AGRO SQL 에이전트 기반 그룹 상대 최적화와 고충실도 데이터 합성
📝 원문 정보
- Title: AGRO-SQL: Agentic Group-Relative Optimization with High-Fidelity Data Synthesis
- ArXiv ID: 2512.23366
- 발행일: 2025-12-29
- 저자: Cehua Yang, Dongyu Xiao, Junming Lin, Yuyang Song, Hanxu Yan, Shawn Guo, Wei Zhang, Jian Yang, Mingjie Tang, Bryan Dai
📝 초록 (Abstract)
텍스트‑투‑SQL 시스템은 고품질 학습 데이터 부족과 복잡한 상황에서 모델의 추론 능력 제한으로 발전이 저해되고 있다. 본 논문에서는 데이터 중심과 모델 중심을 동시에 강화하는 이중 중심 프레임워크를 제안한다. 데이터 측면에서는 실행 검증을 통해 정답률과 의미‑논리 정합성을 보장하는 반복적 데이터 팩토리를 구축하여 강화학습(RL) 준비 데이터를 고충실도로 생성한다. 모델 측면에서는 다양성 인식 콜드 스타트 단계로 견고한 초기 정책을 만든 뒤, 그룹 상대 정책 최적화(GRPO)를 적용해 환경 피드백을 통해 에이전트의 추론 능력을 정교화한다. BIRD와 Spider 벤치마크에서 단일 모델 기준 최첨단 성능을 달성함을 실험적으로 입증한다.💡 논문 핵심 해설 (Deep Analysis)
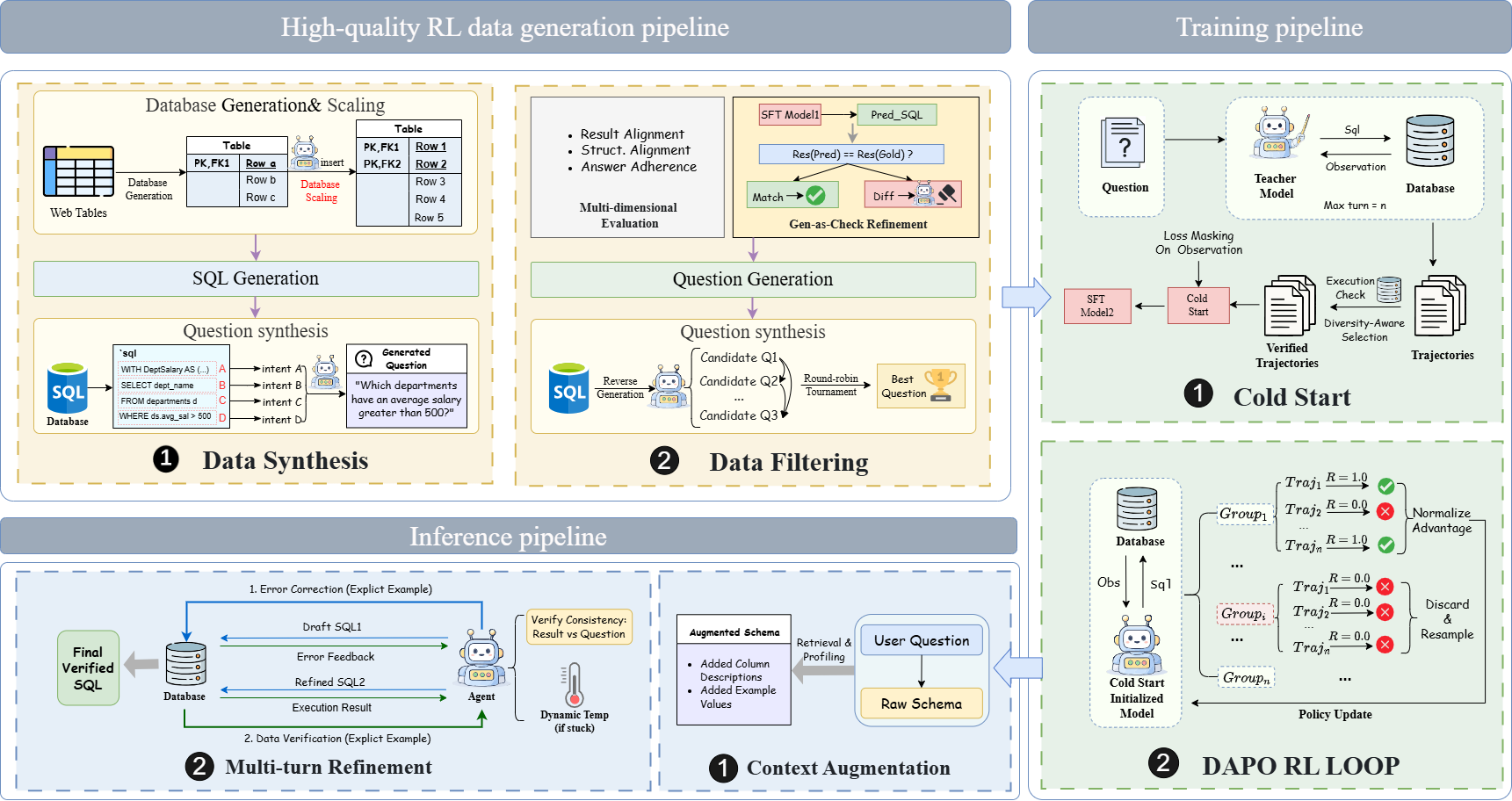
두 번째 병목은 모델의 추론·강화학습 능력이다. 기존 강화학습 기반 Text‑to‑SQL 접근법은 초기 정책이 편향돼 탐색 효율이 낮고, 보상 신호가 희소해 학습이 정체되는 문제가 있다(Shao et al., 2024). 이를 해결하기 위해 저자들은 “다양성 인식 콜드 스타트(Diversity‑Aware Cold Start)”를 제안한다. 이 단계에서는 여러 서로 다른 정책(에이전트)들을 동시에 초기화하고, 각 정책이 서로 다른 질의 유형·스키마 구조를 탐색하도록 유도한다. 이렇게 하면 초기 탐색 공간이 넓어져 보상 신호를 더 풍부하게 수집할 수 있다. 이어지는 “그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO)”는 개별 에이전트의 정책을 동일 그룹 내 다른 에이전트와 비교해 상대적인 성과를 기반으로 업데이트한다. 즉, 절대적인 보상값이 아니라 “내 그룹 내 상대적 순위”를 활용해 정책을 조정함으로써, 과도한 탐색과 과소 탐색 사이의 균형을 자동으로 맞춘다. 이는 정책 간 협업·경쟁 메커니즘을 도입한 점에서 기존 PPO, A2C 등 전통적 RL 알고리즘과 차별화된다.
실험 결과는 BIRD와 Spider 두 주요 벤치마크에서 단일 모델 기준 최고 성능을 기록했다는 점에서 설득력을 얻는다. 특히, 복합 질의·다중 테이블 조인 상황에서 기존 최첨단 모델 대비 2~3%p의 정확도 향상을 보인 것은 데이터 팩토리와 GRPO가 실제 추론 능력 향상에 기여했음을 시사한다. 그러나 논문에서는 “단일 모델”에 한정된 비교만 제시하고, 앙상블이나 라지 모델(Large Language Model)과의 비교는 부족하다. 또한, 데이터 팩토리 구축에 필요한 컴퓨팅 비용과 시간, 그리고 GRPO의 하이퍼파라미터(그룹 크기, 상대 보상 스케일 등)에 대한 민감도 분석이 부실하게 다뤄졌다. 이러한 요소들은 실제 산업 현장에 도입할 때 장벽이 될 수 있다.
향후 연구 방향으로는(1) 다양한 스키마·도메인에 대한 일반화 능력을 검증하기 위한 교차‑도메인 실험, (2) 데이터 팩토리와 GRPO를 LLM 기반 코덱스(예: GPT‑4o, Claude)와 결합해 프롬프트‑레벨 강화학습을 시도, (3) 비용‑효율성을 높이기 위한 메타‑학습 기반 정책 초기화 기법 개발이 제시될 수 있다. 전반적으로 본 논문은 데이터 품질과 정책 최적화라는 두 축을 동시에 강화함으로써 Text‑to‑SQL 연구에 새로운 패러다임을 제시했으며, 향후 실용적인 시스템 구축에 중요한 토대를 제공한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리