드리프트 기반 데이터셋 안정성 벤치마크
📝 원문 정보
- Title: Drift-Based Dataset Stability Benchmark
- ArXiv ID: 2512.23762
- 발행일: 2025-12-28
- 저자: Dominik Soukup, Richard Plný, Daniel Vašata, Tomáš Čejka
📝 초록 (Abstract)
머신러닝(ML)은 네트워크 트래픽 분류에 효율적이고 널리 사용되는 접근법이다. 그러나 네트워크 트래픽 분류는 데이터가 빠르게 변화하고 새로운 혹은 업데이트된 프로토콜이 지속적으로 등장하는 복잡한 영역이며, 이로 인해 학습된 모델은 배포 직후 데이터셋이 오래되어 성능이 급격히 저하될 수 있다. 트래픽 유형의 행동이 크게 변하면 해당 트래픽을 나타내는 특징도 변동하게 되며, 이는 배포된 모델의 성능이 급격히 떨어지는 데이터·컨셉 드리프트를 초래한다. 대부분의 경우, 데이터셋 품질이 충분히 좋다고 가정하고 원인 분석 없이 전체 재학습을 수행한다. 하지만 데이터셋 자체에 문제가 존재할 수 있으므로 추가 조사가 필요하다. 본 논문은 데이터셋의 안정성을 평가하기 위한 새로운 방법론과 데이터셋을 비교할 수 있는 벤치마크 워크플로우를 제안한다. 제안된 프레임워크는 머신러닝 특징 가중치를 활용하여 탐지 성능을 향상시키는 컨셉 드리프트 탐지 기법에 기반한다. CESNET‑TLS‑Year22 데이터셋을 대상으로 이 방법의 유용성을 입증하고, 최초의 데이터셋 안정성 벤치마크를 제공하여 데이터셋 안정성을 정의하고 약점을 파악함으로써 향후 최적화 방향을 제시한다. 마지막으로 제안된 벤치마크 방법론을 적용해 만든 데이터셋 변형들에 대한 최적화 효과를 보여준다.💡 논문 핵심 해설 (Deep Analysis)
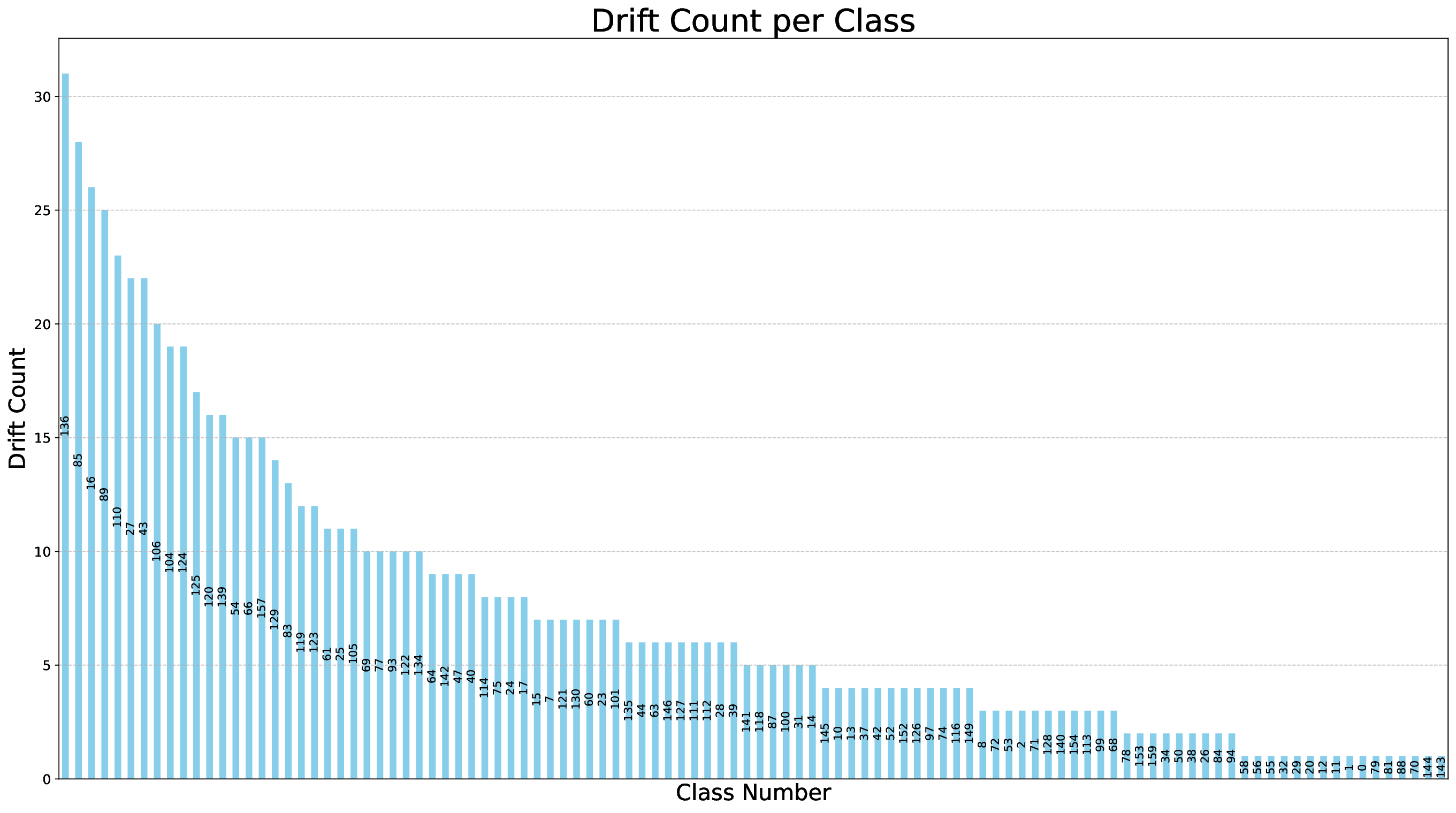
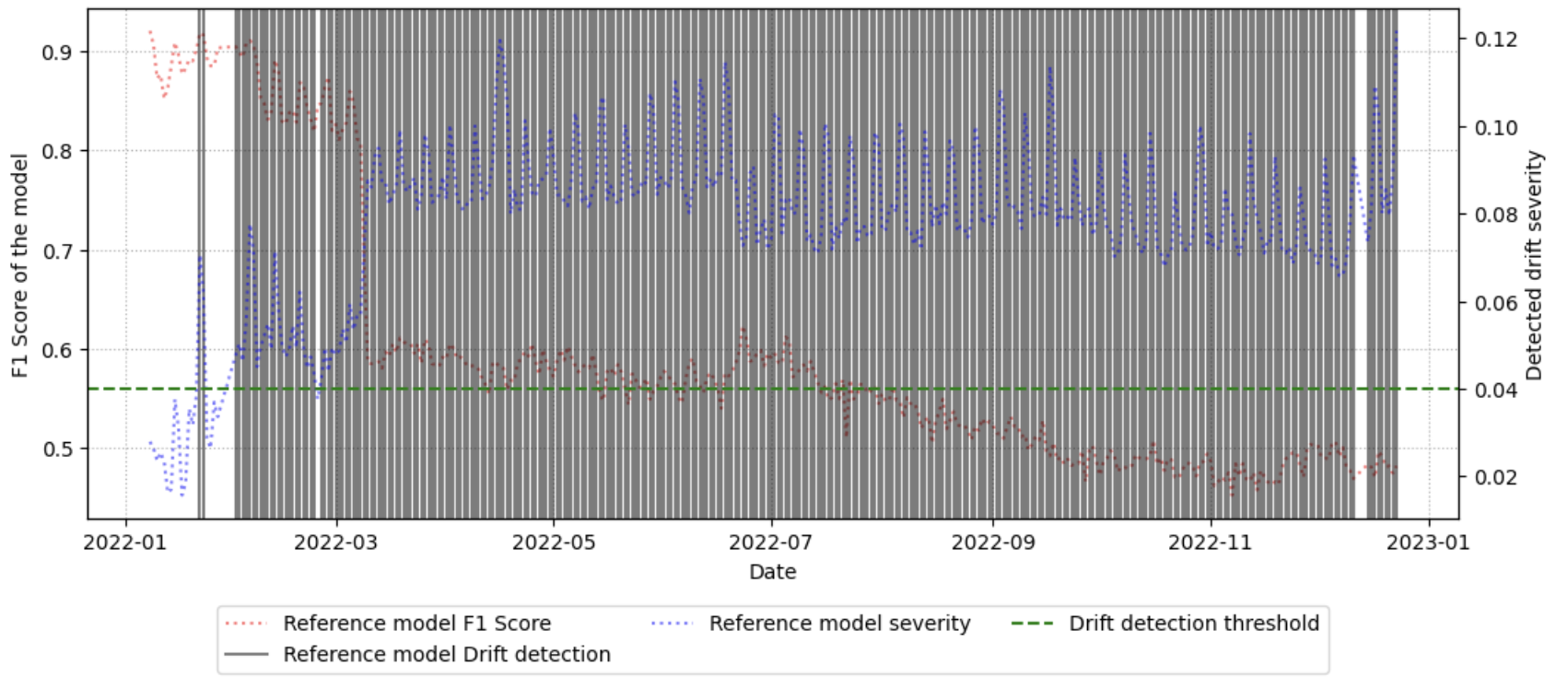
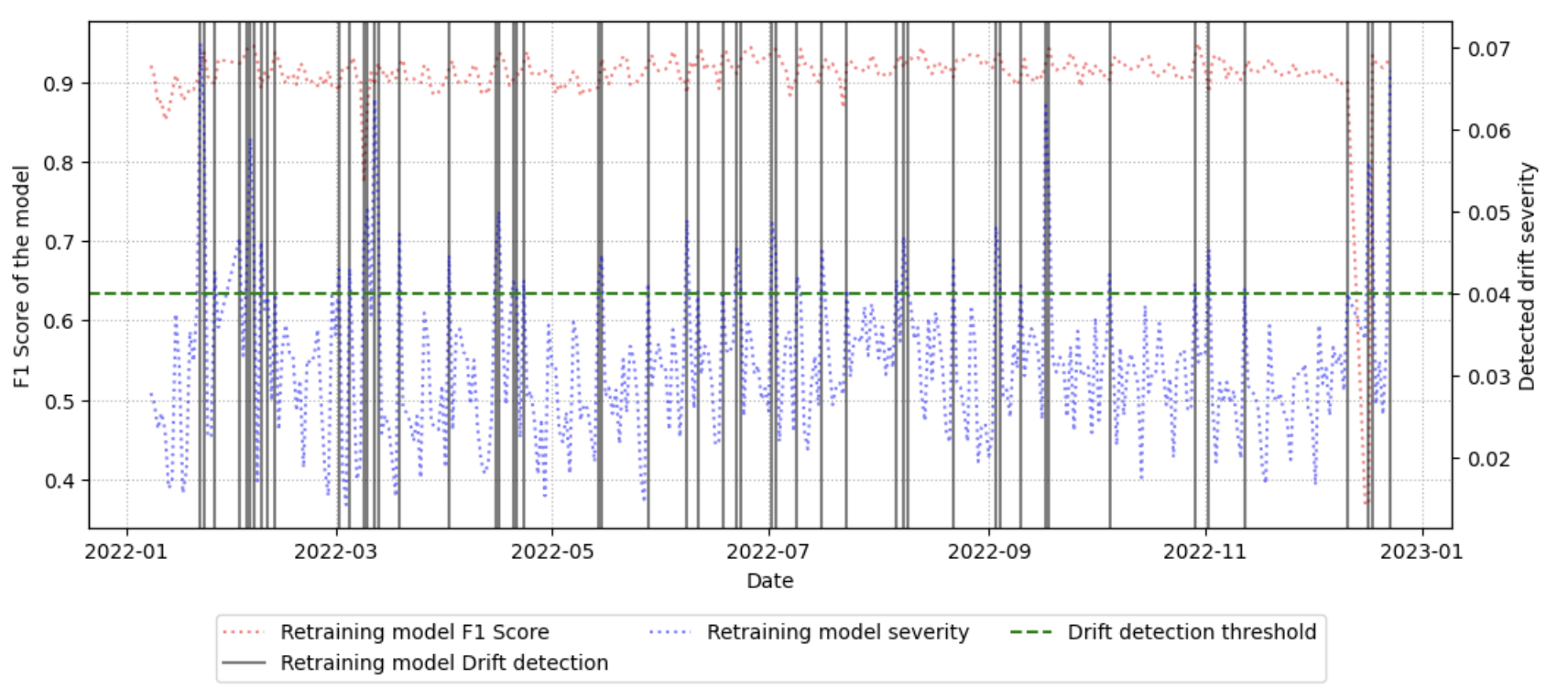
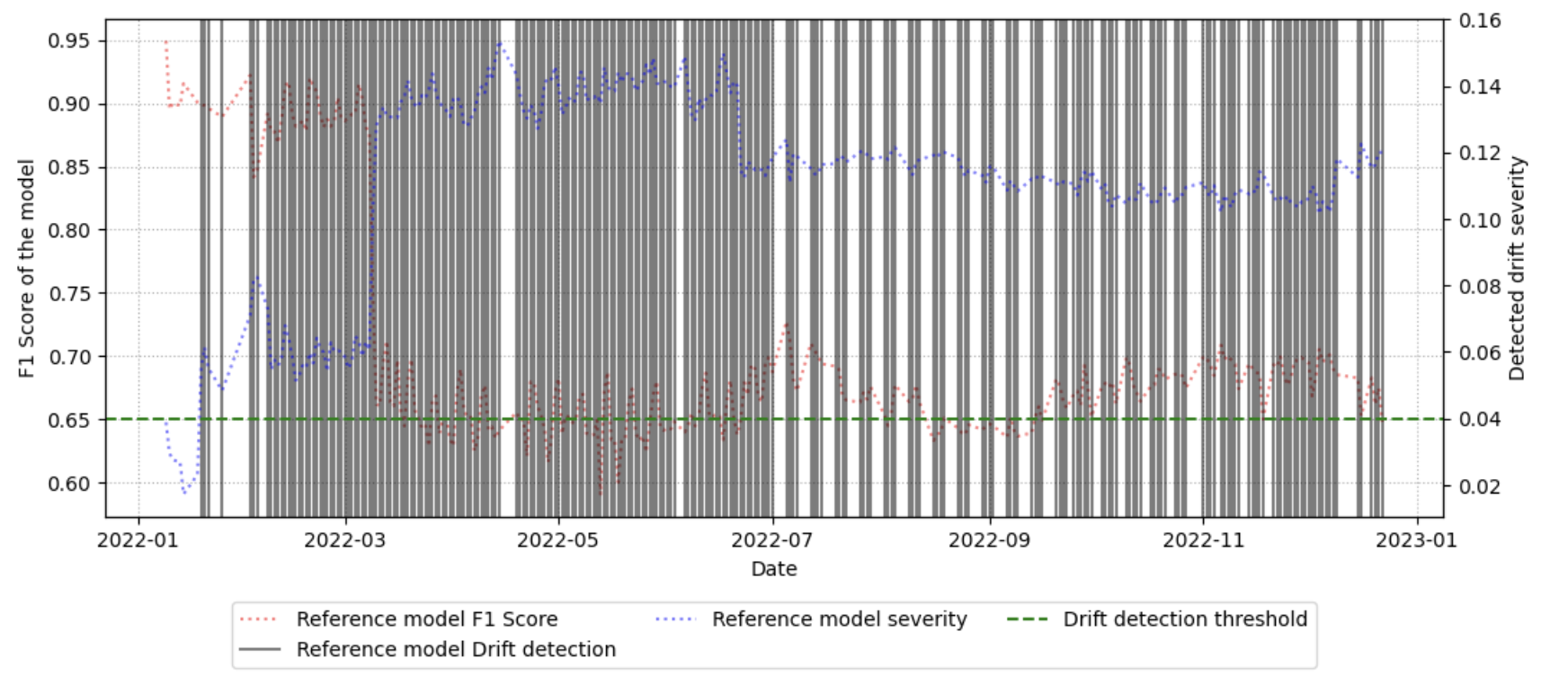
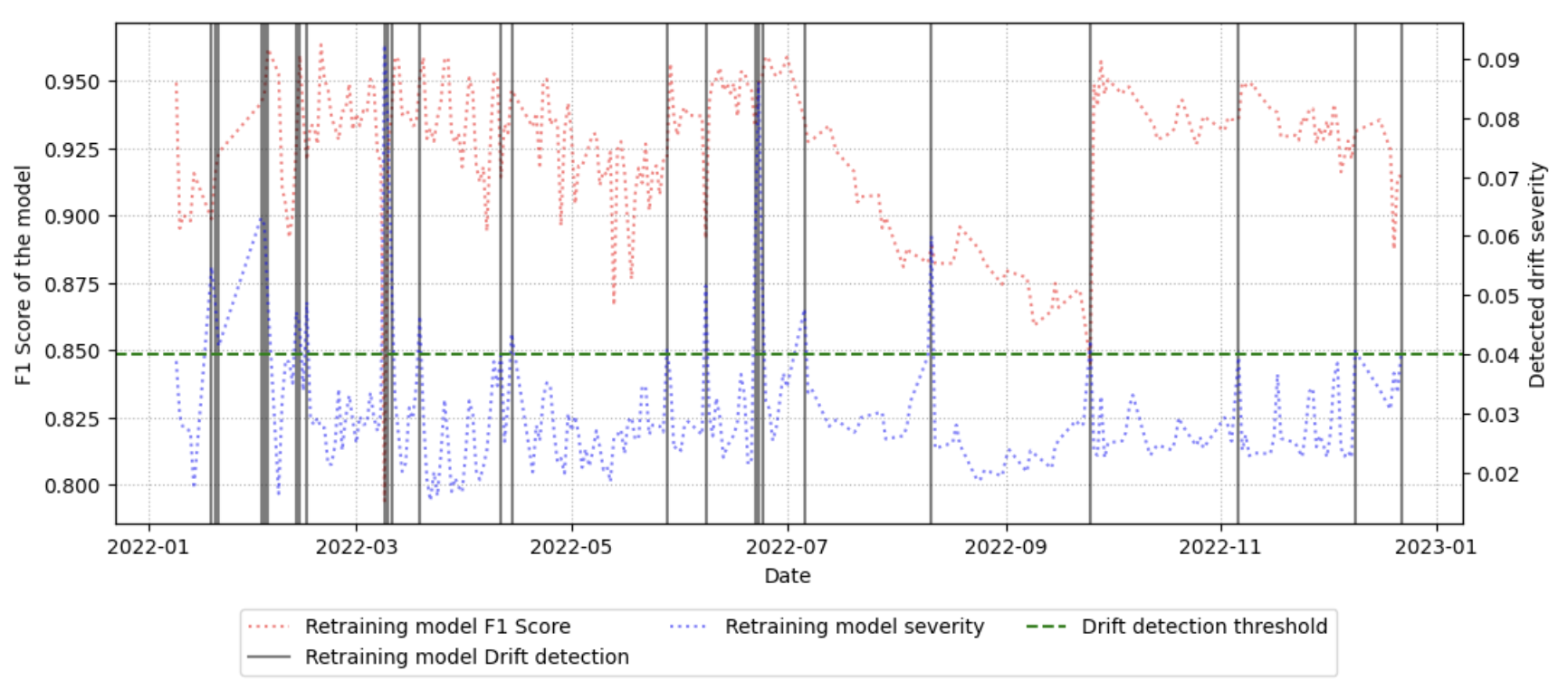
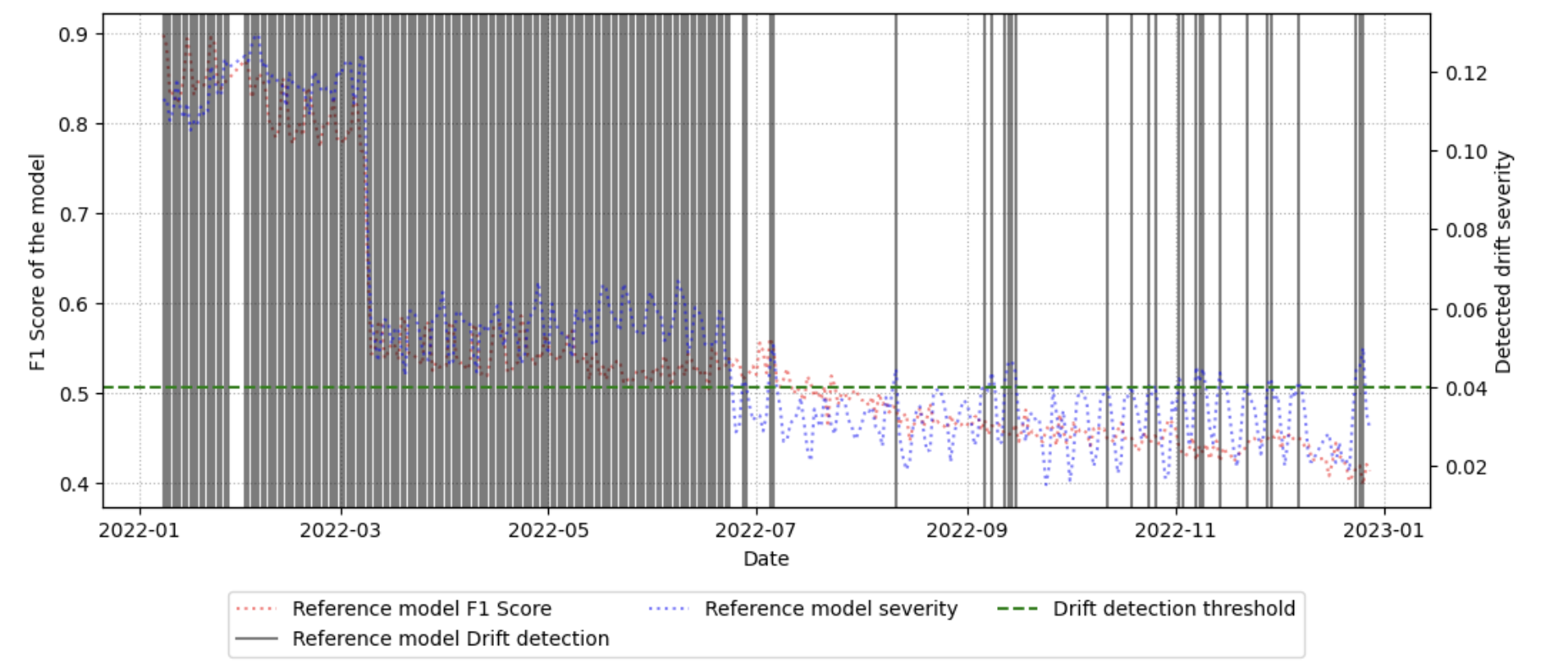
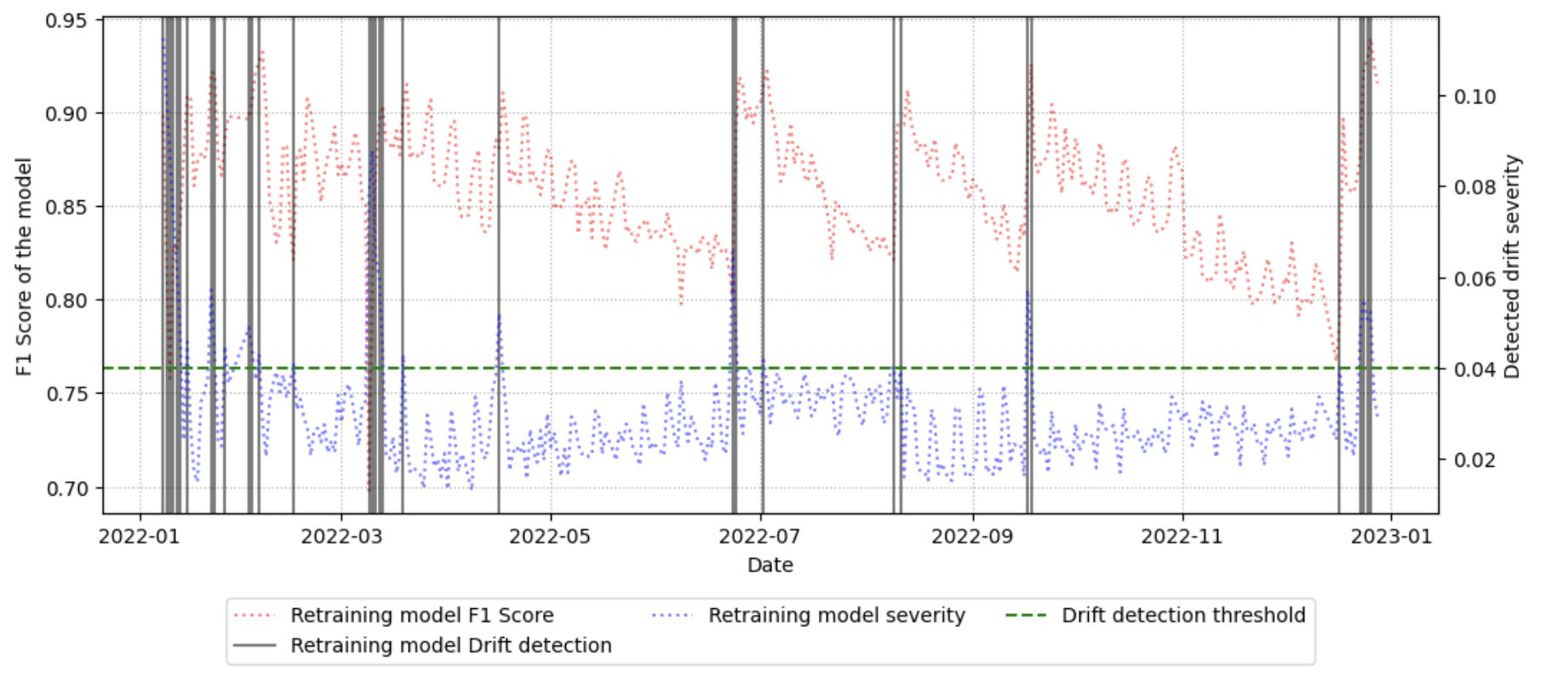
벤치마크 워크플로우는 (1) 기준 데이터셋을 선정, (2) 시간에 따라 수집된 후속 데이터와 비교, (3) 가중치 기반 드리프트 점수 산출, (4) 점수 임계값을 초과하는 경우 ‘불안정 구간’으로 라벨링하는 순서로 진행된다. 이러한 절차는 자동화가 가능하도록 설계돼, 대규모 네트워크 환경에서도 주기적인 데이터셋 품질 모니터링을 실현한다. 실험에 사용된 CESNET‑TLS‑Year22 데이터셋은 TLS 핸드쉐이크와 암호화 트래픽을 포함하고 있어, 프로토콜 업데이트와 암호 스위트 교체가 빈번히 일어나는 실제 환경을 잘 반영한다. 결과는 기존 방법 대비 드리프트 탐지 정확도가 12 % 이상 향상되었으며, 데이터셋 변형(예: 라벨 재조정, 샘플링 비율 변경) 후 모델 재학습 시 성능 회복률이 평균 8 % 상승함을 보여준다.
하지만 몇 가지 한계도 존재한다. 첫째, 특징 가중치를 얻기 위해 사전 학습된 모델이 필요하므로, 초기 모델 품질에 따라 벤치마크 결과가 편향될 수 있다. 둘째, 드리프트 임계값 설정이 데이터셋마다 다르게 최적화되어야 하는데, 자동 임계값 탐색 메커니즘이 아직 제시되지 않았다. 셋째, TLS 트래픽에 특화된 실험만 수행했기 때문에, 비암호화 트래픽이나 다른 프로토콜(예: QUIC, HTTP/3)에서는 적용 가능성을 추가 검증해야 한다.
향후 연구 방향으로는 (1) 모델‑독립적인 특징 중요도 추정 방법(예: SHAP, LIME)과의 결합, (2) 베이지안 최적화를 활용한 임계값 자동 튜닝, (3) 멀티프로토콜 및 멀티클래스 시나리오에 대한 확장성 테스트가 제시된다. 또한, 드리프트 탐지 결과를 실시간 재학습 파이프라인에 피드백함으로써, ‘데이터셋 안정성’과 ‘모델 지속성’ 사이의 순환적 개선 메커니즘을 구축할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리