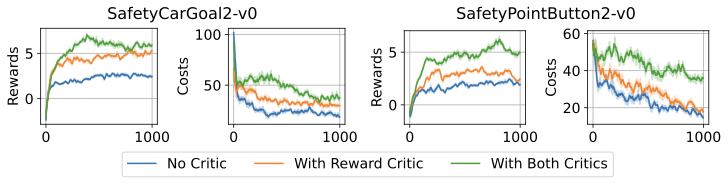
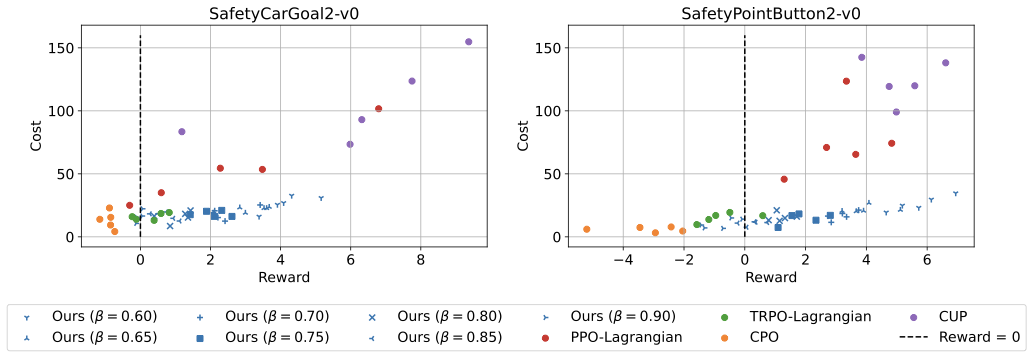
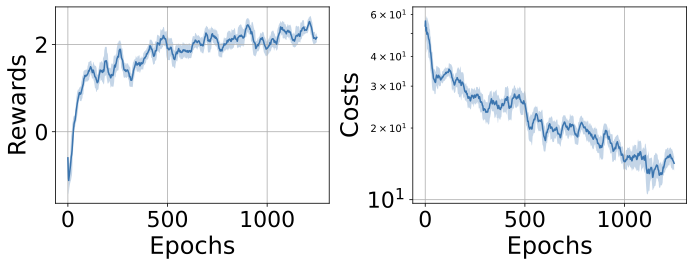
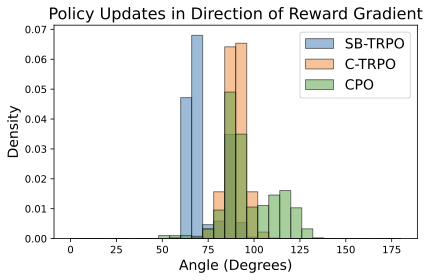
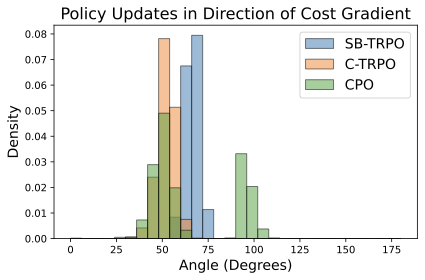
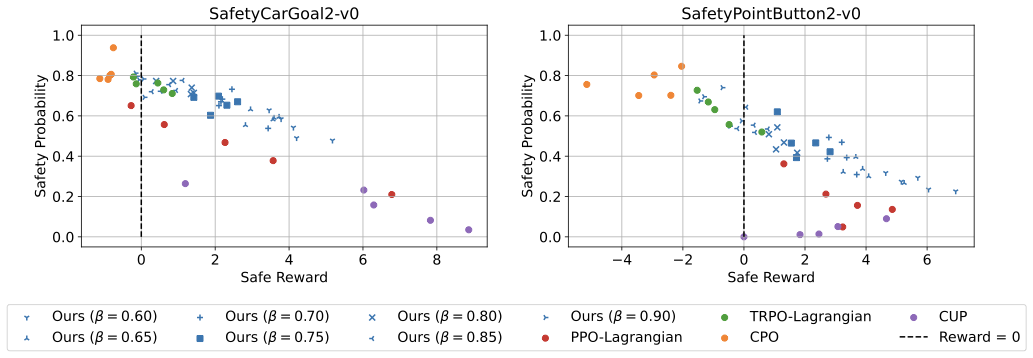
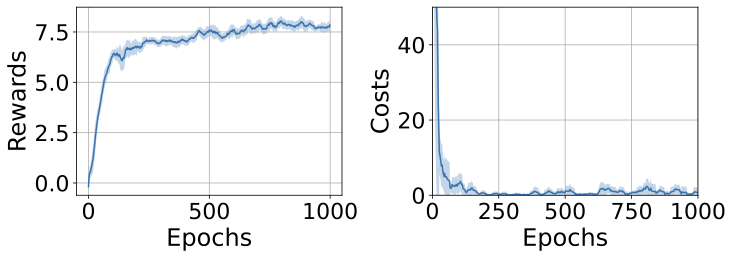
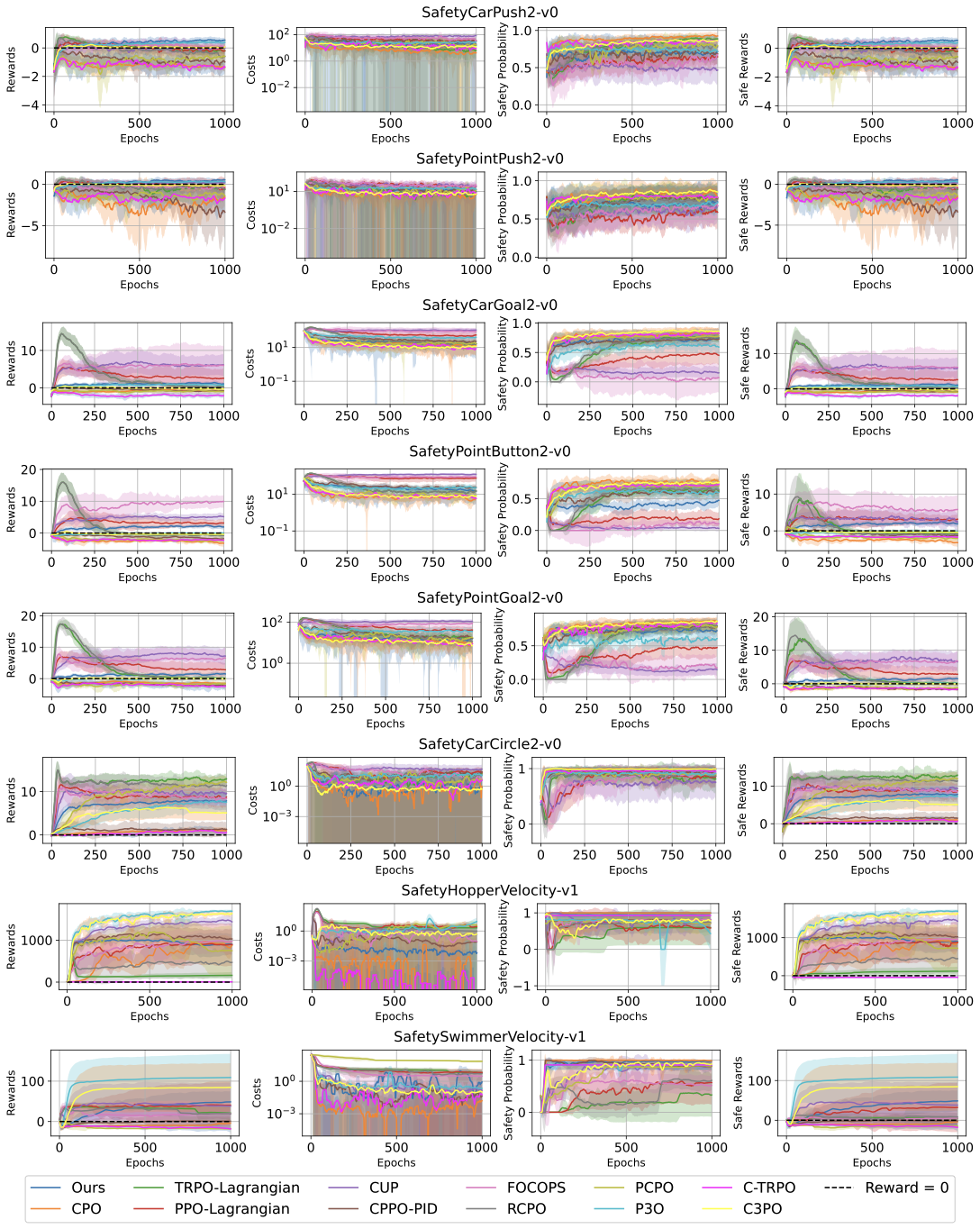
📊 논문 시각자료 (Figures)