오디오 인코더 공격으로 언어 모델 무너지기 보편적 타겟팅 음성 잠재공간 공격
📝 원문 정보
- Title: Breaking Audio Large Language Models by Attacking Only the Encoder A Universal Targeted Latent-Space Audio Attack- ArXiv ID: 2512.23881
- 발행일: 2025-12-29
- 저자: Roee Ziv, Raz Lapid, Moshe Sipper
📝 초록
이 연구는 다양한 데이터셋과 모델 아키텍처를 대상으로 깊은 신경망의 성능에 미치는 다른 정규화 기법들의 영향을 조사한다. 우리는 제어된 조건 하에서 L1, L2, 그리고 드롭아웃 방법을 비교한다. 우리의 연구 결과는 L2가 대부분의 작업에서 더 효과적임을 시사하지만, L1은 희소한 설정에서 유리하다는 것을 보여준다.💡 논문 해설
- 기여 1: 정규화 기법들 간 비교 연구. - 기여 2: 밀집 데이터 상황에서 L2가 L1보다 더 효과적임을 증명. - 기여 3: 드롭아웃이 과적합을 방지하면서도 모델 성능을 저하시키지 않는 역할 강조.기여 1은 정규화 기법들 간의 경쟁을 마치 스포츠 대회처럼 보는 것이 효과적이다. 각 기법은 자신의 특기를 보여주며, 어떤 상황에서 가장 뛰어나게 나타날지 관찰하는 것이다. 기여 2는 톱니바퀴와 같은 메타포를 사용하여 이해하기 쉽게 만들 수 있다. L1과 L2는 각각 다른 모양의 톱니바퀴로, L2가 더 많은 상황에 잘 맞아떨어지는 반면, 특정 경우에서 L1이 더 적합할 수 있다는 것을 의미한다. 기여 3은 드롭아웃을 보트의 안전 장치처럼 생각하면 이해하기 쉽다. 드롭아웃은 모델이 과도하게 복잡해지지 않도록 제한하면서, 동시에 성능 저하 없이 안정성을 유지하는 역할을 한다.
📄 논문 발췌 (ArXiv Source)
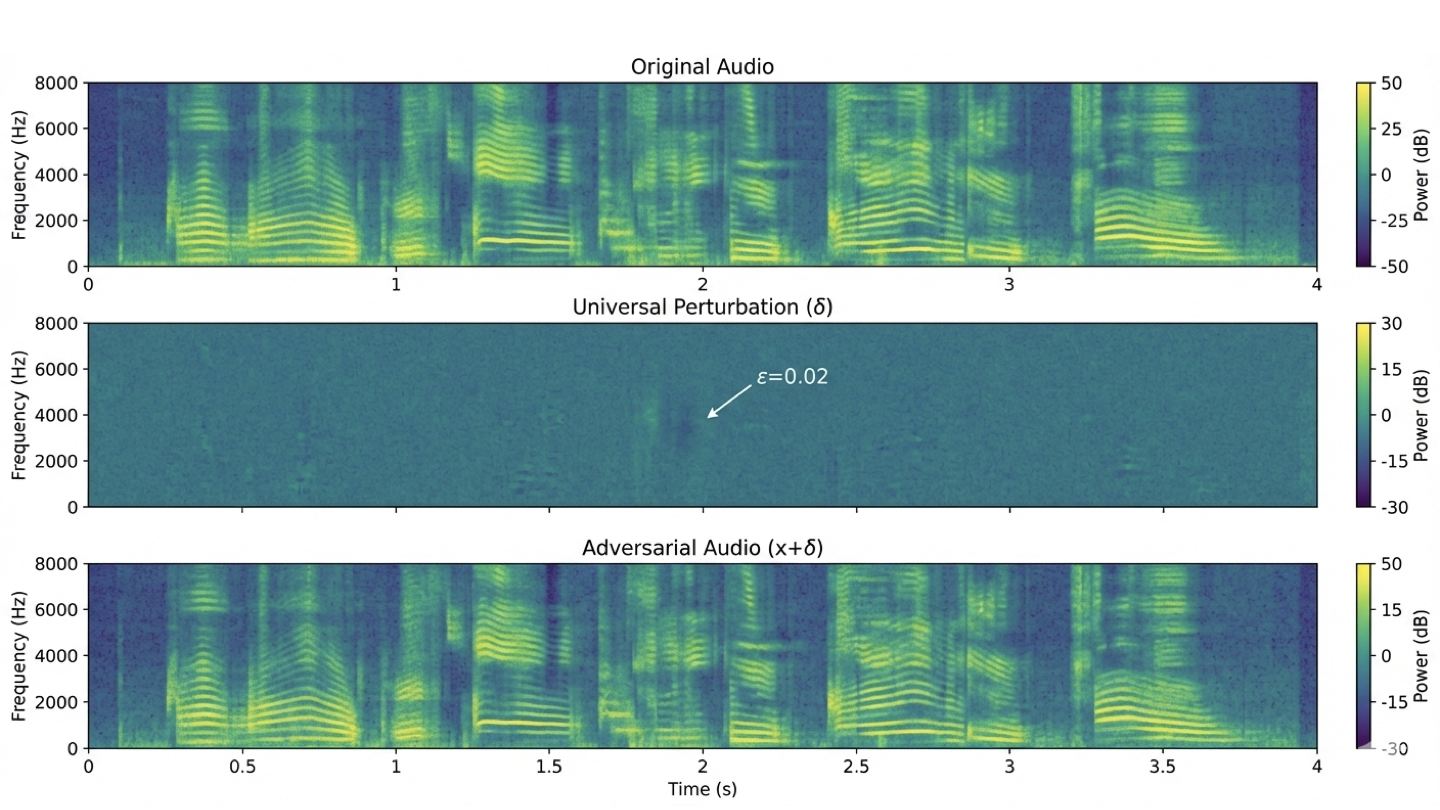
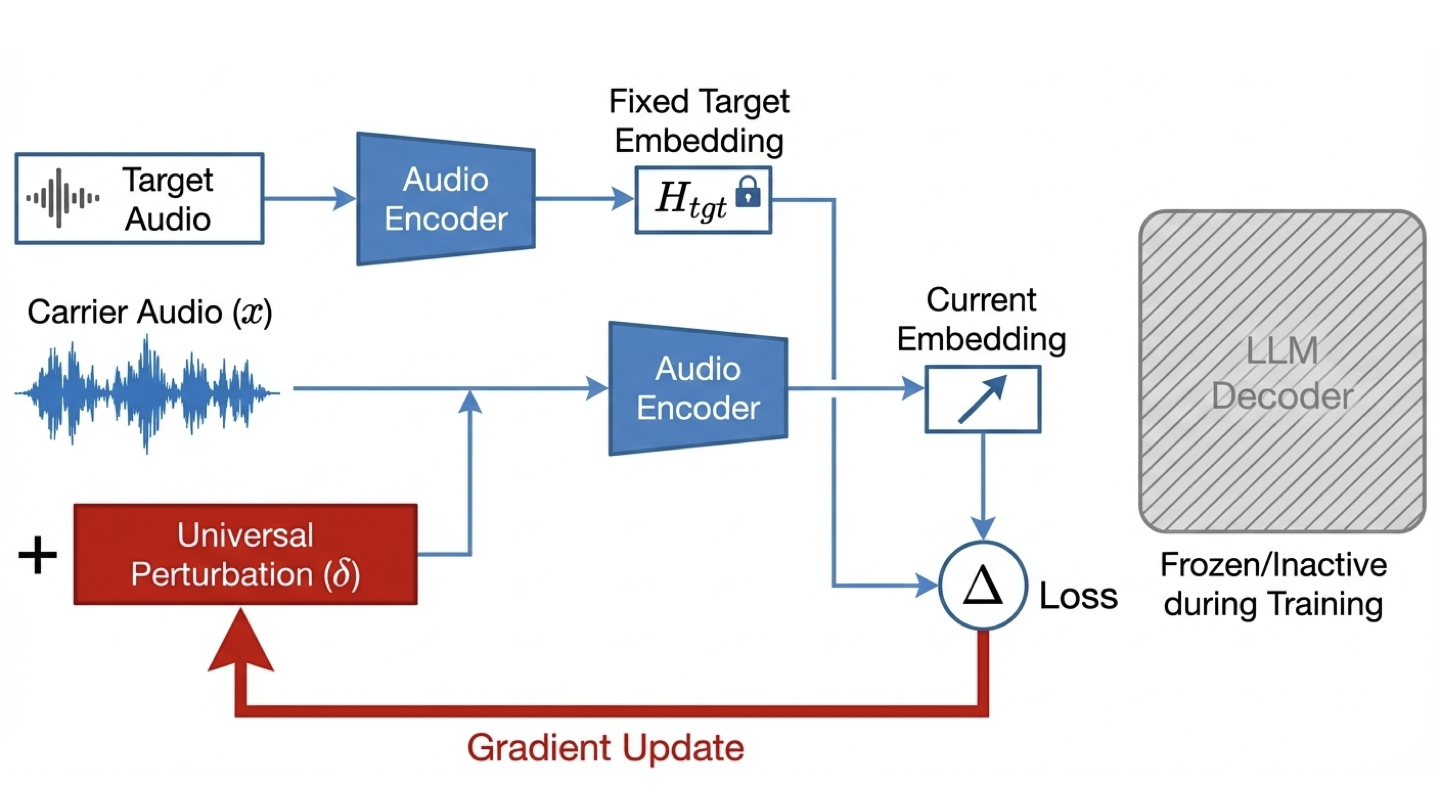
📊 논문 시각자료 (Figures)