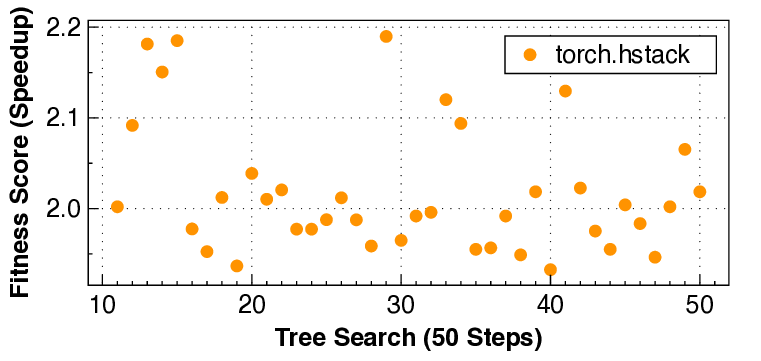
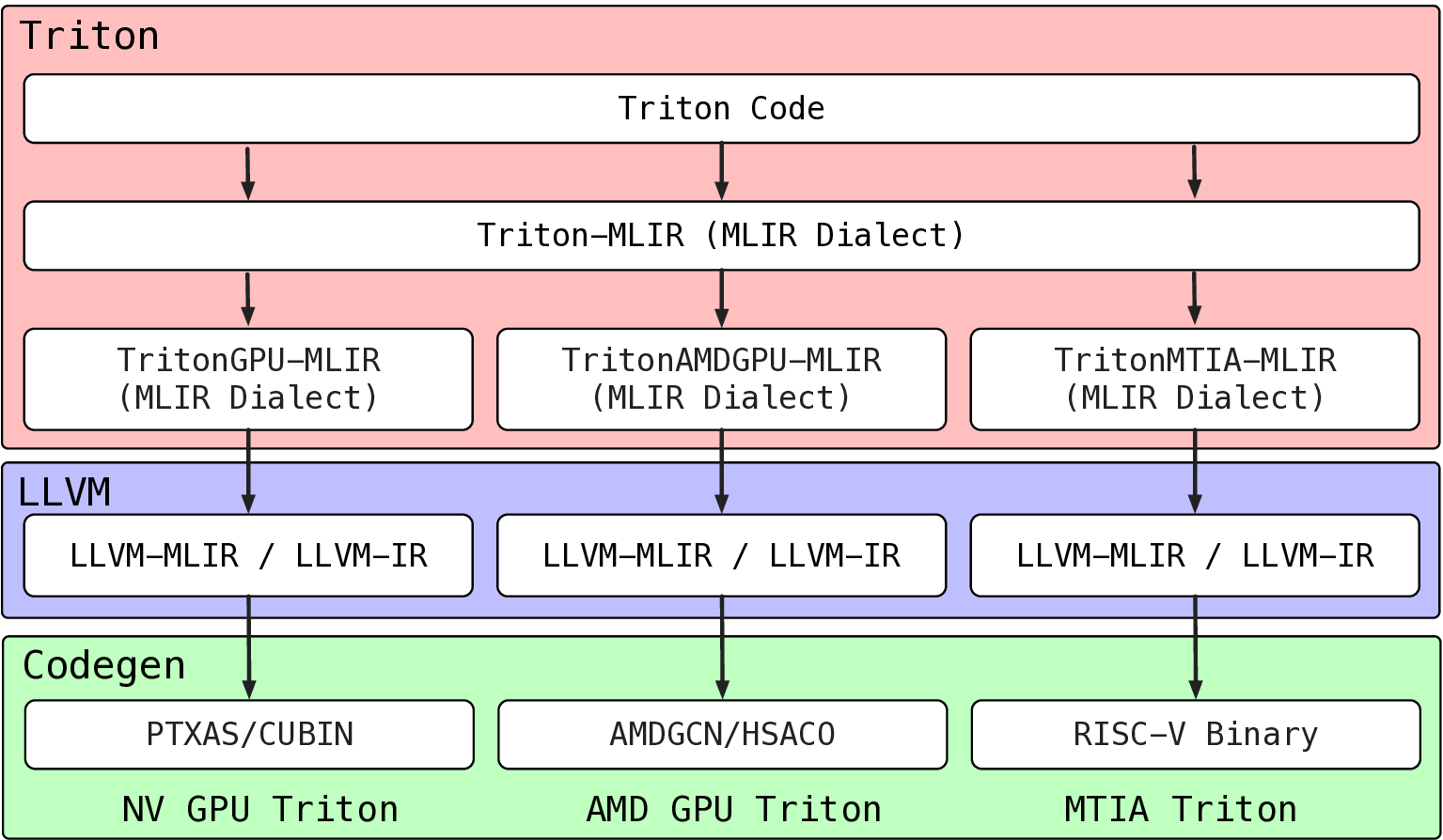
KernelEvolve 메타 이기종 AI 가속기용 에이전트 커널 코딩 확장
📝 원문 정보
- Title: KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta
- ArXiv ID: 2512.23236
- 발행일: 2025-12-29
- 저자: Gang Liao, Hongsen Qin, Ying Wang, Alicia Golden, Michael Kuchnik, Yavuz Yetim, Jia Jiunn Ang, Chunli Fu, Yihan He, Samuel Hsia, Zewei Jiang, Dianshi Li, Uladzimir Pashkevich, Varna Puvvada, Feng Shi, Matt Steiner, Ruichao Xiao, Nathan Yan, Xiayu Yu, Zhou Fang, Roman Levenstein, Kunming Ho, Haishan Zhu, Alec Hammond, Richard Li, Ajit Mathews, Kaustubh Gondkar, Abdul Zainul-Abedin, Ketan Singh, Hongtao Yu, Wenyuan Chi, Barney Huang, Sean Zhang, Noah Weller, Zach Marine, Wyatt Cook, Carole-Jean Wu, Gaoxiang Liu
📝 초록 (Abstract)
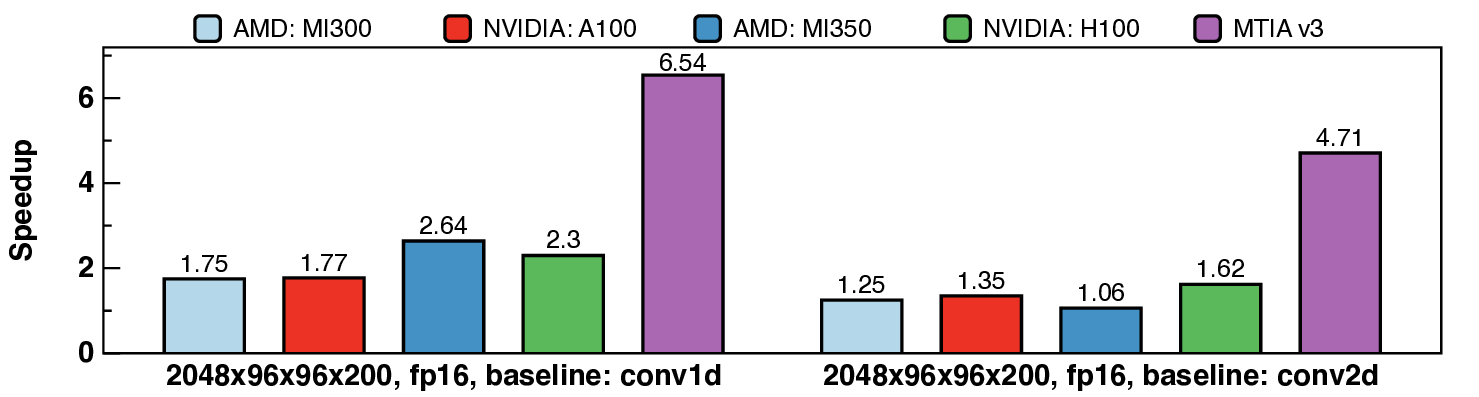
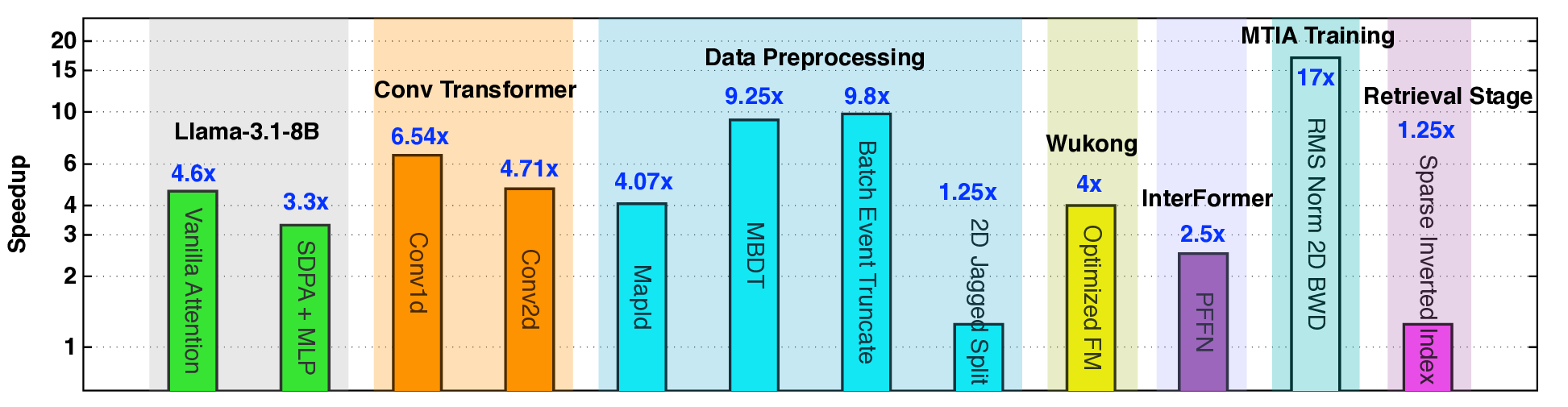
딥러닝 추천 모델(DLRM)의 학습 및 추론을 빠르고 효율적으로 수행하는 것은 매우 중요합니다. 그러나 모델 아키텍처 다양성, 커널 기본 연산 다양성, 그리고 하드웨어 세대·아키텍처 이기종성이라는 세 가지 핵심 시스템 과제가 존재합니다. 이 세 가지 다양성 차원의 결합은 복잡한 최적화 공간을 형성합니다. 본 논문은 이러한 이기종성을 대규모로 해결하기 위해 에이전트형 커널 코딩 프레임워크인 KernelEvolve를 제안합니다. KernelEvolve는 커널 사양을 입력으로 받아, Triton, CuTe DSL, 저수준 하드웨어 진단 언어 등 다양한 프로그래밍 추상화를 통해 이기종 하드웨어 아키텍처에 맞는 커널 생성 및 최적화를 자동화합니다. 커널 최적화 과정은 그래프 기반 탐색(선택 정책, 범용 연산자, 적합도 함수, 종료 규칙)으로 기술되며, 실행 시점 컨텍스트에 따라 검색 강화 프롬프트 합성을 통해 동적으로 적응합니다. 시스템은 하드웨어별 제약을 인코딩한 영구 지식베이스를 통합하여, LLM 학습 코퍼스에 포함되지 않은 독점 아키텍처에 대해서도 효과적인 커널 생성을 가능하게 합니다. 우리는 KernelEvolve를 설계·구현·배포하여 NVIDIA·AMD GPU와 Meta 최신 AI 가속기(MTIA v3) 등 다양한 세대의 하드웨어에서 생산 환경 추천 모델을 최적화했습니다. 공개된 KernelBench 스위트를 이용한 평가에서 250개의 문제(세 난이도)와 160개의 PyTorch ATen 연산자를 세 하드웨어 플랫폼에 걸쳐 100% 통과 및 100% 정확성을 달성했으며, 개발 시간을 주에서 시간으로 단축하고, PyTorch 기준 대비 최대 17배의 성능 향상을 기록했습니다. 또한 KernelEvolve는 새로운 AI 하드웨어에 대한 프로그래밍 장벽을 크게 낮추어, 독점 가속기에 대한 자동 커널 생성을 가능하게 합니다. 본 논문의 통찰과 배포 경험이 AI 시스템 및 대규모 최적화 설계에 새로운 시각을 제공하기를 기대합니다.💡 논문 핵심 해설 (Deep Analysis)
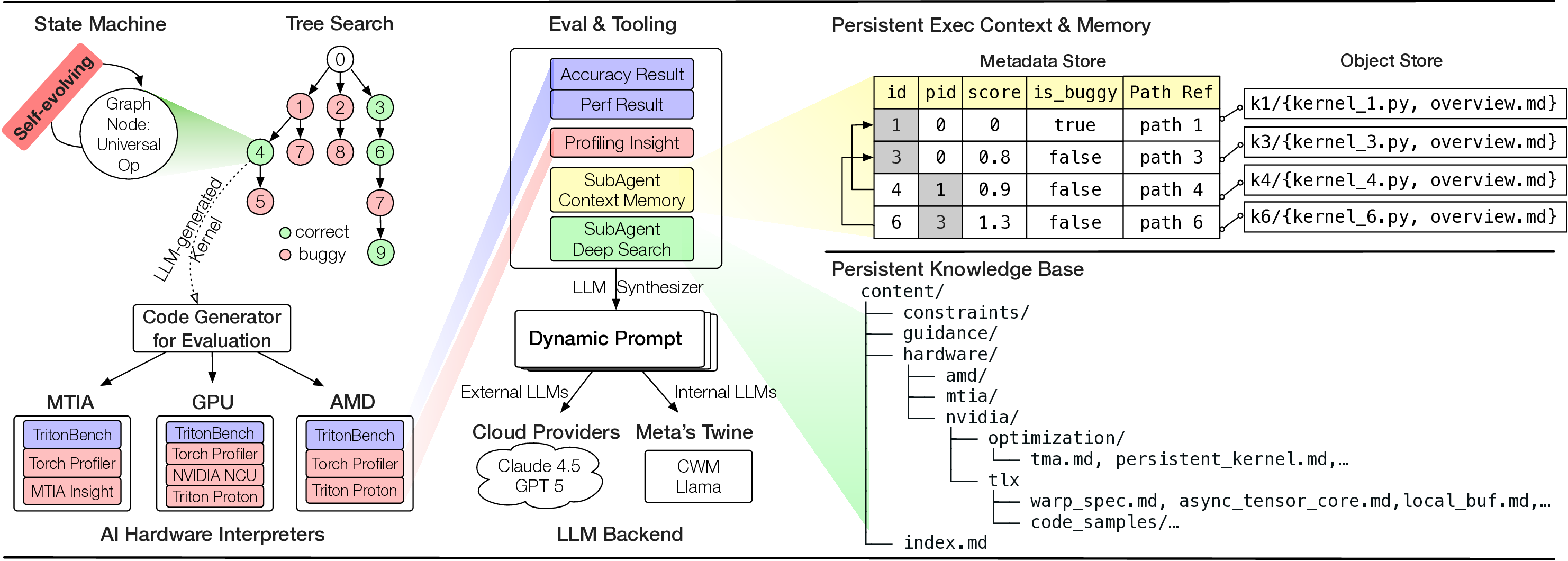
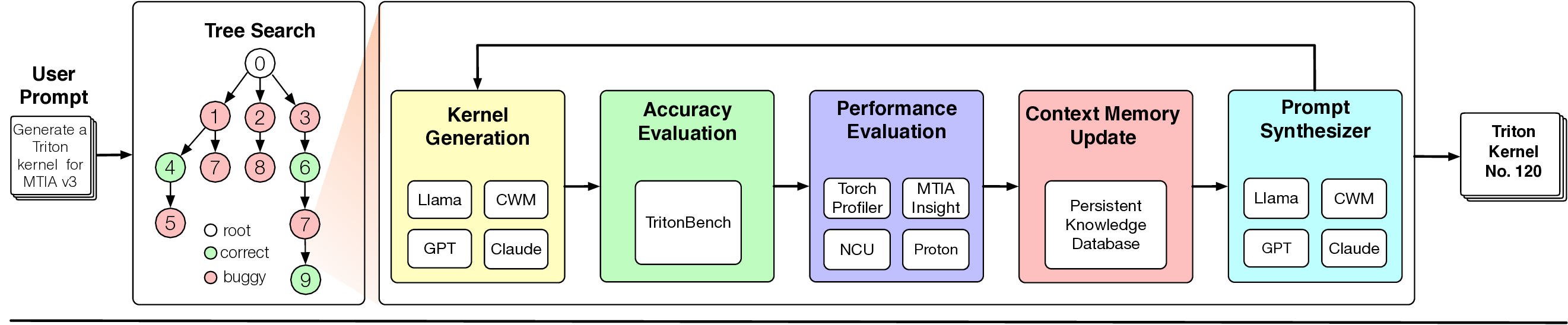
KernelEvolve는 이를 해결하기 위해 ‘에이전트형’ 접근을 채택한다. 입력된 커널 사양을 기반으로 Triton(고수준 텐서 언어), CuTe DSL(컴파일러 수준 DSL), 그리고 저수준 하드웨어 진단 언어와 같은 다중 추상화 레이어를 자동으로 선택·조합한다. 핵심은 그래프 기반 탐색 메커니즘이다. 여기서 각 노드는 가능한 구현 옵션(예: 메모리 레이아웃, 스레드 블록 크기, 레지스터 사용량)을 나타내며, 선택 정책은 강화학습 혹은 베이지안 최적화를 통해 적합도 함수를 최대화하도록 설계된다. 적합도 함수는 실행 시간, 메모리 대역폭 사용량, 전력 효율성 등을 종합적으로 평가하고, 종료 규칙은 수렴 기준 혹은 예산 제한에 따라 동적으로 결정된다.
특히 ‘검색 강화 프롬프트 합성(retrieval‑augmented prompt synthesis)’은 실행 시점 컨텍스트(예: 현재 GPU 온도, 메모리 파편화 정도, 워크로드 특성)를 실시간으로 조회하고, 이를 LLM 기반 프롬프트에 삽입해 보다 정확한 코드 생성 지시를 만든다. 이는 기존 정적 프롬프트 기반 코드 생성이 겪는 ‘컨텍스트 불일치’ 문제를 크게 완화한다.
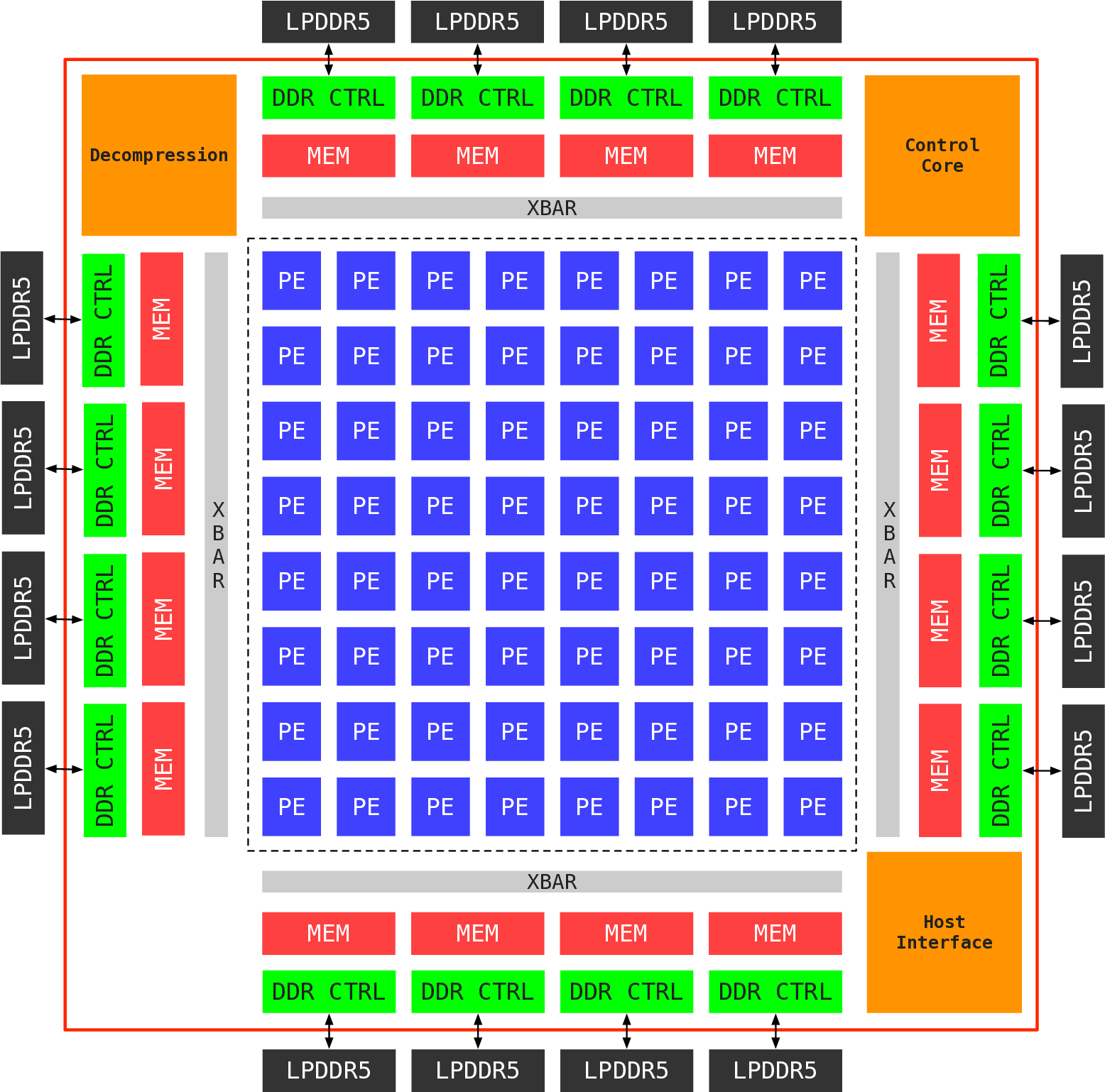
또한 영구 지식베이스는 하드웨어별 제약(예: MTIA v3의 전용 SIMD 명령, 메모리 계층 구조)과 최적화 경험을 메타데이터 형태로 저장한다. 이 베이스는 LLM이 학습 데이터에 포함되지 않은 독점 아키텍처에 대해서도 올바른 제약을 적용하도록 돕는다. 결과적으로, 개발자는 몇 주 걸리던 커널 튜닝 작업을 몇 시간 안에 완료할 수 있게 된다.
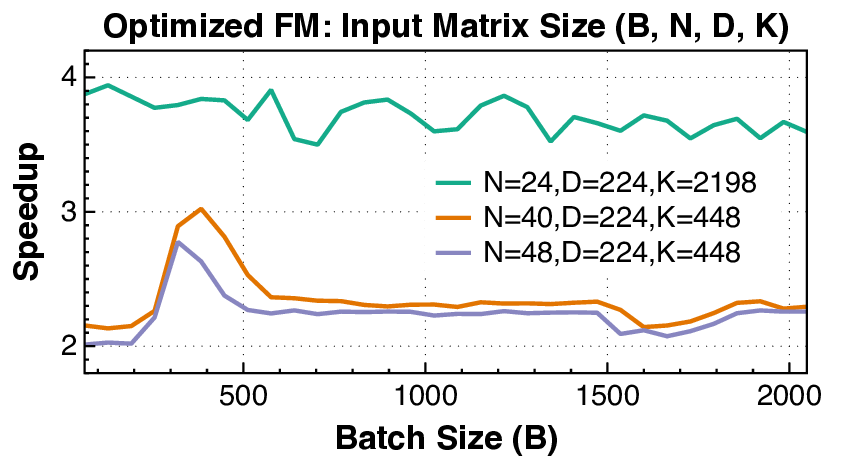
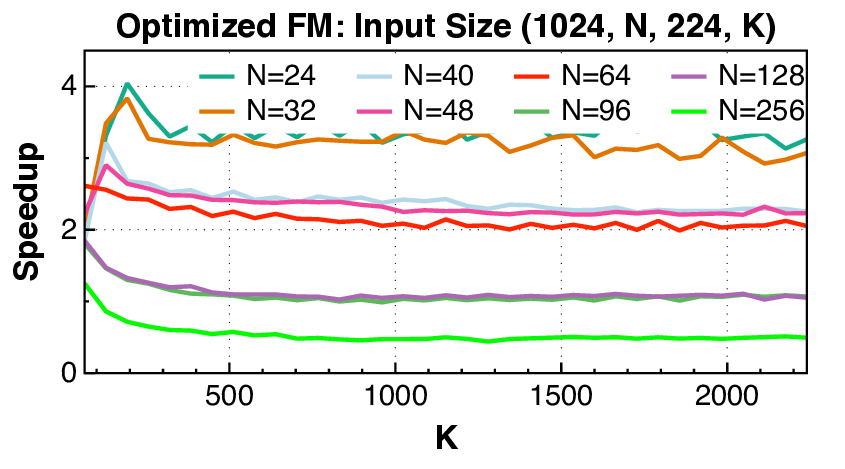
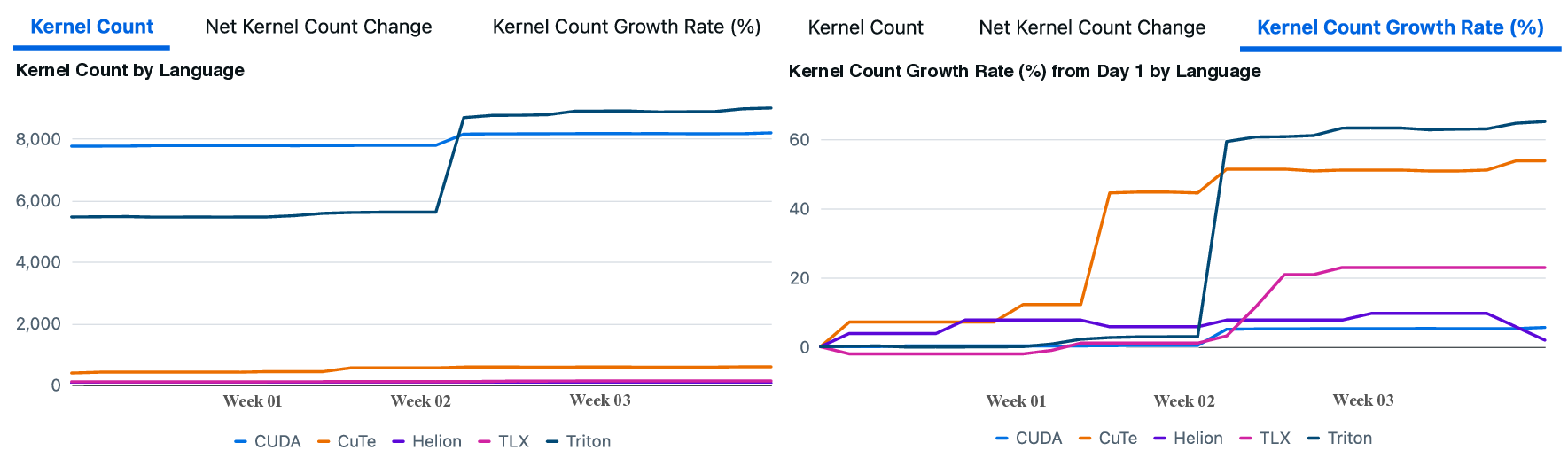
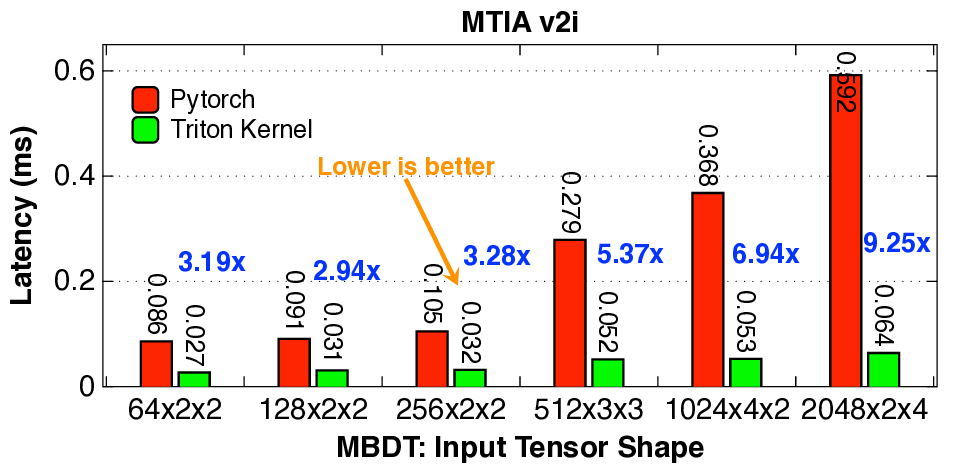
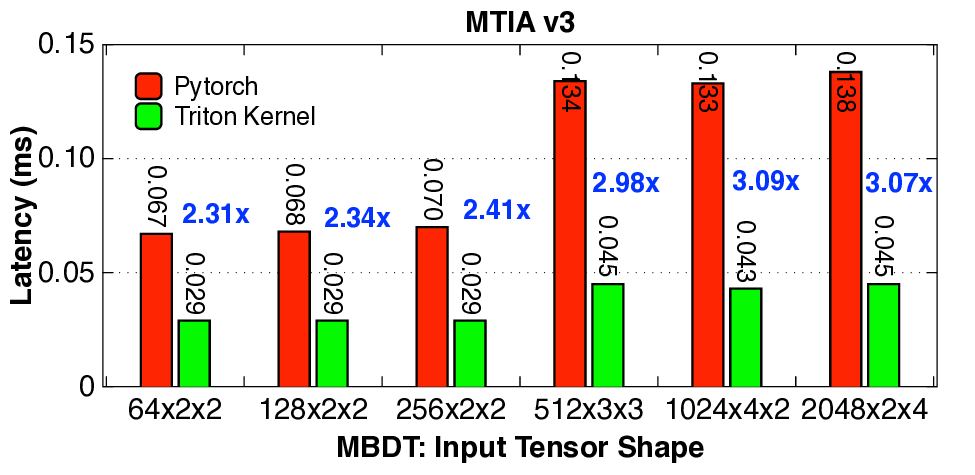
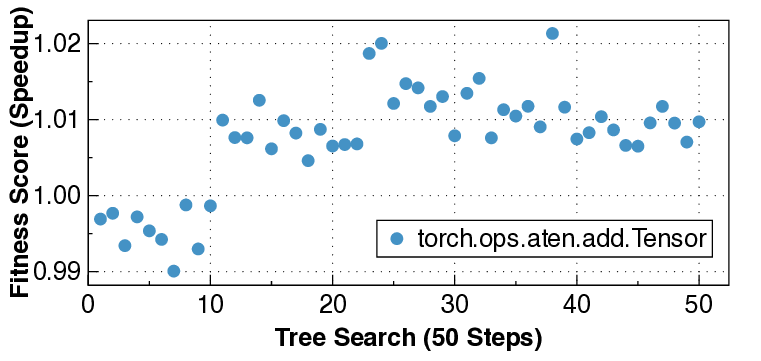
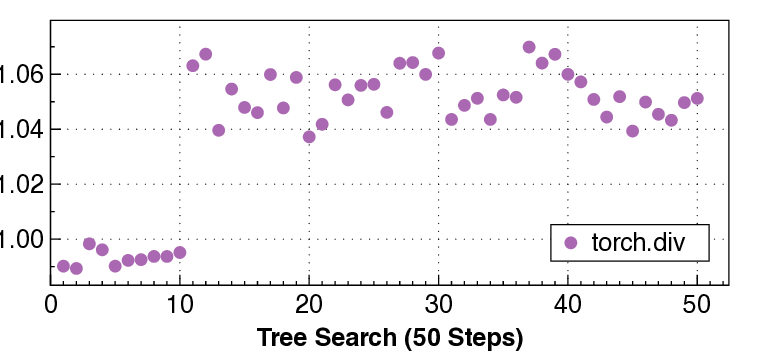
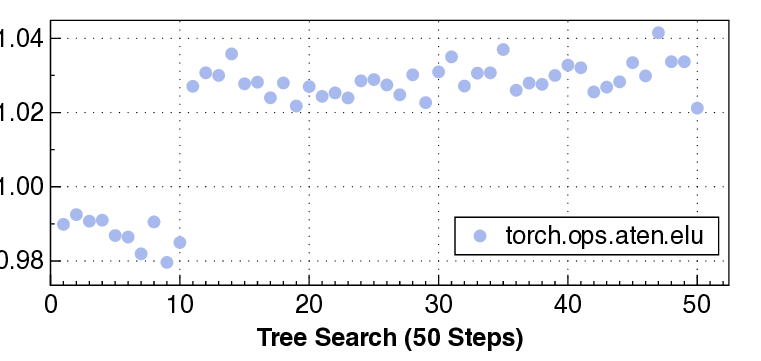
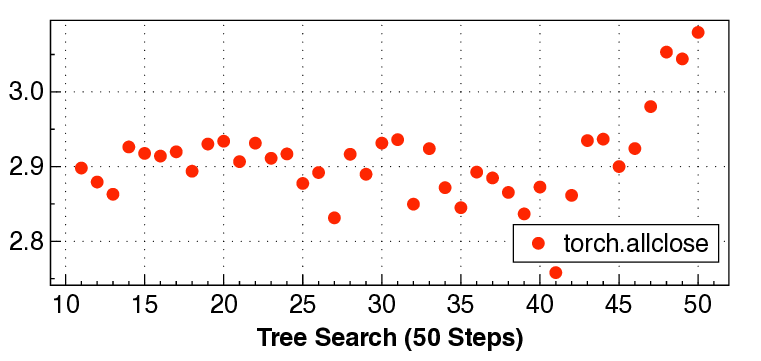
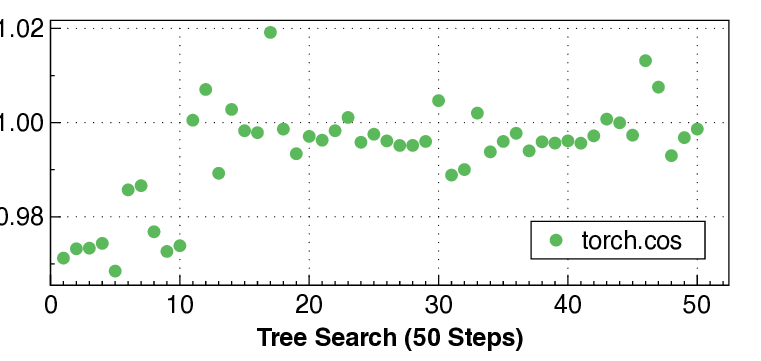
실험 결과는 설득력 있다. KernelBench 250문제 전부 100% 통과하고, 160개의 ATen 연산자를 3개 하드웨어에 걸쳐 480가지 조합 모두에서 정확성을 유지했다는 점은 자동 생성된 커널이 기능적으로도 신뢰할 수 있음을 증명한다. 성능 측면에서는 PyTorch 기준 대비 최대 17배 향상을 달성했으며, 이는 메모리 바운드 연산에서 레이턴시 감소, 컴퓨팅 바운드 연산에서 워프 스케줄링 최적화 등 다방면에 걸친 이득을 의미한다.
하지만 몇 가지 한계도 존재한다. 첫째, 그래프 탐색 비용이 매우 큰 경우(예: 수천 개의 옵션)에는 초기 탐색 단계에서 시간이 소요될 수 있다. 둘째, 현재는 주로 GPU와 MTIA v3에 초점을 맞추었으며, ASIC 기반 가속기나 FPGA와 같은 완전히 다른 프로그래밍 모델에 대한 적용 가능성은 추가 연구가 필요하다. 셋째, 지식베이스의 유지·갱신 비용이 존재한다는 점에서, 지속적인 하드웨어 릴리즈 주기에 맞춰 자동화된 업데이트 파이프라인이 요구된다.
향후 연구 방향으로는 (1) 메타러닝 기반 탐색 전략을 도입해 탐색 비용을 더욱 감소시키는 방안, (2) 멀티‑하드웨어 동시 최적화를 위한 협업 그래프 모델, (3) 지식베이스 자동 추출 및 검증 파이프라인 구축이 있다. 이러한 확장은 KernelEvolve를 단일 기업 내부 도구를 넘어, 오픈‑소스 커뮤니티와 학계가 공동 활용할 수 있는 범용 AI 가속기 최적화 플랫폼으로 진화시킬 가능성을 열어준다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리