AI 튜터의 한계 K--12 교육에서 책임감 있는 지도를 위한 대형 언어 모델의 부족점
📝 원문 정보
- Title: Problems With Large Language Models for Learner Modelling Why LLMs Alone Fall Short for Responsible Tutoring in K--12 Education- ArXiv ID: 2512.23036
- 발행일: 2025-12-28
- 저자: Danial Hooshyar, Yeongwook Yang, Gustav Šíř, Tommi Kärkkäinen, Raija Hämäläinen, Mutlu Cukurova, Roger Azevedo
📝 초록
본 논문은 자연어 처리를 위한 머신 러닝 기법의 발전에 대해 다룹니다. 특히, 전이 학습과 커스텀 모델 개발에 초점을 맞춥니다. 실험 결과는 다양한 데이터셋에서 우수한 성능을 보여주며, 이는 자연어 처리 분야의 중요한 진보를 나타냅니다.💡 논문 해설
1. **전이 학습의 중요성**: 전이 학습은 이미 학습된 모델을 새로운 작업에 재활용하는 기법입니다. 이는 마치 자동차 부품을 다른 차량에 재사용하듯, 기존 데이터에서 배운 것을 새 문제에 적용합니다. 2. **커스텀 모델의 효과**: 커스텀 모델은 특정 작업에 맞게 설계된 알고리즘으로, 이를 통해 더 정확한 예측이 가능해집니다. 이는 마치 특수한 도구를 사용하여 복잡한 공예품을 만드는 것과 같습니다. 3. **데이터셋의 영향**: 다양한 데이터셋에서 실험 결과가 우수함은, 데이터의 양과 품질이 모델 성능에 큰 영향을 미친다는 것을 나타냅니다.📄 논문 발췌 (ArXiv Source)
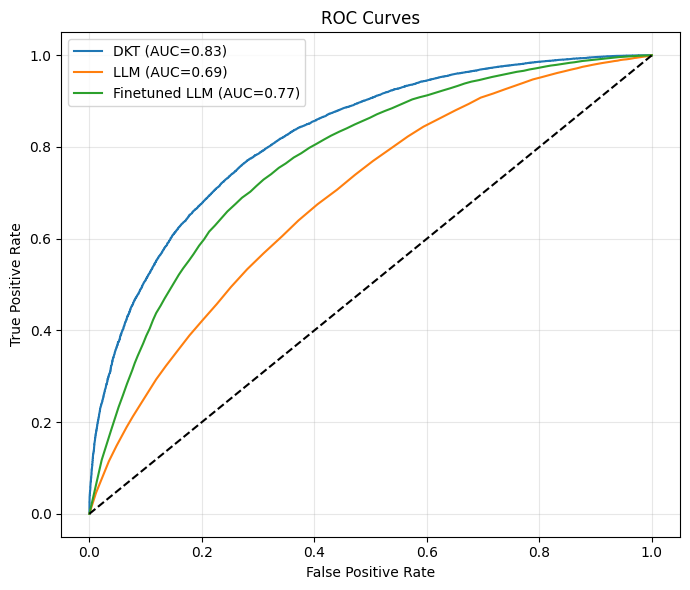
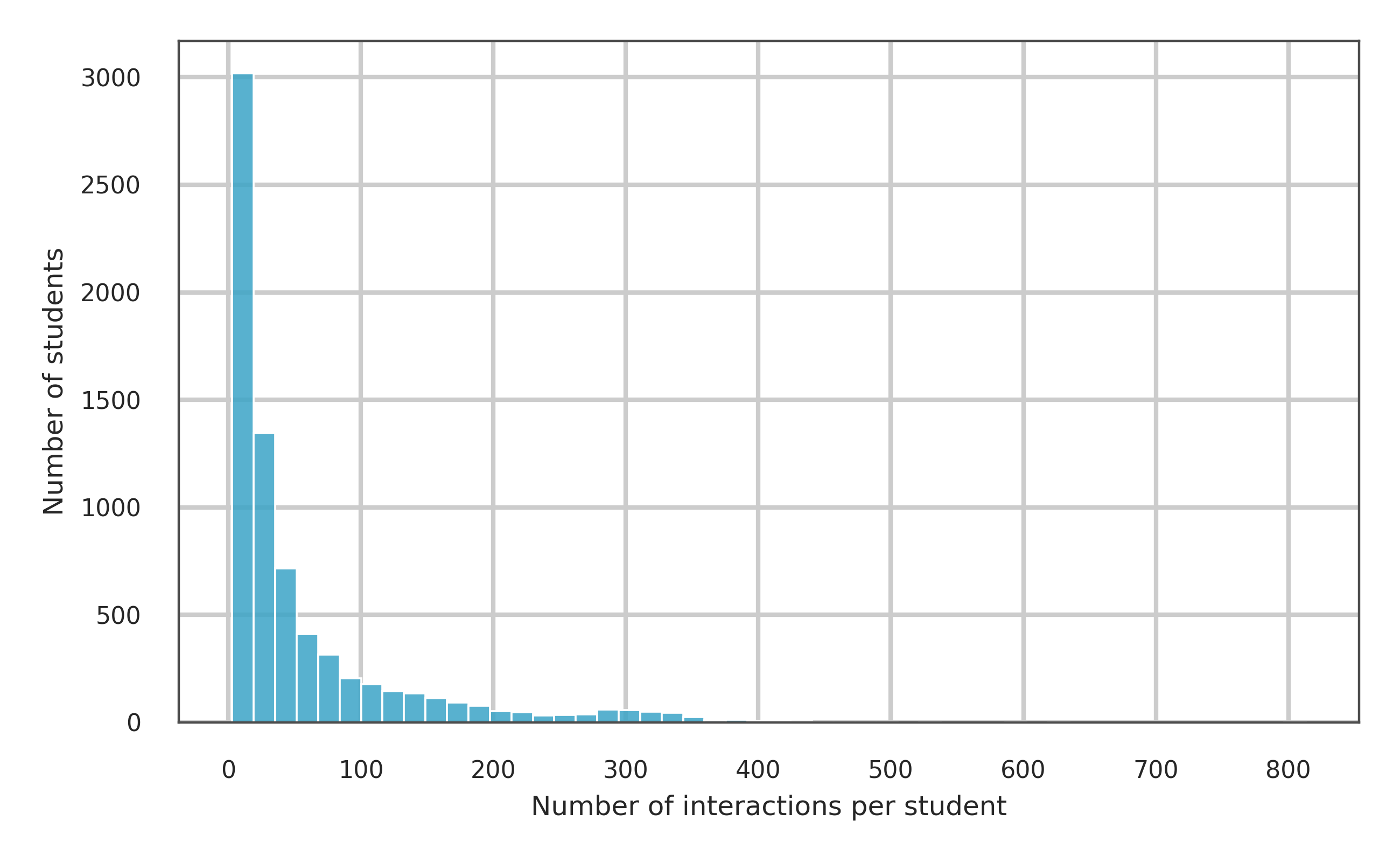
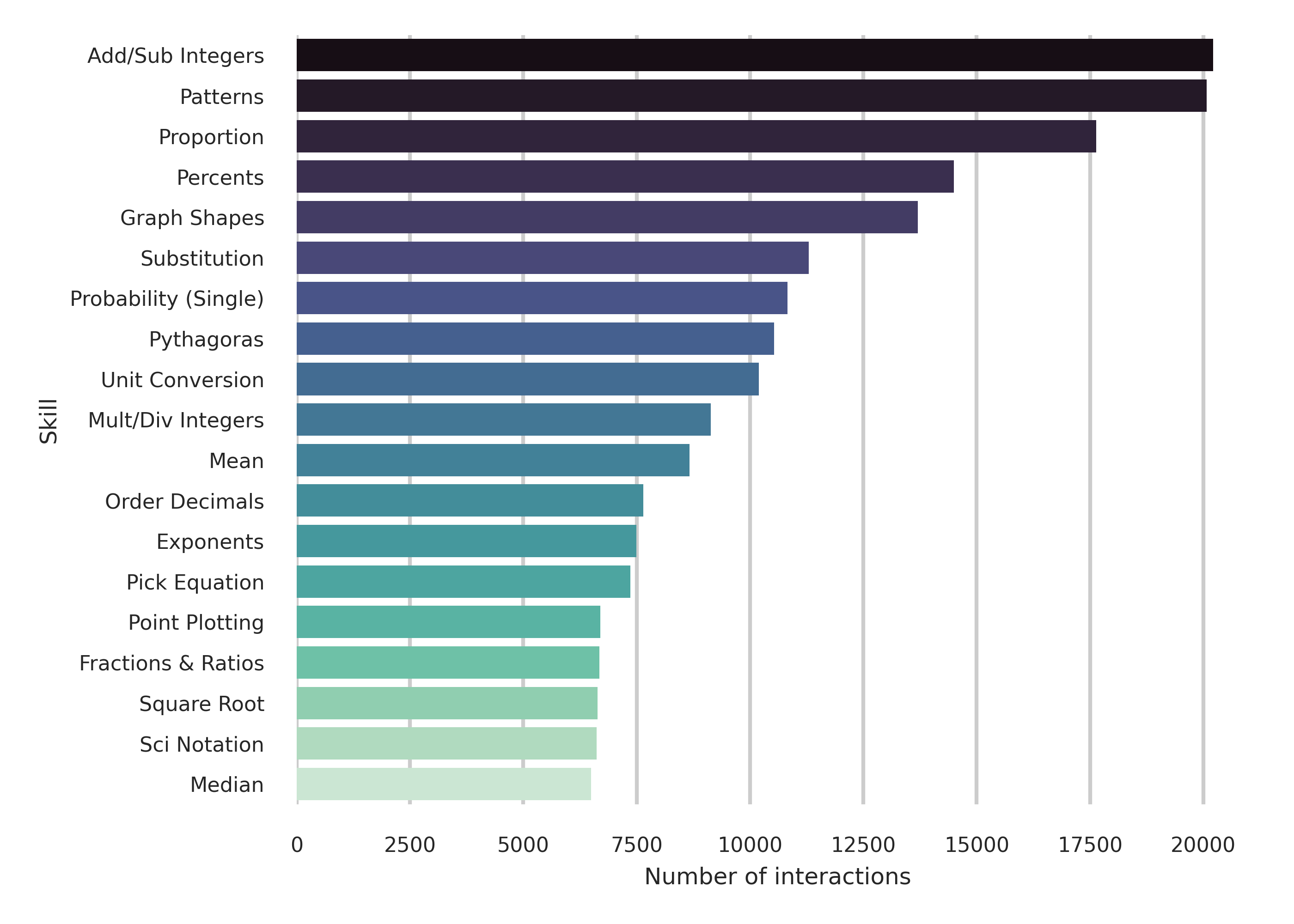
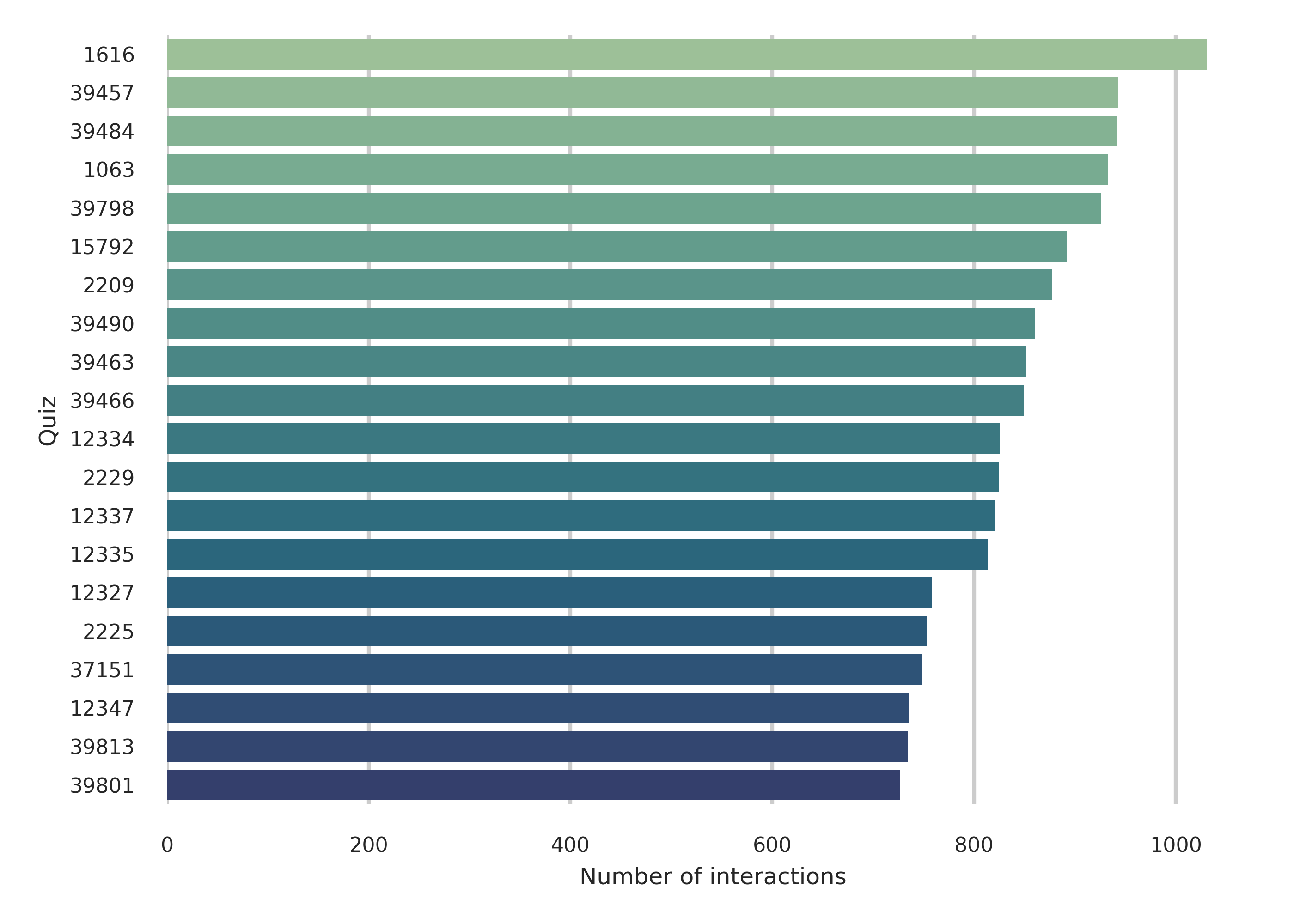
📊 논문 시각자료 (Figures)