감사된 스킬 그래프 기반 자기 개선 검증 가능한 보상과 경험 합성 지속 메모리 관리
📝 원문 정보
- Title: Audited Skill-Graph Self-Improvement for Agentic LLMs via Verifiable Rewards, Experience Synthesis, and Continual Memory
- ArXiv ID: 2512.23760
- 발행일: 2025-12-28
- 저자: Ken Huang, Jerry Huang
📝 초록 (Abstract)
강화학습을 이용해 대형 언어모델을 장기적인 목표를 가진 인터랙티브 에이전트로 전환하는 연구가 활발히 진행되고 있다. 최근 조사에서는 단일 턴 생성에서 순차적 의사결정으로의 전환을 강조하며, 계획·추론·도구 활용·자기 개선·메모리와 같은 핵심 능력으로 에이전트 강화학습을 분류한다. 동시에, 비동기 생성‑학습 파이프라인과 이질적인 환경을 위한 통합 인터페이스가 다중 턴·다중 과제 학습의 안정적 확장을 가능하게 한다는 점이 강조된다. 그러나 실제 배포된 자기 개선 루프는 최적화 압력, 분포 이동, 관측 불완전성으로 인해 보상 해킹, 취약한 특수화, 추적·감사·거버넌스가 어려운 행동 변이와 같은 운영 보안 문제에 직면한다. 본 논문은 자기 개선을 검증자‑감시자가 증거 기반으로 승인을 내리는 성장형 방향성 스킬 그래프로 컴파일하는 “Audited Skill‑Graph Self‑Improvement (ASG‑SI)” 방식을 제안한다. ASG‑SI는 도구 사용 정확성, 결과 타당성, 스킬 재사용, 구성 무결성을 위한 검증 가능한 분해 보상, 대규모 스트레스 테스트와 커리큘럼 커버리지를 위한 경험 합성, 그리고 무한 컨텍스트 성장을 방지하면서 장기 신용 할당을 유지하는 지속 메모리 제어를 결합한다. 핵심 메커니즘은 후보 스킬과 조합을 재생하고 최소 충분 증거 번들을 생성해 승인을 결정하며, 불투명한 선호 신호 대신 재생 가능한 아티팩트에서 형성된 보상을 복원할 수 있게 한다.💡 논문 핵심 해설 (Deep Analysis)

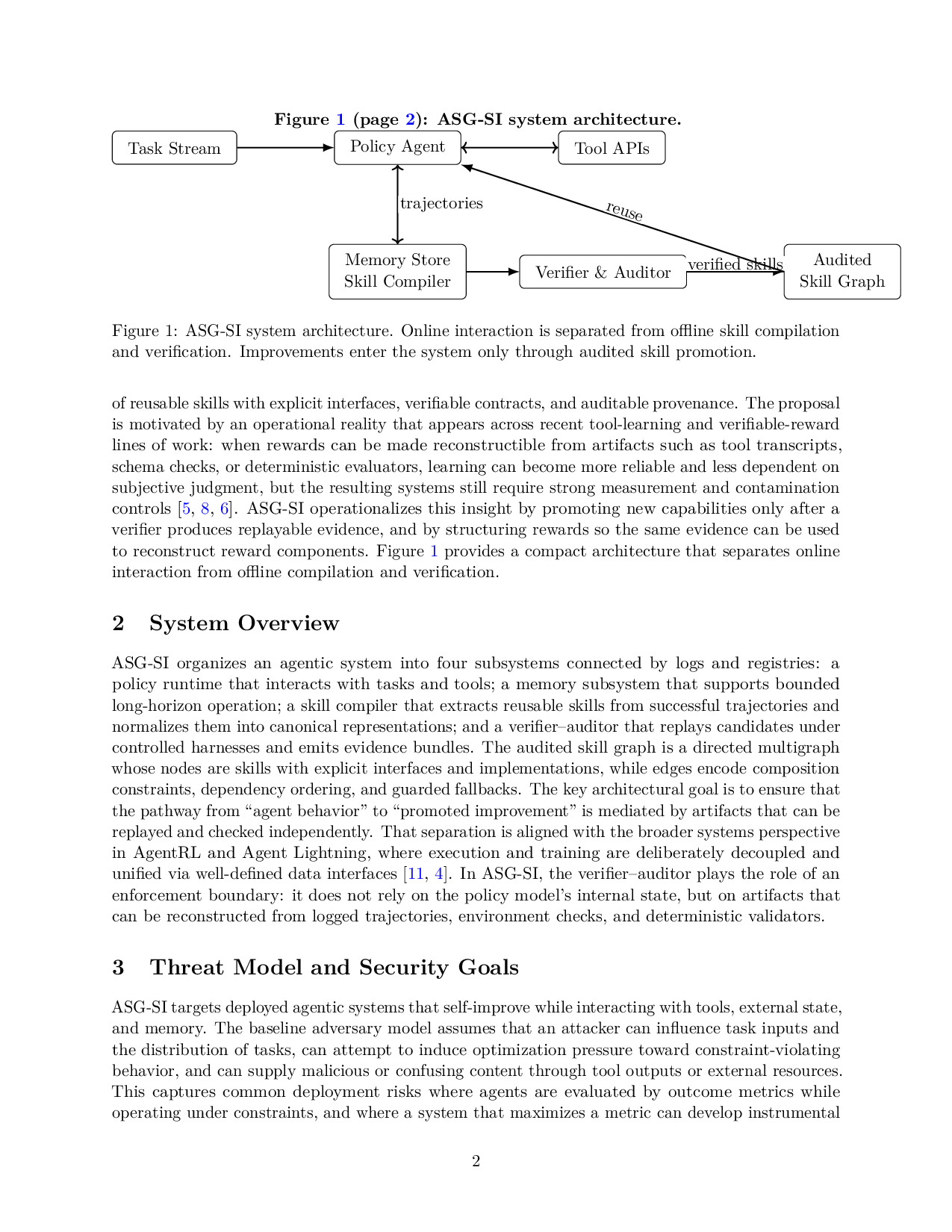
두 번째는 검증자‑감시자 메커니즘이다. 후보 스킬이 그래프에 추가되기 전, 검증자는 해당 스킬을 독립적인 샌드박스 환경에서 재현(replay)한다. 재현 과정에서 도출되는 로그, 입력‑출력 쌍, 도구 호출 기록 등은 “최소 충분 증거(minimally sufficient evidence)”로 압축된다. 이 증거는 형식화된 메타데이터 스키마에 맞춰 저장되며, 이후 감사자는 동일한 증거를 검토해 승인을 내린다. 중요한 점은 증거가 재생 가능하다는 것인데, 이는 향후 동일한 스킬이 동일한 상황에서 동일한 결과를 내는지를 자동으로 검증할 수 있음을 의미한다. 따라서 보상 해킹이나 “숨은 보상 신호”에 의한 편향을 사전에 차단한다.
세 번째는 분해 보상 설계이다. 전통적인 RLHF(인간 피드백 기반 강화학습)에서는 최종 응답에 대한 단일 스칼라 보상이 주어지지만, 이는 왜 특정 스킬이 좋은지 설명하기 어렵다. ASG‑SI는 보상을 네 가지 축으로 분해한다. ① 도구 사용 정확성(예: API 호출 파라미터가 스키마와 일치하는가), ② 결과 타당성(생성된 텍스트·데이터가 목표와 일치하는가), ③ 스킬 재사용성(이미 존재하는 스킬을 얼마나 효율적으로 조합했는가), ④ 구성 무결성(스킬 조합이 논리적·형식적으로 일관되는가). 각 축은 독립적인 검증 로직을 갖고, 전체 보상은 가중합으로 계산된다. 이렇게 하면 특정 스킬이 하나의 축에서 높은 점수를 받아 전체 시스템을 오염시키는 상황을 방지한다.
네 번째는 **경험 합성(Experience Synthesis)**이다. 실제 환경에서 충분한 다양성을 확보하기 위해서는 방대한 양의 상호작용 데이터가 필요하지만, 비용과 시간 제약이 있다. ASG‑SI는 기존 스킬 그래프와 메타 모델을 활용해 가상 시나리오를 자동 생성한다. 합성된 경험은 난이도와 도메인 다양성을 조절할 수 있어, 에이전트가 아직 다루지 못한 “극한 상황”을 미리 스트레스 테스트한다. 이는 커리큘럼 학습과 유사하게, 쉬운 과제에서 점진적으로 어려운 과제로 이동하도록 돕는다.
마지막으로 지속 메모리 관리이다. LLM은 컨텍스트 길이에 제한이 있기 때문에, 장기적인 기억을 무한히 누적하면 중요한 정보가 희석된다. ASG‑SI는 메모리를 계층적 요약하고, 오래된 스킬에 대한 메타 정보를 압축 저장한다. 또한, 그래프 기반 메모리는 “시간에 따라 중요한 노드만 활성화”하는 메커니즘을 제공해, 장기 보상 신호가 필요한 상황에서도 필요한 정보를 빠르게 검색할 수 있다. 이는 기존의 단순 롤링 윈도우 방식보다 효율적이며, 메모리 부하와 연산 비용을 크게 낮춘다.
전체적으로 ASG‑SI는 투명성·검증 가능성·안전성을 강화하면서도, 스킬 재사용과 자동 커리큘럼을 통해 학습 효율성을 유지한다. 다만 구현상의 과제로는 (1) 검증자와 샌드박스 환경의 정밀도와 비용 관리, (2) 증거 번들의 표준화와 상호운용성, (3) 그래프 규모가 커짐에 따라 검색·합성 효율을 유지하는 알고리즘 설계가 있다. 향후 연구는 이러한 엔지니어링 문제를 해결하고, 실제 산업 현장에서 ASG‑SI가 어떻게 정책·규제 프레임워크와 연계될 수 있는지를 탐색해야 할 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리