고위험 레버리지 선물 거래를 위한 효율·위험인식 앙상블 강화학습
📝 원문 정보
- Title: FineFT: Efficient and Risk-Aware Ensemble Reinforcement Learning for Futures Trading
- ArXiv ID: 2512.23773
- 발행일: 2025-12-29
- 저자: Molei Qin, Xinyu Cai, Yewen Li, Haochong Xia, Chuqiao Zong, Shuo Sun, Xinrun Wang, Bo An
📝 초록 (Abstract)
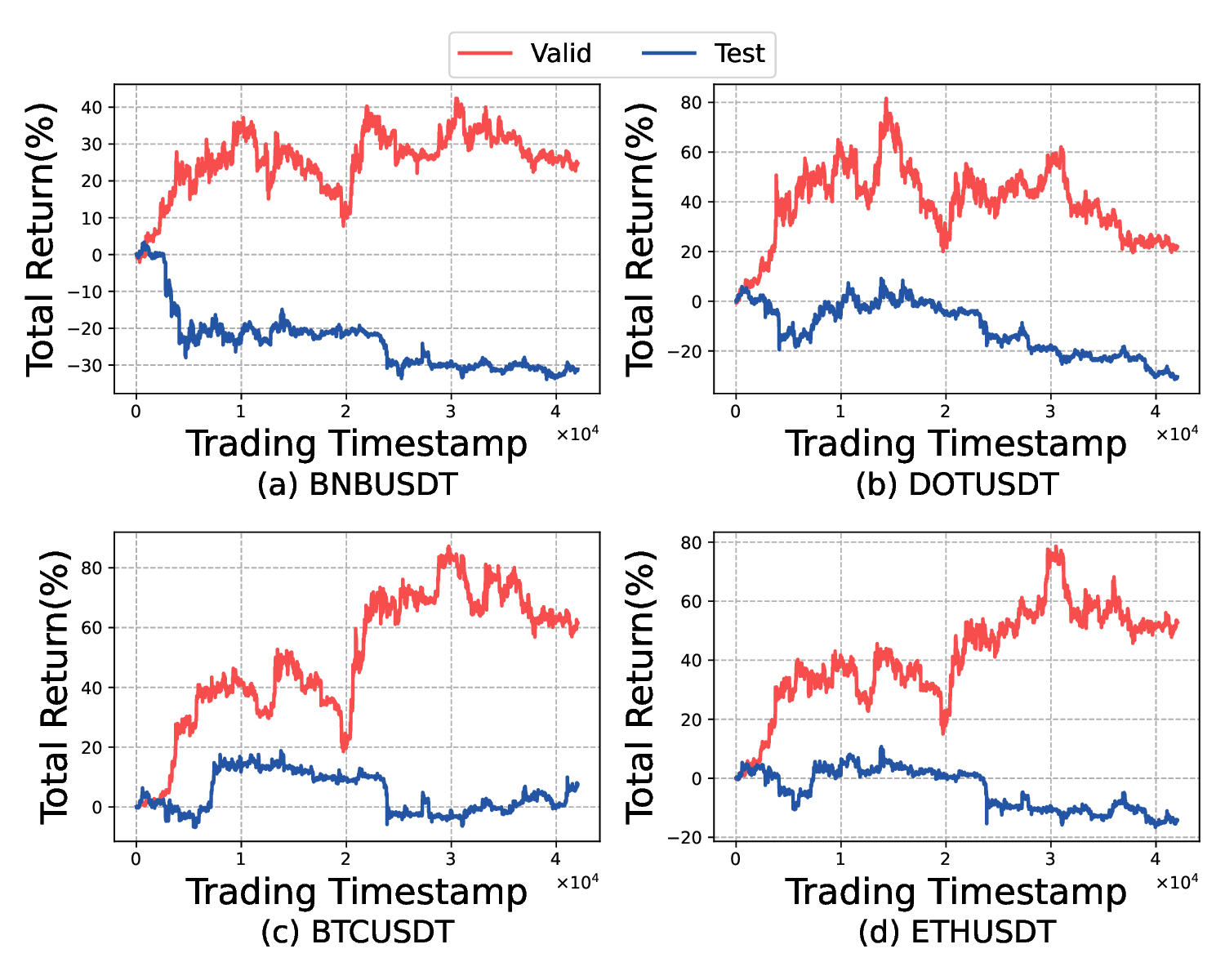
** 선물은 사전에 정해진 날짜와 가격에 자산을 교환하도록 하는 계약으로, 높은 레버리지(예: 5배)와 거대한 유동성(수조 달러 규모) 때문에 암호화폐 시장에서 활발히 이용된다. 강화학습(RL)은 다양한 양적 투자 과제에 널리 적용되어 왔지만, 기존 대부분의 방법은 현물(예: 주식) 거래에 초점을 맞추고 있어 높은 레버리지를 갖는 선물 시장에 바로 적용하기 어렵다. 그 이유는 첫째, 높은 레버리지가 보상 변동성을 크게 확대해 학습이 매우 불안정하고 수렴이 어려워진다. 둘째, 기존 연구는 자신의 역량 한계를 인식하지 못해, 코로나19와 같은 블랙스완 상황에서 이전에 보지 못한 시장 상태에 직면했을 때 큰 자본 손실 위험에 노출된다. 이를 해결하기 위해 우리는 세 단계로 구성된 앙상블 RL 프레임워크인 FineFT를 제안한다. ① 단계 I에서는 앙상블 Q‑학습기들을 각 학습기의 TD 오차를 활용한 선택적 업데이트 방식으로 훈련시켜 수렴 속도와 성능을 향상시킨다. ② 단계 II에서는 다양한 시장 동역학 하에서 수익성을 기준으로 Q‑학습기들을 필터링하고, 각 동역학에 대한 시장 표현을 VAE에 학습시켜 학습기들의 역량 경계를 파악한다. ③ 단계 III에서는 학습된 VAE가 새로운 시장 상태를 감지하면, 필터링된 앙상블과 보수적 정책 중 하나를 동적으로 선택해 수익성을 유지하고 위험을 완화한다. 고주파, 5배 레버리지를 적용한 암호화폐 선물 환경에서 12개의 최신 베이스라인과 6가지 금융 지표를 사용한 광범위한 실험 결과, FineFT는 위험을 40 % 이상 감소시키면서도 수익성에서 최고 성과를 기록했으며, 시각화된 선택적 업데이트 메커니즘은 각 에이전트가 서로 다른 시장 동역학에 특화됨을 보여준다.**
💡 논문 핵심 해설 (Deep Analysis)
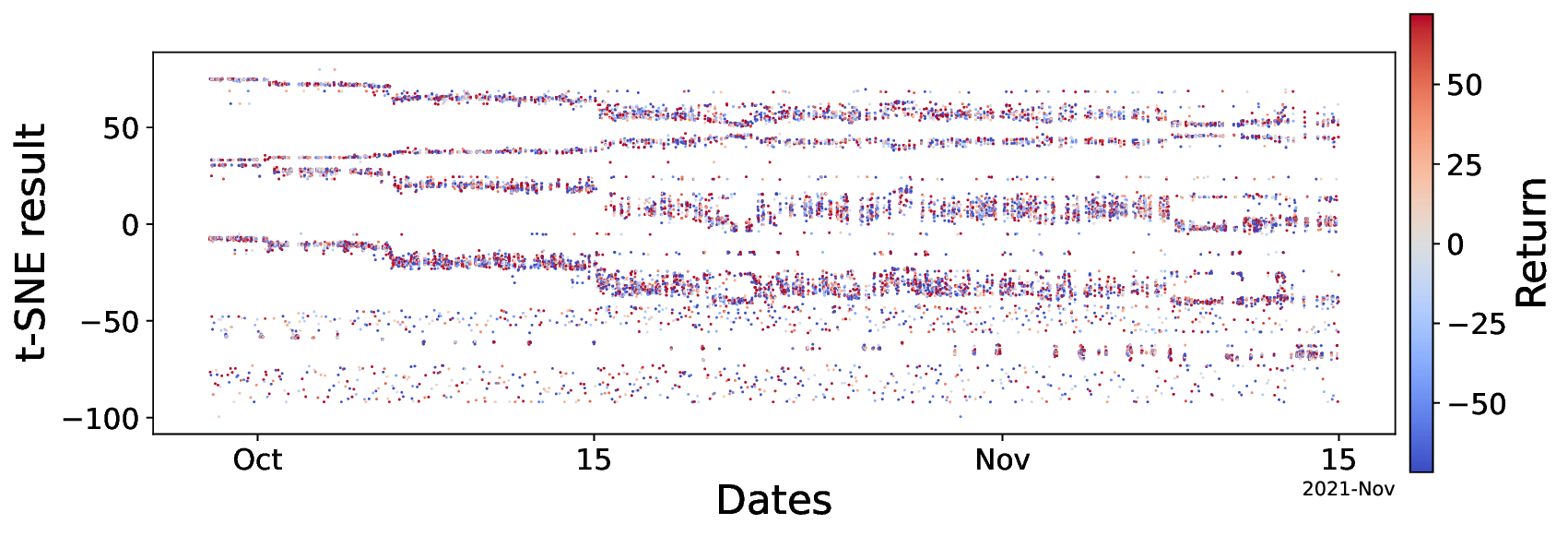
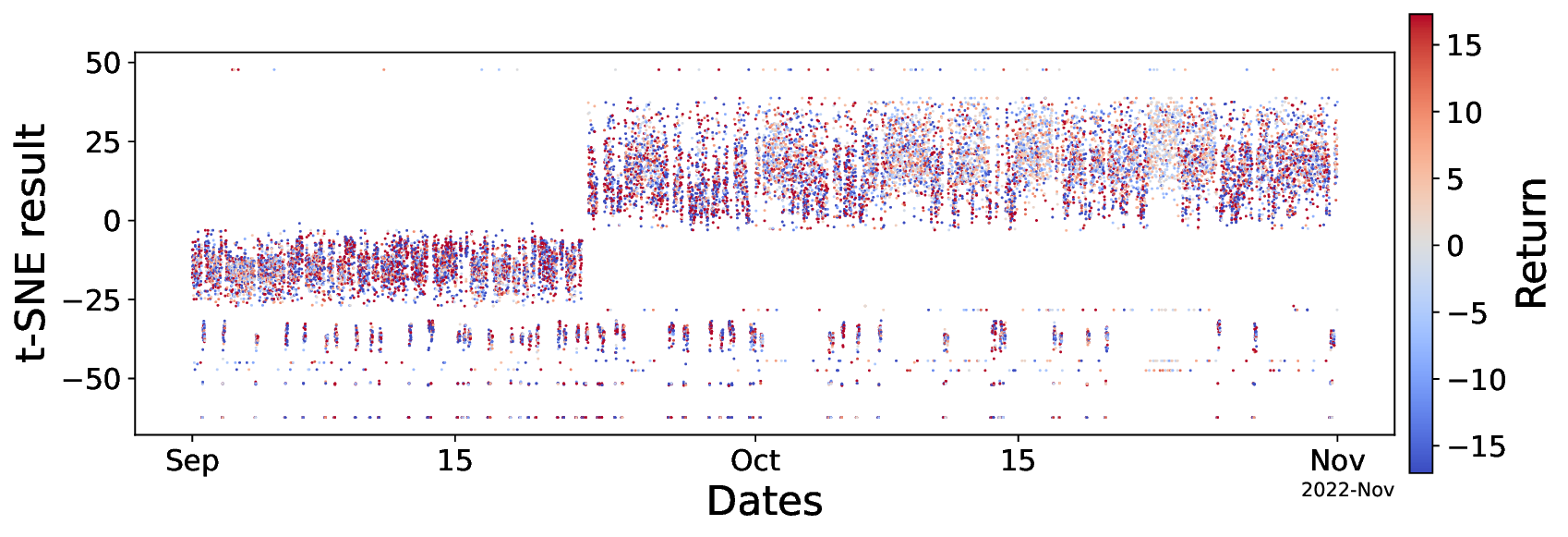
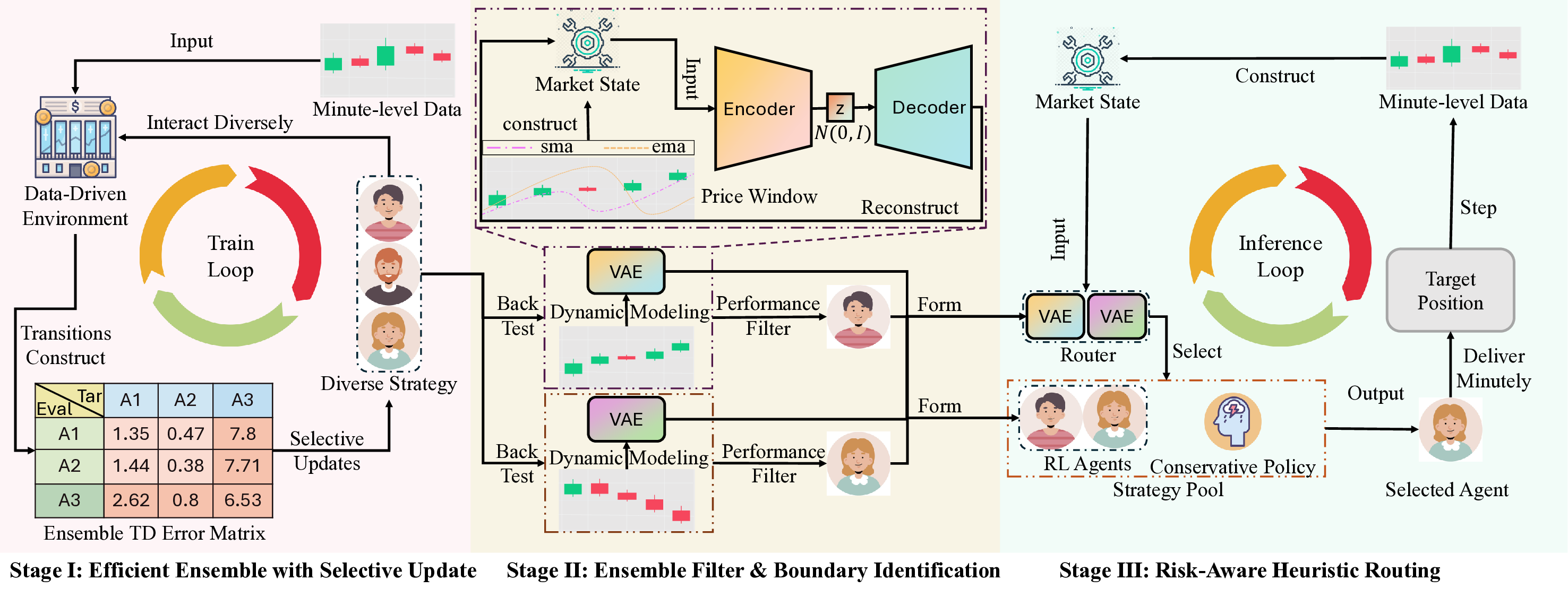
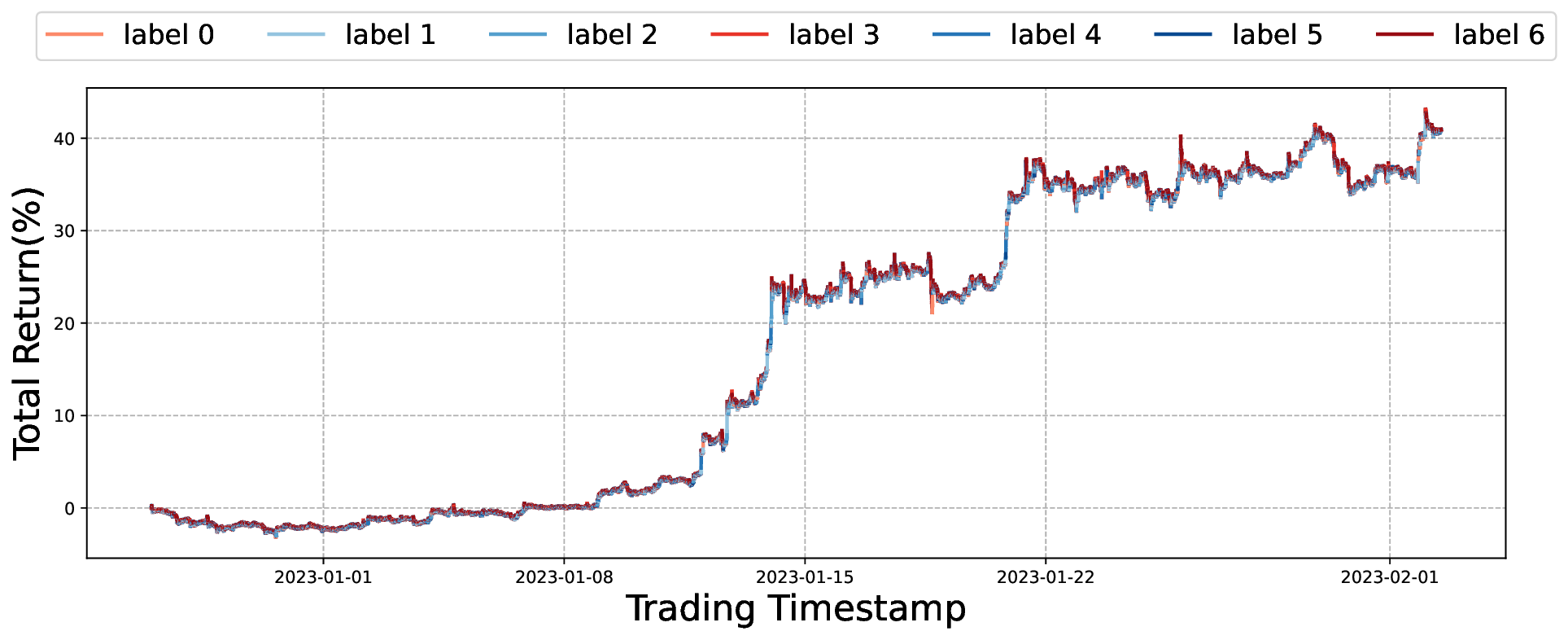
FineFT 논문은 레버리지가 높은 선물 시장, 특히 변동성이 극심한 암호화폐 선물에 특화된 강화학습 프레임워크를 제시한다는 점에서 학술적·실무적 의의가 크다. 기존 RL 기반 트레이딩 연구는 대부분 현물 주식이나 낮은 레버리지를 전제로 설계돼, 보상 스케일이 비교적 안정적이며 위험 관리 기법이 단순히 포트폴리오 제약 정도에 머문다. 그러나 5배 이상의 레버리지는 작은 가격 변동에도 손익이 급격히 확대돼, TD 오차가 폭발적으로 커지고 학습이 발산할 위험이 있다. FineFT는 이를 해결하기 위해 앙상블 TD 오차 기반 선택적 업데이트라는 메커니즘을 도입한다. 구체적으로, 여러 Q‑학습기 각각의 TD 오차를 계산하고, 오차가 낮은 학습기만을 업데이트 대상으로 삼음으로써 노이즈가 큰 샘플을 배제하고 학습 안정성을 확보한다. 이는 기존의 경험 재플레이(Experience Replay)나 가중 평균 앙상블과는 달리, 학습기 간의 역할을 동적으로 재분배하는 ‘전문화(specialization)’ 효과를 만든다.
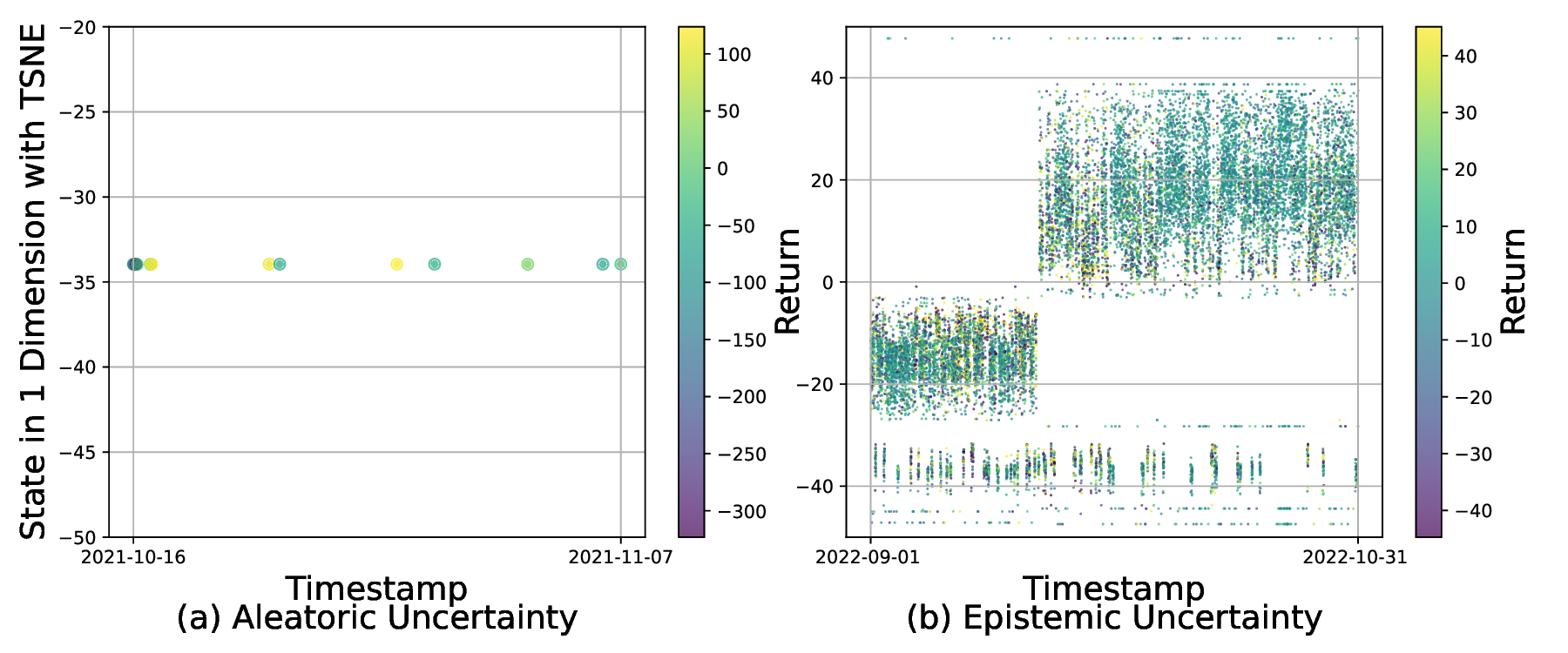
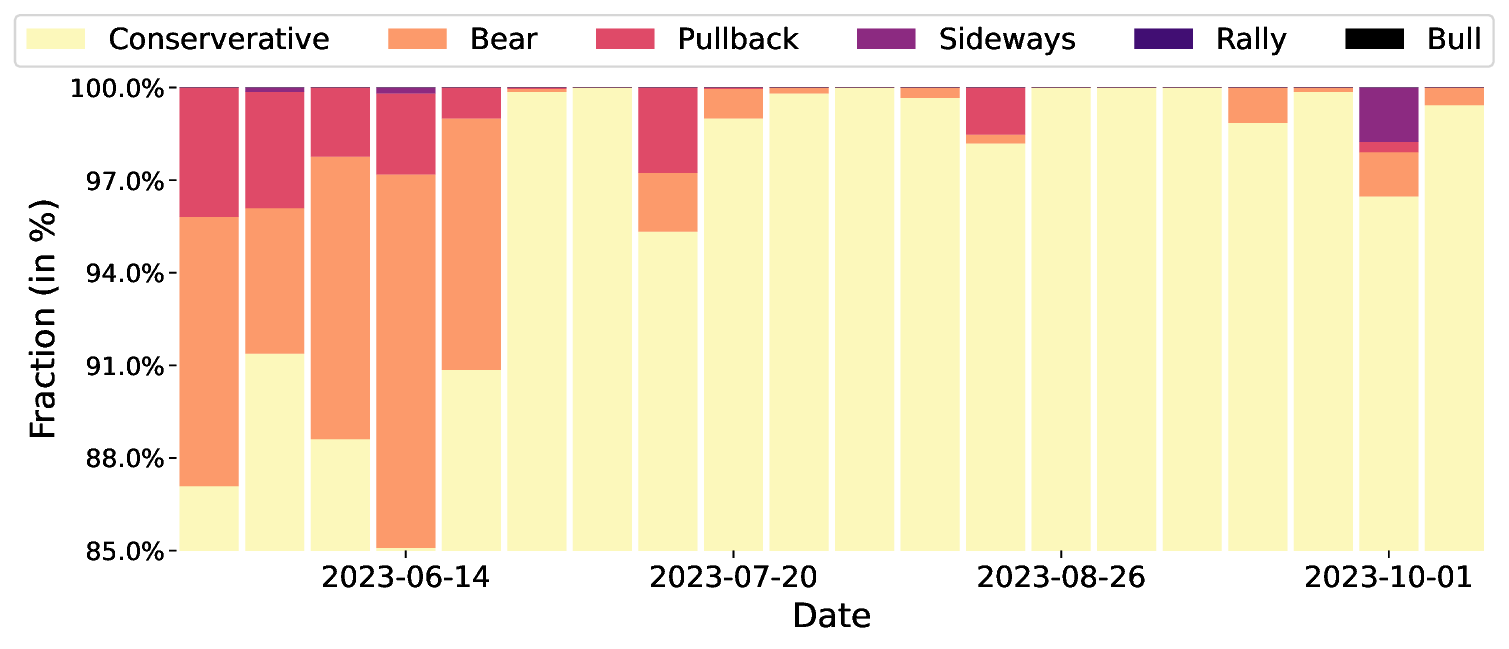
두 번째 단계에서는 역량 경계 탐지를 위해 VAE를 활용한다. 시장을 여러 동역학(예: 상승·하락·횡보, 변동성 급증 등)으로 구분하고, 각 동역학에 대해 수익성이 높은 Q‑학습기만을 남긴 뒤, 해당 동역학의 시장 상태를 VAE에 학습시킨다. VAE는 고차원 시장 피처를 저차원 잠재공간에 압축하면서 재구성 오류(reconstruction error)를 통해 입력이 학습된 분포와 얼마나 벗어났는지를 측정한다. 따라서 새로운 시장 상황이 기존 동역학과 크게 다를 경우 재구성 오류가 크게 증가하고, 이는 “역량 초과” 상황을 감지하는 신호가 된다. 이 설계는 블랙스완 이벤트와 같이 훈련 데이터에 포함되지 않은 급격한 변동에 대해 사전에 위험을 회피하도록 만든다.
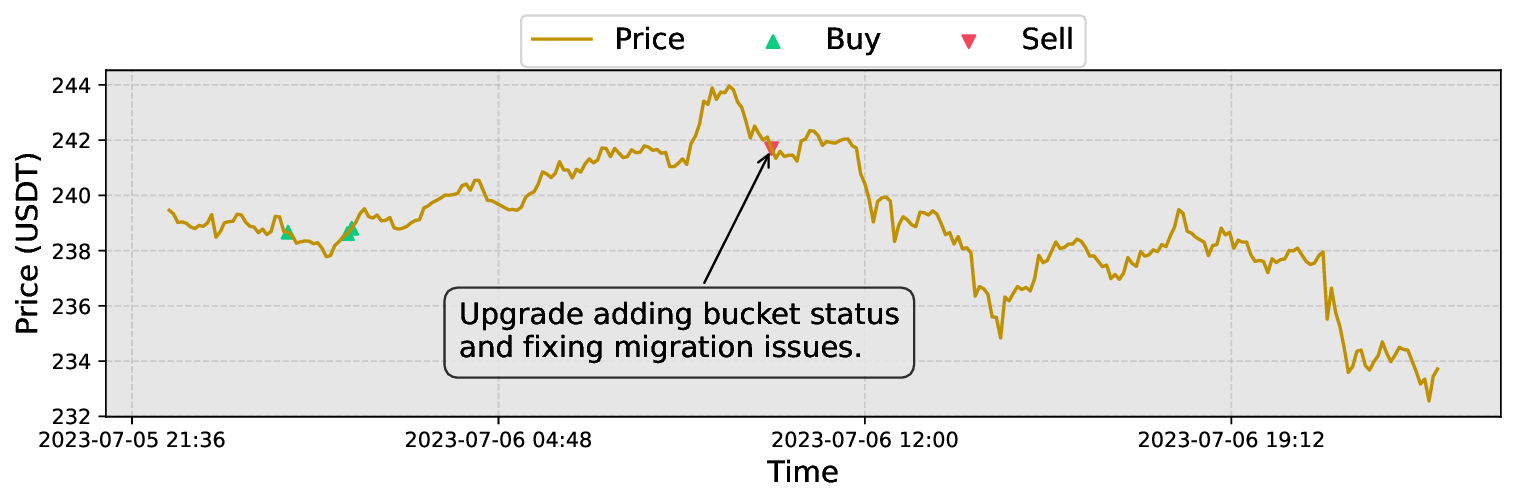
세 번째 단계에서는 동적 정책 전환을 수행한다. VAE의 재구성 오류가 사전에 정의된 임계값 이하이면 필터링된 앙상블 중 가장 높은 Q‑값을 가진 학습기를 선택하고, 오류가 임계값을 초과하면 보수적인 정책(예: 포지션 축소·현금 보유)으로 전환한다. 이렇게 하면 위험이 급증하는 순간 자동으로 손실을 제한하면서도, 정상적인 시장에서는 앙상블의 수익성을 최대한 활용한다.
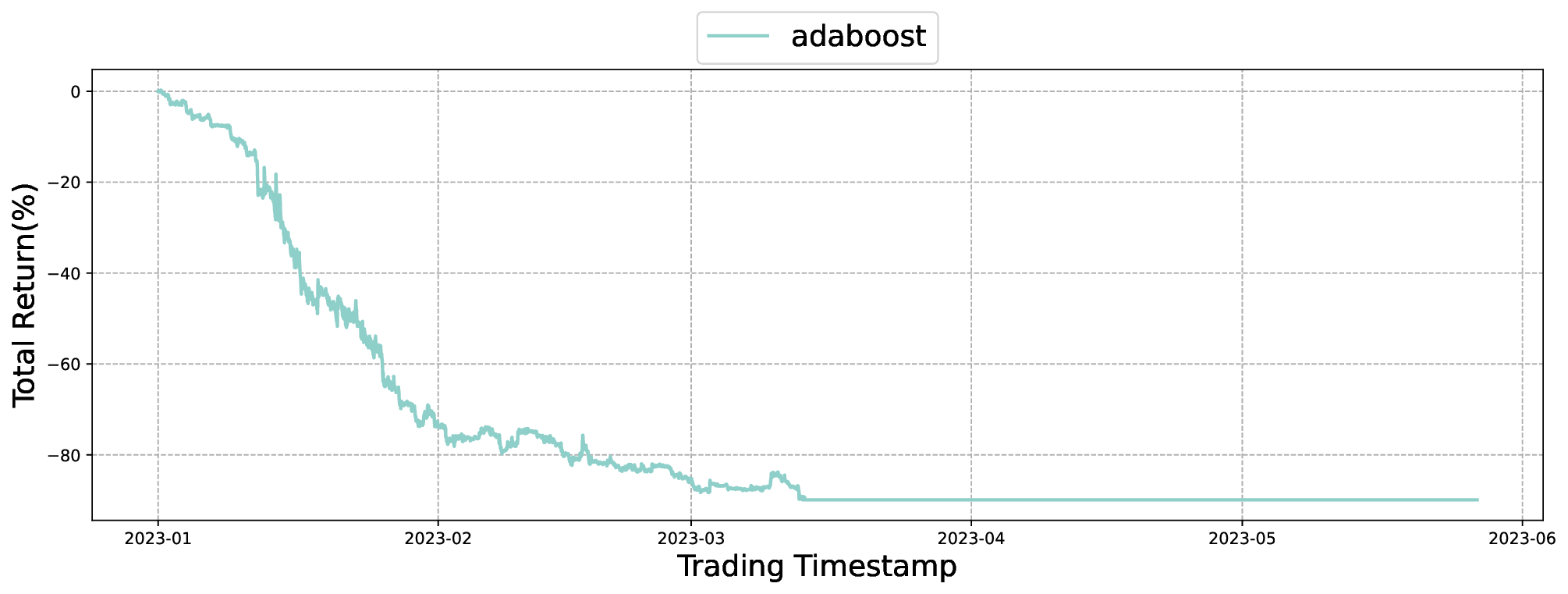
실험 설계도 주목할 만하다. 저자들은 5배 레버리지를 적용한 고주파 암호화폐 선물 데이터를 사용해 12개의 최신 베이스라인(DDPG, SAC, PPO, Ensemble DQN 등)과 6가지 금융 지표(Sharpe Ratio, Sortino Ratio, Max Drawdown, Calmar Ratio, Profit Factor, Annualized Return)를 비교했다. 결과는 FineFT가 위험 지표(특히 Max Drawdown)에서 40 % 이상 개선하면서도 수익성 지표에서는 최고 수준을 기록했다는 점에서, 위험 관리와 수익성 사이의 트레이드오프를 효과적으로 해결했음을 보여준다. 또한, 각 학습기가 특정 시장 동역학에 특화되는 현상을 시각화한 결과는 앙상블이 단순히 평균을 내는 것이 아니라 전문가 집합(expert ensemble) 으로 작동한다는 가설을 실증한다.
하지만 몇 가지 한계도 존재한다. 첫째, VAE 기반 역량 경계 탐지는 재구성 오류 임계값 설정에 민감하며, 임계값을 잘못 잡을 경우 과도한 보수 정책 전환으로 수익을 놓칠 위험이 있다. 둘째, 실험은 주로 비트코인·이더리움 등 주요 암호화폐 선물에 국한돼 있어, 낮은 유동성 알트코인이나 전통적인 금·원 선물 등 다른 시장에 대한 일반화 가능성은 검증되지 않았다. 셋째, 앙상블 Q‑학습기의 수와 구조(예: 네트워크 깊이, 탐험 전략)가 성능에 미치는 영향을 상세히 분석하지 않아, 실제 운영 환경에서의 계산 비용과 지연(latency) 문제가 충분히 논의되지 않았다. 향후 연구에서는 VAE 대신 변분 베이지안 방법이나 정상성 검정 기반의 역량 경계 모델을 도입하고, 다양한 레버리지 비율·시장 종류에 대한 확장 실험을 수행함으로써 실용성을 높일 수 있을 것이다.
**
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리