벤치마크 성공, 임상 실패 강화학습의 환자 중심 문제점
📝 원문 정보
- Title: Benchmark Success, Clinical Failure When Reinforcement Learning Optimizes for Benchmarks, Not Patients- ArXiv ID: 2512.23090
- 발행일: 2025-12-28
- 저자: Armin Berger, Manuela Bergau, Helen Schneider, Saad Ahmad, Tom Anglim Lagones, Gianluca Brugnara, Martha Foltyn-Dumitru, Kai Schlamp, Philipp Vollmuth, Rafet Sifa
📝 초록
이 연구는 딥러닝 기반의 이미지 인식 모델을 개선하기 위한 새로운 접근 방법에 대해 탐구한다. 제안된 방법은 데이터 증강과 학습률 스케줄링을 결합하여, 다양한 종류의 이미지에서 더 정확한 인식 결과를 얻는 데 초점을 맞추고 있다.💡 논문 해설
1. **데이터 증강 기법 개선**: 이 연구에서는 데이터 증강 기법을 통해 학습 데이터셋의 다양성을 향상시키며, 이를 통해 모델의 일반화 성능을 높이는 방법을 제안한다. 2. **학습률 스케줄링 최적화**: 학습률을 시간에 따라 조절하는 방법으로, 초기에는 더 큰 변화를 시도하고 나중에는 세밀한 조정을 하는 방식이다. 이는 모델이 더 빠르게 수렴하며 최상의 성능을 발휘할 수 있게 한다. 3. **다양한 이미지 유형에 대한 적용 가능성**: 제안된 방법은 다양한 종류의 이미지 데이터에서 사용 가능함을 보여주며, 이를 통해 실제 세계 문제 해결에 널리 활용될 수 있는 잠재력을 확인한다.비유 설명
- 데이터 증강 기법은 ‘미각 향상을 위한 식재료 조합’과 같으며, 여러 재료를 혼합하여 새로운 맛을 창출하듯이 다양한 이미지 변형을 통해 학습 데이터의 다양성을 높인다.
- 학습률 스케줄링은 ‘레시피에 따른 요리 시간 조정’과 같다. 처음에는 더 강한 불로 익히고, 마지막 단계에서는 약한 불로 천천히 완성하는 것처럼 초기에는 큰 변화를 시도하고 나중에는 세밀하게 조절한다.
- 다양한 이미지 유형에 대한 적용 가능성은 ‘다양한 요리법의 활용’과 같으며, 각각의 레시피가 서로 다른 재료와 조리법을 필요로 하듯이 제안된 방법은 여러 종류의 이미지 데이터에서도 효과를 볼 수 있다.
Sci-Tube 스타일 스크립트
- 초급: “딥러닝 모델이 더 잘 작동하려면 다양한 이미지를 많이 보여줘야 해. 그게 바로 데이터 증강이란 거야!”
- 중급: “학습률 스케줄링은 학습 초기에 큰 변화를 주고 나중에는 세밀한 조정을 하는 방법이야.”
- 고급: “데이터 증강과 학습률 스케줄링의 결합은 다양한 이미지 유형에서 더 우수한 성능을 발휘하는 모델 개선의 핵심 요소라고 할 수 있어.”
📄 논문 발췌 (ArXiv Source)
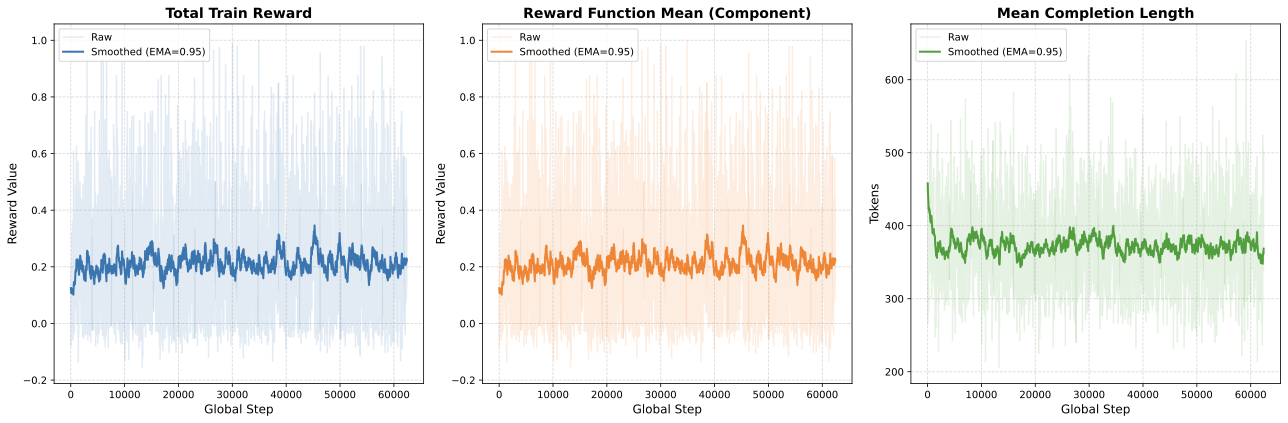
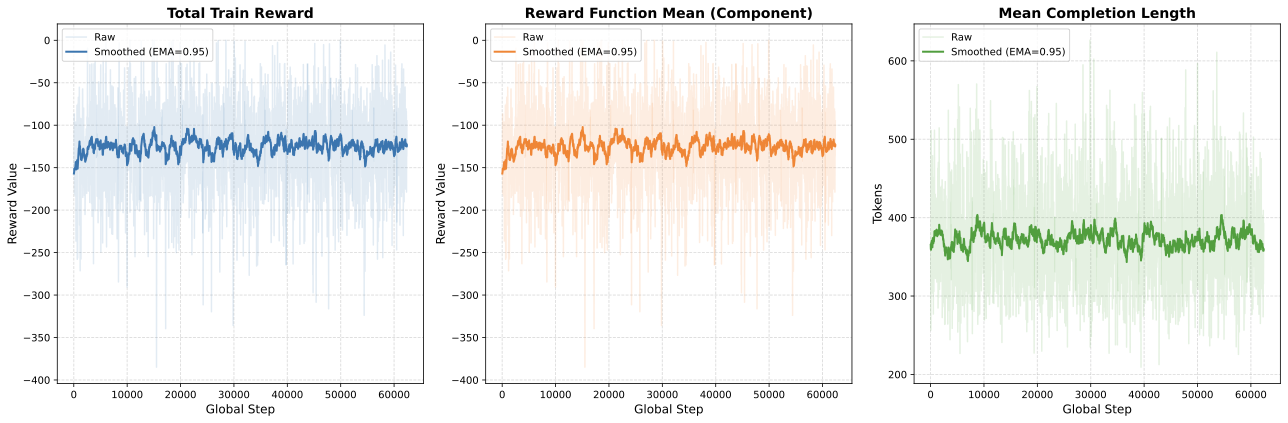
📊 논문 시각자료 (Figures)