이 논문에서는 다중 에이전트 강화 학습(MARL)에서 상이성을 활용하는 방법을 제안하고, 이를 실용적으로 적용하기 위한 알고리즘을 개발한다. 제안된 HetDPS(Heterogeneity-based Dynamic Parameter Sharing) 알고리는 에이전트 간의 상이성을 정량화하여 파라미터 공유 방식을 동적으로 조정하며, 이를 통해 더 나은 해석 가능성과 적응력을 제공한다.
💡 논문 해설
본 논문에서는 MARL에서 상이성(heterogeneity)에 대한 체계적인 분석을 수행하고, 이를 활용하기 위한 방법론을 개발한다. 특히, 제안된 HetDPS 알고리즘은 에이전트 간의 다양한 상이성을 정량화하여 동적으로 파라미터 공유 방식을 조정함으로써, 기존 방법에 비해 더 나은 해석 가능성과 적응력을 제공한다. 여기서 상이성은 관찰 상이성, 반응 전이 상이성, 효과 전이 상이성, 목표 상이성, 그리고 정책 상이성으로 구분된다.
📄 논문 발췌 (ArXiv Source)
# 상이성을 활용한 MARL
방법
패러다임
적응성
상이성 활용에 대한 관계
NPS
공유 없음
없음
없음
FPS
전체 공유
없음
없음
FPS+id
전체 공유
없음
없음
Kaleidoscope
부분 공유
있음
상이성 활용 없음, 정책의 상이성을 편향으로 증가시킴
SePS
그룹 공유
없음
목표 상이성과 반응 전이 상이성을 암묵적으로 활용함
AdaPS
그룹 공유
있음
목표 상이성과 반응 전이 상이성을 암묵적으로 활용함
MADPS
그룹 공유
있음
정책 상이성만 명시적으로 활용함
HetDPS(우리의)
그룹 공유
있음
상이성을 명시적으로 활용하여 상이한 거리를 활용함
style="width:85.0%" />
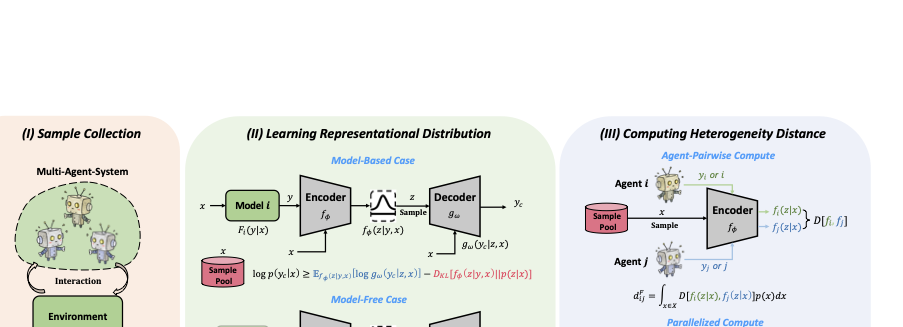
상이성 정량화를 기반으로 하는 다중 에이전트 동적 파라미터 공유 알고리즘의 방법.
제안된 방법은 다양한 유형의 상이성을 정확하게 정량화할 뿐만 아니라 에이전트 간의 “종합적인 상이성”도 측정할 수 있다. 또한, 이 방법은 MARL에서 사용되는 파라미터 공유 유형에 독립적이므로 온라인으로 배포될 수 있으며 이를 통해 실용성을 더욱 강화한다. 본 절에서는 우리의 방법론을 실제 적용하여 그 잠재력을 보여주기 위한 사례 연구를 제공한다.
본 논문은 MARL에서 파라미터 공유를 응용 상황으로 선택하였다. 파라미터 공유는 MARL에서 흔히 사용되는 기법으로 샘플 활용 효율성을 높일 수 있지만, 과도한 사용은 에이전트의 정책 상이성 표현을 억제할 수 있다. 많은 연구들은 파라미터 공유와 정책 상이성 사이의 균형점을 찾기 위해 노력해왔지만, 기존 접근법에는 해석력 부족과 적응력 부족이라는 두 가지 주요 문제가 있다.
이러한 문제를 해결하기 위해, 우리는 Heterogeneity-based 다중 에이전트 Dynamic Parameter Sharing 알고리즘(HetDPS)을 제안한다. HetDPS는 다음과 같은 두 가지 핵심 아이디어를 갖추고 있다(자세한 내용은 부록 J 참조):
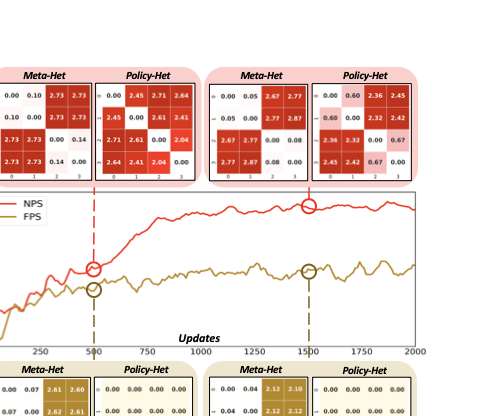
상이성 거리를 통해 에이전트 그룹화하기: 우리는 거리 기반 클러스터링 방법을 사용하여 에이전트를 그룹화함으로써, 그룹 수나 융합 임계값과 같은 작업 특수한 하이퍼파라미터의 도입을 피한다. 상이성 거리 행렬은 알고리즘의 해석력을 강화한다.
정기적으로 상이성을 정량화하고 에이전트의 파라미터 공유 패러다임을 수정하기: 이러한 접근 방식은 정책들이 국소 최적점을 벗어날 수 있게 도와주며, 이 메커니즘의 효과는 MARL 영역뿐만 아니라 대형 모델 조정과 같은 더 넓은 RL 영역에서도 검증되었다.
위 아이디어를 결합하여 HetDPS 방법을 Figure 1에서 설명한 것처럼 제시한다. 이 접근 방식은 일반적인 MARL 알고리즘과 결합할 수 있으며 다양한 파라미터 공유 초기화를 지원(e.g., FPS와 NPS). $T$ 업데이트마다, 알고리즘은 에이전트의 거리 행렬을 계산하고 거리 기반 클러스터링을 통해 그룹화한다. 이전 주기에 클러스터링 결과가 존재하는 경우 두 클러스터링 결과 간에 이분 그래프 매칭을 수행하여 정책 상속 관계를 도와준다. 이러한 이중 클러스터링 메커니즘은 알고리즘의 적응력을 효과적으로 향상시킨다.
우리는 MARL에서 상이성 활용이 이 범위를 넘어서 가능하다는 점을 강조한다. 우리의 방법을 통해 연구자들은 특정 유형의 상이성 또는 종합적인 상이성을 정량화할 수 있으며, 이를 최신의 MARL 연구 방향과 통합할 수 있다(부록 C 참조).
전제 조건
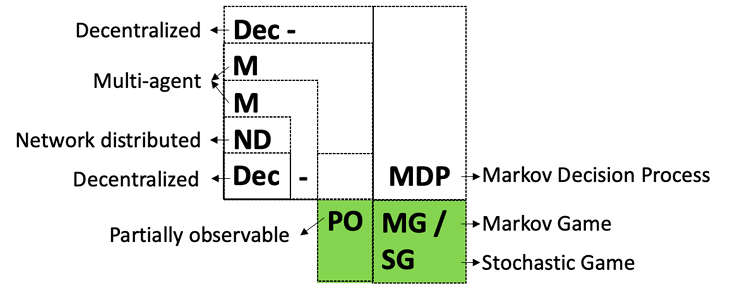
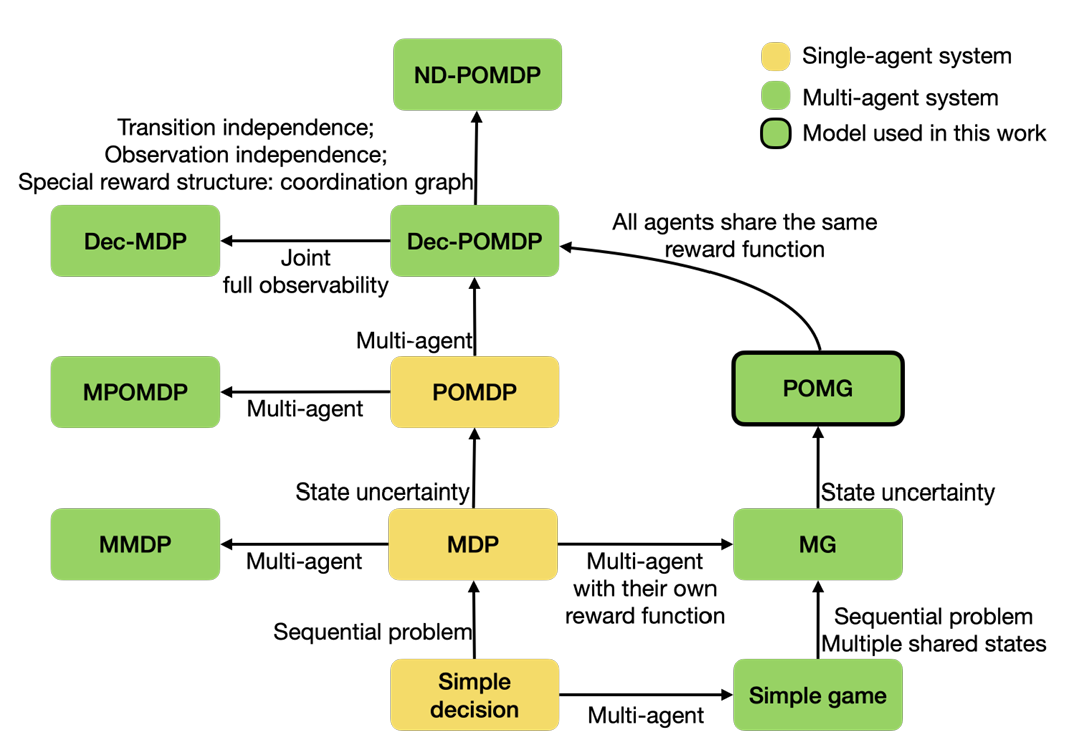
MARL의 기본 문제: 본 논문에서는 부분적으로 관찰 가능한 마르코프 게임(POMG)을 MARL의 기본 문제에 대한 일반적인 모델로 사용한다. 에이전트 상이성 연구를 더 잘 수행하기 위해, 우리는 [IMG_PROTECT_N]에서와 같은 에이전트 수준의 모델링 접근법을 채택한다. POMG는 8튜플로 정의되며 다음과 같이 표현된다:
이 표현에서 $N$은 모든 에이전트의 집합이고, $\{S^i\}_{i\in N}$는 전역 상태 공간을 나타내며 이를 $`\{S^i\}_{i\in N} =\times_{i\in N} S^{i} \times S^{E}`$로 인수분해할 수 있다. 여기서 $`S^{i}`$는 에이전트 $i$의 상태 공간이고, $`S^{E}`$는 환경 상태 공간을 나타내며 모든 비에이전트 구성 요소를 대응한다. $\{O^i\}_{i\in N}=\times_{i\in N} O^{i}$은 공동 관찰 공간이고, $\{A^i\}_{i\in N}=\times_{i\in N} A^{i}`$는 모든 에이전트의 공동 행동 공간이다. $\{\Omega^i\}_{i\in N}`$은 관찰 함수 집합을 나타내며,
$\{\mathcal{T}^i\}_{i\in N}=(\mathcal{T}^1, \cdots, \mathcal{T}^{|N|},\mathcal{T}^E)`$는 모든 에이전트의 전이와 환경 전이를 수집한다. 마지막으로, $\{r_i\}_{i\in N}`$은 모든 에이전트의 보상 함수 집합이고, $`\gamma`$는 할인 요소이다.
각 시간 단계 $t`에서, 에이전트 $i$는 관찰 $o^i_t \sim \Omega^{i}(\cdot|\hat{s}_t)$를 받으며, 여기서 $\hat{s}t \in {S^i}{i\in N}$은 시간 $t$의 전역 상태이다. 그런 다음 에이전트 $i$는 관찰에 기반하여 행동을 결정하고 그 결과로 행동 $a^i_t \sim \pi_i(\cdot|o^i_t)$를 수행한다. 환경은 모든 에이전트로부터 행동을 수집하여 전역 행동 $\hat{a}_t = (a^1_t, \dots, a^{|N|}t)$을 형성한다. 우리는 에이전트 $i$의 로컬 상태 전환이 전체 상태와 전체 행동에 의해 영향을 받는다고 가정하므로, 그의 로컬 상태는 새로운 상태로 전환된다: $s^i{t+1} \sim \mathcal{T}^i(\cdot|\hat{s}_t, \hat{a}_t)$. 마찬가지로 다른 에이전트와 환경도 전환하여 다음 전역 상태 $\hat{s}_{t+1} = (s^1_{t+1}, \dots, s^{|N|}_{t+1}, s^E_{t+1}) \sim (\mathcal{T}^1(\cdot|\hat{s}_t, \hat{a}_t), \dots, \mathcal{T}^{|N|}(\cdot|\hat{s}_t, \hat{a}_t), \mathcal{T}^E(\cdot|\hat{s}_t, \hat{a}_t)) = \{\mathcal{T}^i\}_{i\in N}(\cdot|\hat{s}_t, \hat{a}_t)$을 얻는다. 동시에 모든 에이전트가 보상을 받으며 특정 에이전트 $i$의 보상은 $r^i_t \sim r^{i}(\cdot|\hat{s}_t, \hat{a}_t)$로 주어진다.
MARL의 목표는 POMG를 해결하여 모든 에이전트의 누적 보상을 최대화하는 최적 공동 정책을 찾는 것이다. 우리는 에이전트 $i`$의 개인적인 최적 정책을 $\pi_i^{*}`로 표기하고, 최적 공동 정책은 $\hat{\pi}^{*}로 표기하며 이를 다음과 같이 표현한다: $\hat{\pi}^{*}=(\pi_1^{*}, \dots, \pi_{|N|}^{*})$. POMG의 최적 공동 정책은 다음 방정식을 통해 얻을 수 있다:
여기서 $\gamma`$는 할인 요소이고, 기대값은 초기 상태 $`\hat{s}_0`$에서 시작하는 공동 정책 $`\hat{\pi}`$를 통해 트래JECTORY를 취한다.
소개
다중 에이전트 강화 학습(MARL)은 군집 로봇 제어, 자율주행 차량, 대형 언어 모델 조정 등 다양한 실제 응용 분야에서 성공을 거두고 있다. 그러나 대부분의 MARL 연구는 동질 다중 에이전트 시스템에 대한 정책 학습에 초점을 맞추며, 상이한 다중 에이전트 시나리오에 대한 심층적 논의를 간과해왔다. 상이성은 다중 에이전트 시스템에서 일반적인 현상이다. 예를 들어 자연에서는 다양한 종류의 물고기가 먹이를 찾아 협력하고[IMG_PROTECT_N], 인간 사회에서는 다양성이 높은 팀들이 더 높은 지능과 탄력을 보여주며, 인공 시스템에서는 공중 드론과 지상 차량이 삼림 화재 감시를 위해 협력한다[IMG_PROTECT_N]. 상이성은 시스템 기능을 향상시키고 비용을 절감하며 견고성을 높이는 데 도움이 되지만, 효과적으로 상이성을 활용하는 것은 여전히 다중 에이전트 시스템의 핵심 과제이다. 환경과 상호 작용을 통해 학습하는 방법으로서 MARL은 다중 에이전트 시스템이 협력 정책을 학습할 수 있게 효과적으로 만드는 역할을 한다. 따라서 강화 학습 관점에서 상이성을 탐구하면 MARL의 적용 범위를 크게 확장시킬 수 있다.
현재 MARL 분야에서는 일부 연구가 명시적 또는 암묵적으로 에이전트 상이성에 대해 언급하지만, 그 정의와 식별에 초점을 맞춘 것은 거의 없다. 명시적인 상이성 논의를 보면, 여러 연구들은 상이한 MARL에서 의사소통 문제[IMG_PROTECT_N], 신용 할당[IMG_PROTECT_N], 제로샷 일반화[IMG_PROTECT_N] 등을 탐구해왔다. 그러나 이러한 작업들은 기능적으로 명확히 다른 에이전트에만 초점을 맞추고 있으며, 상이성의 정의가 부족하다. 반면 많은 연구는 MARL에서 정책 다양성을 탐구한다. 일부 연구에서는 특정 항목을 사용하여 에이전트를 그룹화하거나[IMG_PROTECT_N], 정책 차이를 측정하고 이를 제어하기 위한 알고리즘을 설계하는 등 다양한 접근 방식을 취한다.
style="width:75.0%" />
우리의 철학. 우리는 MARL에서 상이성을 체계적으로 논의하고, 상이성 정의, 측정 및 활용 방법론을 구축하는 것을 목표로 한다.
그러나 이러한 연구들은 정책 다양성이 어디서 비롯되는지 또는 그것이 근본적으로 에이전트 차이와 어떻게 관련되어 있는지를 충분히 다루지 못한다. MARL에서 상이성의 정의 및 분류에 관해 이야기하자면, [IMG_PROTECT_N]은 물리적이고 행동적인 유형으로 상이성을 나누지만 수학적 정의가 부족하다. [IMG_PROTECT_N]은 다중 에이전트 상이성 환경을 위한 확장 POMDP를 제공하지만, 상이성 분류 및 정의는 포함되지 않는다. 다른 연구에서는 로컬 전환 상이성을 도입하나 MARL의 모든 요소를 포괄하지 못한다[IMG_PROTECT_N]. 현재까지도 MARL 관점에서 에이전트 상이성에 대한 체계적인 분석에는 여전히 부족한 점이 있다. 이러한 간극을 메꾸기 위해, 우리는 MARL 도메인에서 상이성을 정의하고 측정하며 활용하는 일련의 연구를 수행한다(그런데 이 연구의 철학은 Figure 2에 요약되어 있다). 그리고 관련 작업의 자세한 내용은 부록 A를 참조할 수 있다. 우리의 기여는 다음과 같다:
상이성 정의: MARL의 에이전트 수준 모델을 바탕으로 관찰 상이성, 반응 전이 상이성, 효과 전이 상이성, 목표 상이성, 그리고 정책 상이성을 분류하고 각각에 대한 정의를 제공한다.
상이성 측정: 우리는 상이성 거리를 정의하고, 모델링과 모델 없는 설정 모두에 적용 가능한 표현 학습 기반 측정 방법을 제안한다. 또한 에이전트의 종합적인 상이성을 정량화하기 위한 메타 전환 상이성 개념도 제공한다.
상이성 활용: 우리는 상이성 정량화를 기반으로 하는 다중 에이전트 동적 파라미터 공유 알고리즘을 개발하여, 다른 관련 파라미터 공유 방법에 비해 더 나은 해석력과 작업 특수 하이퍼파라미터가 적음을 제공한다.
본 논문에서는 이론에서 실질적인 적용으로 그리고 일반적인 관점에서 구체적인 사례로 논의를 진행하는 접근 방식을 취한다. 전체 구조는 다음과 같이 구성된다:
Section 18은 MARL의 기본 문제에 대한 에이전트 수준 모델링을 소개하고, Section 19에서는 MARL에서 상이성의 분류와 정의를 제공하며, Section 20은 상이성을 측정하기 위한 방법론과 사례 연구를 제안한다. Section 21에서는 동적 파라미터 공유 알고리즘을 설명하고, Section 22는 관련 실험 결과를 제공하며, 마지막으로 Section 23에서 논문을 요약한다.
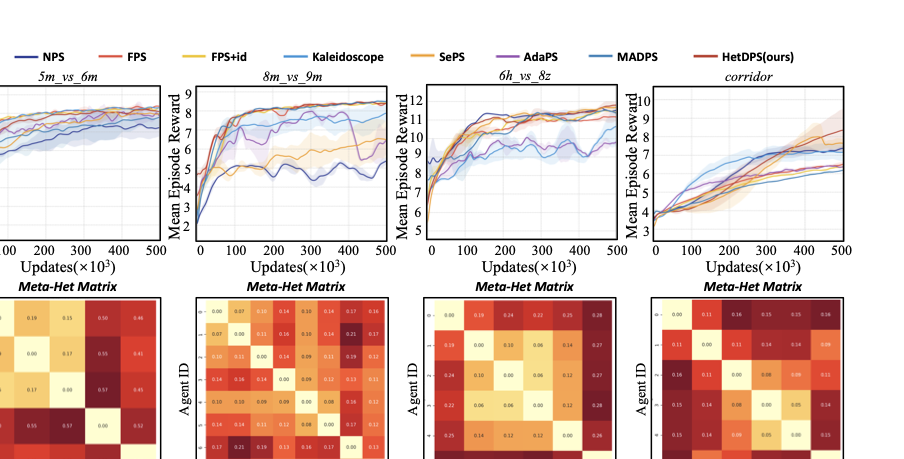
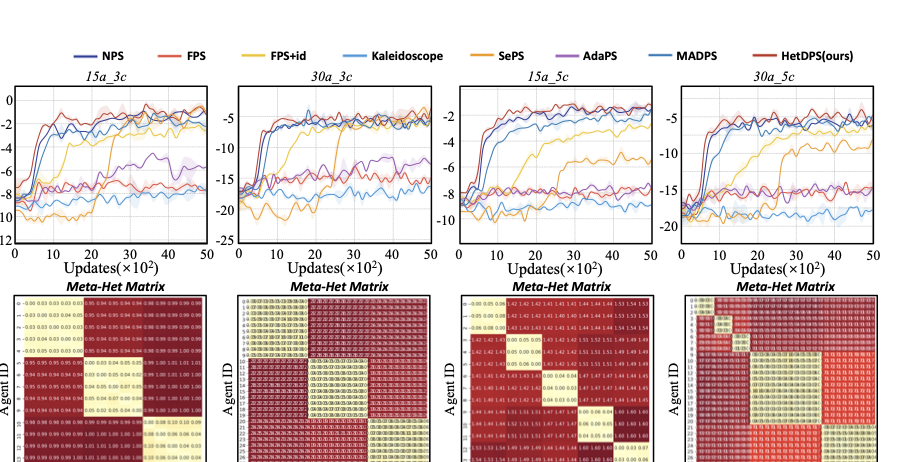
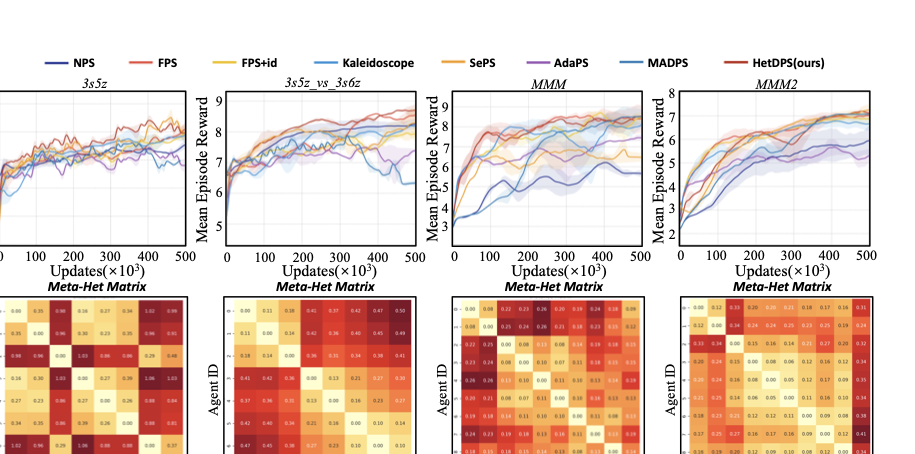
본 절에서는 HetDPS와 다른 파라미터 공유 방법 간에 포괄적인 비교를 수행한다. 성능 비교뿐만 아니라 우리의 방법론을 사용하여 각 MARL 작업의 상이성 특성을 분석하고, 알고리즘의 해석력을 보여준다. 또한 하이퍼파라미터 실험 및 효율성과 자원 소비 실험을 수행하여 HetDPS의 적응력과 실용성을 보인다.
실험 설정
style="width:80.0%" />
Partical-based Multi-agent Spreading에 대한 결과.
환경: Partical-based Multi-agent Spreading (PMS)[IMG_PROTECT_N]는 정책 다양성 도메인에서 대표적인 환경이다. 이 환경에서는 여러 에이전트가 맵의 중심부에 무작위로 생성되며, 몇몇 랜드마크가 주변 근처에 생성된다. 에이전트와 랜드마크 모두 다양한 색상을 가지며, 에이전트는 색상이 일치하는 랜드마크로 이동해야 한다. 또한 에이전트는 랜드마크 근처에 도착했을 때 밀집한 형태를 형성해야 한다. 우리는 4가지 대표적인 작업을 사용하며, 각각은 다른 숫자와 색상 분포를 갖추고 있다(자세한 내용은 Table 참조).