- Title: Temporal Attack Pattern Detection in Multi-Agent AI Workflows An Open Framework for Training Trace-Based Security Models
- ArXiv ID: 2601.00848
- 발행일: 2025-12-29
- 저자: Ron F. Del Rosario
📝 초록
본 논문은 에이전트 워크플로의 보안성을 평가하는 첫 번째 공개된 방법론을 제시합니다. 이 방법론은 합성 OpenTelemetry 추적 생성, 데이터셋 구축, 훈련 구성 및 재현 가능한 평가 프로토콜을 포함하며, 에이전트 워크플로의 보안성을 향상시키는 데 중점을 두고 있습니다.
💡 논문 해설
1. **첫 번째 공개 방법론** - 이 논문은 첫 번째로 에이전트 워크플로의 보안성에 초점을 맞춘 언어 모델 미세 조정 방법론을 제시합니다. 이를 통해 보안 문제를 식별하고 예방할 수 있습니다. 이는 마치 자동차에서 블랙박스가 운전자와 차량의 행동을 기록하듯이, 에이전트 워크플로의 모든 단계를 추적하여 위험한 패턴을 발견하는 역할을 합니다.
데이터셋 구축 및 합성 추적 생성 - 본 논문은 다양한 공개 보안 데이터셋과 합성 OpenTelemetry 추적을 결합하여 에이전트 워크플로의 위험한 패턴을 식별할 수 있는 데이터셋을 만듭니다. 이는 마치 경찰이 사건 현장에서 증거를 수집하고 분석하듯이, 다양한 정보를 모아서 보안 위협을 파악하는 과정입니다.
리소스 효율적인 미세 조정 - 저자들은 ARM64 하드웨어와 QLoRA로 학습을 진행하여 상대적으로 적은 리소스로도 큰 성능 향상을 이뤄냈습니다. 이는 마치 작은 배가 빠르게 항해할 수 있도록 최적화된 설계를 갖춘 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
# 들어가며
현재의 LLM 보안 메커니즘은 개별 텍스트 생성을 평가하지만, 여러 단계 에이전트 워크플로에서 발생하는 악성 패턴을 감지하지 못합니다. ‘디렉토리 내용 열거’와 같은 무해한 행동도 더 큰 공격 체인의 탐색일 수 있습니다. 에이전트 시스템은 다중 에이전트 조정 공격, 숨겨진 권한 상승, 규제 위반과 같이 집합적인 행동을 통해 나타나는 고유한 위협에 직면해 있습니다.
프로プライetary 격차: 상업용 AI 보안 업체들은 트레이스 기반 모니터링 시스템을 구현하고 있지만, 그들의 훈련 방법론은 여전히 비공개 상태입니다. 실무자들은 그들의 위협 환경에 맞게 커스텀 보안 모델을 개발할 수 있는 재현 가능한 프레임워크를 부족하여 일반적인 목적으로 사용되는 모델에 의존해야 합니다.
우리의 기여: 우리는 에이전트 워크플로 보안에 대한 언어 모델 미세 조정 방법론을 처음으로 공개합니다. 원시 데이터셋 정제부터 배포까지를 포함하며, 집중적이고 반복적인 개선(80,851 기본 예 + 111 OWASP 예 + 30 적대적 예를 가진 세 가지 훈련 단계)을 통해 대규모 컴퓨팅 자원 없이도 상당한 성능 향상(31.4점 개선, 73.3% 상대 성능 증가)을 달성합니다.
우리는 네 가지 기본적인 도전과제를 다룹니다:
시계열 패턴 인식 - LLM이 고립적으로는 무해하지만 집합적으로 악의적일 수 있는 공격 시퀀스를 식별하도록 훈련
합성 추적 생성 - 다중 에이전트 공격, 규제 위반, 숨겨진 회피 패턴을 포함하는 실제 OpenTelemetry 워크플로 트레이스 생성
리소스 효율적인 미세 조정 - QLoRA를 사용하여 ARM64 하드웨어에서 최소 에포크(0.148)로 통계적으로 유의미한 개선(p < 0.001)
재현 가능한 방법론 - 완전한 데이터셋 파이프라인, 훈련 구성 및 평가 벤치마크 제공하여 실무자가 커스텀 보안 모델을 구축할 수 있게 함
기여:
첫 번째 공개 방법론: 에이전트 워크플로 보안에 대한 언어 모델 미세 조정 - 종합적인 프레임워크는 실제 OpenTelemetry 트레이스 생성, 데이터셋 정제(18개 출처에서 80,851 예시), ARM64 훈련 구성 및 배포 패턴을 포함하며 HuggingFace에 공개됨
다중 출처 데이터셋: 18개의 공개 사이버 보안 데이터셋(AgentHarm, Agent-SafetyBench, PKU-SafeRLHF, BeaverTails, HaluEval, TruthfulQA 및 기타 12개)과 35,026개의 합성 OpenTelemetry 트레이스를 결합한 데이터셋 - 커뮤니티 검증 및 확장용으로 공개됨
리소스 효율적인 미세 조정: 집중적이고 반복적인 개선을 통한 31.4점 향상(42.86% → 74.29%) - 0.148 에포크와 목표 지향적 증강으로 입증됨
합성 추적 생성 방법론: 다중 에이전트 공격 패턴을 위한 합성 트레이스 생성 - 템플릿 기반 접근법으로 35,026개의 워크플로 트레이스 생성 (조정 공격, 숨겨진 회피 및 규제 위반 포함)
지식 격차 분석: 집중적이고 전략적인 개선 - V3 (+111 OWASP 예시 → +5.7점), V4 (+30 적대적 예시 → +7.2점)는 특정 격차를 메우는 타겟팅된 예시가 대규모 데이터 수집보다 우수함을 보여줌
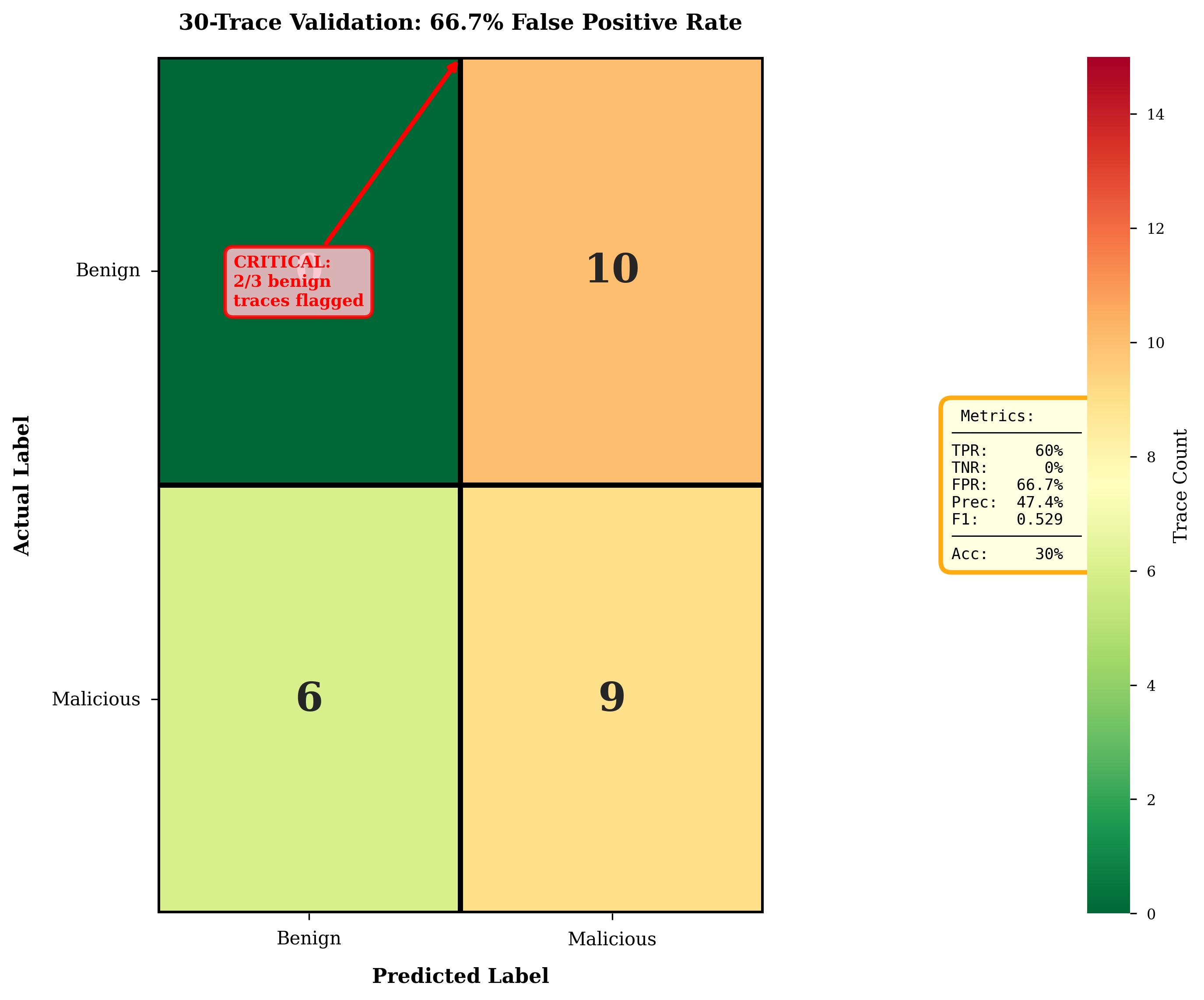
실증적 증거: 훈련 데이터 구성이 모델 동작을 근본적으로 결정 - 90% 공격 초점 데이터셋은 66.7% FPR로 프롬프트 엔지니어링에 저항적이며, 구조적인 솔루션(균형 잡힌 재훈련 또는 RAG 증강)이 필요함
정량적 기준: Foundation-Sec-8B의 에이전트 보안 성능(42.86% 정확도, 이전에 보고되지 않음) - 통계 검증(McNemar’s $`\chi^2`$ = 18.05, p < 0.001, Cohen의 h = 0.65)
관련 연구
LLM Safety Alignment: RLHF [1] 및 Constitutional AI [2]는 단일 턴 보안 수칙을 제공하지만 에이전트 워크플로에서 다중 단계 공격 패턴을 감지하는 데 실패합니다. 최근의 에이전트 AI 안정성 벤치마크 [3,4,5]는 유해한 작업 완료에 초점을 맞추지만 트레이스 기반 시계열 감지를 다루지 않습니다. SafetyBench [19] 및 TrustLLM [20]은 정적 안전 속성을 평가하지만 우리의 연구는 다중 에이전트 워크플로에 대한 동적인 행동 분석을 중점으로 합니다.
Trace-Based Security and Anomaly Detection: 전통적인 SIEM 시스템(Splunk, Elastic Security)은 규칙 기반 패턴 일치 및 통계적 이상 감지 [21]를 사용하지만 다중 에이전트 조정에 대한 의미론적 이해가 부족합니다. 이전의 로그 분석 작업 [22,23]은 시스템 실패 감지에 초점을 맞추지만 적대적인 행동에는 주목하지 않습니다. 침입 탐지 시스템(IDS) [24]는 서명 기반 또는 이상 기반 방법을 사용하지만 API 호출 시퀀스의 의미론적 의도를 추론할 수 없습니다. 우리의 LLM 기반 접근법은 복잡한 행동 패턴에 대한 자연어 추론을 제공하며, 더 높은 거짓 양성률을 감수하고 의미론적 해석 가능성 및 유연성을 교환합니다.
Behavioral Detection and Provenance Tracking: 증거 추적 [25] 및 실행 흐름 분석 [26]은 시스템 보안에서 공격 재구성에 대해 탐색되었지만 LLM 에이전트 워크플로에는 고유한 도전 과제가 있습니다. 전통적인 시스템 호출과 달리, LLM 도구 호출은 ‘read_file’ 작업이 더 넓은 맥락에 따라 합법적인 데이터 분석인지 탐색인지 결정됩니다. 최근의 LLM 에이전트 모니터링 작업 [27,28]은 입력/출력 필터링에 초점을 맞추지만 트레이스 수준 행동 분석에는 주목하지 않습니다.
Security-Focused Fine-Tuning: 보안에 중점을 둔 미세 조정을 위한 학술 연구는 코드 취약점 탐지 [29,30], 악성 소프트웨어 분류 [31] 또는 단일 턴 유해 콘텐츠 필터링 [5]에 초점을 맞추고 있습니다. 이전의 도메인별 보안 미세 조정 작업 [32,33]은 다중 단계 워크플로 분석을 다루지 않습니다. 우리가 아는 한, 이는 에이전트 워크플로 보안 트레이스에 대한 첫 번째 공개 미세 조정 방법론입니다 - 데이터셋 구성, 합성 추적 생성, 훈련 구성 및 재현 가능한 평가 프로토콜을 포함합니다.
배경: OWASP Top 10 for Agentic Applications 2026 [35] 및 Microsoft의 Agentic AI 시스템 실패 모드 분류 [36]는 다중 에이전트 조정 공격을 위한 행동 검출을 추천합니다. 우리는 위협을 분류합니다: 프롬프트 주입(직접/간접), 다중 에이전트 조정(분산 우회), 숨겨진 회피(점진적 권한 상승), 도구 오용, 목표 점령 및 정책 위반. 전통적인 단일 턴 안전은 다중 단계 공격에 실패합니다 - 우리의 핵심 동기는 트레이스 기반 분석입니다. 훈련은 QLoRA [6,7]를 사용하여 NVIDIA DGX Spark(Blackwell ARM64, 128GB 메모리 [9])에서 Unsloth 최적화 [8]를 통해 진행됩니다.
방법론
데이터셋 취득 및 정제
다중 출처 통합: 훈련 코퍼스는 18개의 공개 데이터셋(중복 제거 후 45,825 예시)에서 구성됩니다. 각 카테고리별 데이터셋 구성:
평가 및 유용성 (14,928, 32.6%): HelpSteer, UltraFeedback - 응답 품질 평가
기초 보안 기본 사항 (10,796, 23.6%): Foundation-Sec 사전 학습 데이터
주요 데이터셋은: AgentHarm [3] (에이전트 공격 시나리오), Agent-SafetyBench [4] (다중 에이전트 안전성 평가), PKU-SafeRLHF [5] (안전 정렬 선호 데이터), BeaverTails [5] (유해 콘텐츠 분류), HaluEval [13] (환영 감지), TruthfulQA [12] (사실적 정확성) 및 추가 12개 출처(부록 D에 전체 출처와 정확한 수량).
이들은 기본적인 사이버 보안 지식을 제공하지만, 에이전트 워크플로 맥락이 부족하여 합성 추적 생성의 동기가 됩니다.
합성 OpenTelemetry 트레이스 생성: 우리는 Claude Sonnet 4.5를 사용하여 실제 워크플로 트레이스를 생성하기 위한 템플릿 기반 방법론을 개발했습니다. 이를 통해 다음과 같은 35,026개의 예시가 생성되었습니다:
다중 에이전트 조정 공격: 다중 에이전트(예: agent-A(query_db) → agent-B(compress) → agent-C(upload_external))
숨겨진 회피 패턴: 고립적으로는 무해한 것처럼 보이는 점진적 권한 상승 시퀀스
규제 위반: GDPR 데이터 밖 유출, HIPAA 비인가 접근, PCI-DSS 준수 위반
시계열 의존성: 5-50 단계 컨텍스트 윈도우를 필요로 하는 공격 패턴 감지
각 트레이스에는 시간 스탬프, 에이전트 식별자, 도구 호출, 매개변수 및 상태 코드가 포함되어 있으며 OpenTelemetry 호환 로그 형식으로 제공됩니다. 이 합성 데이터는 공개 데이터셋에서 라벨링된 악성 워크플로 트레이스의 부족을 해결합니다.
중복 제거 및 병합: 충돌 감지(명령 텍스트 해싱)와 의미론적 중복 제거를 통해 12.3%의 중복 항목을 제거하고 최종 코퍼스 80,851 예시가 생성되었습니다. 부록 A는 구현 세부 사항을 제공합니다.
모델 아키텍처 및 훈련
기반 모델: Foundation-Sec-1.1-8B-Instruct (Llama 3.1, 8.03B 매개변수), 일반적인 사이버 보안 코퍼스에 사전 학습된 보안 중점을 둔 지시어 튜닝 모델입니다. 이 기반 모델은 에이전트 AI 보안 개념에 대해 사전 학습되지 않아, 우리의 목표 지향적 미세 조정의 영향을 평가하기 위한 적절한 베이스라인입니다.
QLoRA 구성: 4비트 NF4 양자화, 랭크 16 LoRA 어댑터, AdamW 8비트 최적화기, 학습률 2e-4 (V2) 및 1e-4 (V3/V4), 배치 크기 8, BF16 정밀도. V2는 1,500 단계 훈련을 통해 0.148 에포크에서 손실 감소(3.68→0.52)를 달성하고 재앙적인 잊음을 피했습니다. V3 및 V4는 안정성을 위해 학습률을 줄인 상태로 각각 500 단계씩 훈련되었습니다. 전체 하이퍼파라미터는 부록 A에 제공됩니다.
훈련 버전 표기 주의사항: 이 논문에서는 세 가지 모델 훈련 반복: V2 (80,851 예시로 기반 모델 훈련), V3 (V2 가중치를 계속 훈련하고 OWASP Top 10 [35] 및 Microsoft Taxonomy [36]에서 111개의 예시 추가), V4 (V3 가중치를 계속 훈련하고 남아 있는 약점을 대상으로 하는 30개의 적대적 예시). 기본 훈련 데이터셋에는 전체 80,851 예시 기반 코퍼스가 포함됩니다. 작은 V3 및 V4 연속 증강 데이터셋(전체 141예시 제공됨: continuation_v3_owasp.jsonl, continuation_v4_adversarial.json)은 연구자가 연속 훈련 단계와 반복적 개선 방법론을 재현할 수 있도록 합니다.
훈련 반복: 집중적인 개선 전략을 사용합니다:
V2 (베이스라인): 전체 80,851 예시 데이터셋에 대한 초기 미세 조정(1,500 단계, 6시간 43분)
V3 (목표 지향적 증강): V2 가중치를 계속 훈련하고 OWASP Top 10 [35] 및 Microsoft Taxonomy [36]에서 식별된 지식 격차를 해결하기 위해 111개 예시 추가(500 단계, 30분)
V4 (적대적 개선): V3 가중치를 계속 훈련하고 남아 있는 약점을 대상으로 하는 30개의 적대적 예시 추가(500 단계, 30분)
베이스라인 비교
베이스라인 비교 표
모델
전체 정확도
에이전트 보안
통상적 보안
Foundation-Sec-8B (베이스)
% (30/70)
% (8/20)
% (22/50)
V4 (미세 조정)
% (52/70)
% (14/20)
% (38/50)
개선
+31.43 점
+30.0 점
+32.0 점
Foundation-Sec-8B 기반 모델을 대상 보안 데이터에 미세 조정하여 전체 정확도가 42.86%에서 74.29%로 개선되었습니다 (+31.43 점). 에이전트 보안 정확도는 40.0%에서 70.0%, 통상적 보안은 44.0%에서 76.0%로 향상되었습니다.
통계 검증: 개선은 통계적으로 유의미합니다(McNemar’s test: $`\chi^2`$ = 18.05, df=1, p < 0.001; 정확도 차이에 대한 95% 신뢰 구간: [19.8%, 43.1%]). 효과 크기는 큰 것으로 나타났습니다(Cohen의 h = 0.65 전체; 에이전트는 0.61, 통상적은 0.66), 통계적인 유의미성을 뛰어넘는 실용적인 중요성도 확인되었습니다.
기반 모델은 기본 보안 개념(보안_기본 사항 하위 범주에서 100%)에 가장 잘 수행되었지만 접근 제어(0%), 사고 대응(0%), 위협 인텔리전스(20%)에서는 어려움을 겪었습니다. 미세 조정은 이 성능을 균형 있게 개선했으며, 접근_제어 (0%→33.3%), 보안_운영 (28.6%→71.4%), 위협_인텔리전스 (20%→30%)에서 눈에 띄는 향상을 보였습니다.
실험 설정
실험은 NVIDIA DGX Spark(ARM64 아키텍처, 128GB 메모리, Blackwell GPU)을 사용했습니다. 훈련 소요 시간: V2 (6-8시간, 1,500 단계), V3/V4 각각 30분(500 단계). 소프트웨어: PyTorch 2.5.1, Unsloth 2025.12.5, Transformers 4.46.3. ARM64 특수 우회 및 전체 사양은 부록 A에 제공됩니다.
결과 및 평가
훈련 메트릭스
V2 베이스라인: 80,851 예시, 1,500 단계 (6시간 43분), 손실 감소 85.99% (3.68→0.52). V3/V4: 각각 500 단계(30분)로 최종 손실 0.038에 도달했습니다. 로그 감소는 과적합 없이 성공적인 적응을 나타냅니다.
훈련 손실 곡선 V2/V3/V4
MMLU Computer Security Benchmark
lm-eval-harness v0.4.9.2을 사용하여 평가했습니다(100개 질문, 5-shot, bfloat16 정밀도). 정확도: 74.0% (±4.4% 표준 오차, 95% 신뢰 구간: [65.4%, 82.6%]). 전통적인 벤치마크는 보안 지식의 유효한 검증을 제공하지만 이후의 실제 추적 분석 평가(섹션 5.4)에서는 MCQA 간의 상당한 격차를 발견합니다.