SAE 기반 저차원 서브스페이스로 해석 가능한 안전 정렬
📝 원문 정보
- Title: Interpretable Safety Alignment via SAE-Constructed Low-Rank Subspace Adaptation
- ArXiv ID: 2512.23260
- 발행일: 2025-12-29
- 저자: Dianyun Wang, Qingsen Ma, Yuhu Shang, Zhifeng Lu, Zhenbo Xu, Lechen Ning, Huijia Wu, Zhaofeng He
📝 초록 (Abstract)
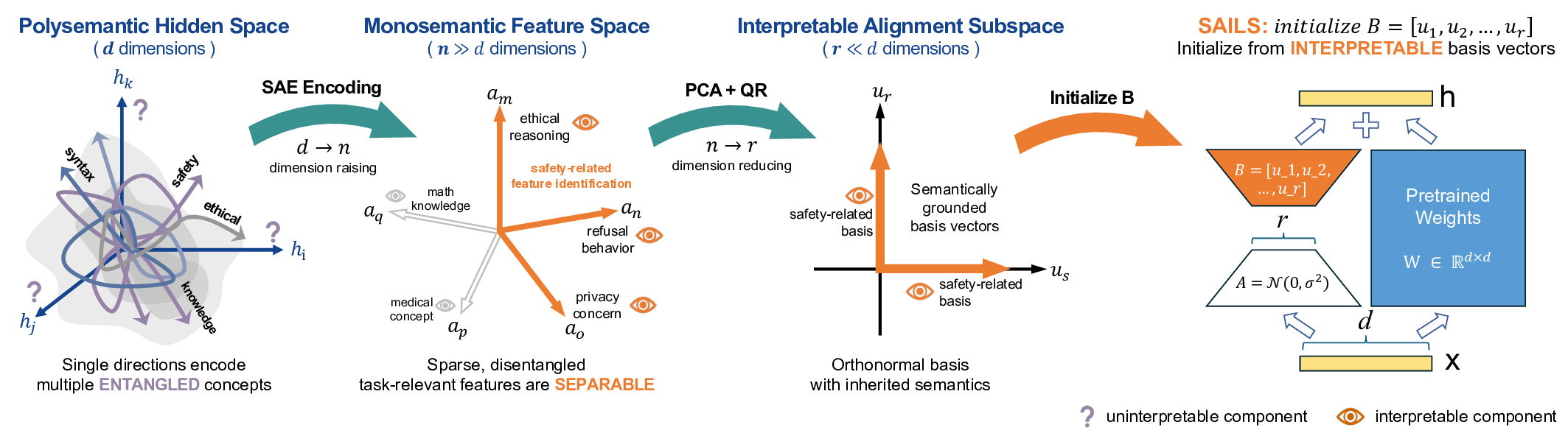
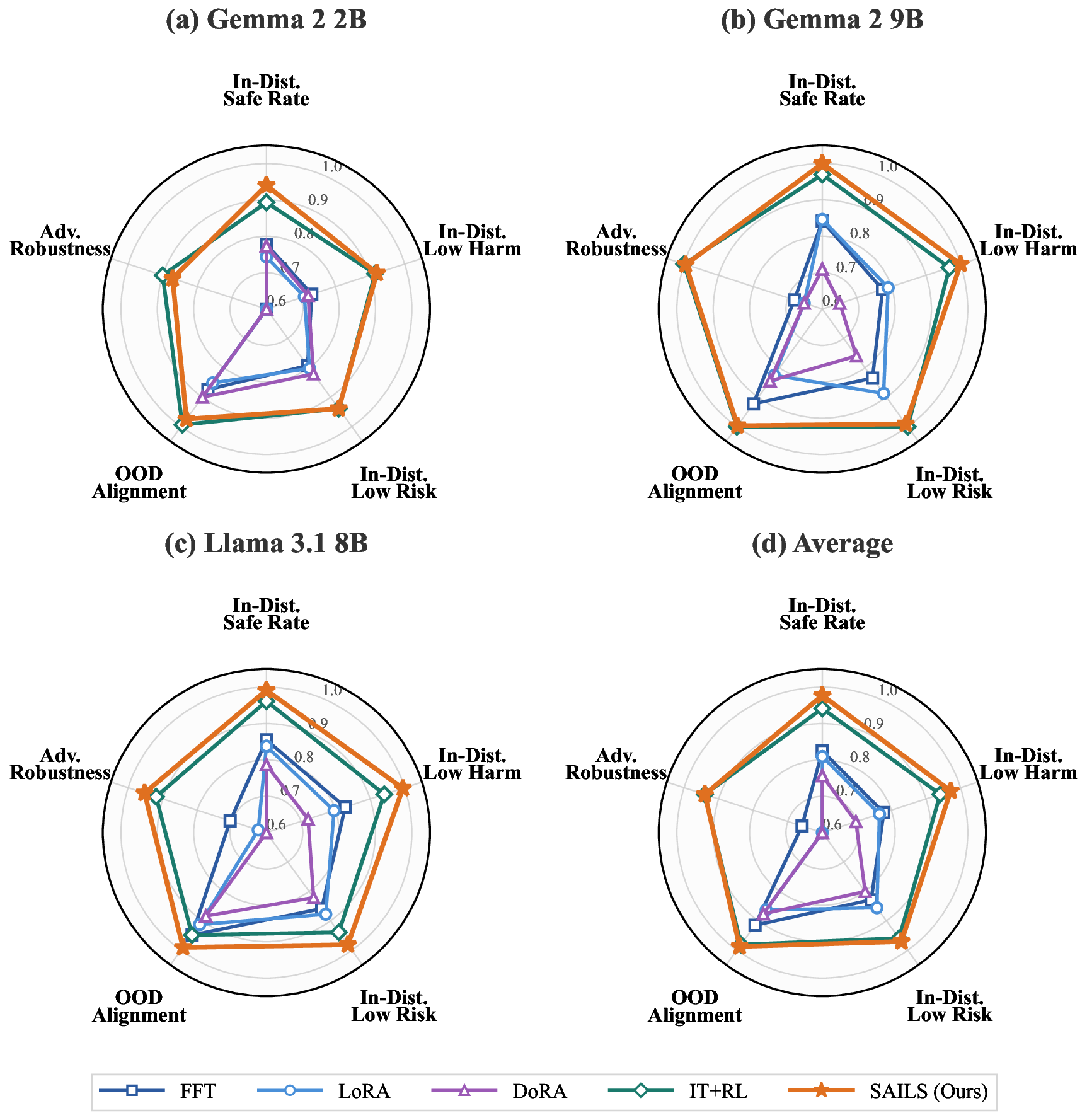
안전 정렬은 대형 언어 모델(LLM)을 해로운 요청을 거부하면서도 유용하게 유지하도록 훈련하는 핵심 과제이다. 기존 연구는 안전 행동이 저차원 구조에 의해 지배된다는 점을 밝혀, 파라미터 효율적인 미세조정(PEFT)이 정렬에 적합할 것이라 기대했다. 그러나 저차원 적응(Low‑Rank Adaptation, LoRA)은 안전 벤치마크에서 전통적인 전체 미세조정 및 강화학습(RL)보다 일관되게 성능이 뒤떨어졌다. 이는 안전과 관련된 방향이 다중 의미(polysemantic) 특성 때문에 무관한 개념과 얽혀 있어, 암묵적인 서브스페이스 식별이 방해받기 때문이라고 본다. 이를 해결하기 위해 우리는 SAILS( Safety Alignment via Interpretable Low‑rank Subspace)를 제안한다. SAILS는 희소 자동인코더(SAE)를 활용해 표현을 단일 의미(monosemantic) 특징으로 분해하고, SAE 디코더의 방향을 이용해 해석 가능한 안전 서브스페이스를 구성한 뒤, 이를 LoRA 어댑터의 초기값으로 사용한다. 이론적으로 우리는 SAE 기반 식별이 단일 의미 가정 하에 회복 오차를 임의로 작게 만들 수 있음을 증명하고, 직접 식별은 불가피한 오차 한계에 머문다. 실험 결과 SAILS는 Gemma‑2‑9B 모델에서 안전 비율을 99.6%까지 끌어올려, 전체 미세조정보다 7.4 포인트 높이고 RLHF 기반 모델과 동등한 수준을 달성했으며, 전체 파라미터의 0.19%만 업데이트하고 해석 가능성을 제공한다. 그래프는 Gemma‑2‑2B, Gemma‑2‑9B, Llama‑3.1‑8B에 대한 인‑도메인 안전 비율, 저위험·저해악, OOD 정렬, 공격 견고성 등을 비교한다.💡 논문 핵심 해설 (Deep Analysis)
이러한 문제를 해결하기 위해 도입된 것이 Sparse Autoencoder(SAE)이다. SAE는 대규모 언어 모델의 내부 활성화를 희소하고 선형적인 토큰 수준 특징으로 압축한다. 중요한 점은 SAE가 학습 과정에서 각 디코더 방향이 가능한 한 단일 의미를 담당하도록 강제한다는 점이다. 즉, “monosemantic” 특성을 갖는 특징 벡터를 얻음으로써, 안전과 직접적으로 연관된 방향을 명시적으로 식별할 수 있다. 논문에서는 SAE 디코더의 가중치를 분석해 “안전”이라는 라벨이 높은 활성화를 보이는 몇몇 차원을 선택하고, 이를 기반으로 안전 서브스페이스를 정의한다. 이렇게 정의된 서브스페이스는 인간이 직관적으로 이해할 수 있는 의미를 가지고 있어, “interpretability”라는 부가 가치를 제공한다.
이후 이 서브스페이스를 LoRA 어댑터의 초기값으로 사용한다. 기존 LoRA는 무작위 초기화 후 데이터에 맞춰 학습하지만, SAILS는 안전 서브스페이스와 정렬된 초기값을 제공함으로써 학습이 시작될 때부터 올바른 방향을 추적한다. 이론적 증명에서는 단일 의미 가정 하에 SAE 기반 식별이 오차를 임의로 작게 만들 수 있음을 보이며, 반대로 직접적인 저차원 서브스페이스 추정은 다중 의미성으로 인해 최소한의 오차 한계가 존재한다는 점을 수학적으로 증명한다.
실험에서는 Gemma‑2‑9B, Gemma‑2‑2B, Llama‑3.1‑8B 등 다양한 모델에 대해 인‑도메인 안전 비율, 저위험·저해악, OOD 정렬, 공격 견고성 등을 포괄적으로 평가한다. 특히 Gemma‑2‑9B에 대해 SAILS는 안전 비율 99.6%를 달성했으며, 이는 전체 파인튜닝보다 7.4 포인트 높은 수치이다. 또한 파라미터 업데이트 비율은 0.19%에 불과해, 기존 방법에 비해 효율성이 크게 향상되었다. RLHF 기반 모델과도 성능이 거의 동등함을 보여, 안전 정렬에 있어 고비용 강화학습 없이도 경쟁력 있는 결과를 얻을 수 있음을 입증한다.
이 논문의 의의는 세 가지로 요약할 수 있다. 첫째, 안전 정렬에 있어 “semantic entanglement”이 핵심 장애 요인임을 실증적으로 제시한다. 둘째, SAE를 활용한 “monosemantic” 특징 추출이 이러한 얽힘을 해소하고 해석 가능한 서브스페이스를 제공한다는 새로운 패러다임을 제시한다. 셋째, 이 서브스페이스를 PEFT와 결합함으로써 파라미터 효율성, 성능, 해석 가능성을 동시에 달성한다는 점이다. 앞으로는 SAE의 규모와 훈련 데이터, 그리고 다양한 도메인에 대한 일반화 능력을 탐색함으로써, 안전 정렬뿐 아니라 윤리·편향 정렬 등 다른 정렬 문제에도 확장 적용할 가능성이 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리