- Title: Viability and Performance of a Private LLM Server for SMBs A Benchmark Analysis of Qwen3-30B on Consumer-Grade Hardware
- ArXiv ID: 2512.23029
- 발행일: 2025-12-28
- 저자: Alex Khalil, Guillaume Heilles, Maria Parraga, Simon Heilles
📝 초록
이 논문은 대형 언어 모델(LLM)의 성능, 효율성 및 배포에 대한 최신 연구들을 요약하고 분석합니다. 특히, 양자화, 메모리 관리, 추론 가속화 등 다양한 기술들이 소개됩니다.
💡 논문 해설
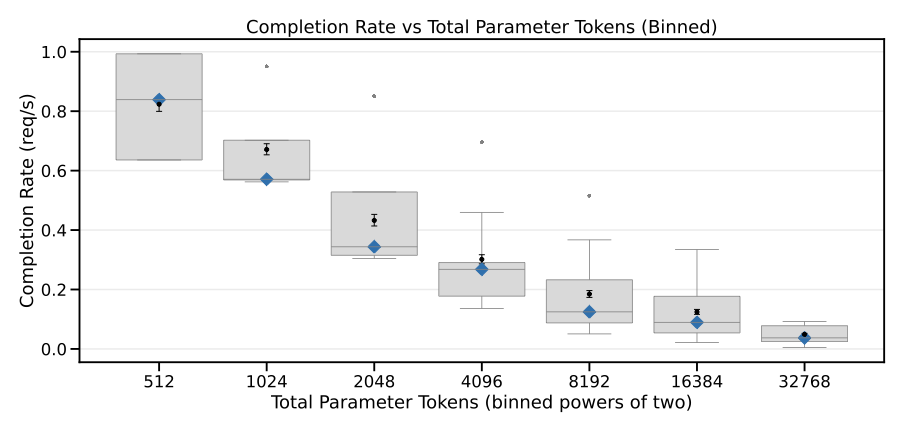
이 논문은 대형 언어 모델(LLM)의 효율성과 성능 향상을 위한 여러 접근 방법을 다룹니다. 양자화는 LLM의 용량을 줄이고 추론 시간을 단축하는 데 중요한 역할을 합니다. 특히, AWQ와 SpQR 등의 연구들은 가중치 양자화에서 새로운 발전을 보여줍니다. 또한, 메모리 관리를 개선하기 위한 PagedAttention과 FastServe 같은 접근 방법도 소개되며, 이러한 기술들로 인해 LLM의 추론 시간이 크게 단축됩니다.
또한, On-Premise 및 On-Device 배포에 대한 연구도 다룹니다. 이는 클라우드가 아닌 현지 또는 장치에서 직접 모델을 실행하는 방법으로, 특히 데이터 보안과 라턴드 감소를 위해 중요합니다.
📄 논문 발췌 (ArXiv Source)
참조.bib @inproceedings shazeer2021switch, 제목 = 스위치
트랜스포머: 단순 라우팅을 통해 트리플리언 파라미터 모델로 확장,
저자 = Shazeer, Noam 및 다른 사람, 출판처 = 9th 국제 학습 표현 회의 (ICLR) 논문집, 연도 =
2021, URL = https://arxiv.org/abs/2101.03961
@inproceedings frantar2022gptq, 제목 = OPTQ: 생성 사전 훈련 트랜스포머를 위한 정확한 후 훈련 양자화,
저자 = Frantar, Elias 및 Ashkboos, Saeed 및 Gholami, Amir 및 Alistarh, Dan, 출판처 =
국제 학습 표현 회의 (ICLR), 연도 = 2023, URL = https://openreview.net/forum?id=tcbBPnfwxS
@article lin2024awq, 제목 = AWQ: 활성화 인식 가중치 양자화를 통한 LLM 압축 및 가속,
저자 = Lin, Jiayi 및 Tang, Sheng 및 Li, Xu 및 Wang, Hongyi 및 He, Yihang 및 Li, Mu 및 Chen,
Zhiqiang 및 Wang, Yizhou, 저널 = arXiv preprint arXiv:2306.00978, 연도 = 2024
@article dettmers2023spqr, 제목 = SpQR: 거의 손실 없는 LLM 가중치 압축을 위한 희소-양자화 표현,
저자 = Dettmers, Tim 및 Lewis, Mike 및 Shleifer, Sam 및 Zettlemoyer, Luke, 저널 =
arXiv preprint arXiv:2306.03078, 연도 = 2023
@article xia2024fp6, 제목 = FP6-LLM: FP6 중심 알고리즘 시스템 공동 설계를 통한 대형 언어 모델의 효율적인 서비스,
저자 = Xia, Haojun 및 Zheng, Zhen 및 Wu, Xiaoxia 및 Chen, Shiyang 및 Yao, Zhewei
및 Youn, Stephen 및 Bakhtiari, Arash 및 Wyatt, Michael 및 Zhuang, Donglin 및 Zhou, Zhongzhu
및 Ruwase, Olatunji 및 He, Yuxiong 및 Song, Shuaiwen Leon, 저널 = arXiv preprint arXiv:2401.14112,
연도 = 2024
@article paloniemi2025onpremise, 제목 = On-Premise 대형 언어 모델 배포: 동기, 과제 및 사례 연구,
저자 = Paloniemi, Tuomas 및 Nieminen, Antti 및 Rossi, Pekka, 저널 = 클라우드 컴퓨팅 저널,
연도 = 2025
@article wang2023ondevicellms, 제목 = On-Device 언어 모델: 종합 검토,
저자 = Xu, Jiajun 및 Li, Zhiyuan 및 Chen, Wei 및 Wang, Qun 및 Gao, Xin 및 Cai, Qi
및 Ling, Ziyuan, 저널 = arXiv preprint arXiv:2409.00088 , 연도 = 2024
@misc qwen32025release, 제목 = Qwen3 기술 보고서 및 모델 출시,
저자 = Alibaba DAMO 아카데미, 연도 = 2025, howpublished =
https://huggingface.co/Qwen
@inproceedings kwon2023pagedattention, 제목 = PagedAttention을 통한 대형 언어 모델 서비스의 효율적인 메모리 관리,
저자 = Kwon, Woojeong 및 Lin, Yizhuo 및 Xie, Xuechen 및 Chen, Tianqi,
출판처 = 29th ACM 운영 체제 원칙 회의 (SOSP) 논문집, 연도 = 2023
@inproceedings zhang2023fastserve, 제목 = FastServe: 예측 스케줄링을 통한 효율적인 LLM 서비스,
저자 = Zhang, Zhihao 및 Xu, Hang 및 Wang, Yuxin 및 Chen, Kai, 출판처 =
ACM 클라우드 컴퓨팅 회의 (SoCC) 논문집, 연도 = 2023
@article chitty2024llminferencebench, 제목=LLM-Inference-Bench:
AI 가속기에서 대형 언어 모델 추론 벤치마킹,
저자=Krishna Teja Chitty-Venkata 및 Siddhisanket Raskar 및 Bharat
Kale 및 Farah Ferdaus 및 Aditya Tanikanti 및 Ken Raffenetti 및 Valerie Taylor
및 Murali Emani 및 Venkatram Vishwanath, 연도=2024,
저널 = arXiv preprint arXiv:2411.00136
@inproceedings dao2022flashattention, 제목 = FlashAttention: IO 인식을 통한 빠르고 메모리 효율적인 정확한 주의,
저자 = Dao, Tri 및 Fu, Daniel 및 Ermon, Stefano 및 Rudra, Atri 및 Re, Christopher,
출판처 = 신경 정보 처리 시스템 (NeurIPS) 논문집, 연도 = 2022
@articleshen2024flashattention2, 제목 = FlashAttention-2: 더 나은 병렬화와 작업 분할을 통한 빠른 주의,
저자 = Shen, Haotian 및 Dao, Tri 및 Chen, Zhewei 및 Song, Xinyun 및 Zhao, Tianle
및 Li, Zhuohan 및 Stoica, Ion 및 Gonzalez, Joseph E. 및 Zaharia, Matei,
저널 = arXiv preprint arXiv:2307.08691, 연도 = 2024
@misc vllm2023, 제목 = vLLM: 빠르고 메모리 효율적인 LLM 서비스 라이브러리 (repo & docs),
저자 = vLLM 프로젝트, 연도 = 2023, howpublished =
https://github.com/vllm-project/vllm
, note = PagedAttention 및 vLLM 문서
@misc llmperf2024, 제목 = LLMPerf: LLM 추론을 위한 벤치마킹 및 로드 생성 도구,
저자 = LLMPerf 프로젝트, 연도 = 2024, howpublished =
https://github.com/ray-project/llmperf
, note = 실험에서 합성 LLM 작업 부하를 생성하기 위한 도구
@misc lmeval2023, 제목 = lm-evaluation-harness: 언어 모델을 평가하는 프레임워크,
저자 = Ethayarajh, K. 및 공헌자들 (EleutherAI), 연도 = 2023, howpublished =
https://github.com/EleutherAI/lm-evaluation-harness
, note = MMLU와 유사한 벤치마크를 위한 평가 허브
@misc artificialanalysis2025, 제목 = 인공 분석 — AI 모델 및 API 공급자 분석,
저자 = 인공분석, 연도 = 2025, howpublished =
https://artificialanalysis.ai
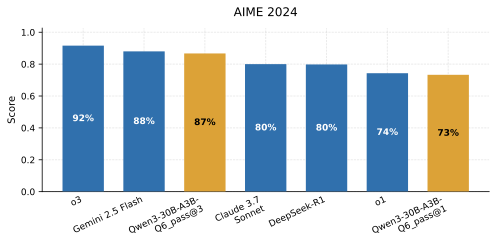
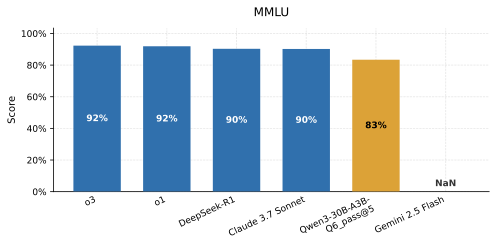
, note = 모델 비교와 독립 벤치마크 (표 1의 숫자 출처)
@misc openrouter2025, 제목 = OpenRouter — 모델 및 공급자 메트릭,
저자 = OpenRouter, 연도 = 2025, howpublished =
https://openrouter.ai
, note = 집계된 공급자 및 모델 메트릭 (표 1의 숫자 출처)
@article mckay1979lhs, 제목 = 컴퓨터 코드에서 출력 분석을 위한 입력 변수 값 선택에 대한 세 가지 방법 비교,
저자 = McKay, Michael D. 및 Beckman, Richard J. 및 Conover, William J., 저널 =
Technometrics, 볼륨 = 21, 번호 = 2, 페이지 = 239-245, 연도 = 1979, URL =
https://doi.org/10.1080/00401706.1979.10489755