보상 모델의 귀납적 편향을 정보 이론적 가이드로 제거
📝 원문 정보
- Title: Eliminating Inductive Bias in Reward Models with Information-Theoretic Guidance
- ArXiv ID: 2512.23461
- 발행일: 2025-12-29
- 저자: Zhuo Li, Pengyu Cheng, Zhechao Yu, Feifei Tong, Anningzhe Gao, Tsung-Hui Chang, Xiang Wan, Erchao Zhao, Xiaoxi Jiang, Guanjun Jiang
📝 초록 (Abstract)
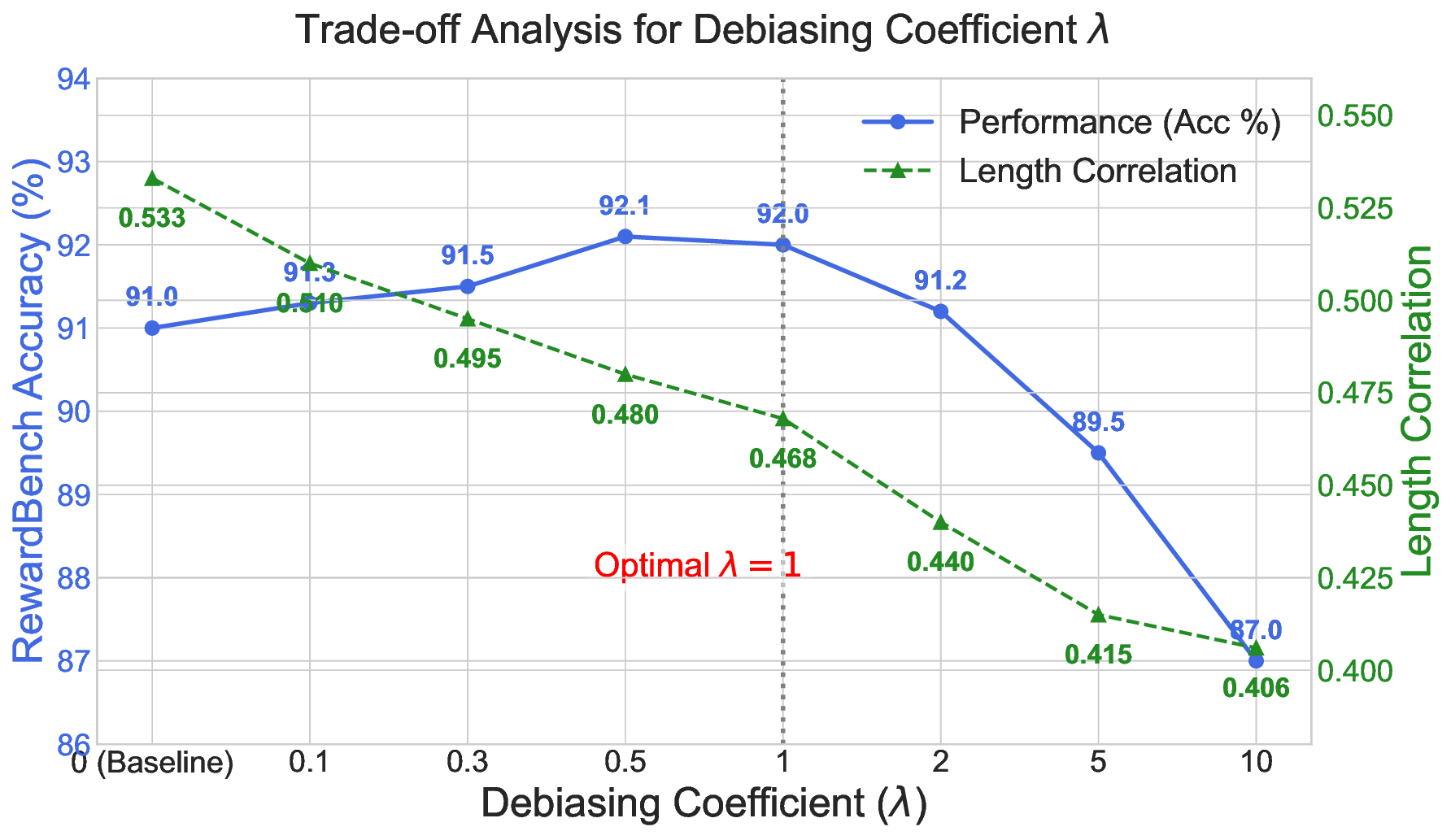
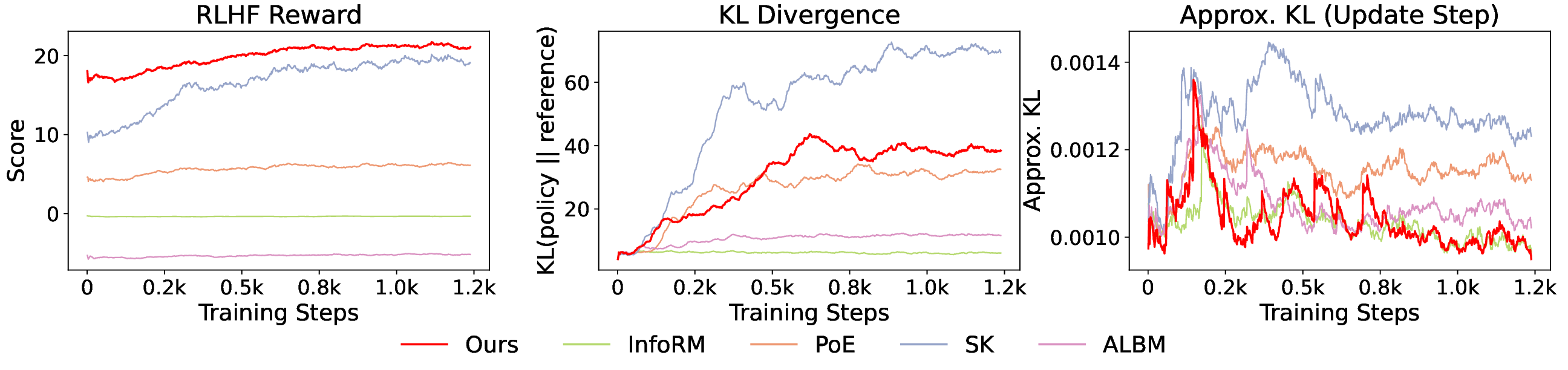
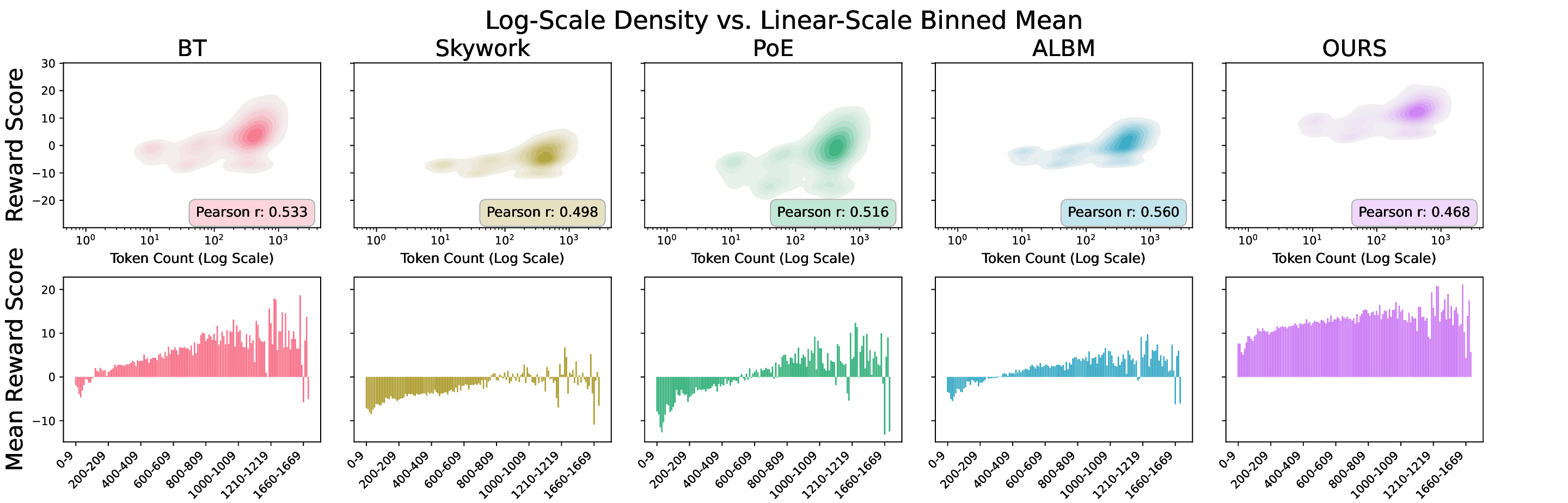
보상 모델(RM)은 인간 피드백을 통한 강화학습(RLHF)에서 대형 언어 모델(LLM)을 인간의 가치에 맞추는 핵심 요소이다. 그러나 RM 학습 데이터는 품질이 낮고, 상세하고 포괄적인 답변이 선호되는 경향 때문에 길이와 같은 귀납적 편향이 쉽게 포함된다. 기존의 RM 편향 완화 방법은 특정 편향 하나에만 초점을 맞추거나 피어슨 상관계수와 같은 단순 선형 관계만을 모델링한다. 보다 복잡하고 다양한 편향을 완화하기 위해, 우리는 정보 병목(IB)에서 영감을 얻은 새로운 정보‑이론적 편향 완화 기법인 DIR(Debiasing via Information optimization for RM)을 제안한다. DIR은 인간 선호 쌍과 RM 점수 사이의 상호정보량(MI)을 최대화하면서, RM 출력과 편향된 속성(예: 길이, 아첨, 형식) 사이의 MI를 최소화한다. 정보 이론에 기반한 이론적 정당성을 통해, DIR은 비선형 상관관계를 포함한 정교한 편향을 처리할 수 있어 실제 적용 범위를 크게 확장한다. 실험에서는 응답 길이, 아첨성, 포맷이라는 세 가지 편향에 대해 DIR의 효과를 검증했으며, 목표 편향을 효과적으로 완화함과 동시에 다양한 벤치마크에서 RLHF 성능을 향상시켜 일반화 능력이 개선됨을 확인했다. 코드와 학습 레시피는 https://github.com/Qwen-Applications/DIR 에서 제공한다.💡 논문 핵심 해설 (Deep Analysis)
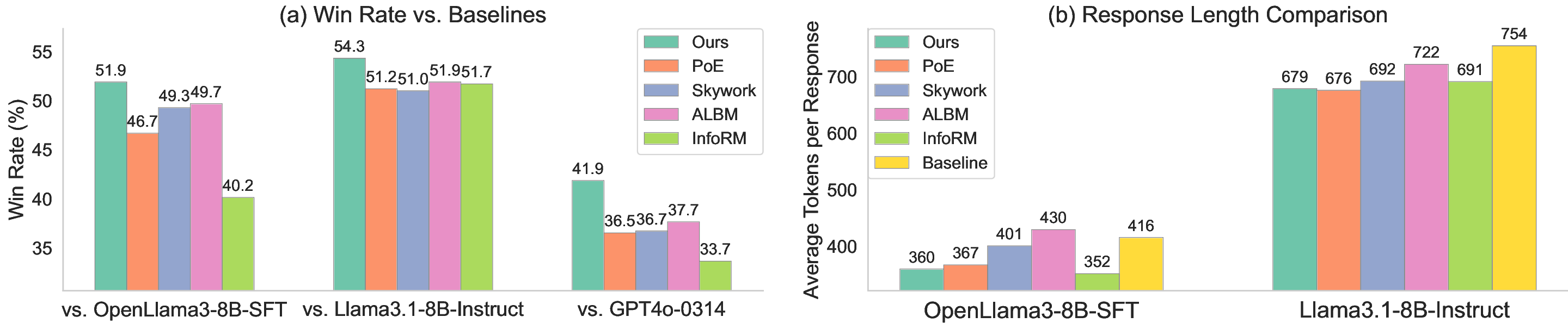
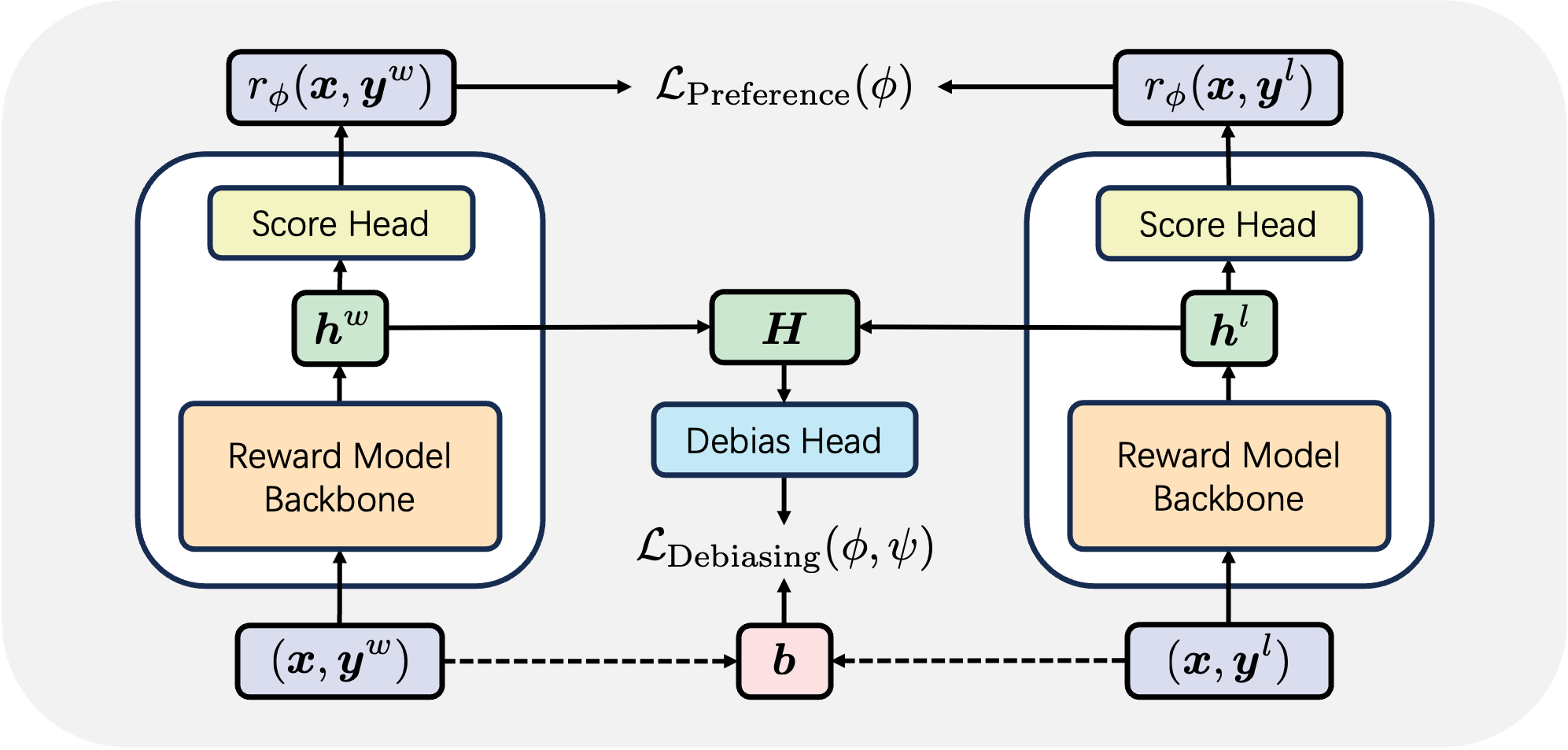
DIR은 이러한 한계를 극복하기 위해 정보 병목(Information Bottleneck, IB) 원리를 차용한다. IB는 입력 변수와 출력 변수 사이의 상호정보량을 최대화하면서, 중간 표현과 입력 사이의 상호정보량을 최소화함으로써 불필요한 정보를 압축한다. 이를 RM에 적용하면, “인간 선호 쌍 ↔ RM 점수” 사이의 MI를 높여 모델이 실제 선호 신호를 잘 포착하도록 하고, 동시에 “RM 출력 ↔ 편향 속성(예: 길이, 아첨, 포맷)” 사이의 MI를 낮춤으로써 편향된 특성이 점수에 미치는 영향을 억제한다.
구체적인 최적화 목표는 다음과 같다.
\
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리