터키어 자연어 이해를 위한 종합 벤치마크: TrGLUE와 SentiTurca 소개
📝 원문 정보
- Title: Introducing TrGLUE and SentiTurca: A Comprehensive Benchmark for Turkish General Language Understanding and Sentiment Analysis
- ArXiv ID: 2512.22100
- 발행일: 2025-12-26
- 저자: Duygu Altinok
📝 초록 (Abstract)
다양한 모델 아키텍처, 특히 트랜스포머, 대형 언어 모델(LLM), 그리고 다른 NLP 시스템의 성능을 평가하기 위해서는 여러 차원에서 성능을 측정하는 종합적인 벤치마크가 필요합니다. 이 중 자연어 이해(NLU)의 평가는 특히 중요하며, 이를 통해 모델의 능력을 평가할 수 있는 기본 기준이 됩니다. 따라서 다양한 관점에서 NLU 능력을 철저하게 평가하고 분석할 수 있는 벤치마크를 설정하는 것이 필수적입니다. GLUE 벤치마크는 영어 NLU의 평가에 대한 표준을 세웠지만, 중국어 CLUE, 프랑스어 FLUE, 일본어 JGLUE와 같이 다른 언어에도 유사한 벤치마크가 개발되었습니다. 그러나 터키어에는 아직 그러한 벤치마크가 존재하지 않습니다. 이러한 간극을 메우기 위해 우리는 다양한 NLU 작업을 포괄하는 터키어를 위한 종합 벤치마크인 TrGLUE와 감성 분석에 특화된 SentiTurca를 소개합니다.💡 논문 핵심 해설 (Deep Analysis)
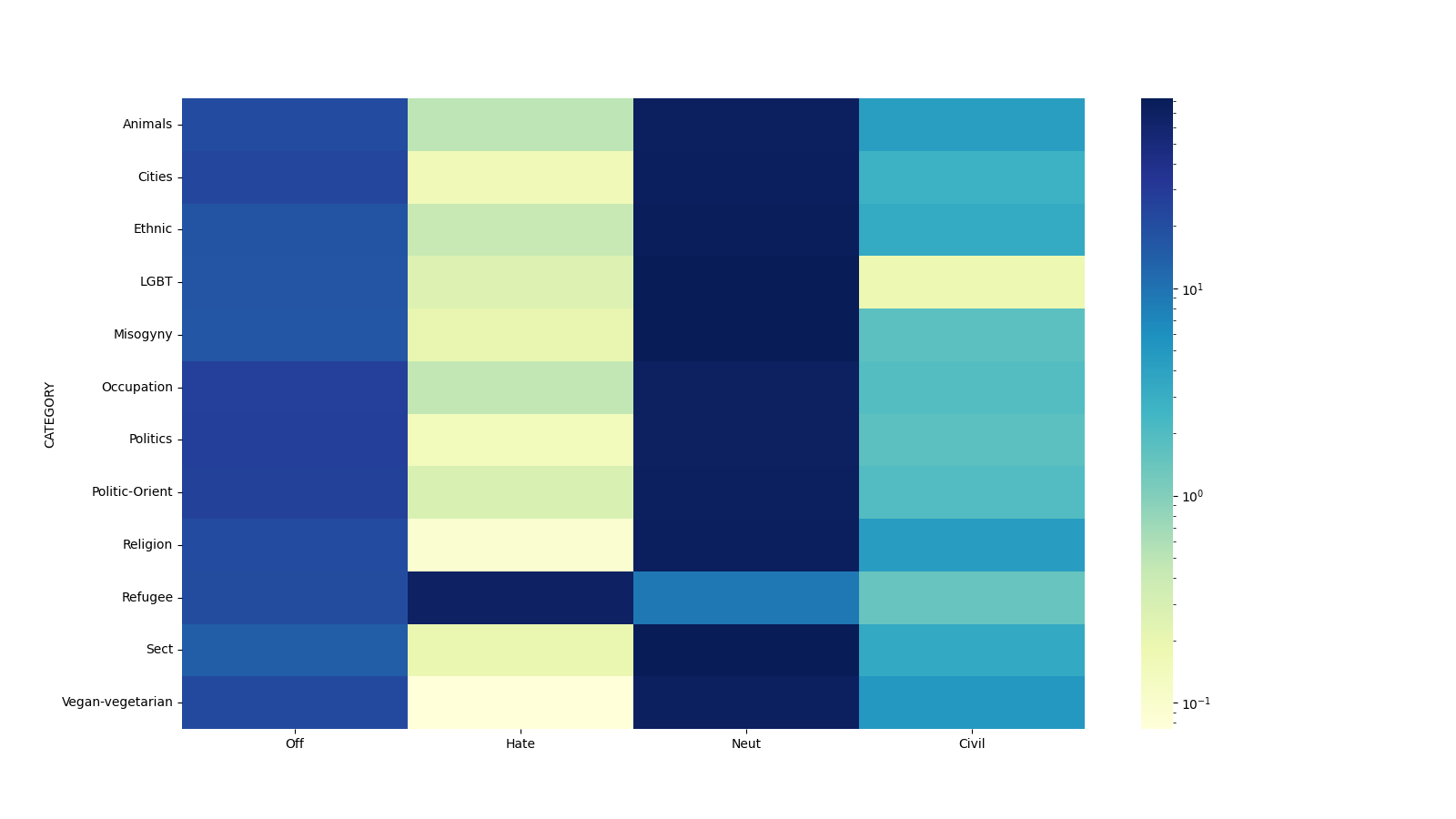
논문은 다양한 언어별로 개발된 벤치마크를 소개하며, 이러한 벤치마크의 중요성을 강조하고 있습니다. 특히, 터키어에 대한 종합적인 NLU 평가 벤치마크가 부재한 상황을 지적하면서 TrGLUE와 SentiTurca의 필요성과 중요성을 설명합니다.
TrGLUE는 터키어 원문 코퍼스를 사용하여 GLUE 스타일의 평가 도메인과 작업 형식을 반영하고, 강력한 LLM 기반 주석화와 모델 간 합의 검사 및 후속 인간 검증을 통한 라벨링 프로세스를 통해 구성됩니다. 이는 언어적 자연성을 최대한 유지하면서 직접 번역으로 인한 오류를 최소화하고, 확장 가능하고 재현 가능한 워크플로우를 제공합니다.
논문은 연구자들이 이러한 벤치마크를 효과적으로 활용할 수 있도록 트랜스포머 기반 모델의 조정과 평가 코드도 제공합니다. 이를 통해 터키어 NLU의 강력한 평가 프레임워크를 구축하고, 연구자들에게 가치 있는 자원을 제공하며, 고품질의 반자동 데이터셋 생성에 대한 통찰력을 제공하는 것을 목표로 합니다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리
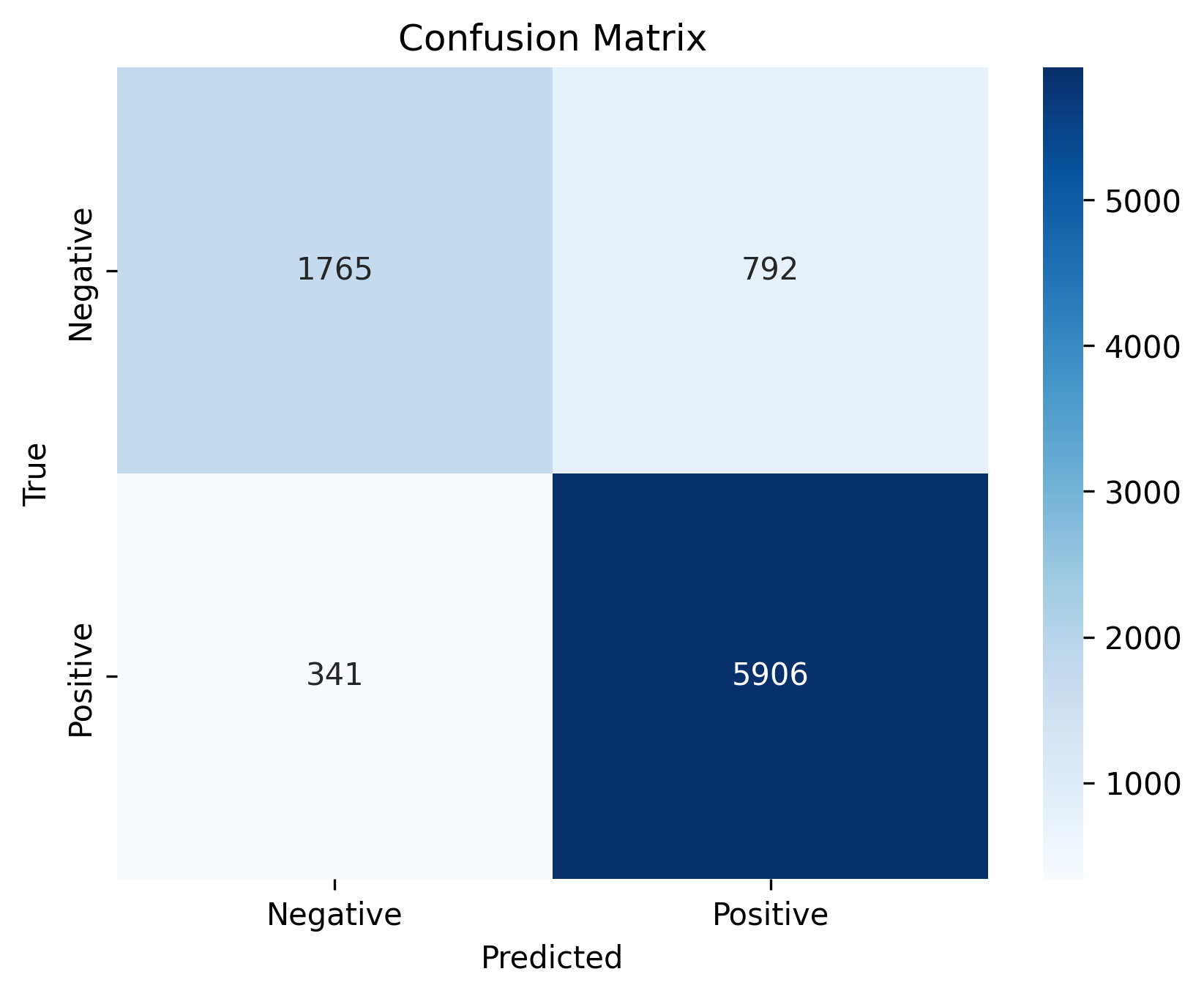
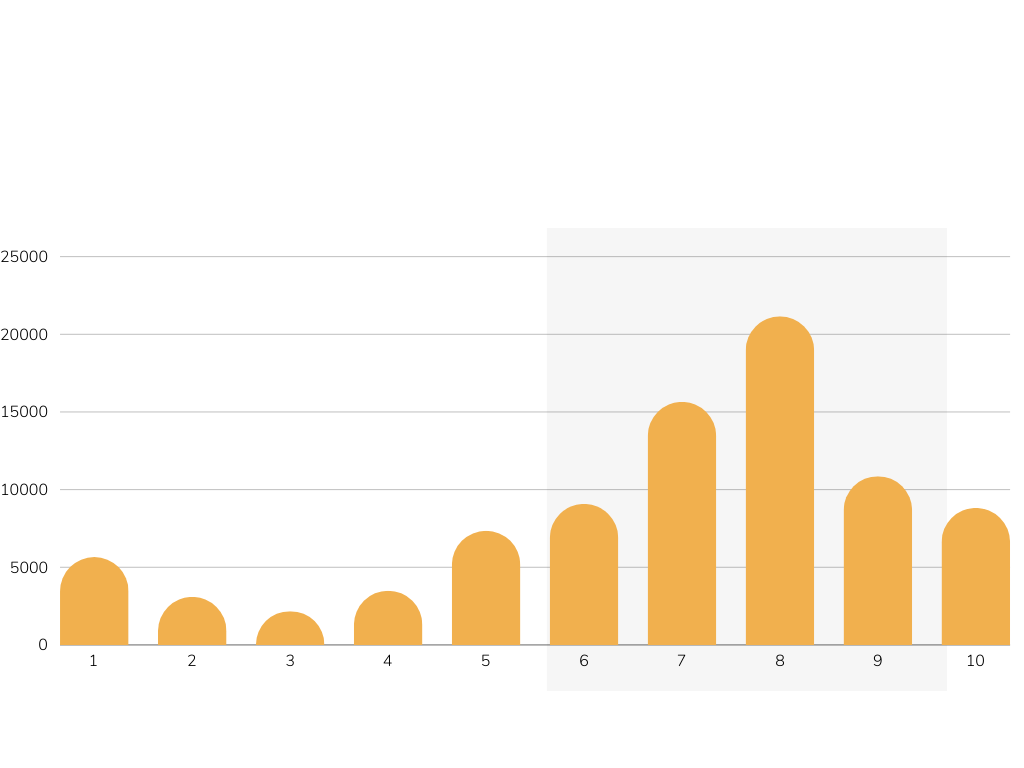
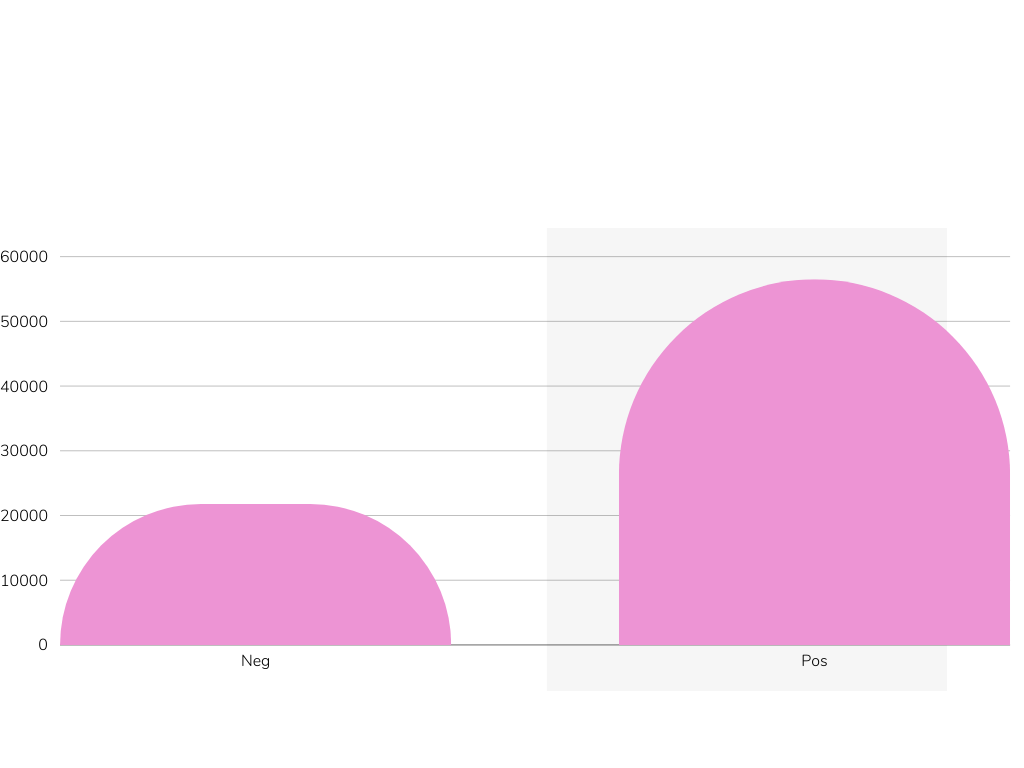
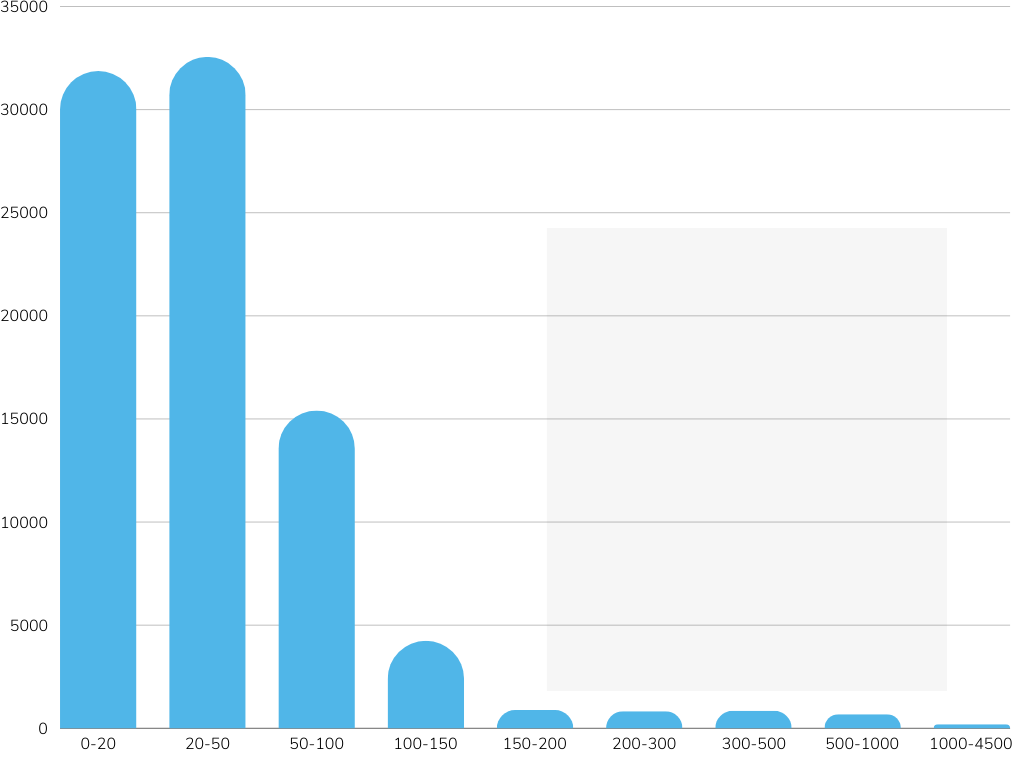
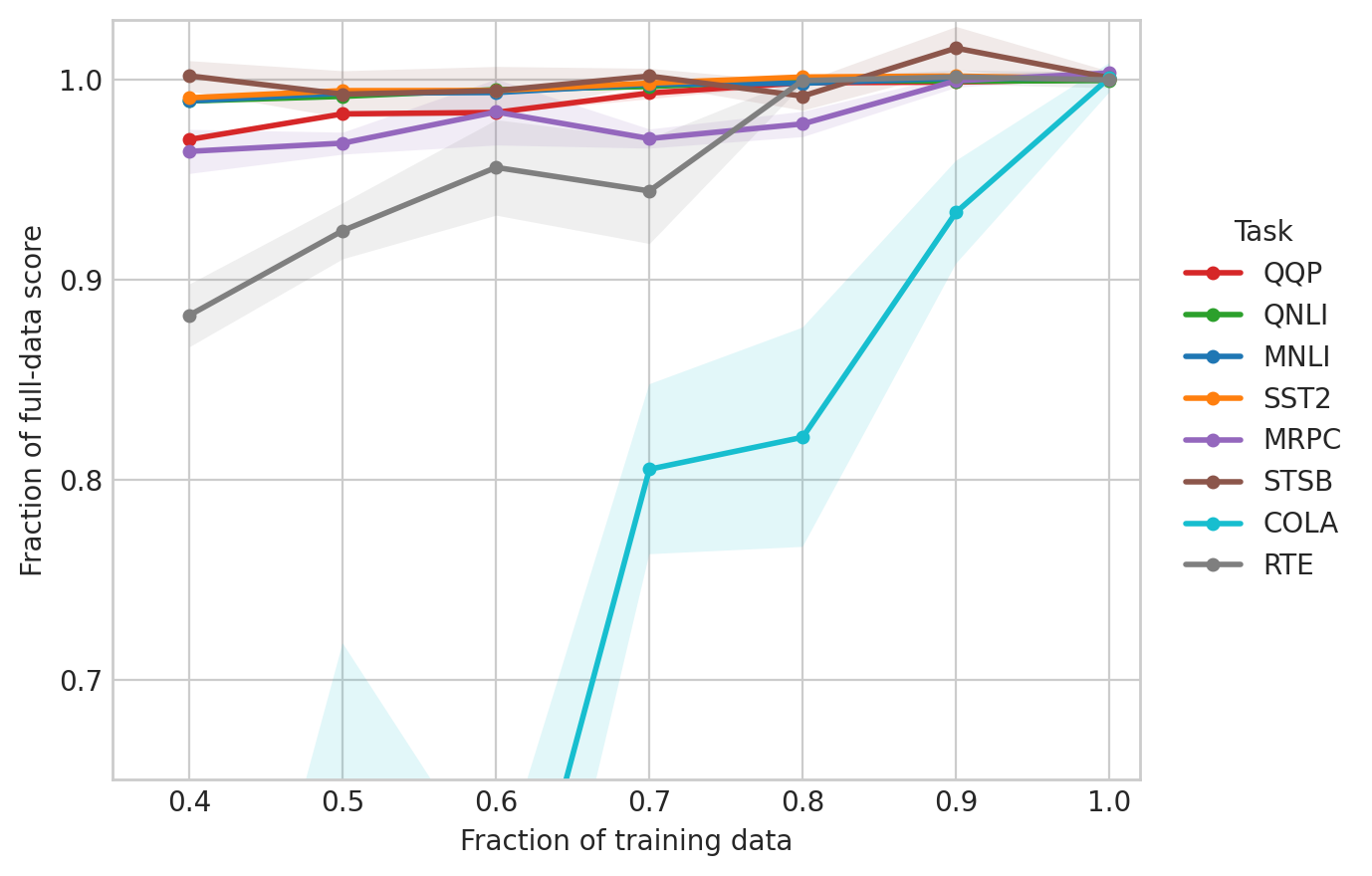
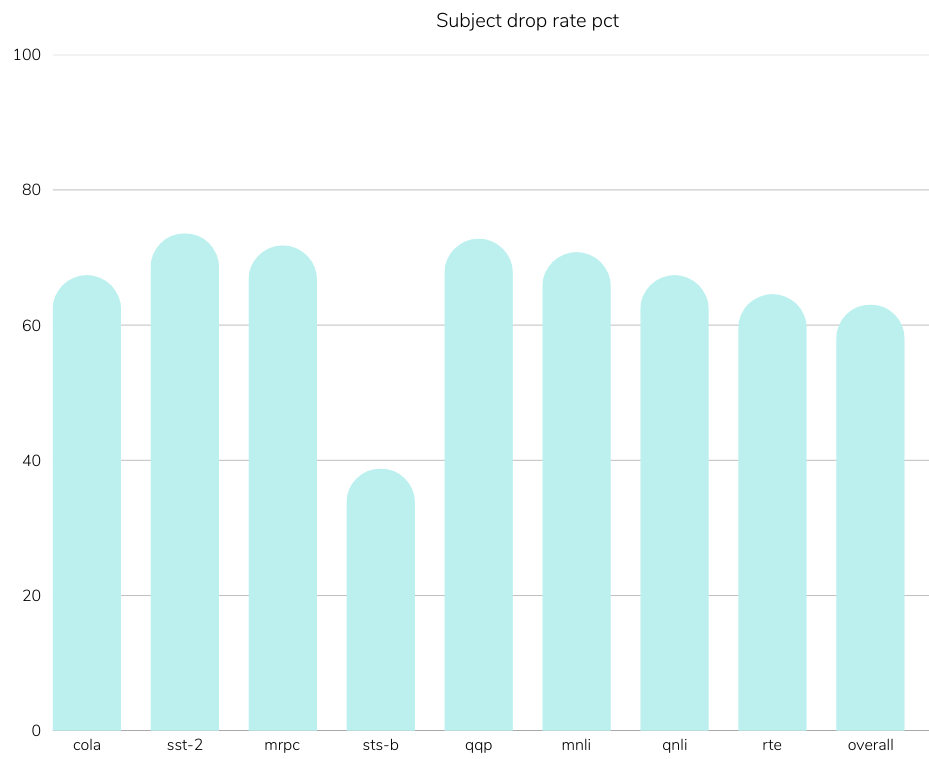
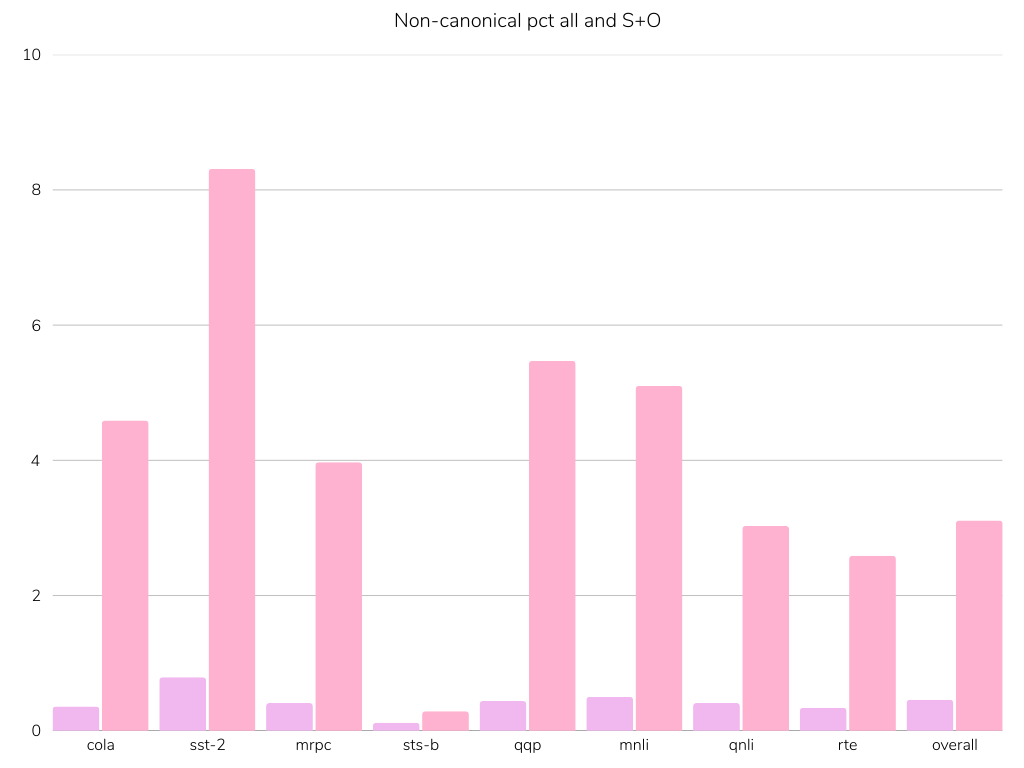
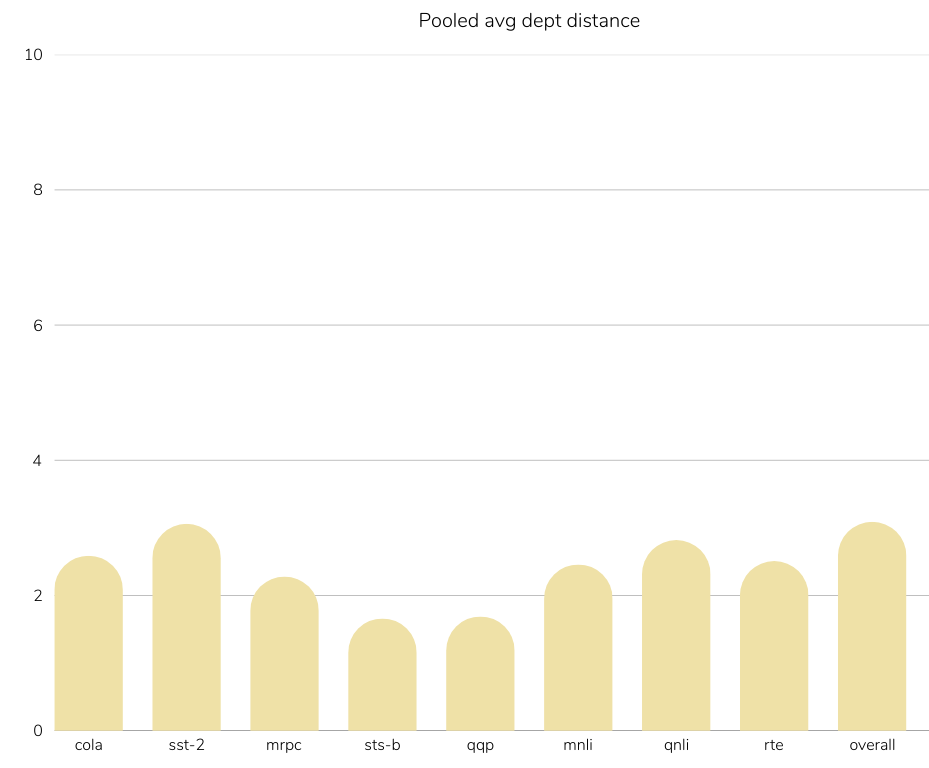
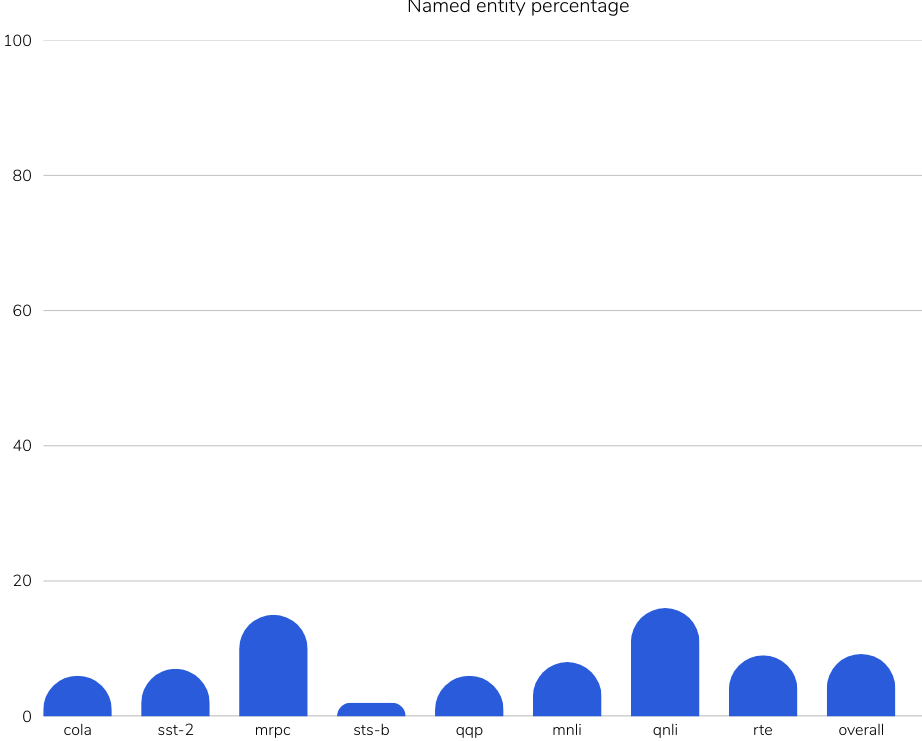







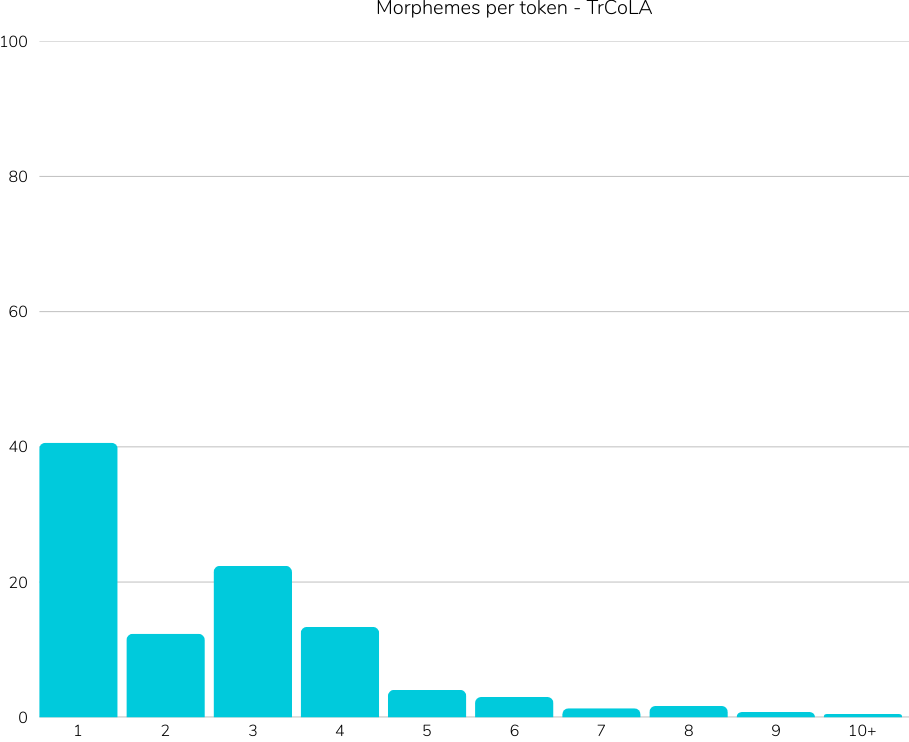
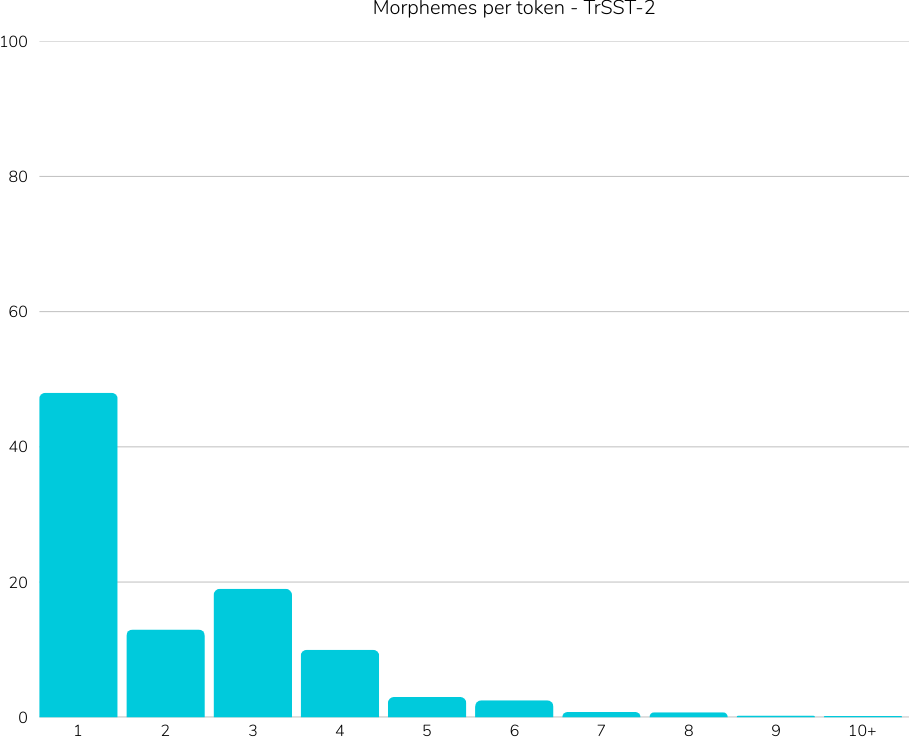
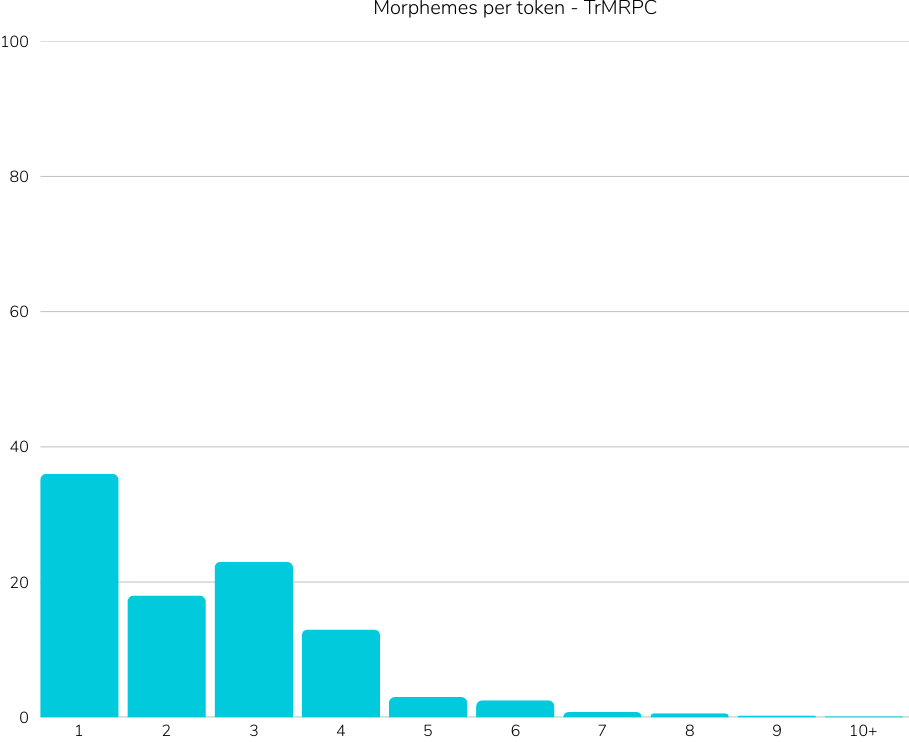
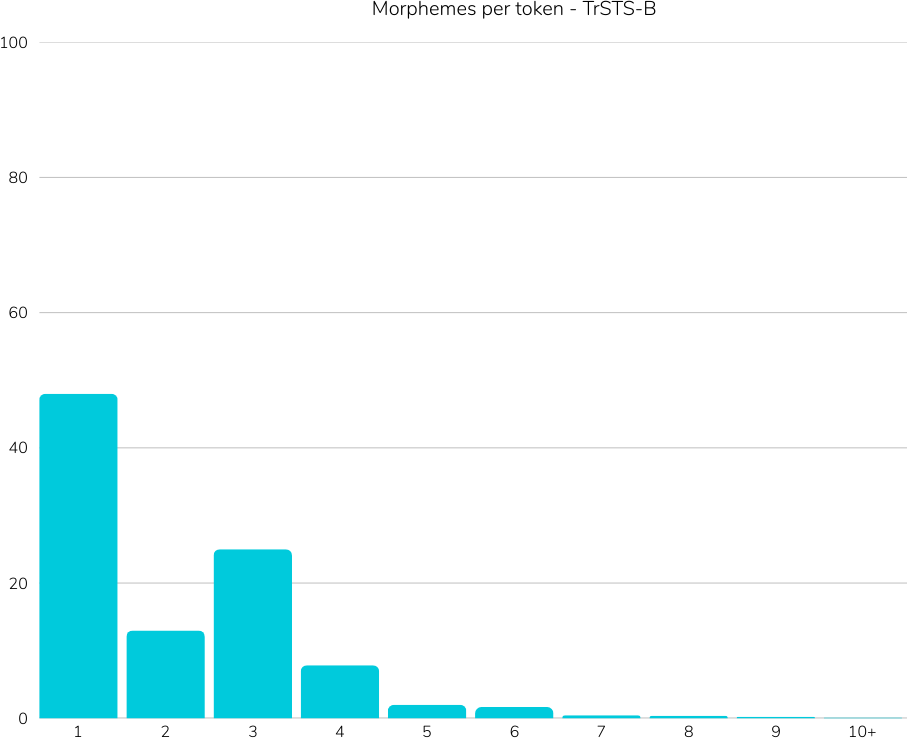
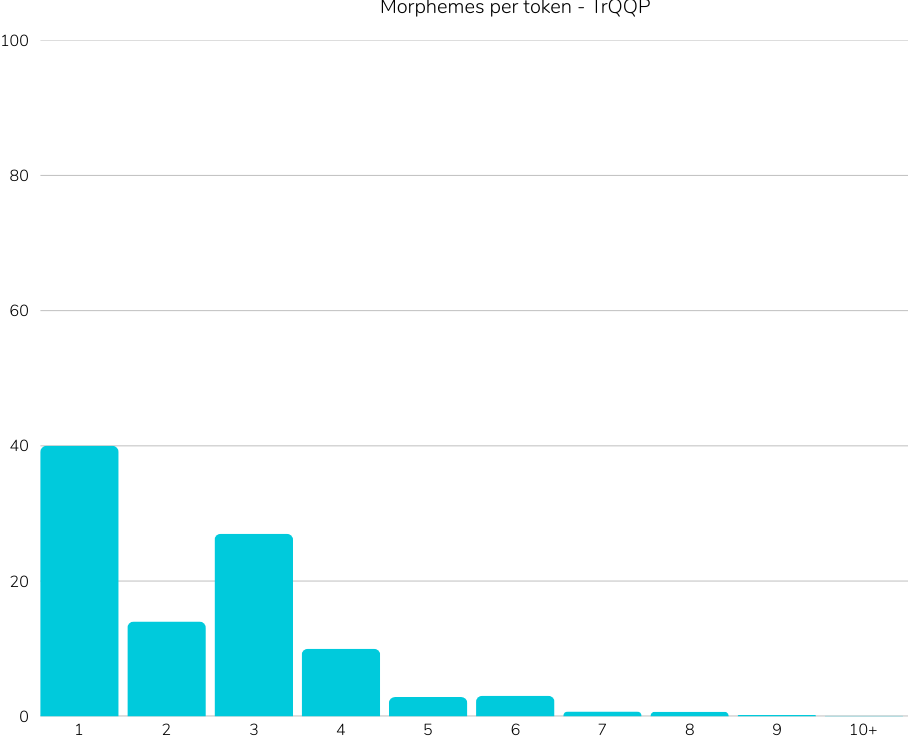
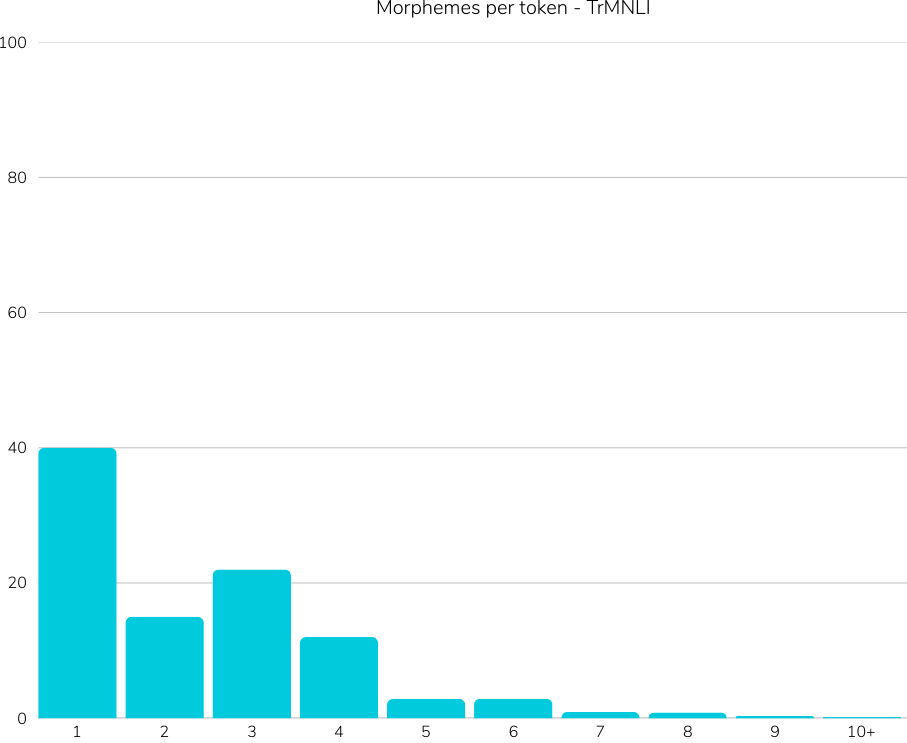
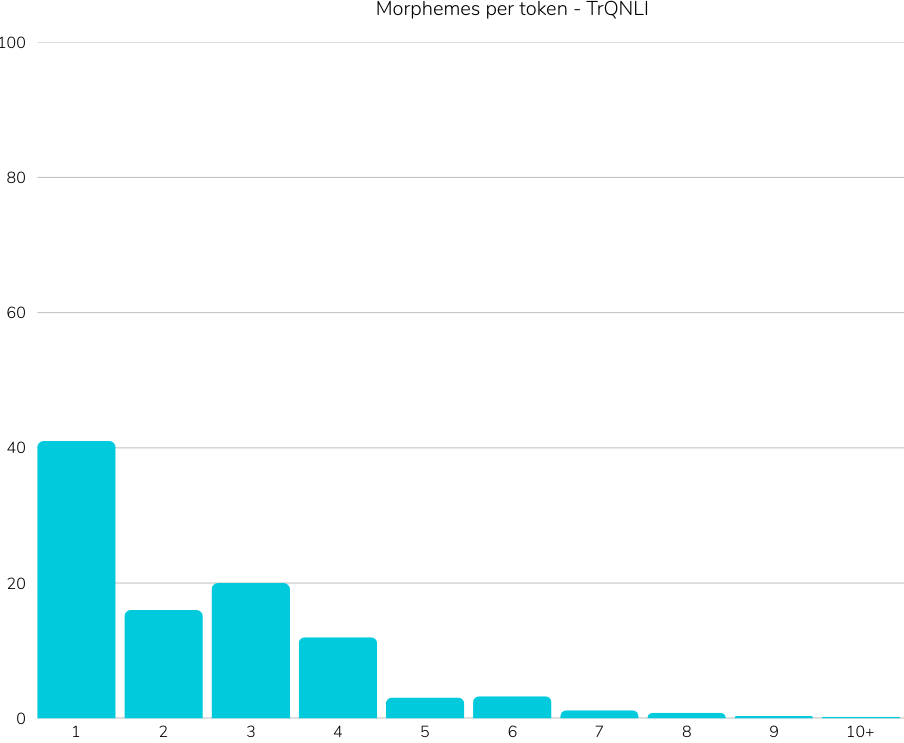
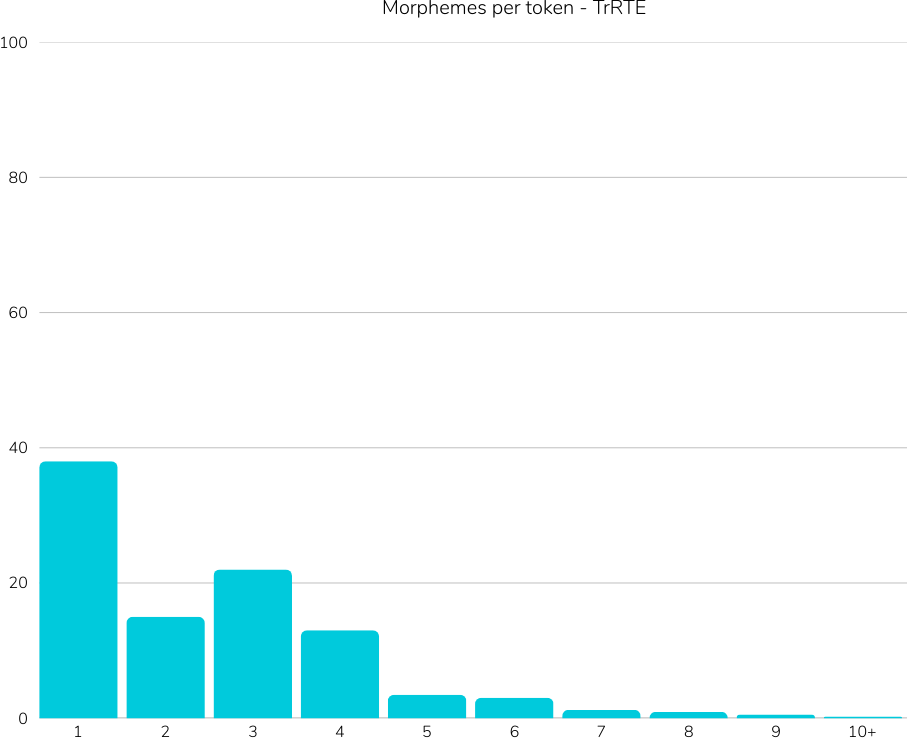
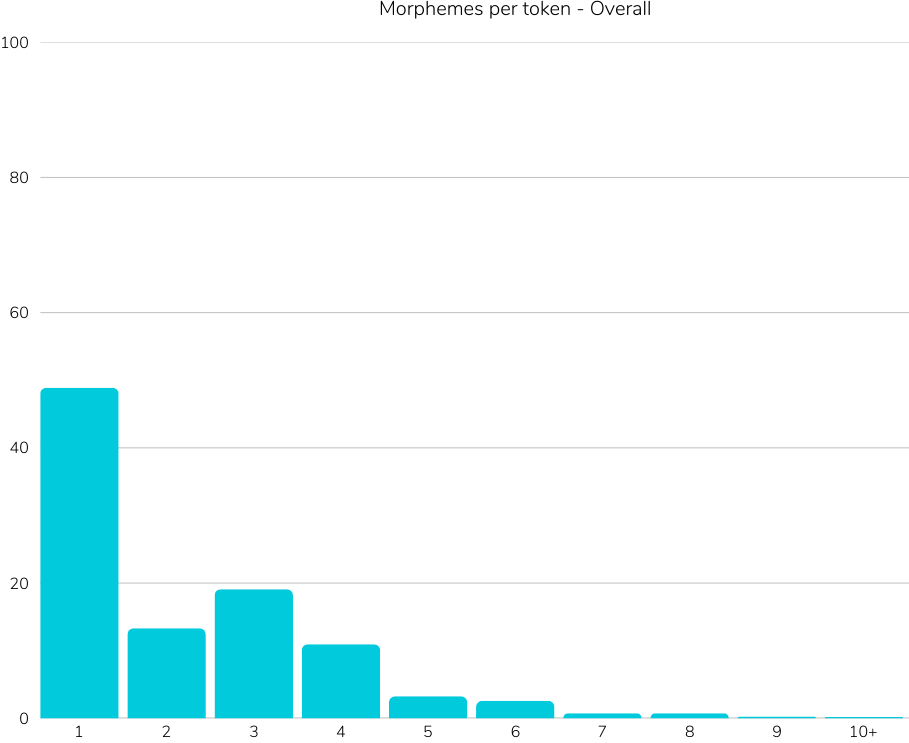
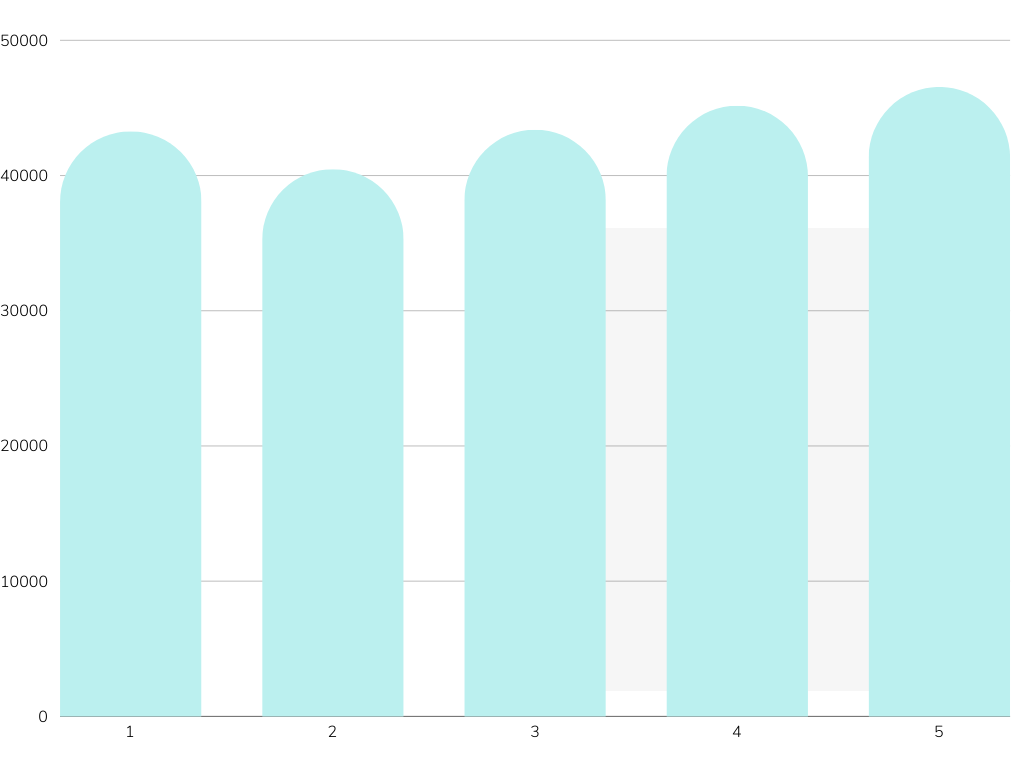
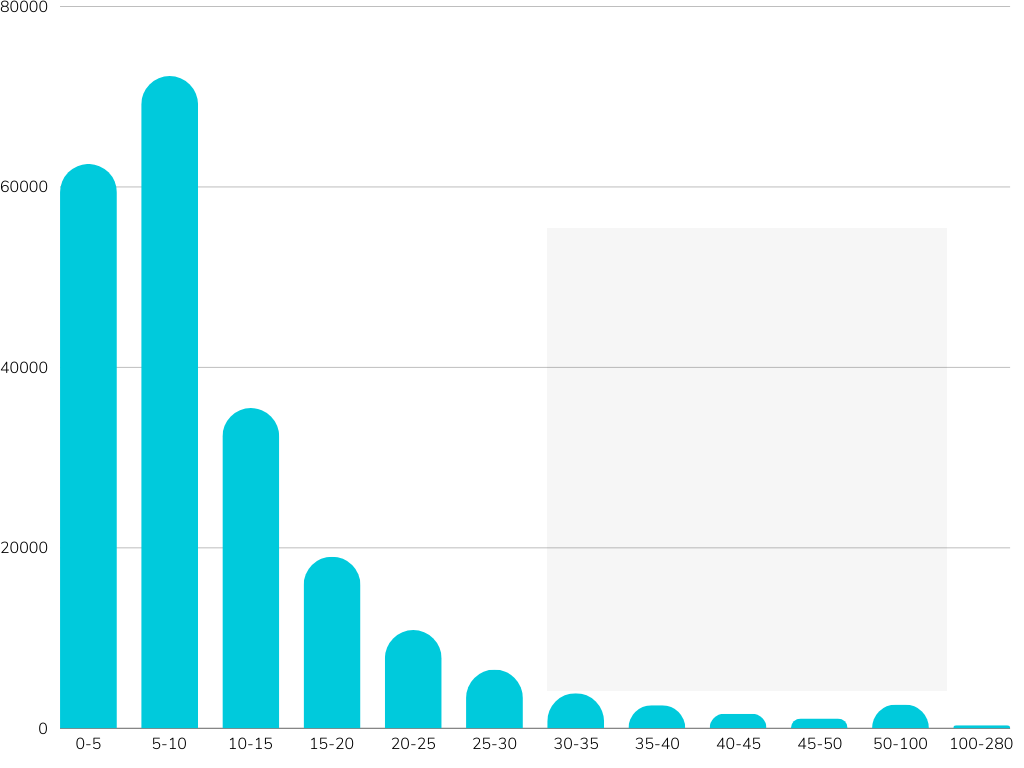
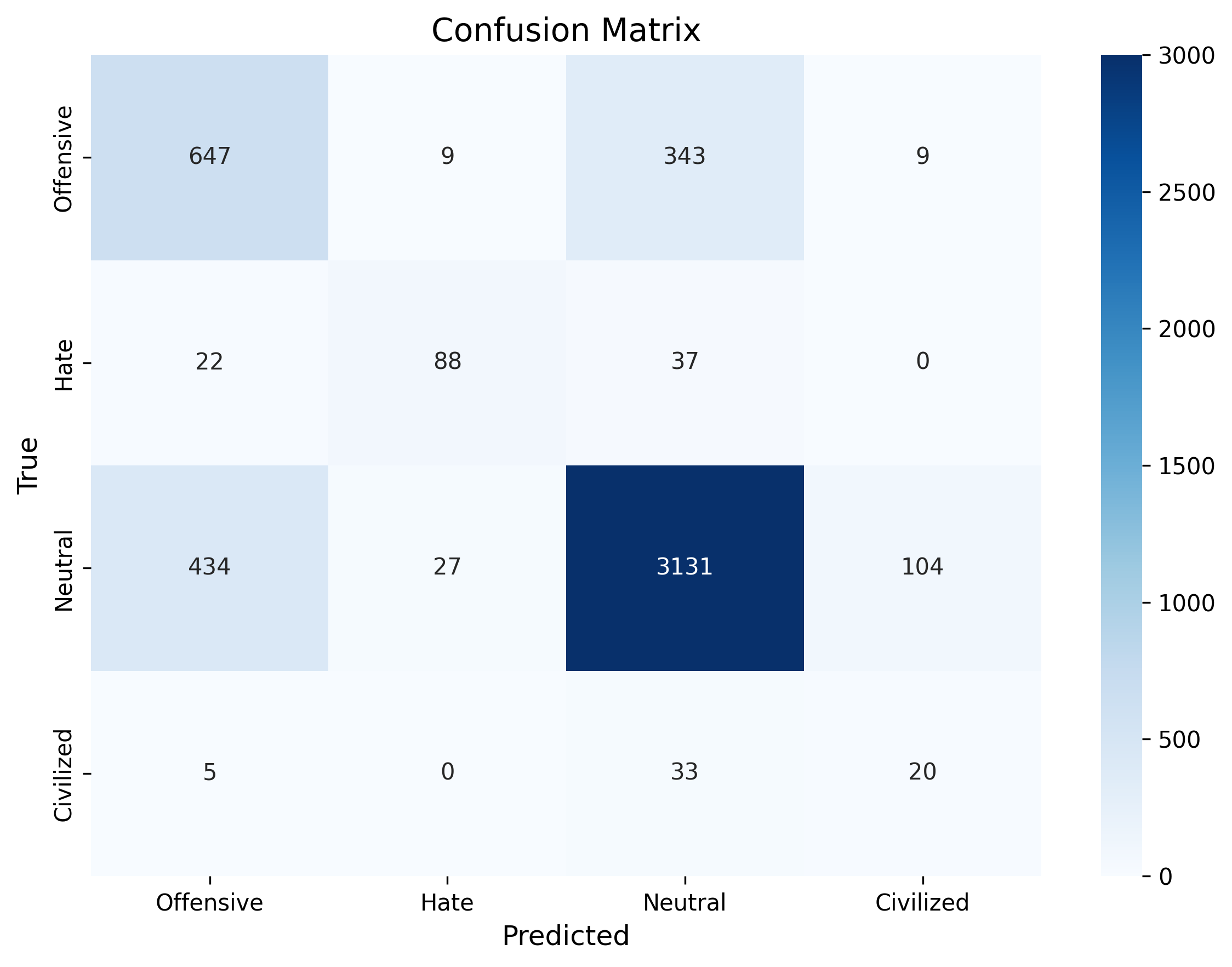
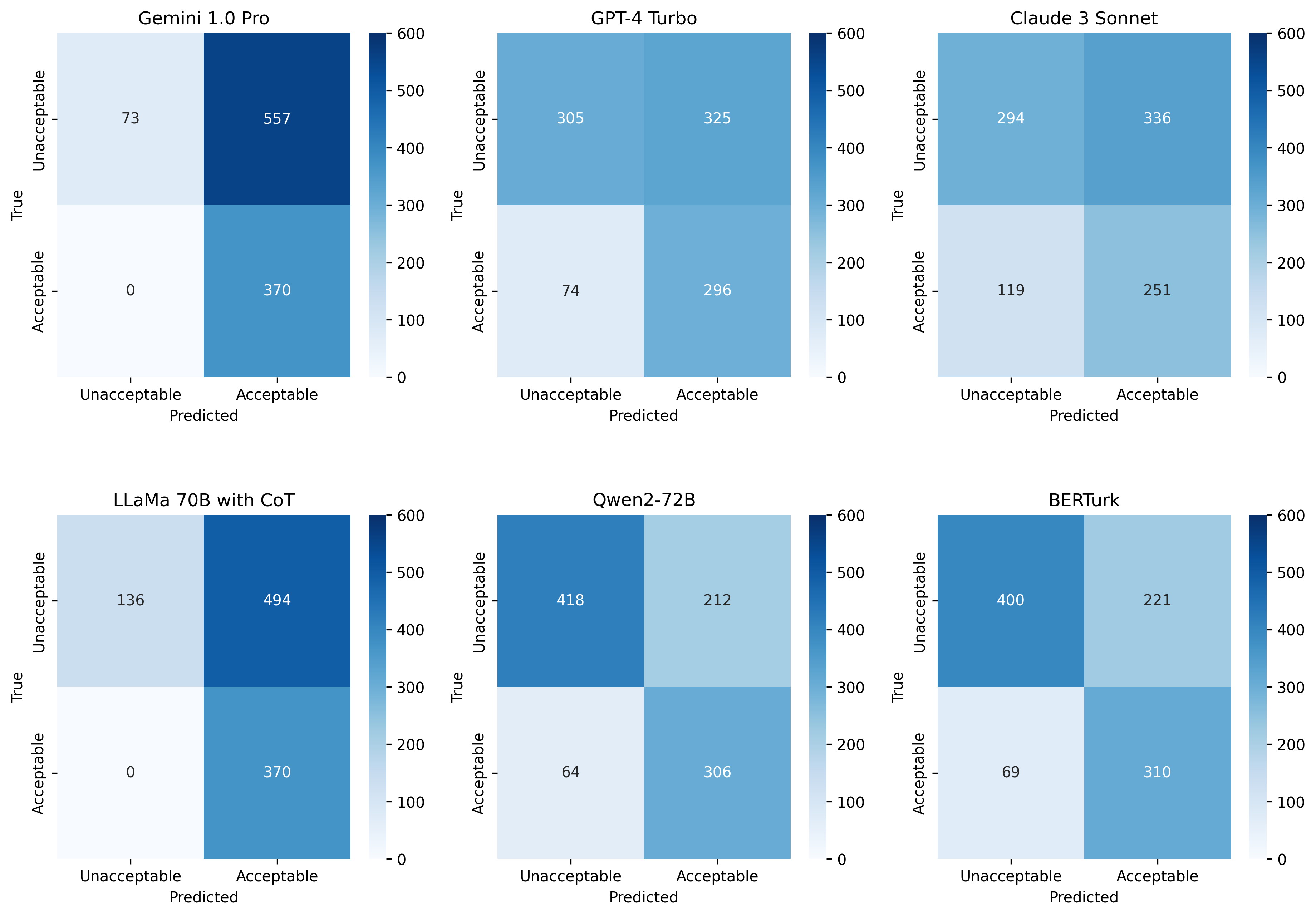
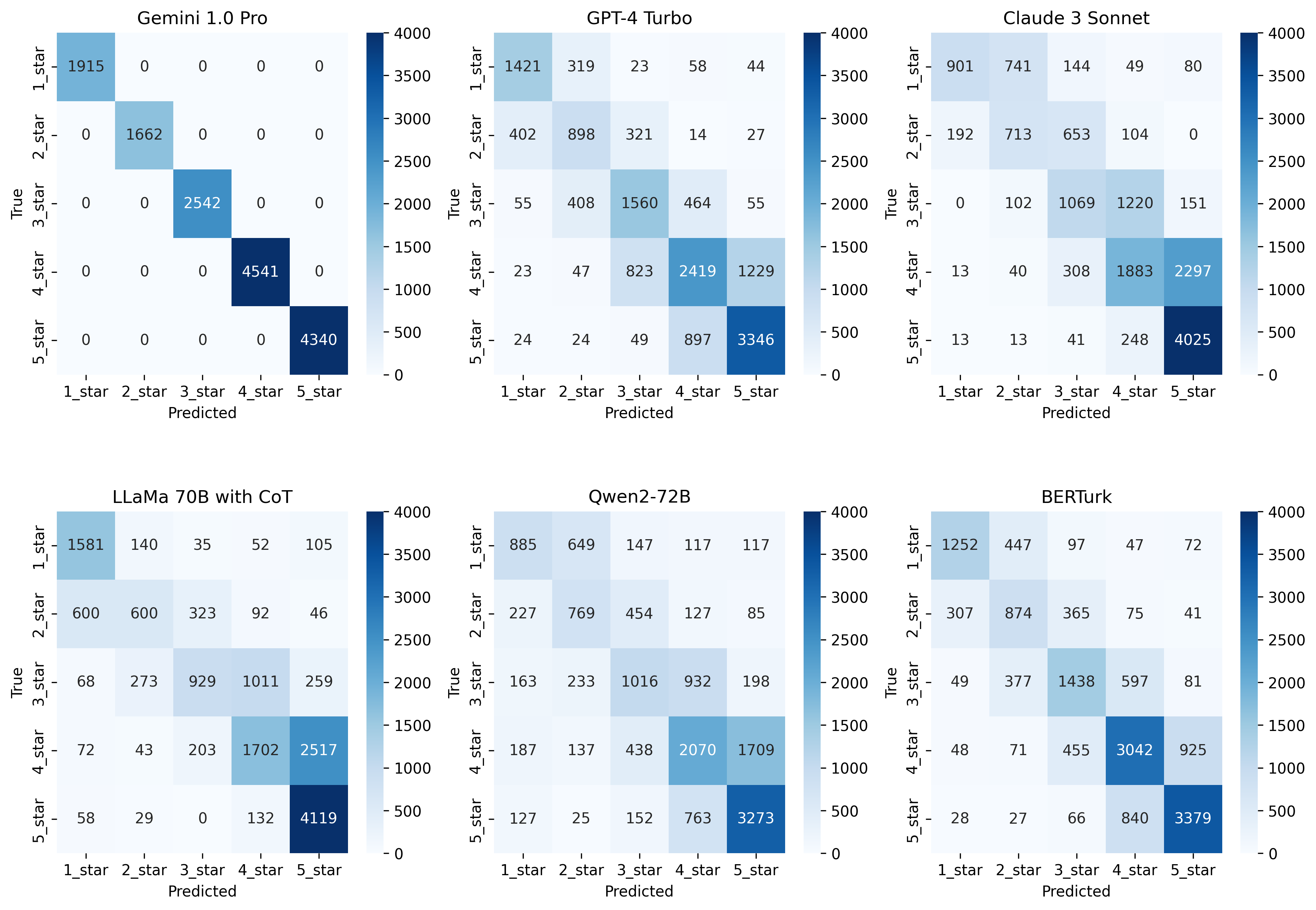
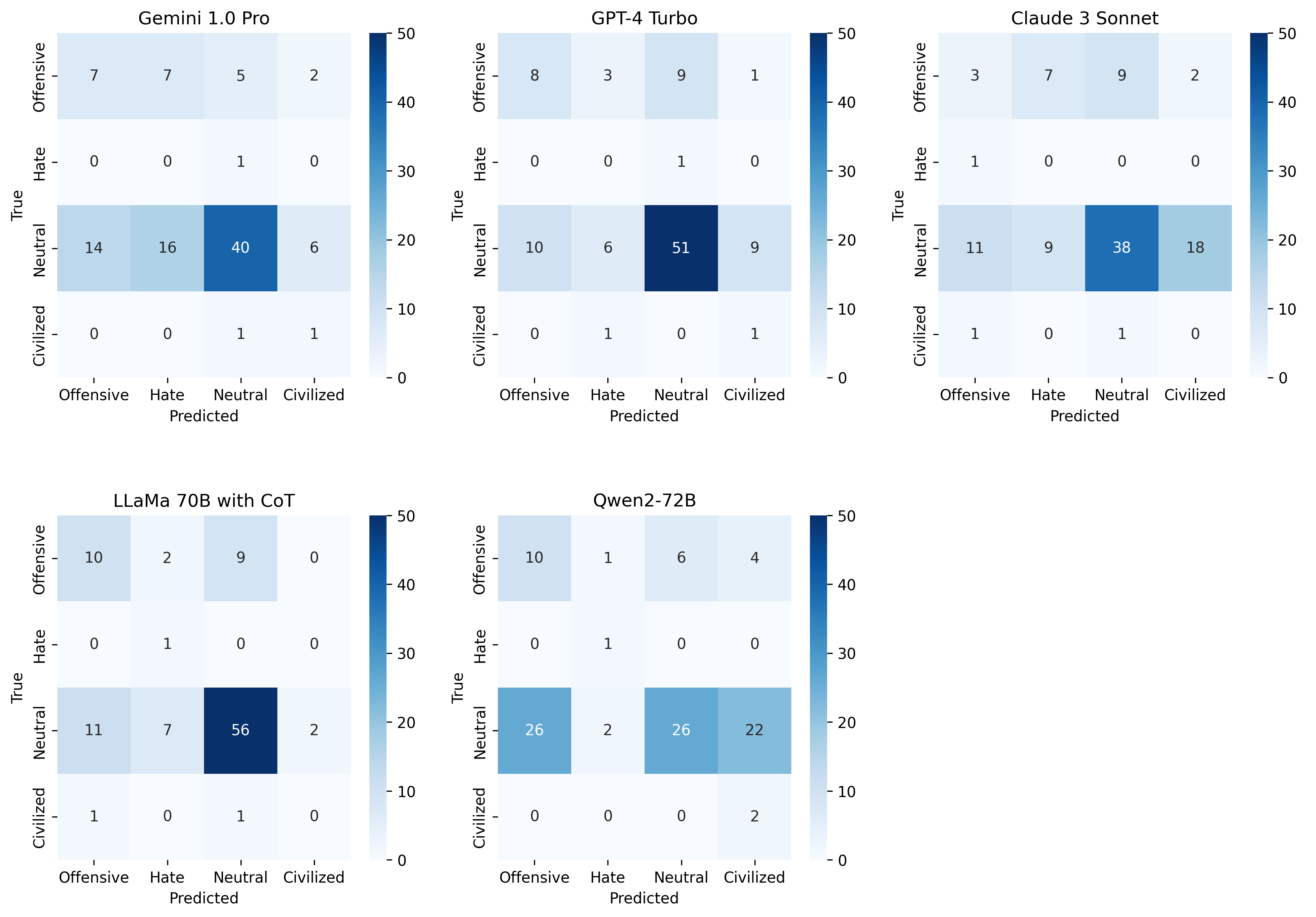
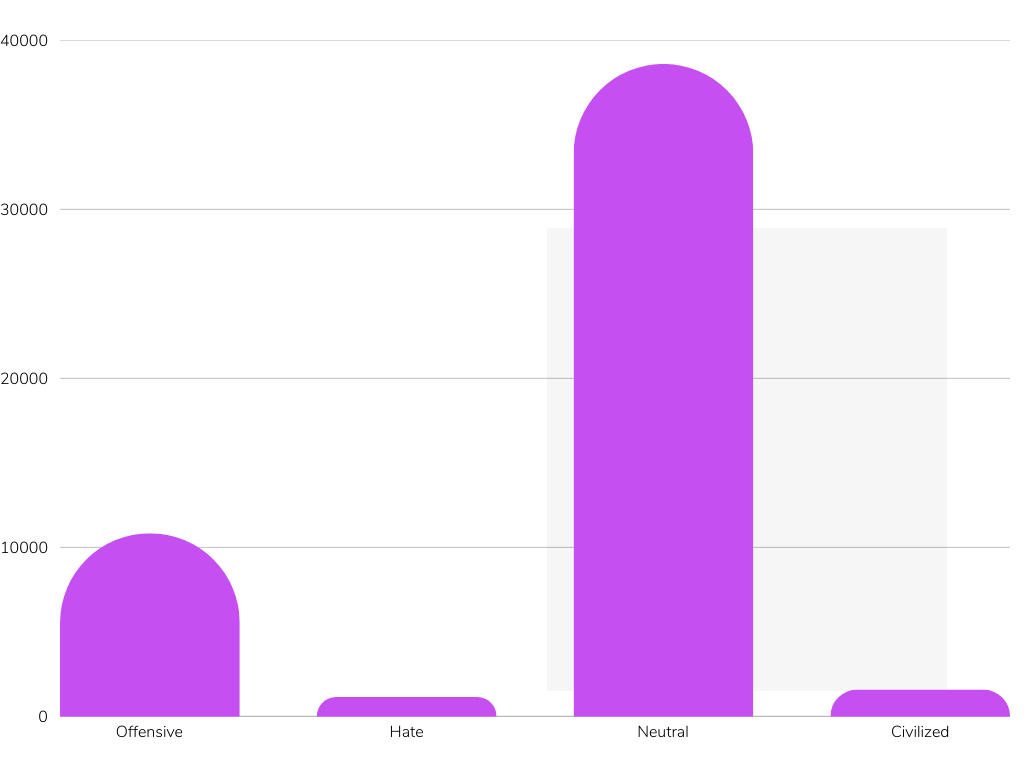
Reference
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.