대형언어모델의 과다생성 블랙박스 공격 벤치마크
📝 원문 정보
- Title: Prompt-Induced Over-Generation as Denial-of-Service A Black-Box Attack-Side Benchmark- ArXiv ID: 2512.23779
- 발행일: 2025-12-29
- 저자: Manu, Yi Guo, Kanchana Thilakarathna, Nirhoshan Sivaroopan, Jo Plested, Tim Lynar, Jack Yang, Wangli Yang
📝 초록
이 연구는 강화학습 알고리즘의 성능을 향상시키기 위해 사용되는 다양한 기법들을 체계적으로 분석하고 비교합니다. 본 논문에서는 다섯 가지 주요 기법, 즉 엡실론 탐욕 정책(Epsilon-Greedy Policy), 소프트맥스 정책(Softmax Policy), 오퍼레이터 학습(Operator Learning), 모델 기반 강화학습(Model-Based Reinforcement Learning), 그리고 적응적 학습률(Adaptive Learning Rate)을 검토합니다. 이들 방법의 장단점을 실험적으로 평가하고, 다양한 환경에서의 성능을 분석하여 최적의 접근 방식을 제시합니다.💡 논문 해설
1. **이 연구의 첫 번째 기여:** 강화학습 알고리즘에 대한 포괄적인 이해를 제공합니다. 이는 마치 여러 도로 중 가장 빠른 길을 찾는 것과 같습니다. 2. **두 번째 중요한 기여:** 다섯 가지 주요 기법을 실험적으로 평가합니다. 이를 통해 각 방법의 장단점을 명확하게 파악할 수 있습니다. 이는 다양한 날씨와 교통 상황에서 자동차 성능을 테스트하는 것과 유사합니다. 3. **세 번째 중요한 기여:** 가장 효과적인 강화학습 기법을 제시합니다. 이것은 최적의 경로를 찾는 것이 아니라, 가장 빠르고 효율적으로 목적지에 도달할 수 있는 자동차를 선택하는 것과 같습니다.📄 논문 발췌 (ArXiv Source)
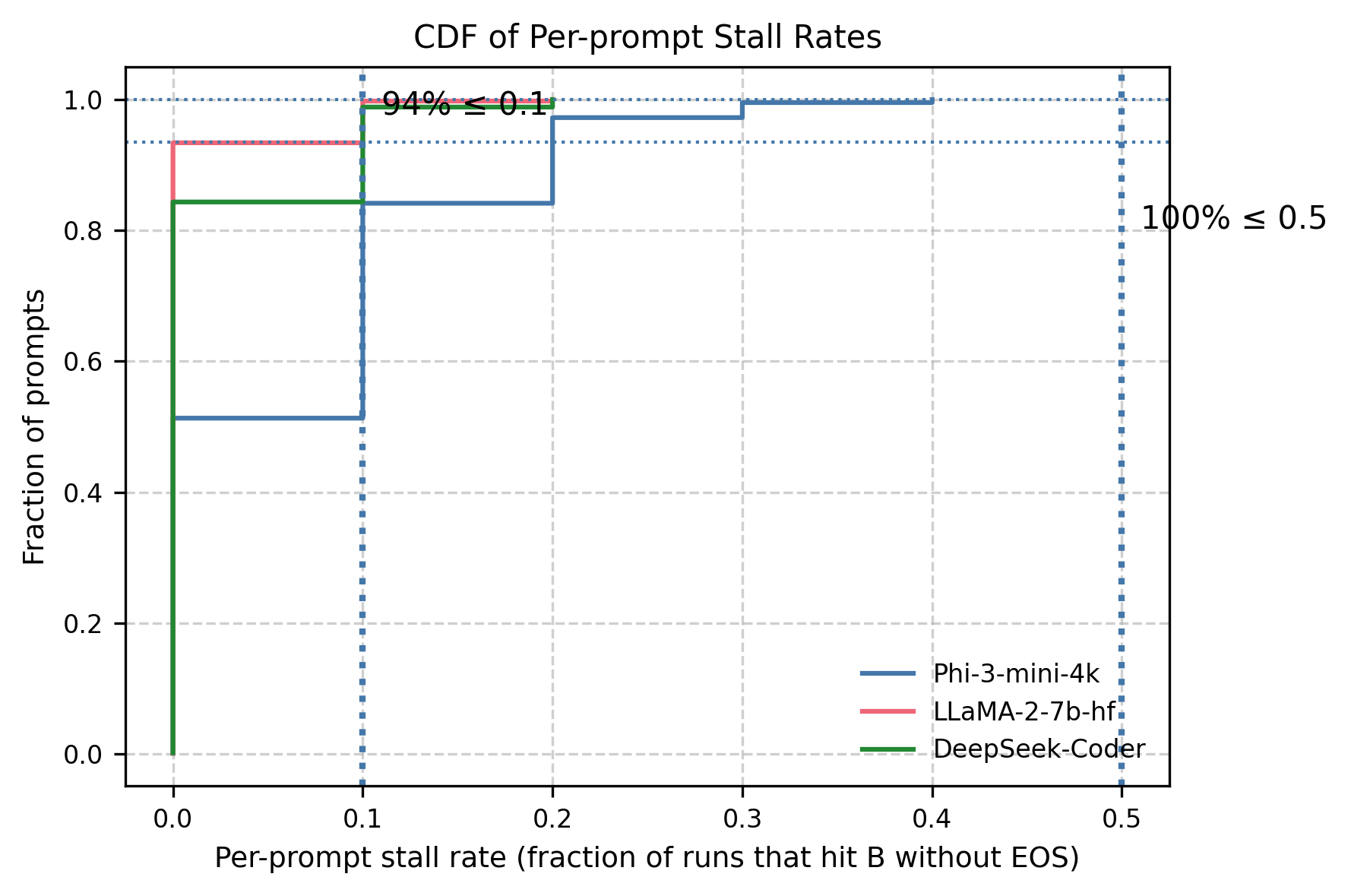
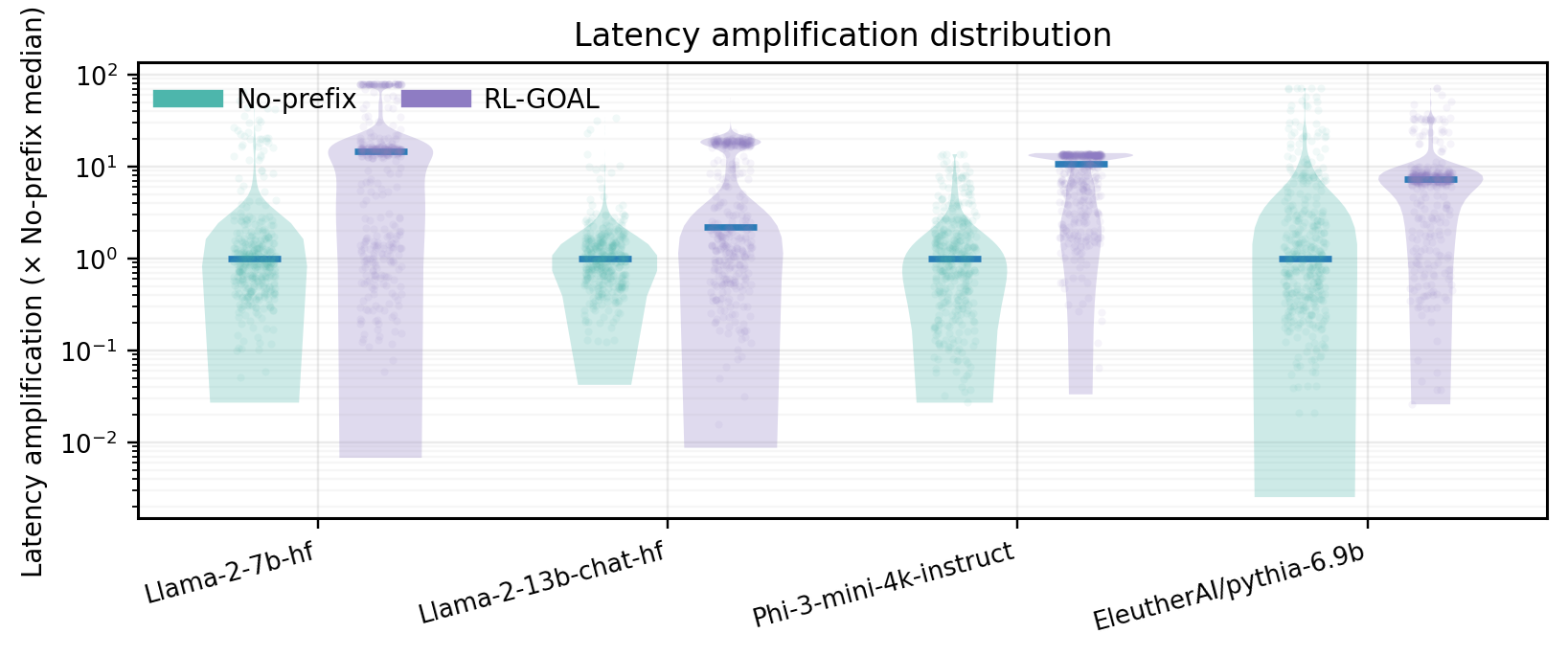
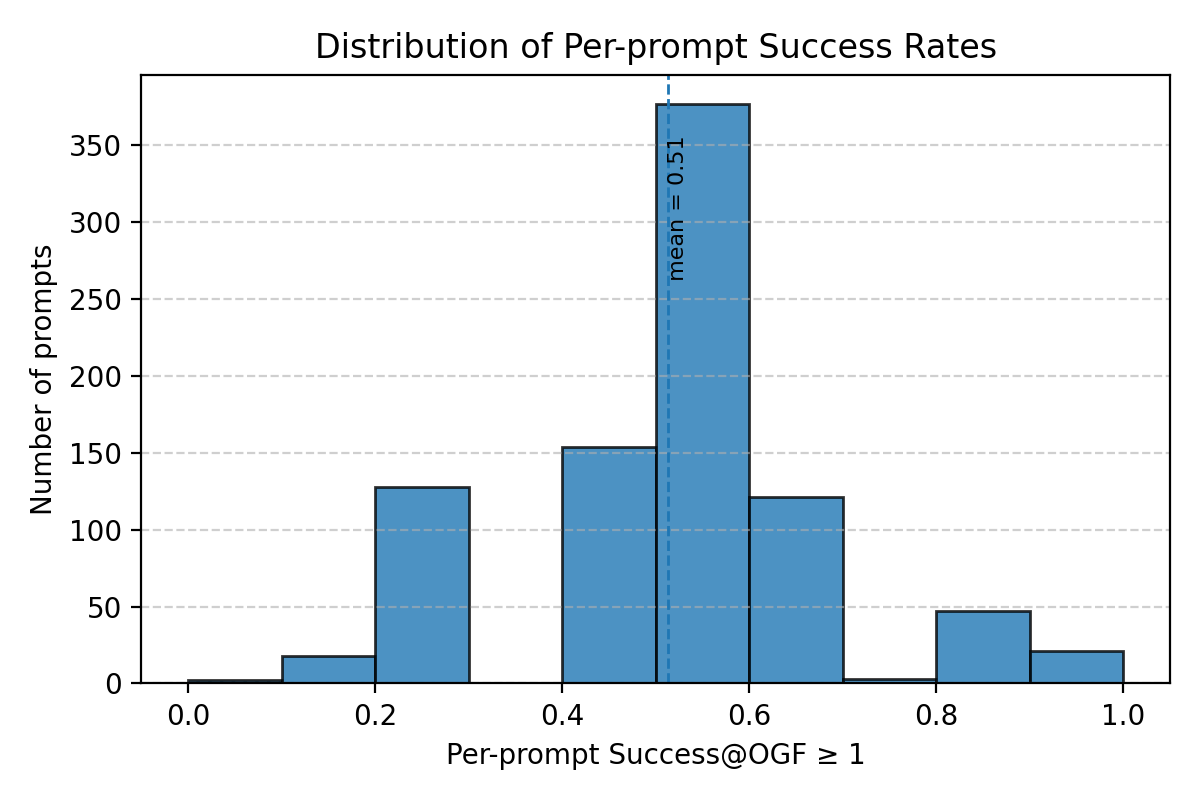
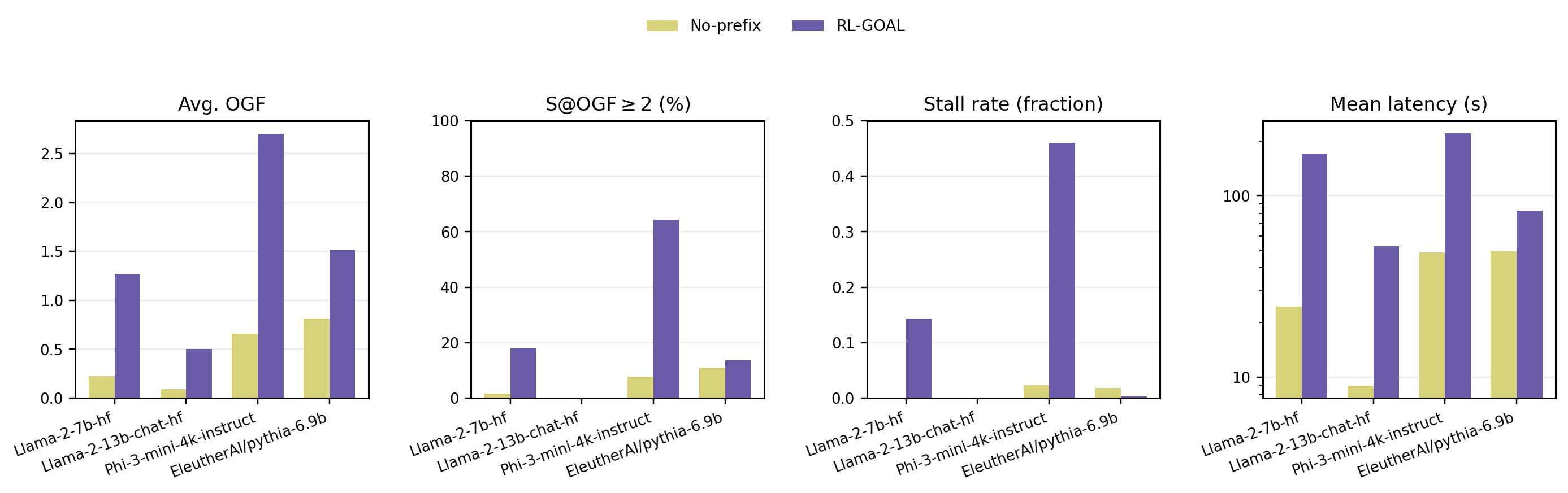
📊 논문 시각자료 (Figures)