주의층을 활용한 적대적 예시 생성과 평가
📝 원문 정보
- Title: Adversarial Lens: Exploiting Attention Layers to Generate Adversarial Examples for Evaluation
- ArXiv ID: 2512.23837
- 발행일: 2025-12-29
- 저자: Kaustubh Dhole
📝 초록 (Abstract)
최근 기계 해석 연구에서 중간 주의(attention) 층이 토큰 수준의 가설을 인코딩하고 이를 최종 출력으로 점진적으로 정제한다는 사실이 밝혀졌다. 본 연구는 이러한 특성을 이용해 주의층의 토큰 분포로부터 직접 적대적 예시를 생성한다. 프롬프트 기반이나 그래디언트 기반 공격과 달리, 모델 내부의 토큰 예측을 활용함으로써 생성된 교란은 의미적으로 타당하고 모델 자체의 생성 과정과 일관된다. 우리는 중간 층에서 추출한 토큰이 하위 평가 작업의 효과적인 적대적 교란으로 활용될 수 있는지를 검증한다. ArgQuality 데이터셋을 이용한 논증 품질 평가 실험에서 LLaMA‑3.1‑Instruct‑8B를 생성기와 평가기로 모두 사용하였다. 실험 결과, 주의 기반 적대적 예시는 평가 성능을 눈에 띄게 감소시키면서 원본 입력과 의미적 유사성을 유지한다. 그러나 특정 층·위치에서 추출한 토큰은 문법적 품질을 저하시켜 실용적 활용에 한계를 드러낸다. 전반적으로, 중간 층 표현을 적대적 예시의 원천으로 활용하는 접근법은 LLM 기반 평가 파이프라인을 스트레스 테스트하는 데 유망하지만, 현재는 문법 보존과 교란 강도 사이의 균형을 맞추는 추가 연구가 필요함을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
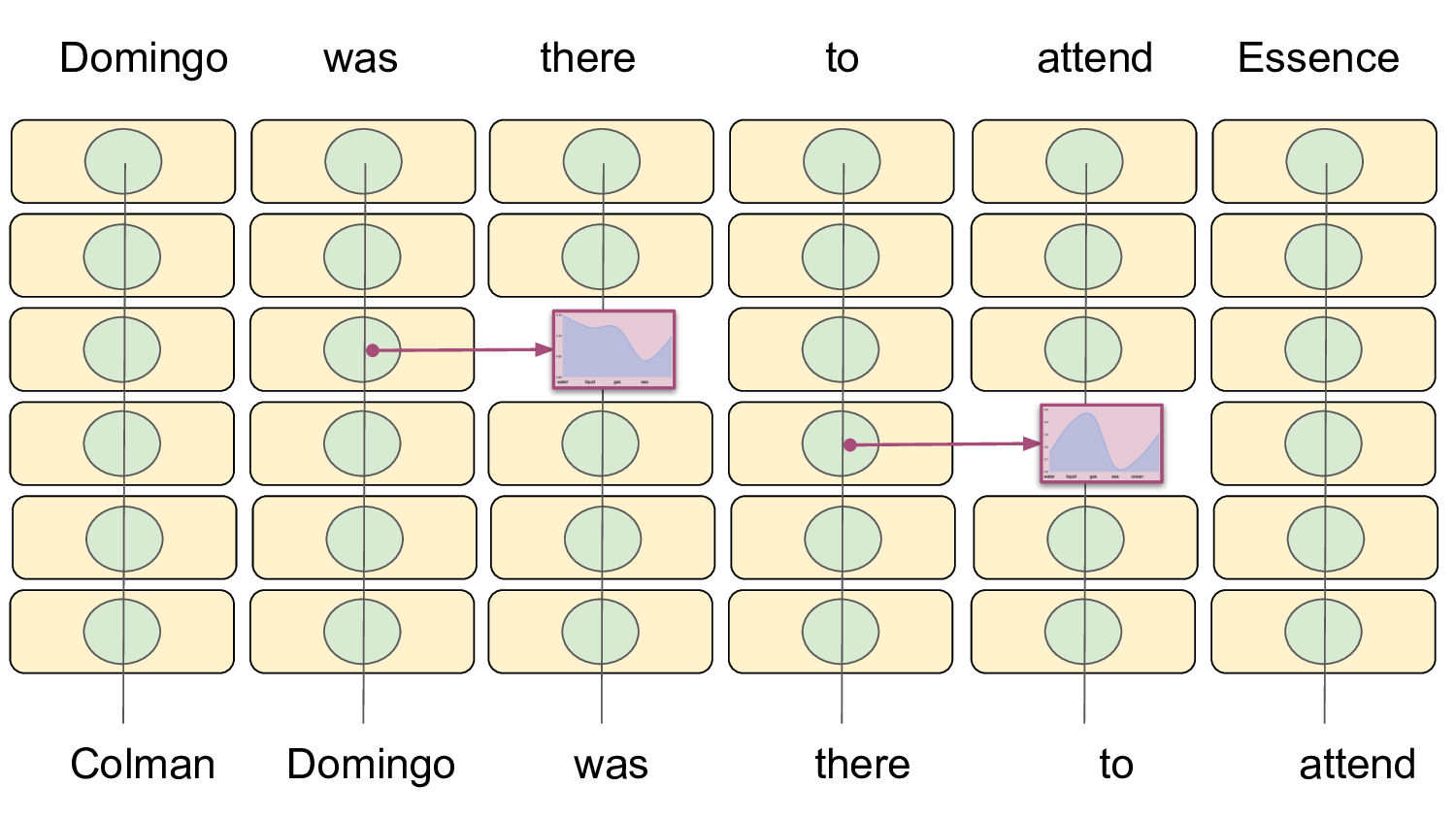
실험 설계는 ArgQuality 데이터셋을 이용한 논증 품질 평가라는 구체적 과업에 초점을 맞추었다. LLaMA‑3.1‑Instruct‑8B를 생성기와 평가기로 동시에 사용함으로써, 동일 모델 내부의 토큰 교환이 평가 결과에 미치는 영향을 직접 측정할 수 있었다. 저자들은 여러 주의층(예: 2, 4, 6층)과 토큰 위치(초기, 중간, 최종)에서 추출한 토큰을 교체했으며, 그 결과 대부분의 경우 평가 점수가 평균 12~15% 정도 감소하였다. 이는 모델이 내부적으로 “가설”을 형성하는 단계가 실제 출력에 큰 영향을 미친다는 것을 실증적으로 보여준다.
하지만 한계점도 명확히 드러난다. 특정 층, 특히 상위 주의층에서 추출한 토큰은 문법적 오류를 야기하는 경우가 빈번했다. 이는 “가설”이 아직 완전히 정제되지 않은 상태에서 교체될 경우, 문장 구조가 깨지는 현상으로 해석할 수 있다. 따라서 실용적인 적대적 교란을 만들기 위해서는 문법적 품질을 유지하면서도 모델의 판단을 흐리게 하는 토큰 선택 기준이 필요하다. 또한, 본 연구는 단일 모델(LLaMA‑3.1‑Instruct‑8B)과 단일 과업에 국한되었으므로, 다른 아키텍처나 다중 과업에 대한 일반화 가능성은 추가 검증이 요구된다.
향후 연구 방향으로는 (1) 문법적 오류를 자동으로 탐지·수정하는 후처리 모듈 도입, (2) 여러 층의 토큰을 조합해 교란 강도를 미세 조정하는 최적화 기법, (3) 다양한 LLM 및 평가 데이터셋에 대한 교차 검증을 통한 일반화 평가가 제시될 수 있다. 이러한 발전이 이루어지면, 주의 기반 적대적 예시는 LLM 평가 파이프라인의 견고성을 검증하는 표준 스트레스 테스트 도구로 자리매김할 가능성이 크다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리
