Splitwise 협업 엣지 클라우드 추론을 위한 Lyapunov 기반 강화학습
📝 원문 정보
- Title: Splitwise: Collaborative Edge-Cloud Inference for LLMs via Lyapunov-Assisted DRL
- ArXiv ID: 2512.23310
- 발행일: 2025-12-29
- 저자: Abolfazl Younesi, Abbas Shabrang Maryan, Elyas Oustad, Zahra Najafabadi Samani, Mohsen Ansari, Thomas Fahringer
📝 초록 (Abstract)
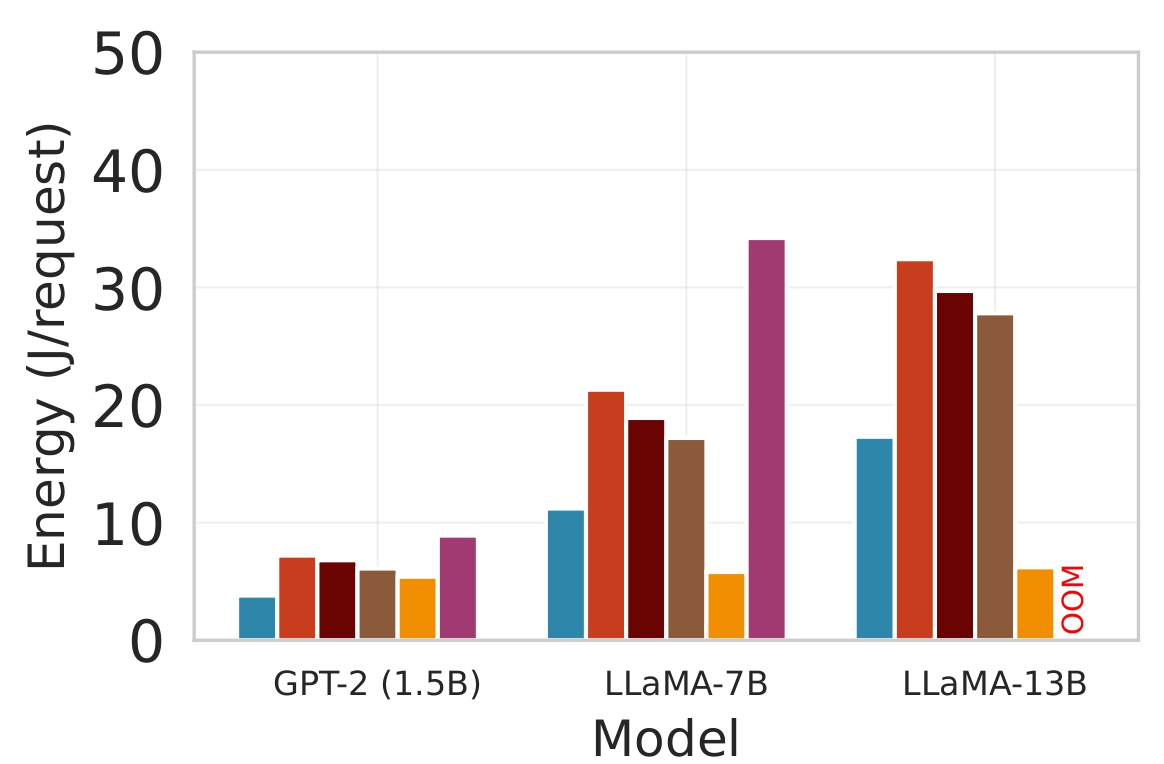
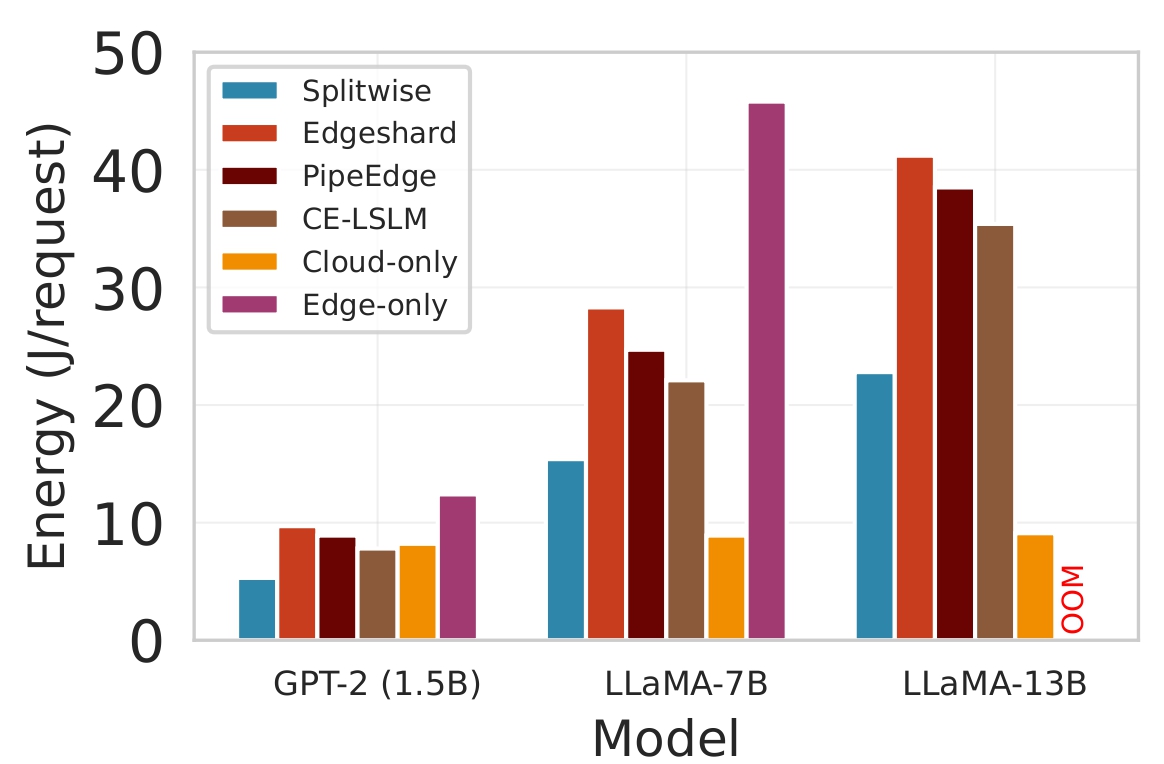
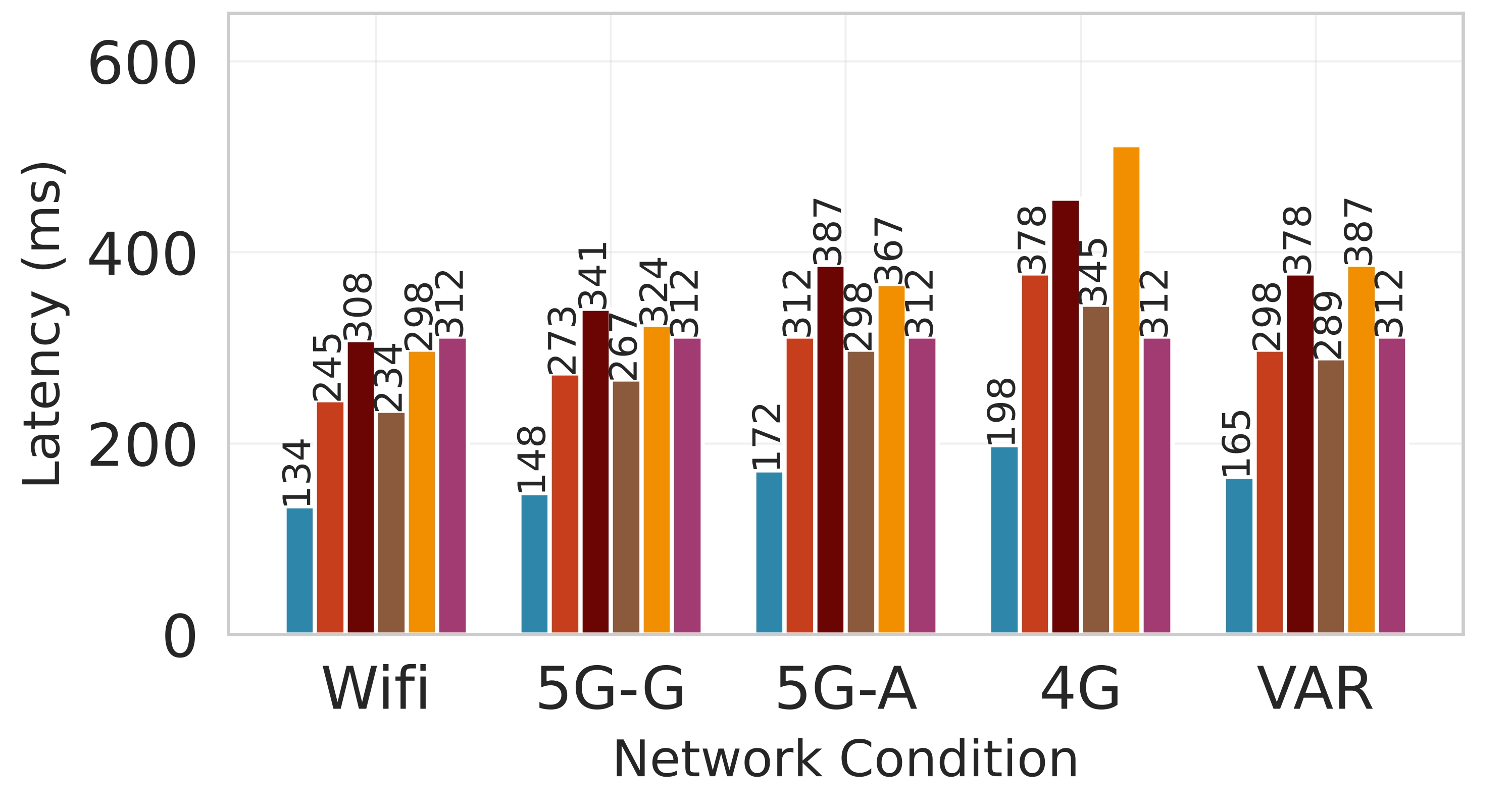
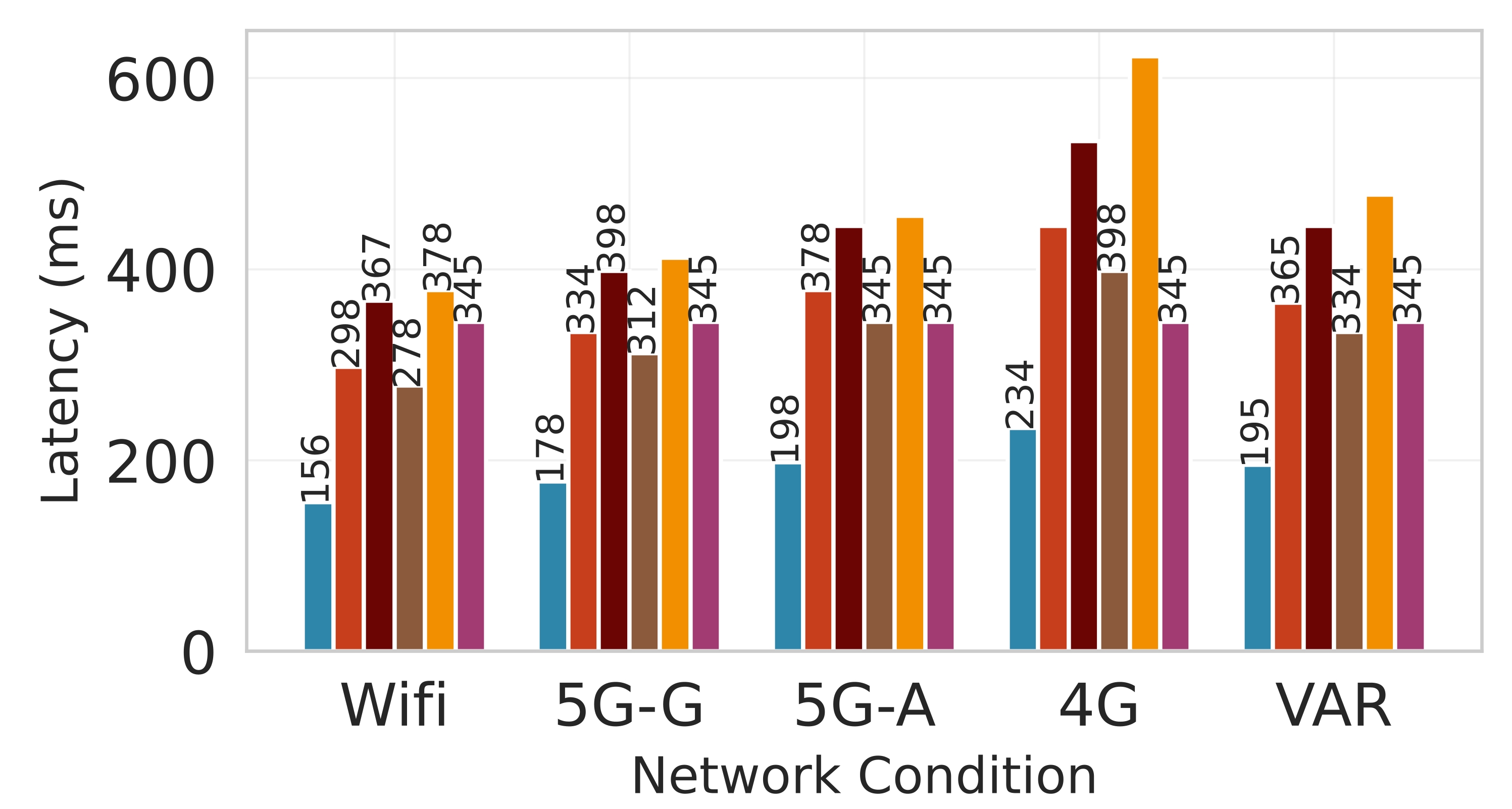
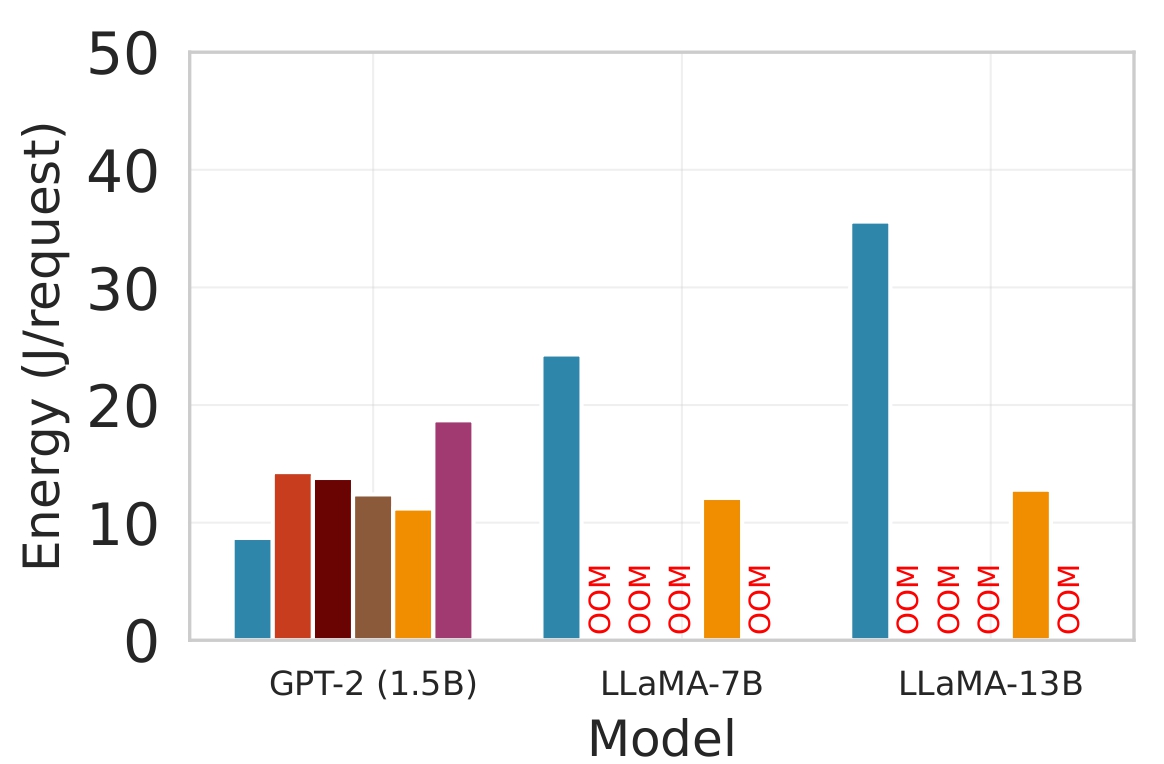
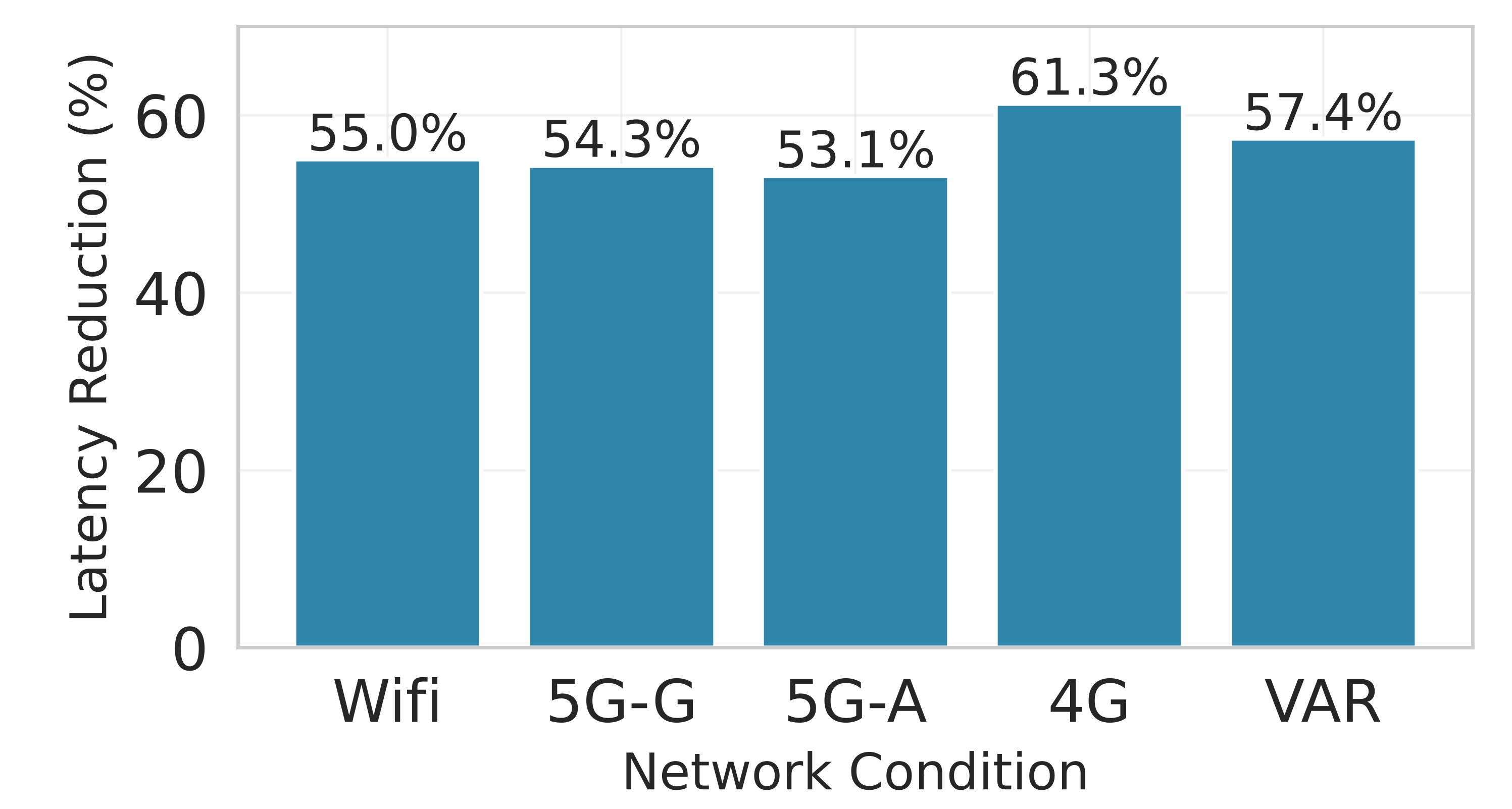
대형 언어 모델(LLM)을 엣지 디바이스에 배치하는 것은 메모리와 전력 제한으로 어려움을 겪는다. 클라우드 전용 추론은 디바이스 부담을 줄이지만 높은 지연시간과 비용을 초래한다. 정적 엣지‑클라우드 파티셔닝은 단일 지표만 최적화하고 대역폭 변동에 취약하다. 본 논문은 Lyapunov 기반 심층 강화학습(DRL) 프레임워크인 Splitwise를 제안한다. Splitwise는 트랜스포머 레이어를 어텐션 헤드와 피드포워드 서브블록으로 분해해 레이어 단위 방식보다 지수적으로 많은 파티션 옵션을 제공한다. Lyapunov 최적화를 이용한 계층적 DRL 정책은 지연시간, 에너지 소비, 정확도 저하를 동시에 최소화하고, 확률적 워크로드와 가변 네트워크 대역폭 하에서 큐 안정성을 보장한다. 또한 통신 실패 시 지수 백오프 복구를 위한 파티션 체크포인트를 도입한다. Jetson Orin NX, Galaxy S23, Raspberry Pi 5에서 GPT‑2(1.5 B), LLaMA‑7 B, LLaMA‑13 B를 대상으로 실험한 결과, Splitwise는 기존 파티셔너 대비 1.4×‑2.8×의 지연 감소와 최대 41 %의 에너지 절감을 달성했다. 95번째 백분위 지연은 클라우드 전용 실행 대비 53‑61 % 감소했으며, 정확도와 메모리 요구량은 크게 변동하지 않았다.💡 논문 핵심 해설 (Deep Analysis)
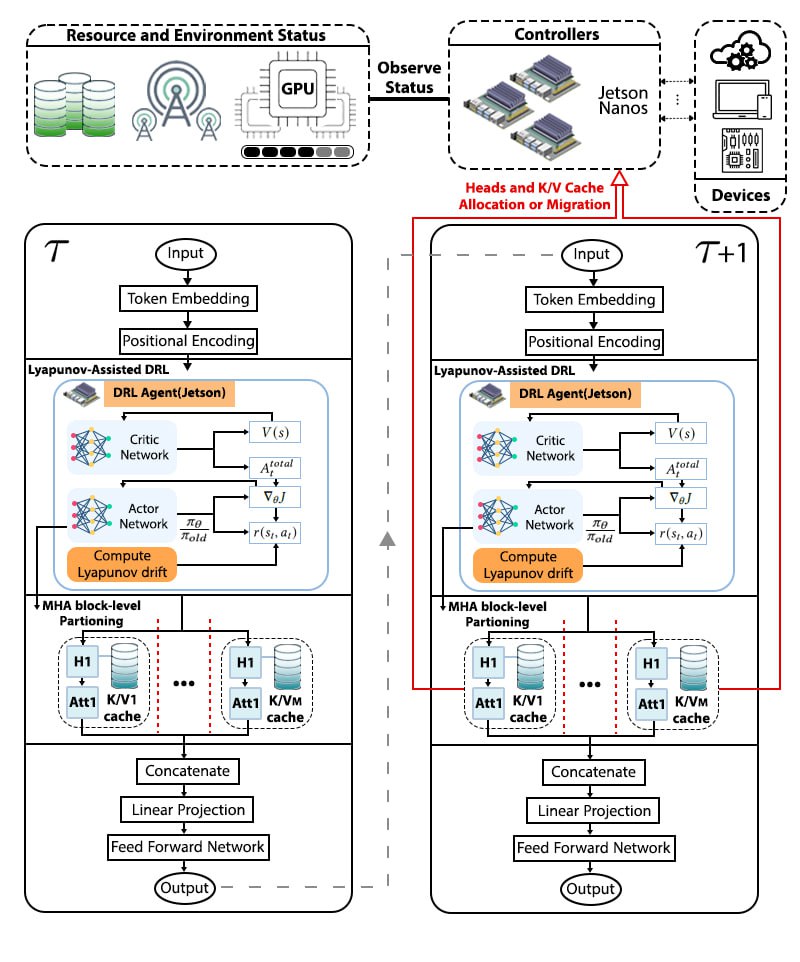
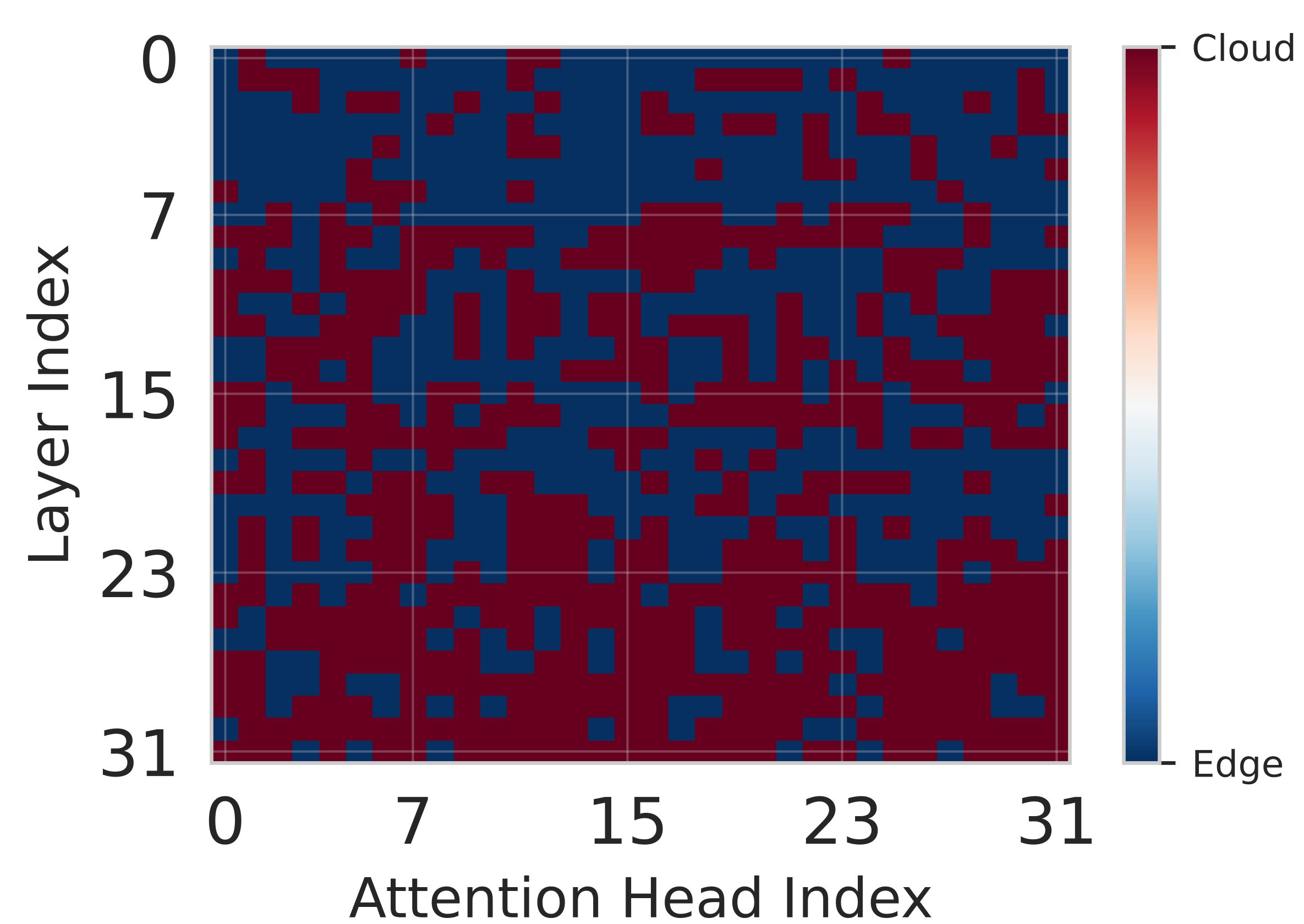
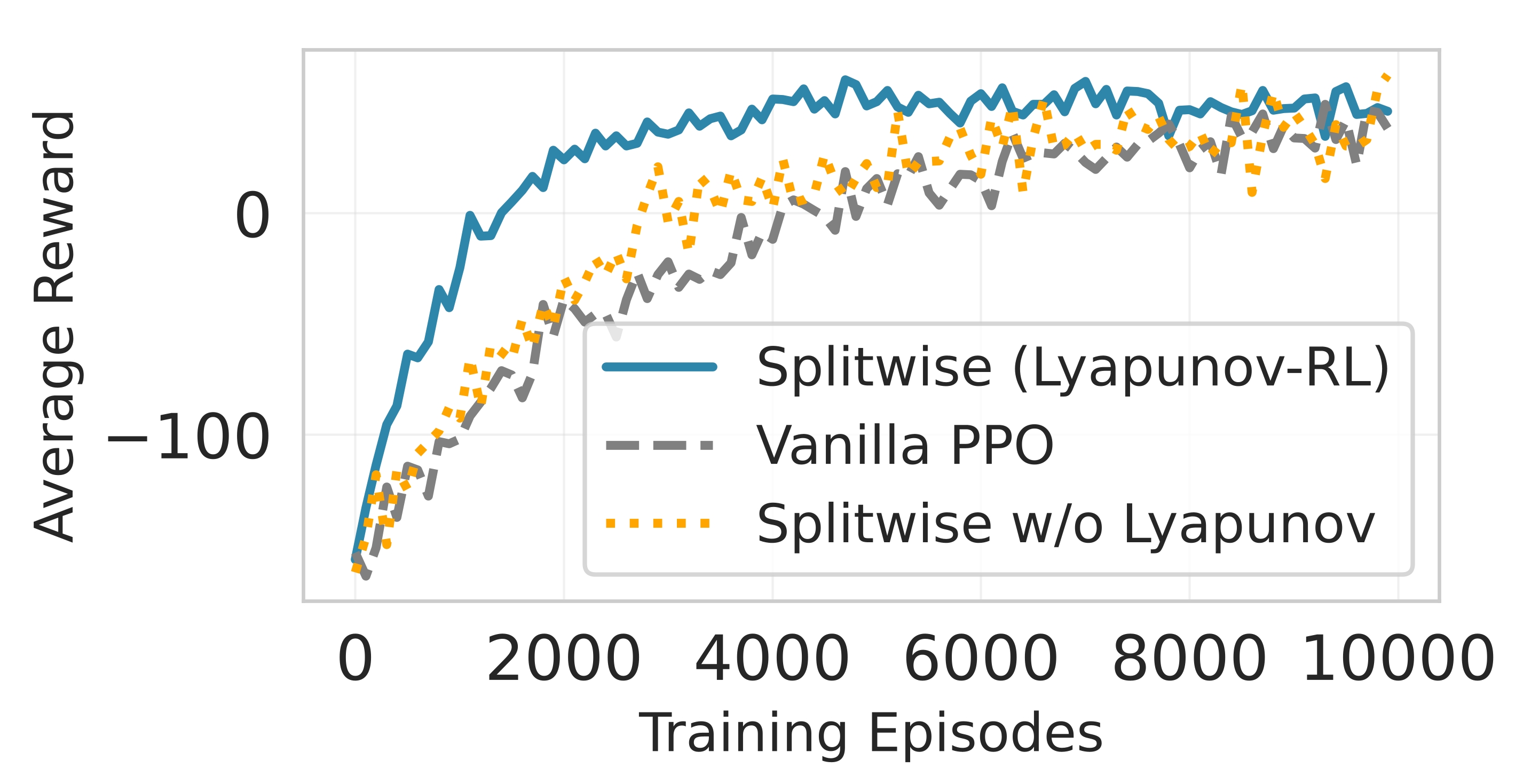
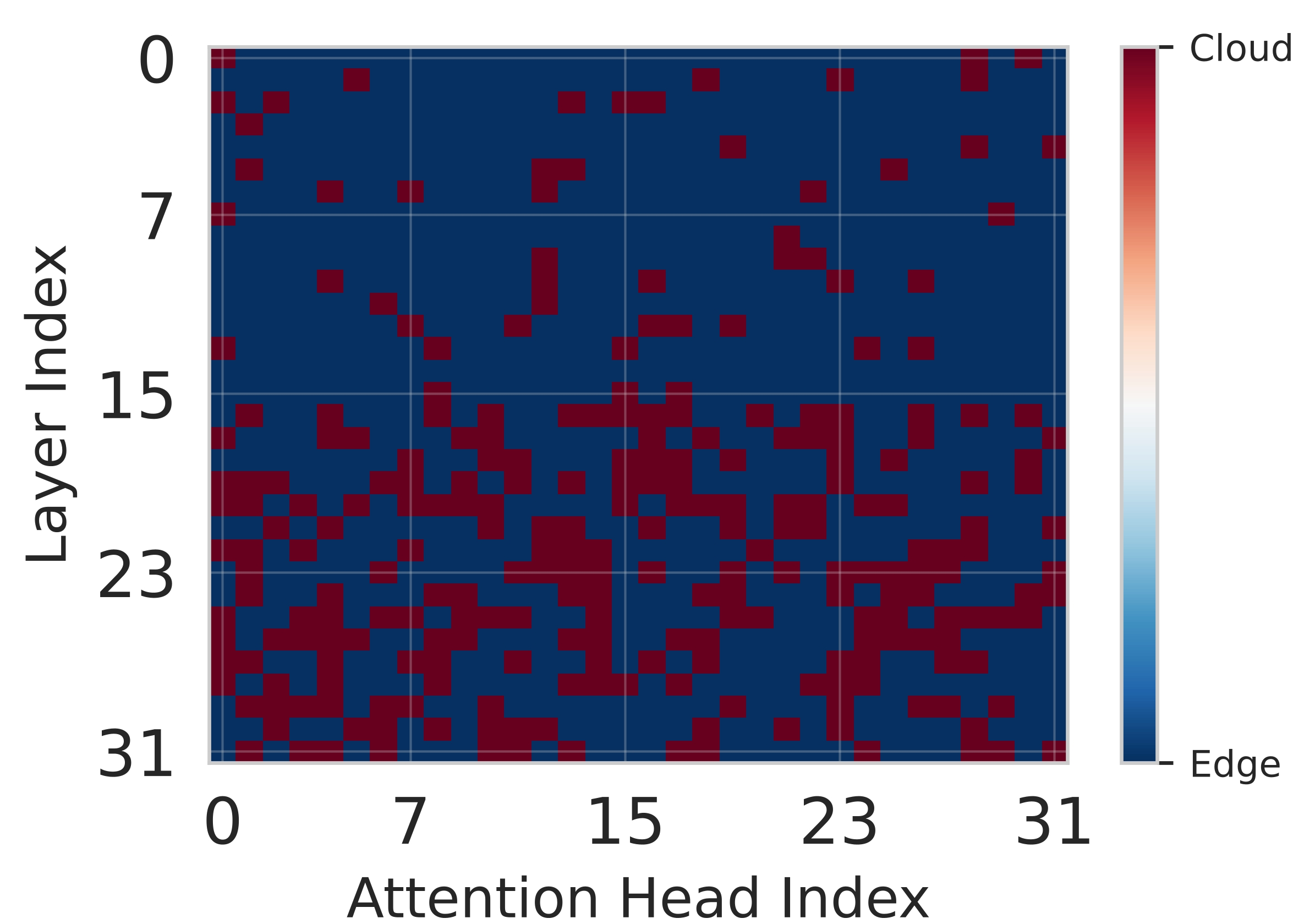
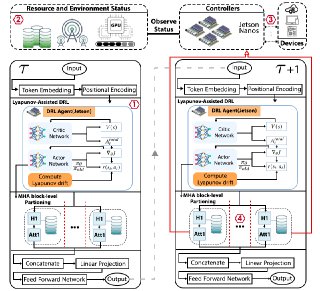
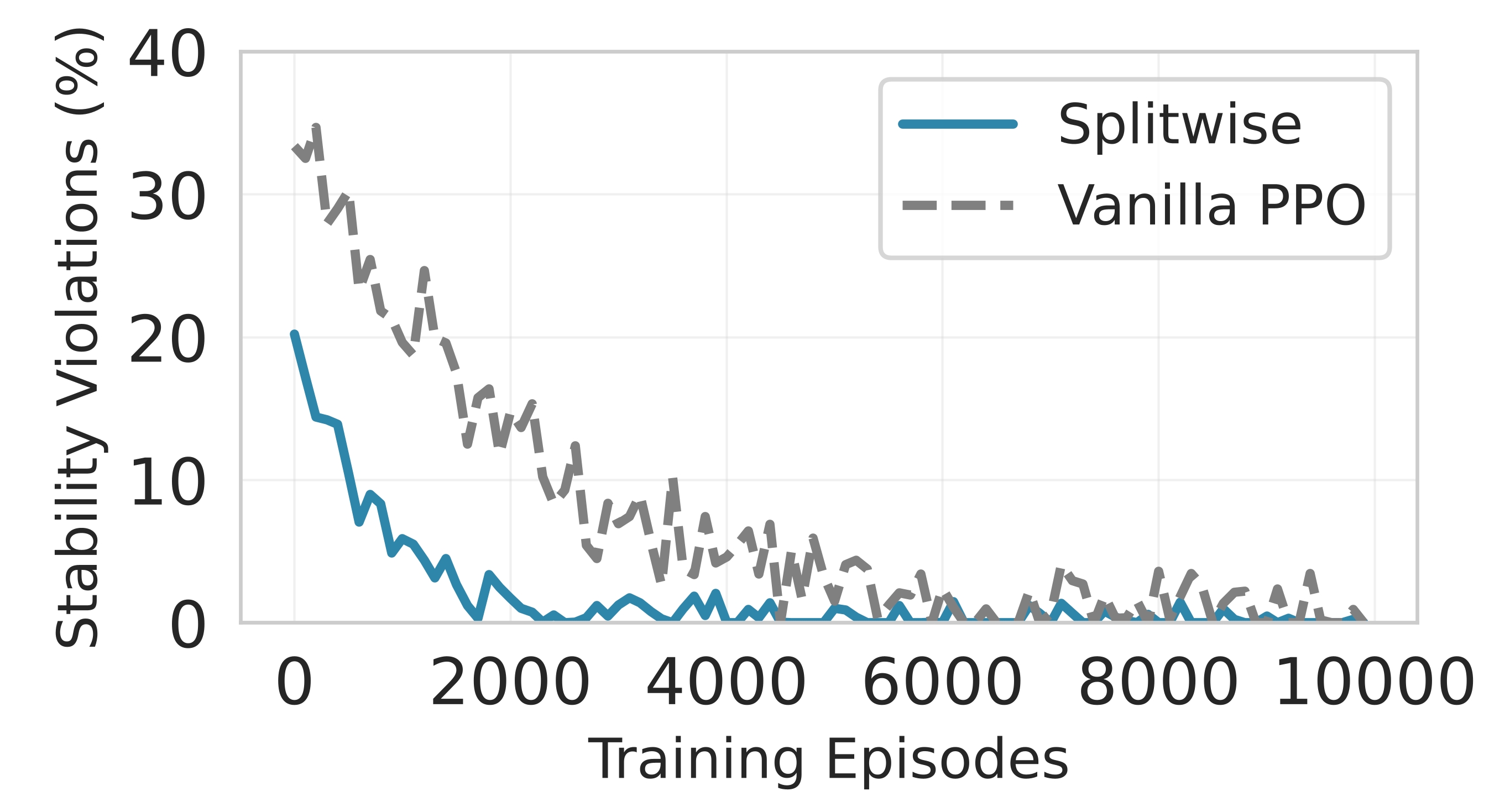
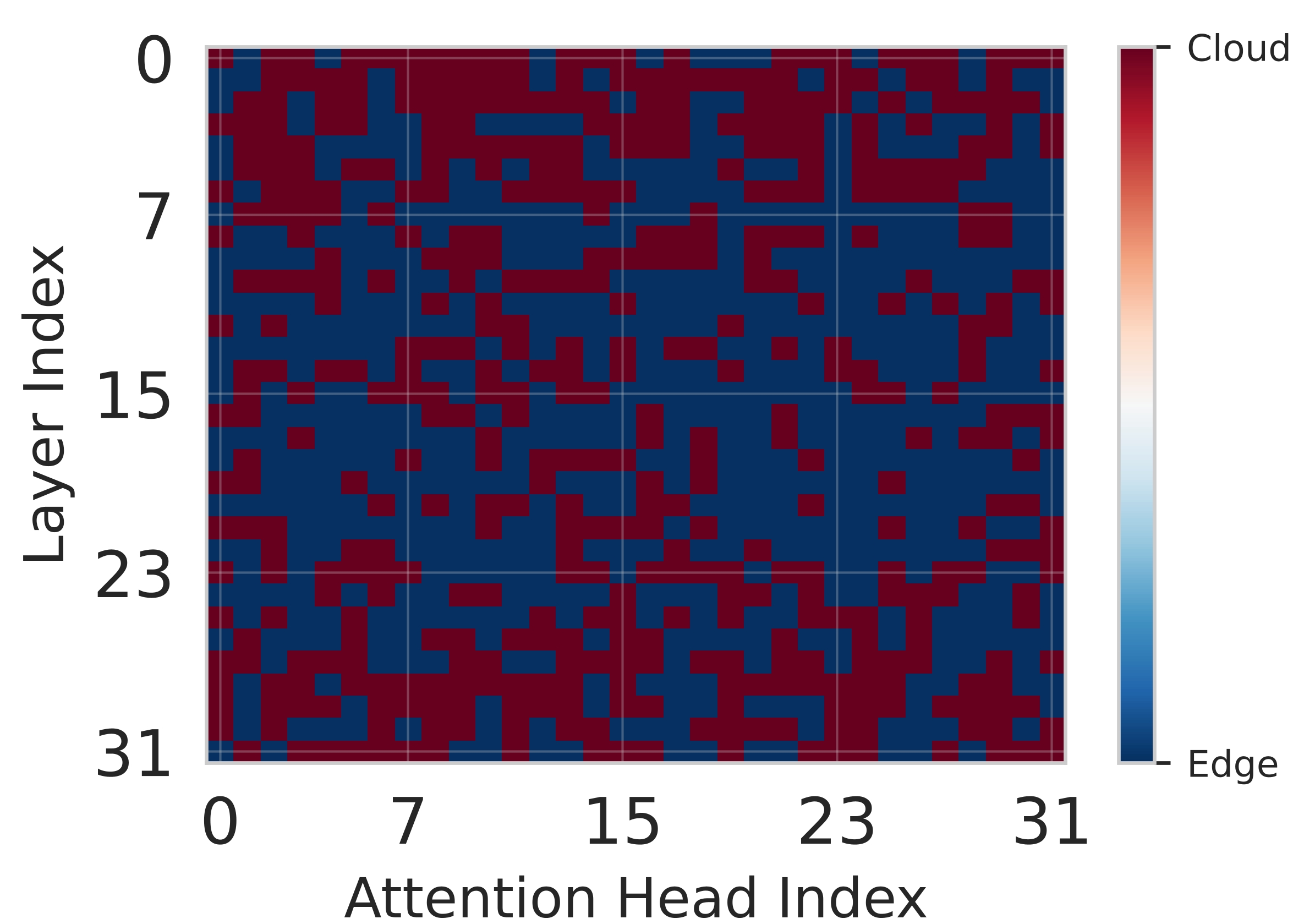
핵심 기술은 Lyapunov 기반의 심층 강화학습이다. Lyapunov 최적화는 시스템의 큐 안정성을 수학적으로 보장하는 프레임워크로, 여기서는 입력 요청 큐와 네트워크 전송 큐의 평균 길이가 제한을 초과하지 않도록 정책을 설계한다. 강화학습 에이전트는 현재 워크로드, 디바이스 전력 상태, 네트워크 대역폭, 모델 정확도 손실 등을 상태 변수로 받아, 각 서브블록을 엣지 혹은 클라우드에 할당하는 행동을 선택한다. 보상 함수는 지연시간 감소, 에너지 절감, 정확도 유지라는 다중 목표를 가중합 형태로 통합하며, Lyapunov 드리프트 항을 추가해 큐 안정성을 페널티로 부여한다. 이렇게 하면 에이전트는 단순히 단일 목표를 최적화하는 것이 아니라, 시스템 전반의 균형을 유지하면서 동적으로 파티션을 조정한다.
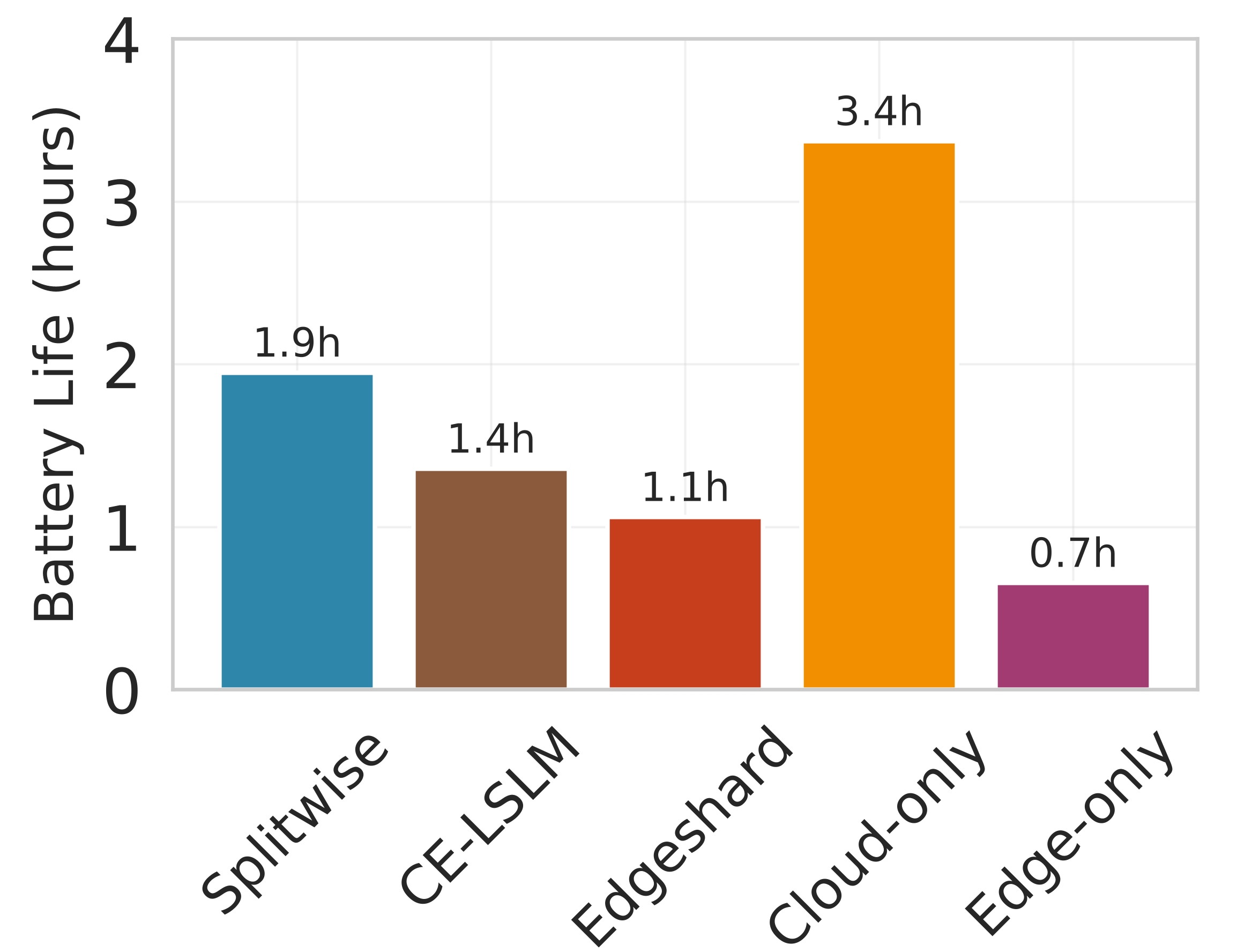
또한 Splitwise는 통신 장애에 대비한 복구 메커니즘을 포함한다. 파티션 체크포인트를 주기적으로 저장하고, 전송 실패 시 지수 백오프 전략을 적용해 재시도를 수행함으로써 서비스 중단 시간을 최소화한다. 이는 특히 모바일 네트워크와 같이 변동성이 큰 환경에서 실용성을 크게 높인다.
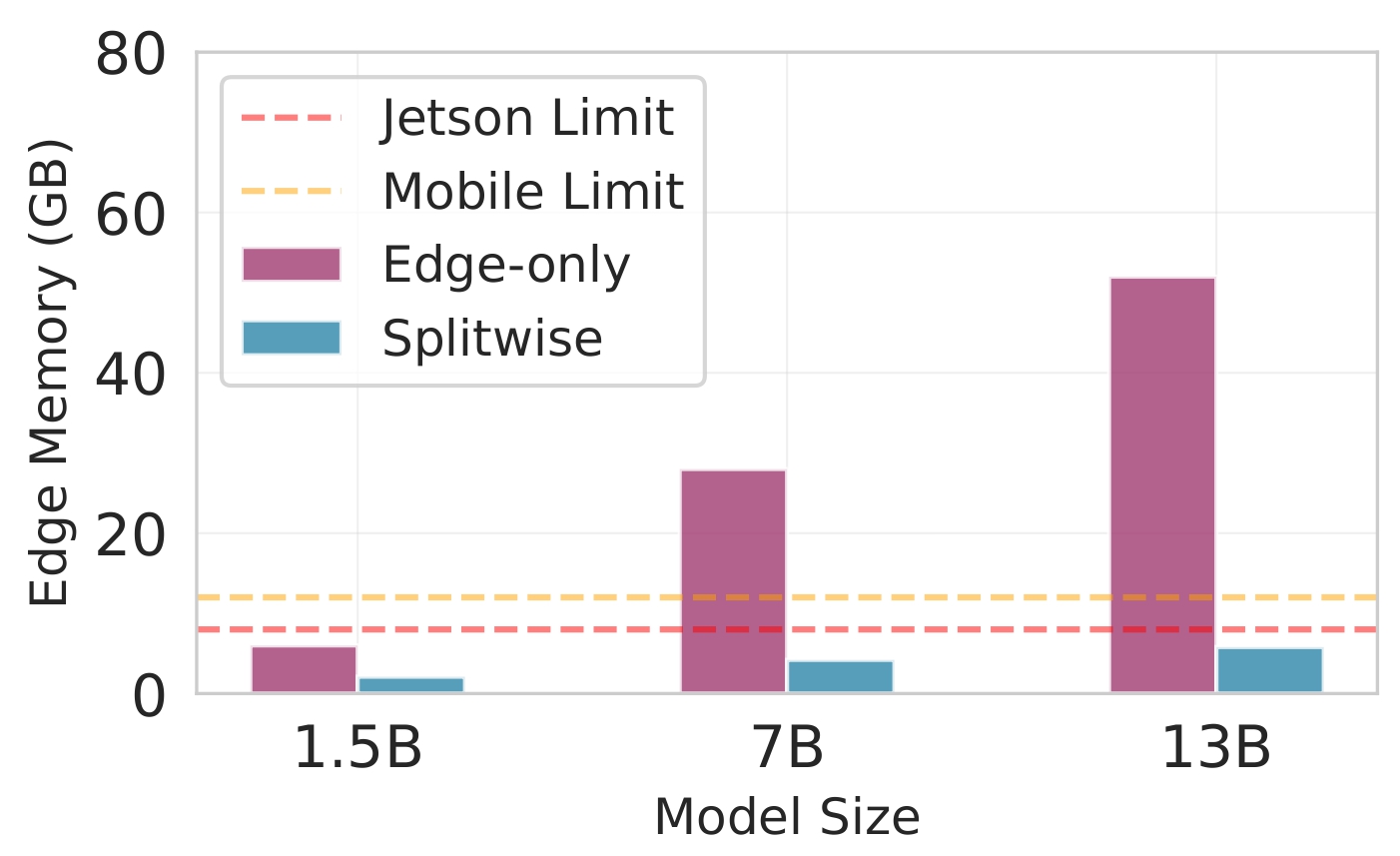
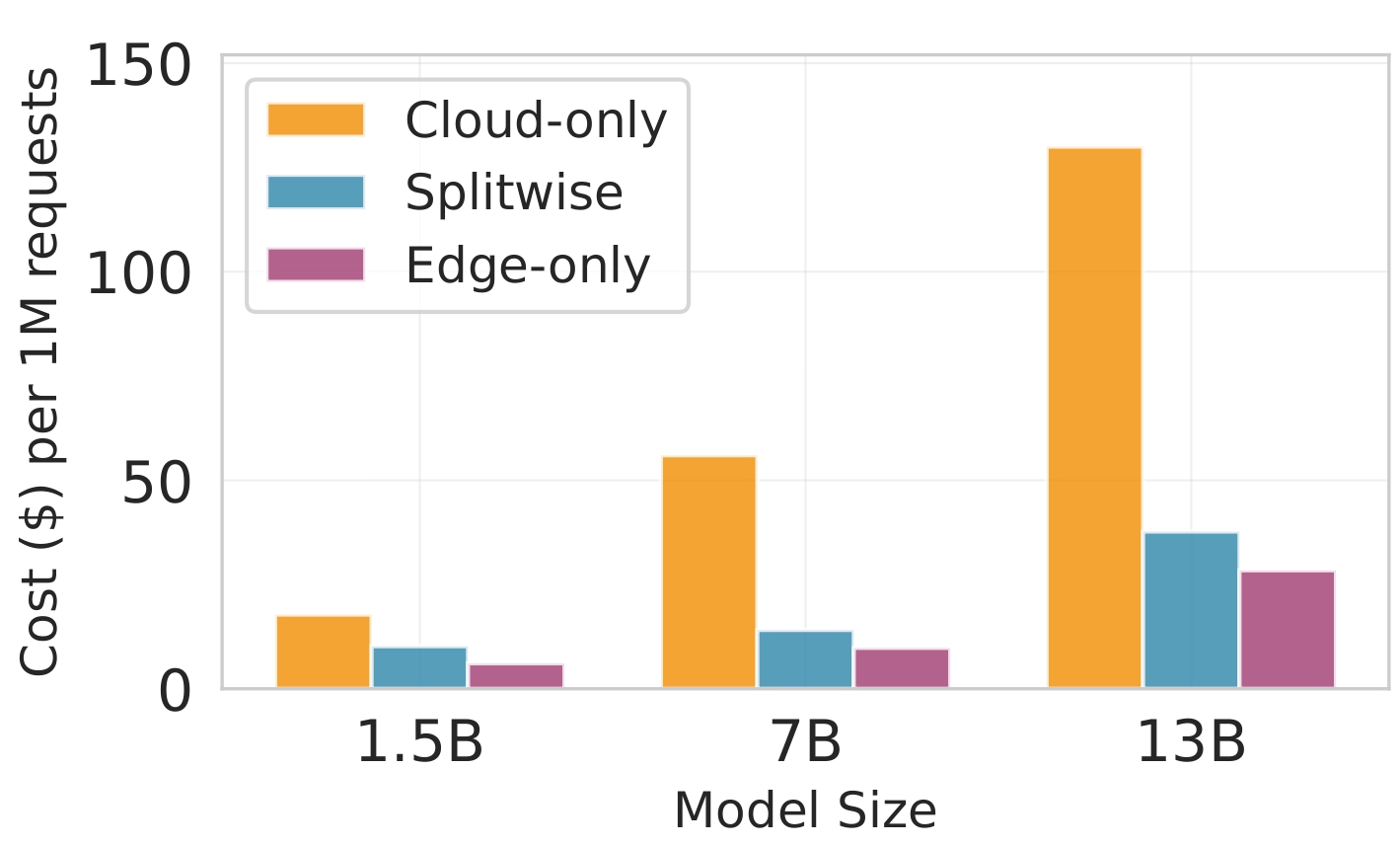
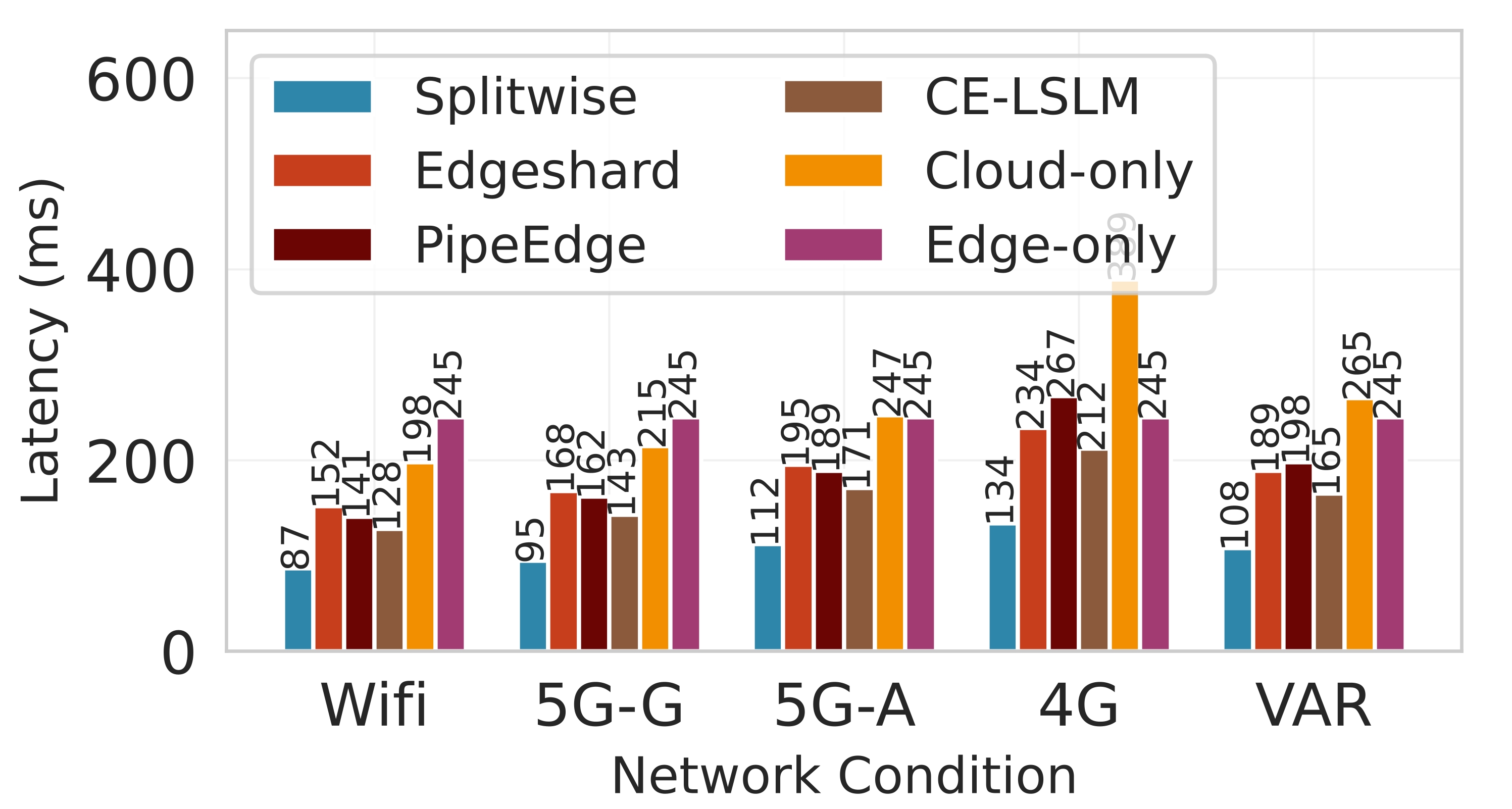
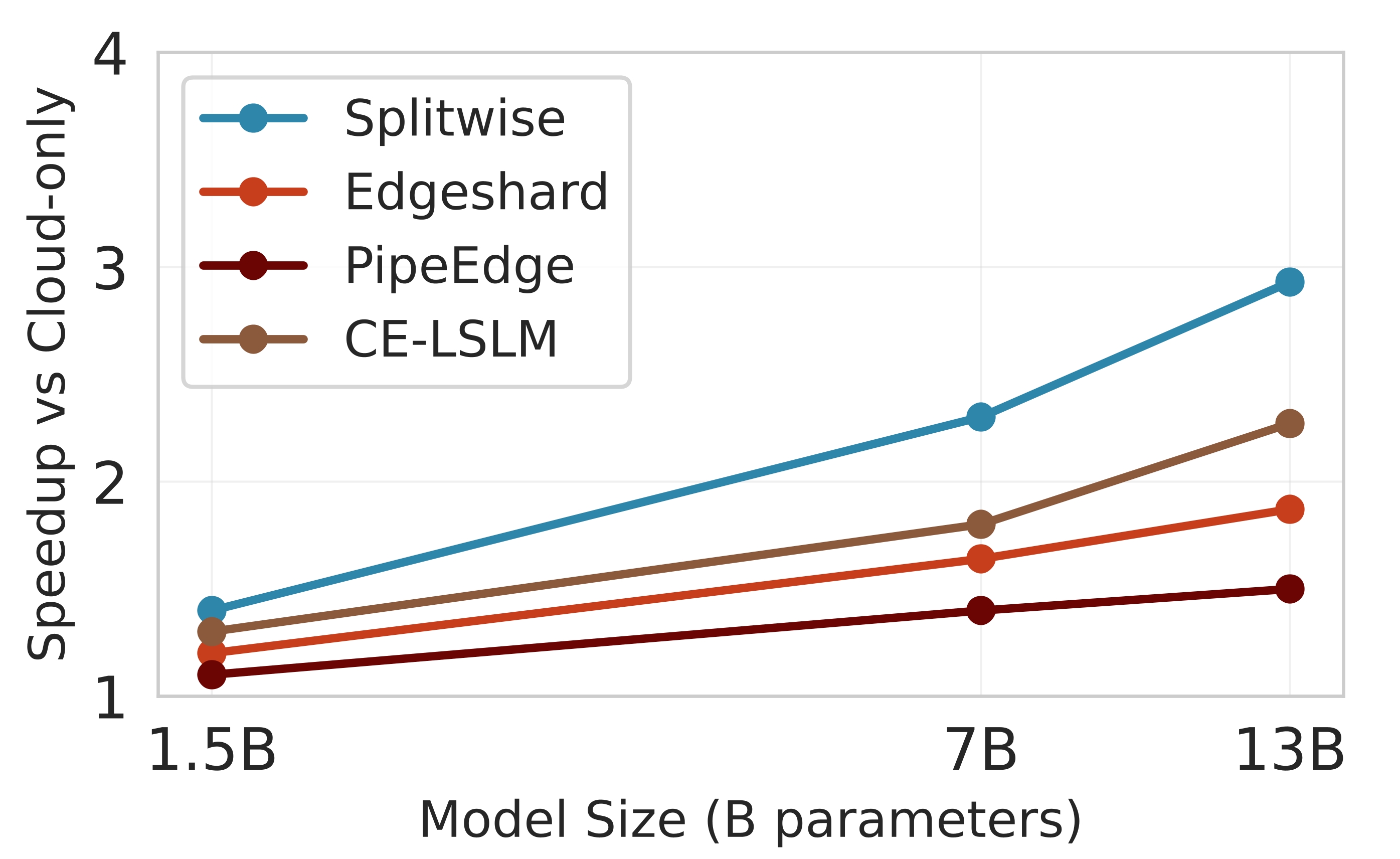
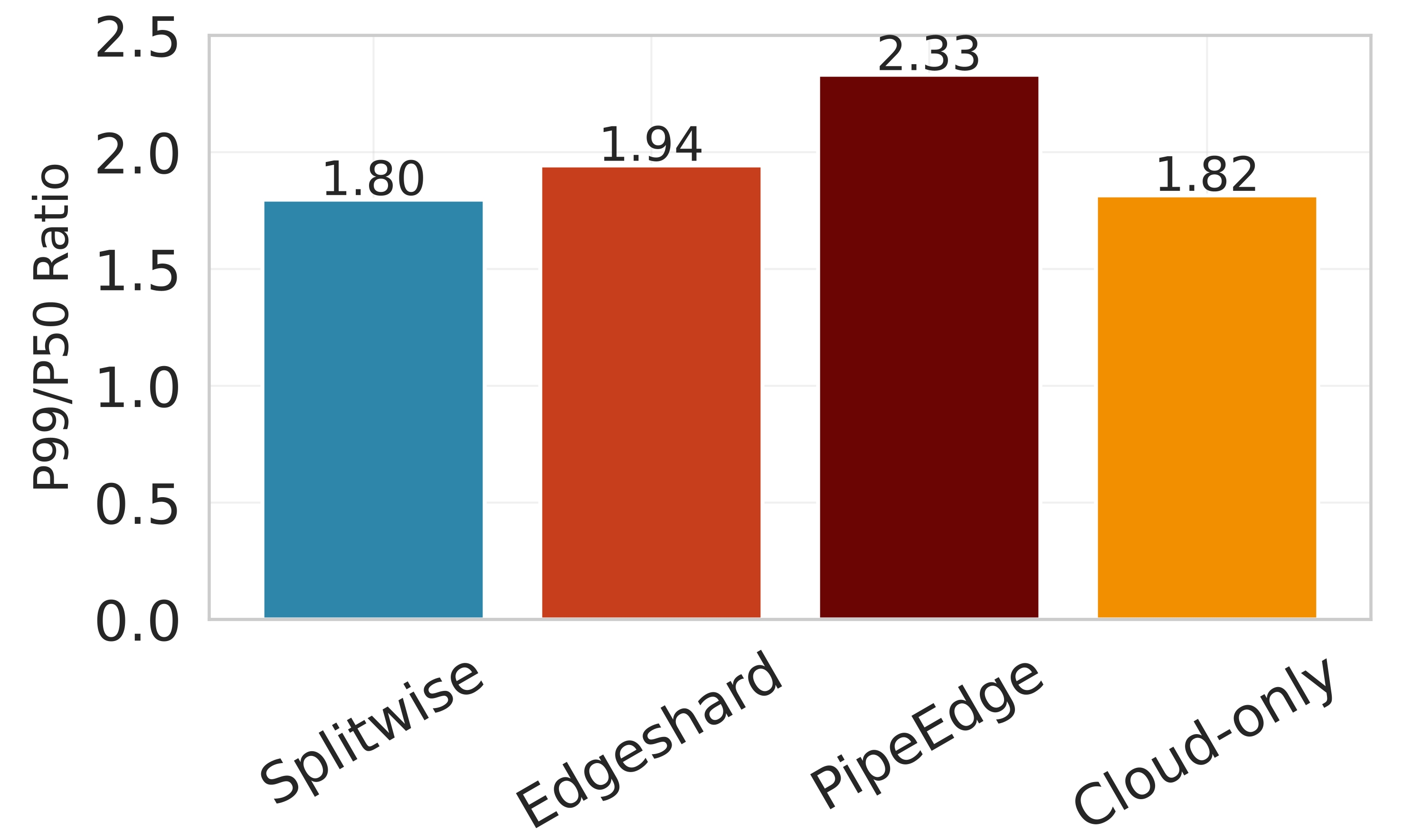
실험 설정은 Jetson Orin NX, Galaxy S23, Raspberry Pi 5와 같은 이질적인 엣지 디바이스와 GPT‑2(1.5 B), LLaMA‑7 B, LLaMA‑13 B 모델을 사용했다. 결과는 Splitwise가 기존 레이어‑단위 파티셔너 대비 평균 1.8배(범위 1.4‑2.8배)의 지연 감소와 최대 41 %의 에너지 절감을 달성했음을 보여준다. 특히 95번째 백분위 지연이 53‑61 % 감소한 점은 실시간 응답성이 중요한 서비스에 큰 의미가 있다. 정확도 측면에서는 어텐션 헤드 단위 파티셔닝이 모델 출력에 미치는 영향을 최소화하도록 설계돼, 원본 모델과 거의 동일한 성능을 유지한다. 메모리 사용량 역시 엣지 디바이스의 제한을 초과하지 않아, 실제 배포 가능성을 입증한다.
종합하면, Splitwise는 미세한 파티션 granularity와 Lyapunov‑보장 강화학습을 결합해, 변동성 높은 엣지‑클라우드 환경에서 LLM 추론을 효율적이고 안정적으로 수행할 수 있는 실용적인 솔루션을 제공한다. 향후 연구에서는 더 큰 모델(예: LLaMA‑30 B 이상)이나 멀티‑클라우드 시나리오, 그리고 프라이버시 보호를 위한 암호화 연산과의 연계도 탐색할 가치가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리