LLM 기반 학습자 모델링의 한계와 K12 책임형 튜터링 필요성
📝 원문 정보
- Title: Problems With Large Language Models for Learner Modelling: Why LLMs Alone Fall Short for Responsible Tutoring in K–12 Education
- ArXiv ID: 2512.23036
- 발행일: 2025-12-28
- 저자: Danial Hooshyar, Yeongwook Yang, Gustav Šíř, Tommi Kärkkäinen, Raija Hämäläinen, Mutlu Cukurova, Roger Azevedo
📝 초록 (Abstract)
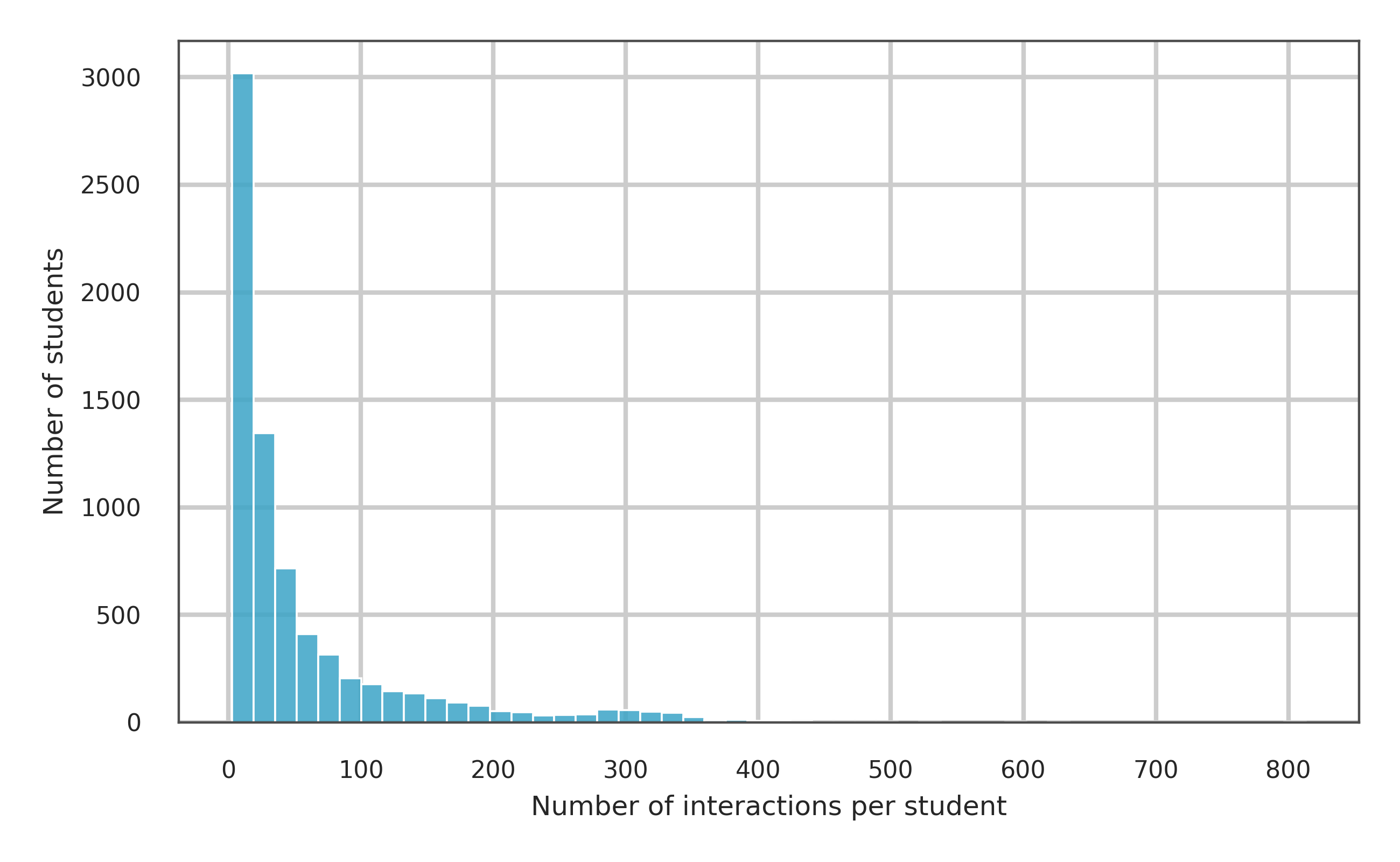
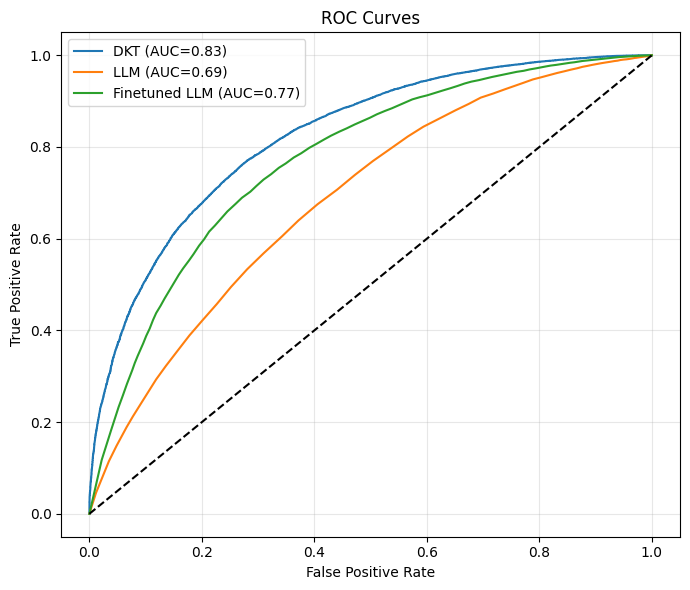
대규모 언어 모델(LLM)을 활용한 K‑12 교육용 튜터가 급속히 등장하면서, 생성 모델이 기존 학습자 모델링을 대체하고 적응형 교육을 위한 범용 엔진이 될 수 있다는 오해가 퍼지고 있다. 이는 특히 EU AI 법이 고위험 분야로 규정한 K‑12 교육에서 책임 있는 설계가 요구되는 상황과 충돌한다. 본 연구는 책임 있는 AI 기반 튜터링에서 학습자 모델링의 역할에 대한 우려를 바탕으로, LLM 기반 튜터 시스템의 주요 제한점에 대한 기존 연구 증거를 종합하고, 학습자의 지식 변화 추적 정확성·신뢰성·시간적 일관성을 한 가지 핵심 측면으로 실증 조사한다. 이를 위해 대규모 공개 데이터셋을 이용해 딥 지식 추적(DKT) 모델과 널리 사용되는 LLM(미세조정 전·후)을 비교하였다. 결과는 DKT가 다음 단계 정답 예측에서 가장 높은 구별 성능(AUC = 0.83)을 보이며 모든 평가 설정에서 LLM을 지속적으로 앞섰음을 보여준다. 미세조정이 LLM의 AUC를 제로샷 대비 약 8% 향상시키지만, 여전히 DKT보다 6% 낮으며 초기 시퀀스에서 오류가 더 많이 발생한다. 초기 오류는 적응형 학습 지원에 가장 큰 해를 끼칠 수 있다. 시간적 일관성 분석에서는 DKT가 안정적이고 방향이 올바른 숙달 업데이트를 유지하는 반면, LLM 변형은 큰 시간적 약점을 보이며 부드럽지만 잘못된 방향의 업데이트를 나타내고, 미세조정 후에도 이러한 문제를 완전히 해소하지 못한다.💡 논문 핵심 해설 (Deep Analysis)
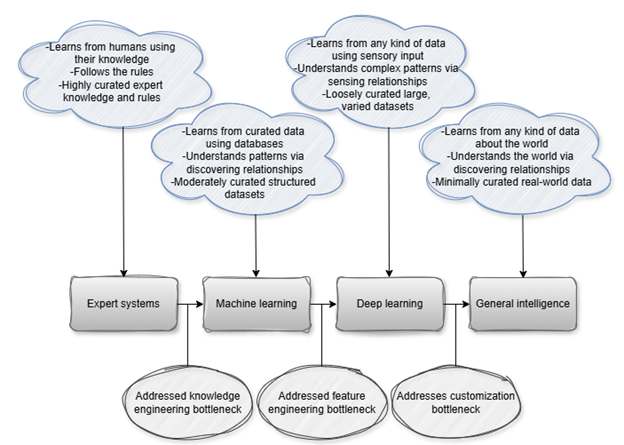
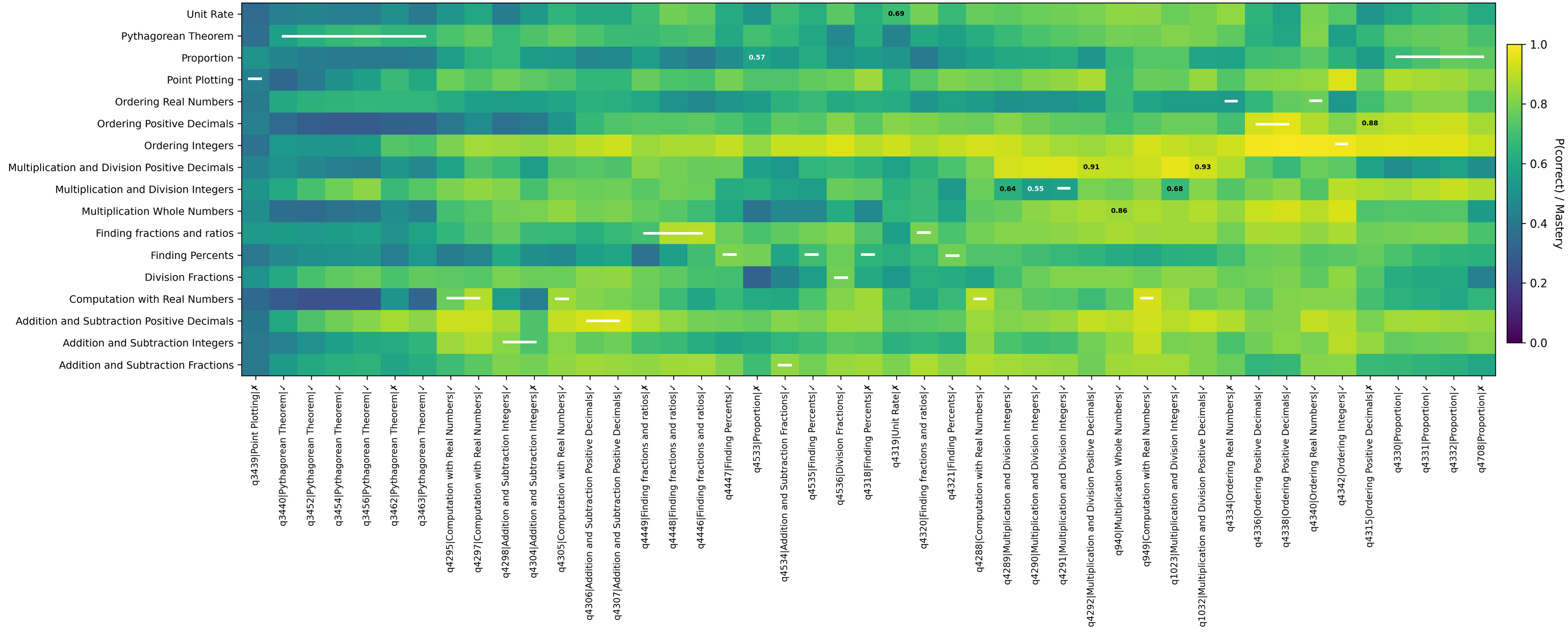
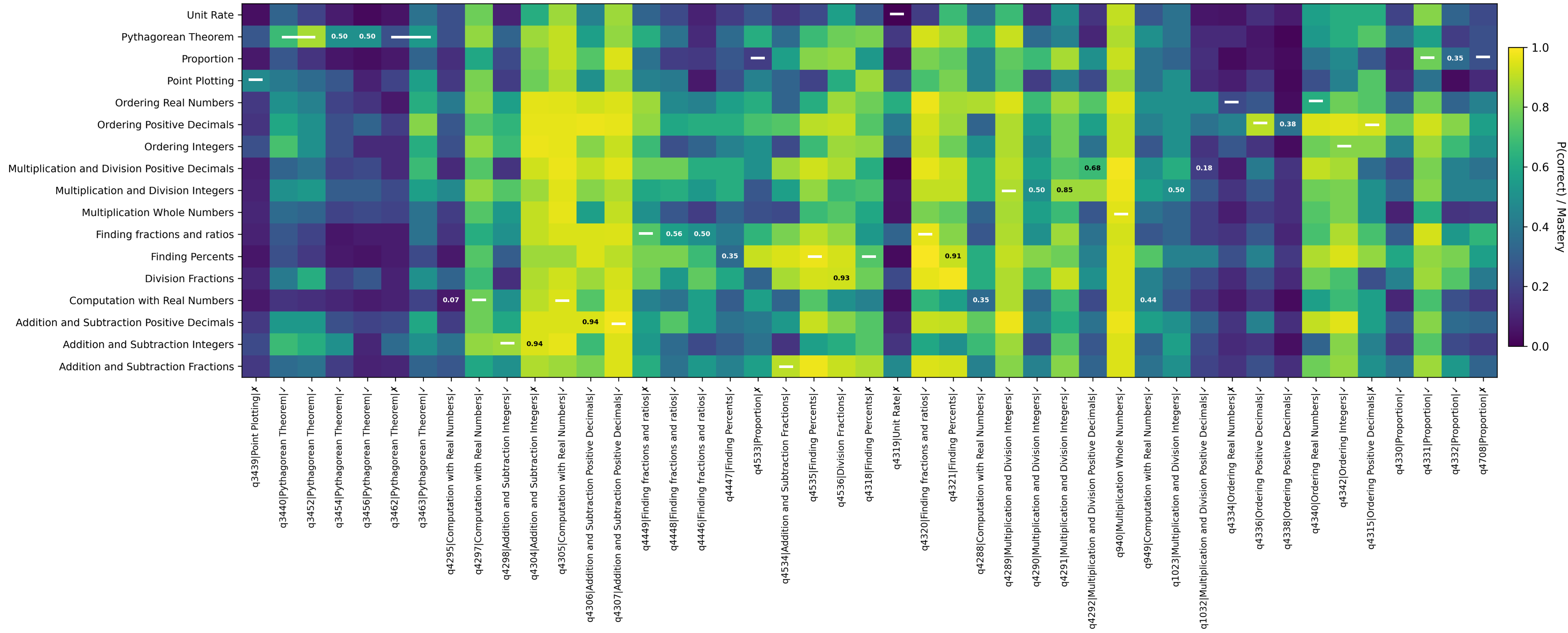
방법론 측면에서 저자는 두 가지 핵심 모델을 비교한다. 하나는 전통적인 딥 지식 추적(Deep Knowledge Tracing, DKT) 모델로, 학생-문제 상호작용 데이터를 시계열적으로 처리해 각 개념에 대한 숙달 확률을 추정한다. 다른 하나는 최신 LLM(예: GPT‑계열)으로, 사전학습된 거대한 언어 이해 능력을 활용해 동일한 입력(학생의 정답 이력)으로 다음 문제 정답 확률을 예측한다. LLM에 대해서는 ‘제로샷’ 상태와 도메인 특화 데이터로 미세조정한 두 버전을 모두 실험한다.
실험 결과는 여러 차원에서 일관되게 DKT가 우수함을 보여준다. 첫째, AUC(곡선 아래 면적) 지표에서 DKT는 0.83이라는 높은 값을 기록했으며, 이는 LLM 제로샷(≈0.70)과 미세조정 후 LLM(≈0.76) 모두를 크게 앞선다. 둘째, 오류 발생 패턴을 살펴보면 LLM은 초기 학습 단계, 즉 학생이 아직 충분한 데이터를 제공하지 않은 상황에서 오히려 높은 오류율을 보인다. 초기 오류는 학습자에게 부적절한 피드백을 제공하거나, 난이도가 부적절한 과제를 제시함으로써 학습 동기를 저하시킬 위험이 크다. 셋째, 시간적 일관성 분석에서는 DKT가 학습자의 숙달 수준을 상승·하강시키는 방향을 정확히 포착하는 반면, LLM은 ‘부드럽지만 잘못된 방향’의 업데이트를 보인다. 이는 LLM이 시계열적 의존성을 충분히 모델링하지 못하고, 현재 입력에 과도하게 의존해 과거 정보를 적절히 통합하지 못한다는 근본적인 구조적 한계를 시사한다.
이러한 결과는 몇 가지 중요한 시사점을 제공한다. 첫째, LLM을 단독으로 학습자 모델링에 활용하는 것은 현재 기술 수준에서 신뢰성·안정성 측면에서 부족하다. 둘째, 미세조정이 성능을 일정 부분 회복시키긴 하지만, 근본적인 시계열 처리 능력과 오류 민감도 문제는 해결되지 않는다. 셋째, 책임 있는 AI 튜터링을 구현하려면 LLM과 전통적인 추적 모델을 하이브리드 방식으로 결합하거나, LLM의 출력에 대한 후처리·검증 메커니즘을 추가해야 한다.
마지막으로 논문은 정책·윤리적 관점에서도 중요한 논의를 제시한다. EU AI Act가 요구하는 ‘고위험’ 시스템에 대한 사전 위험 평가와 지속적인 모니터링을 고려할 때, LLM 기반 튜터는 현재 수준으로는 규제 요건을 충족시키기 어렵다. 따라서 교육 기관·개발자는 모델 선택 시 성능뿐 아니라 투명성·해석 가능성·시간적 일관성 등을 종합적으로 평가하고, 필요시 인간 교사의 개입을 보장하는 설계 원칙을 채택해야 한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리