AInsteinBench 대규모 과학 소프트웨어 개발 에이전트 평가 벤치마크
📝 원문 정보
- Title: AInsteinBench: Benchmarking Coding Agents on Scientific Repositories
- ArXiv ID: 2512.21373
- 발행일: 2025-12-24
- 저자: Titouan Duston, Shuo Xin, Yang Sun, Daoguang Zan, Aoyan Li, Shulin Xin, Kai Shen, Yixiao Chen, Qiming Sun, Ge Zhang, Jiashuo Liu, Huan Zhou, Jingkai Liu, Zhichen Pu, Yuanheng Wang, Bo-Xuan Ge, Xin Tong, Fei Ye, Zhi-Chao Zhao, Wen-Biao Han, Zhoujian Cao, Yueran Zhao, Weiluo Ren, Qingshen Long, Yuxiao Liu, Anni Huang, Yidi Du, Yuanyuan Rong, Jiahao Peng
📝 초록 (Abstract)
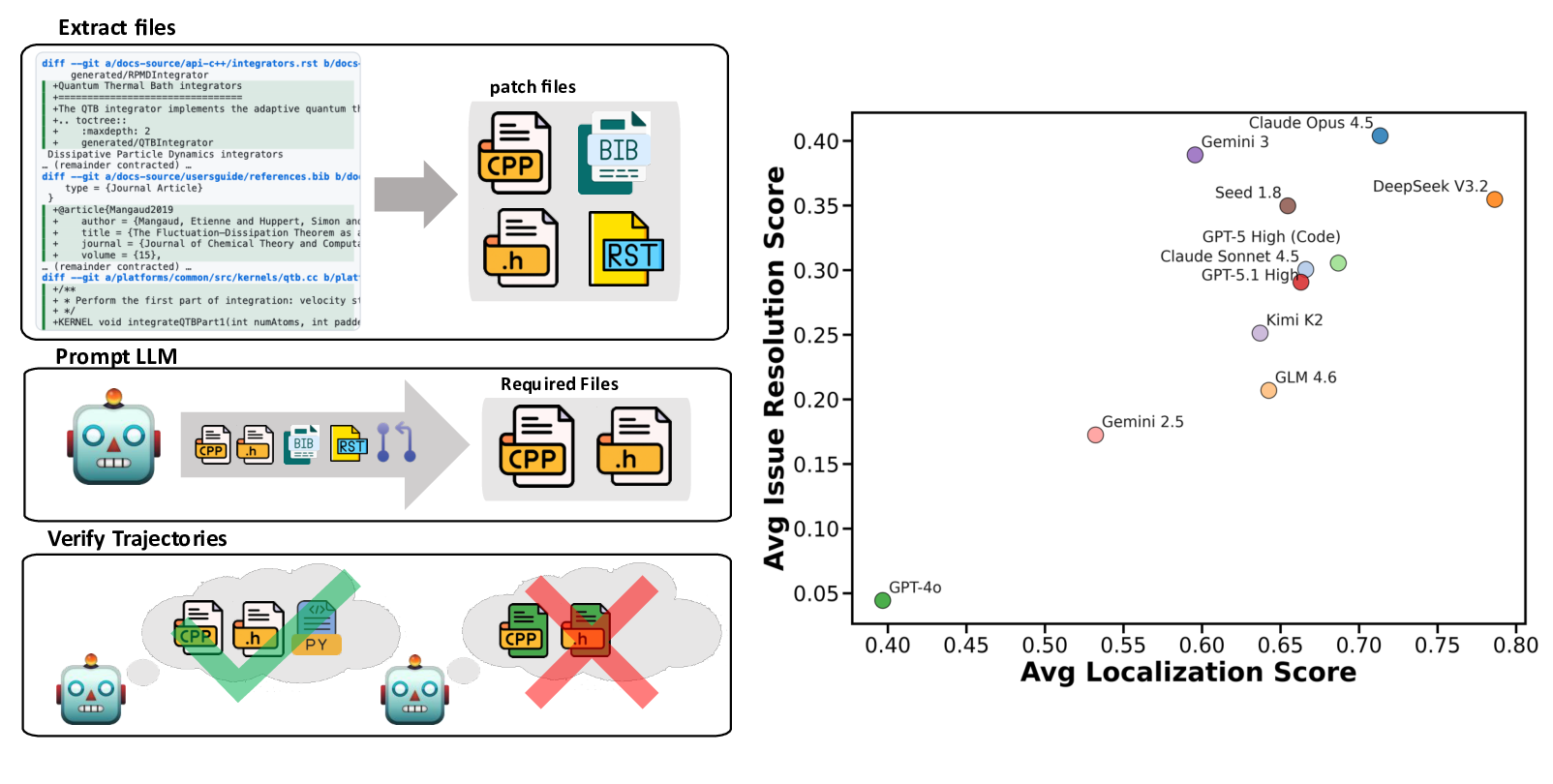
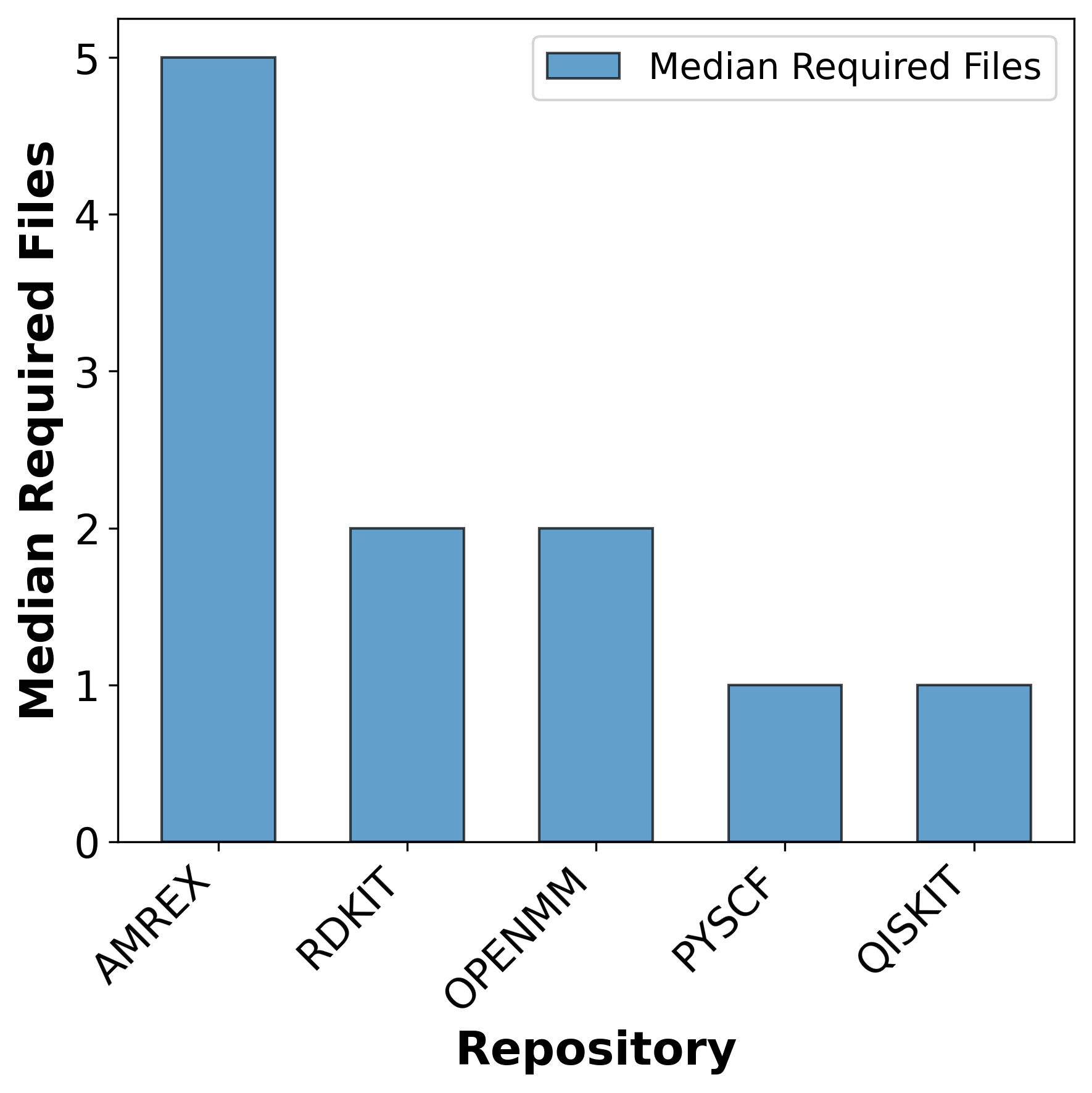
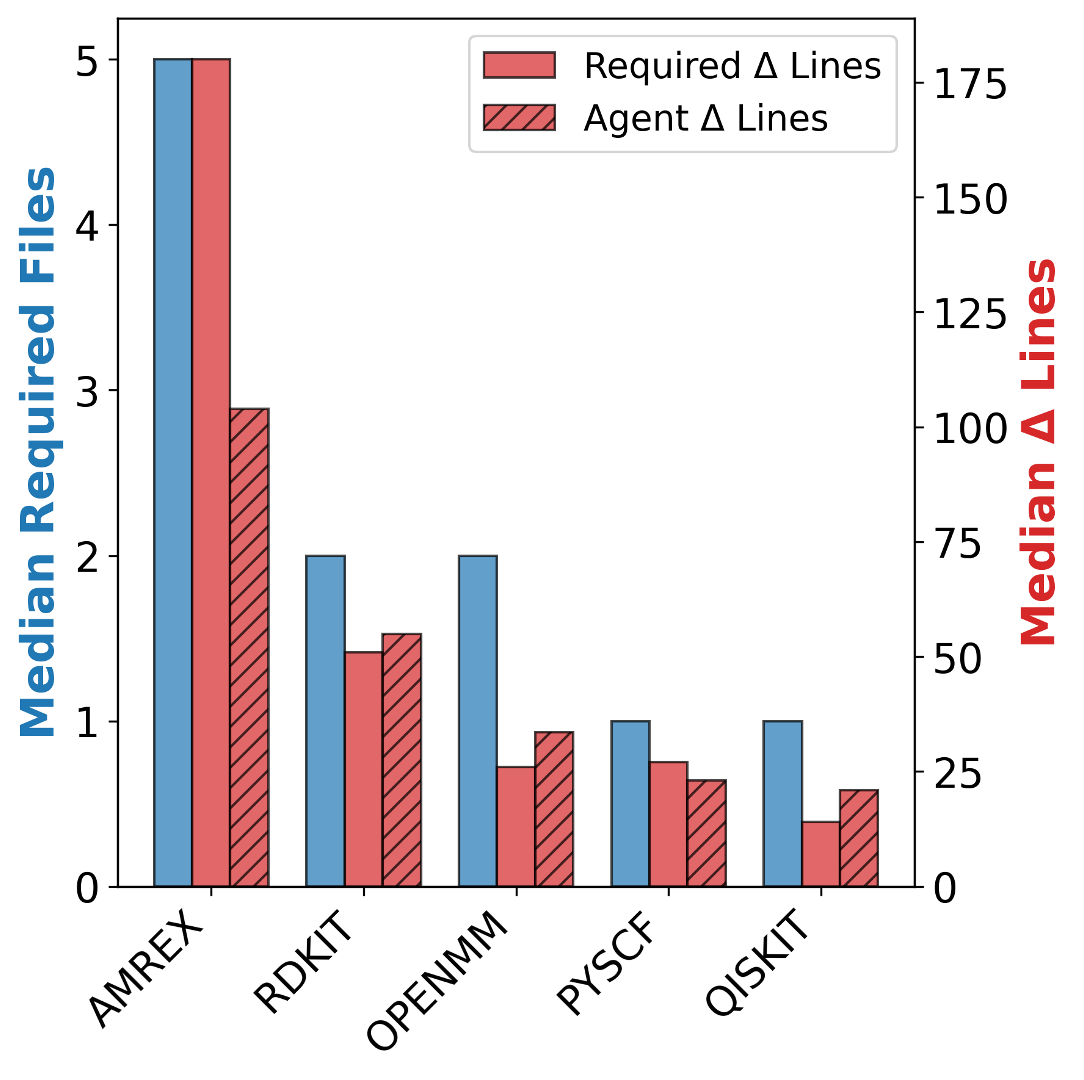
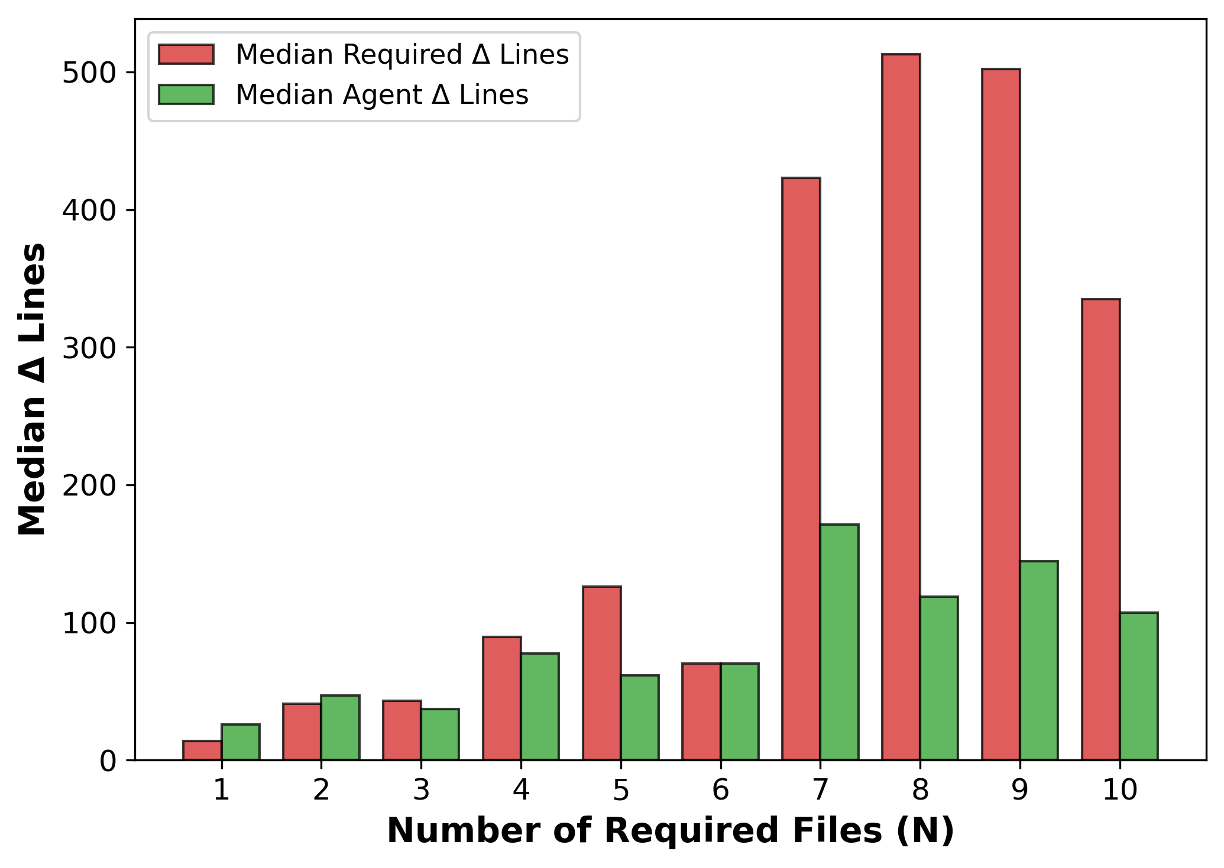
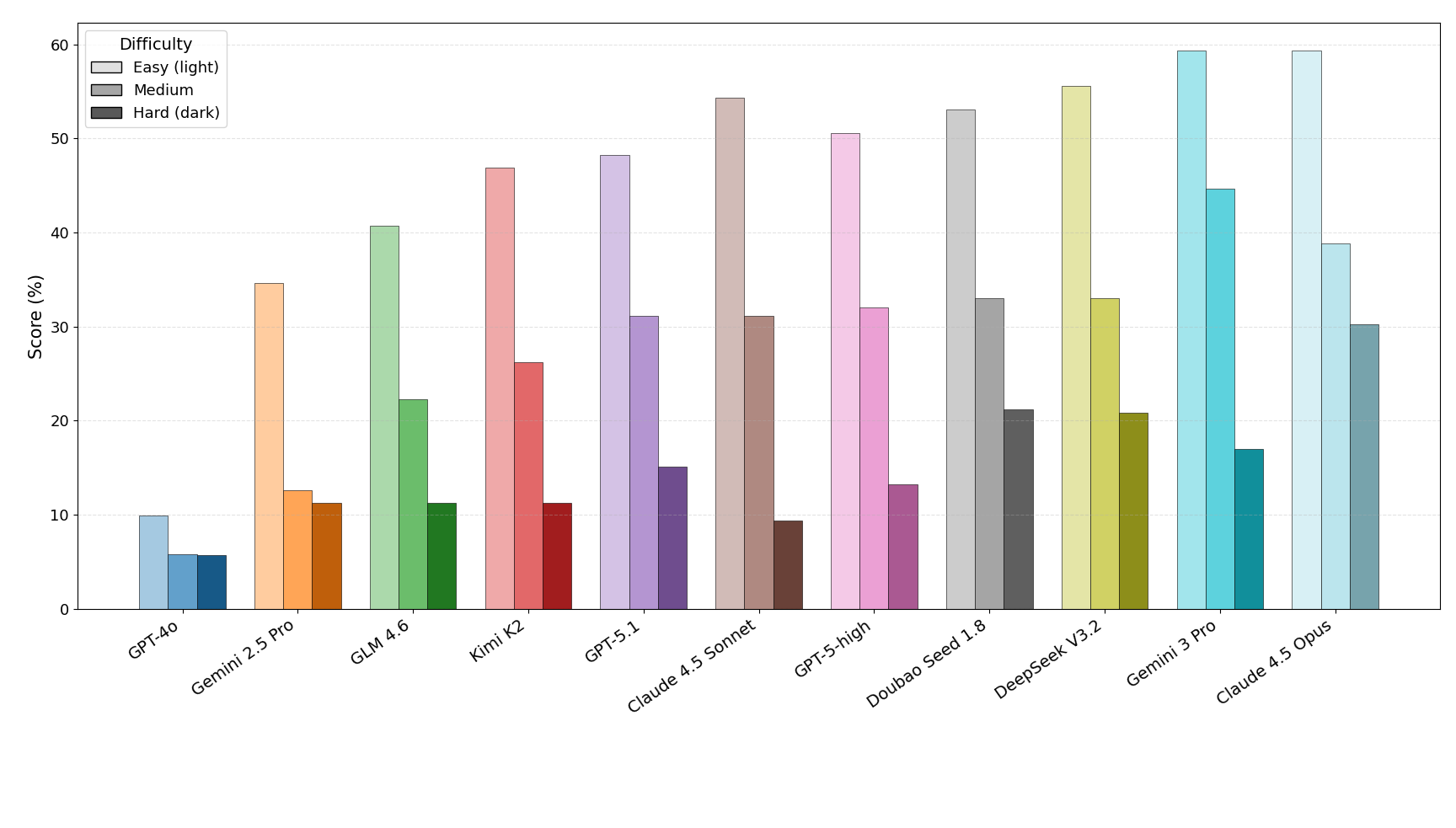
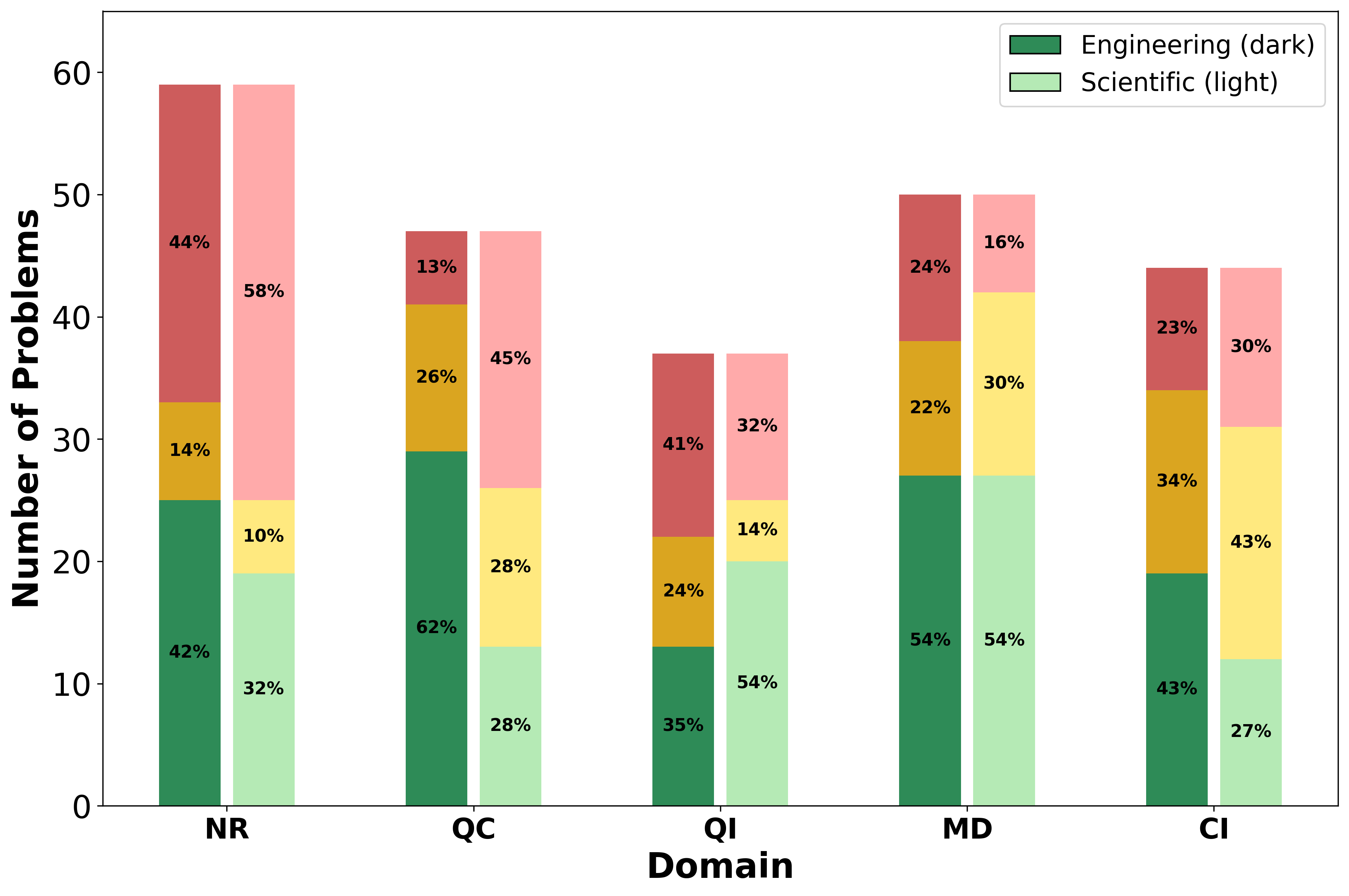
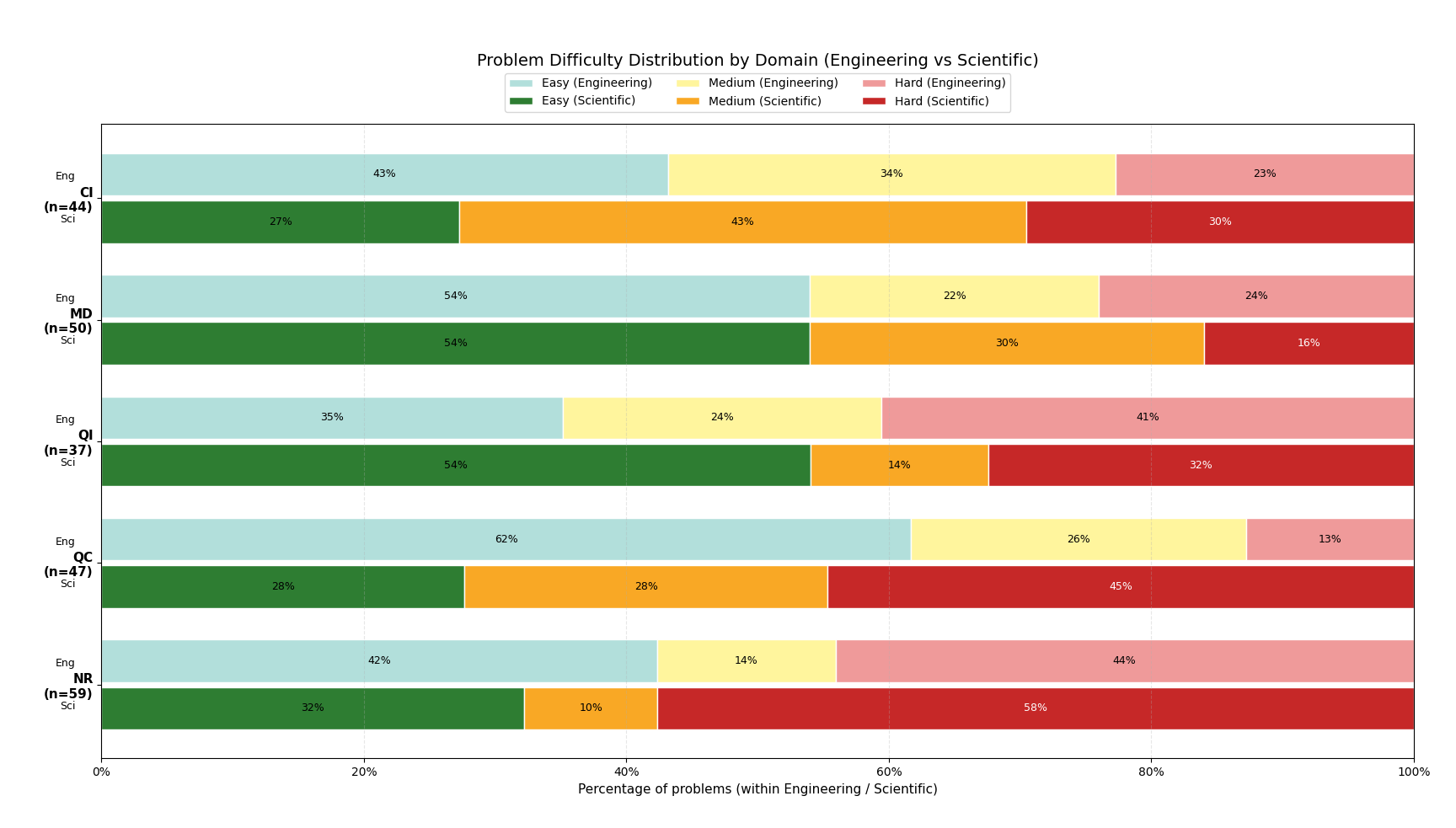
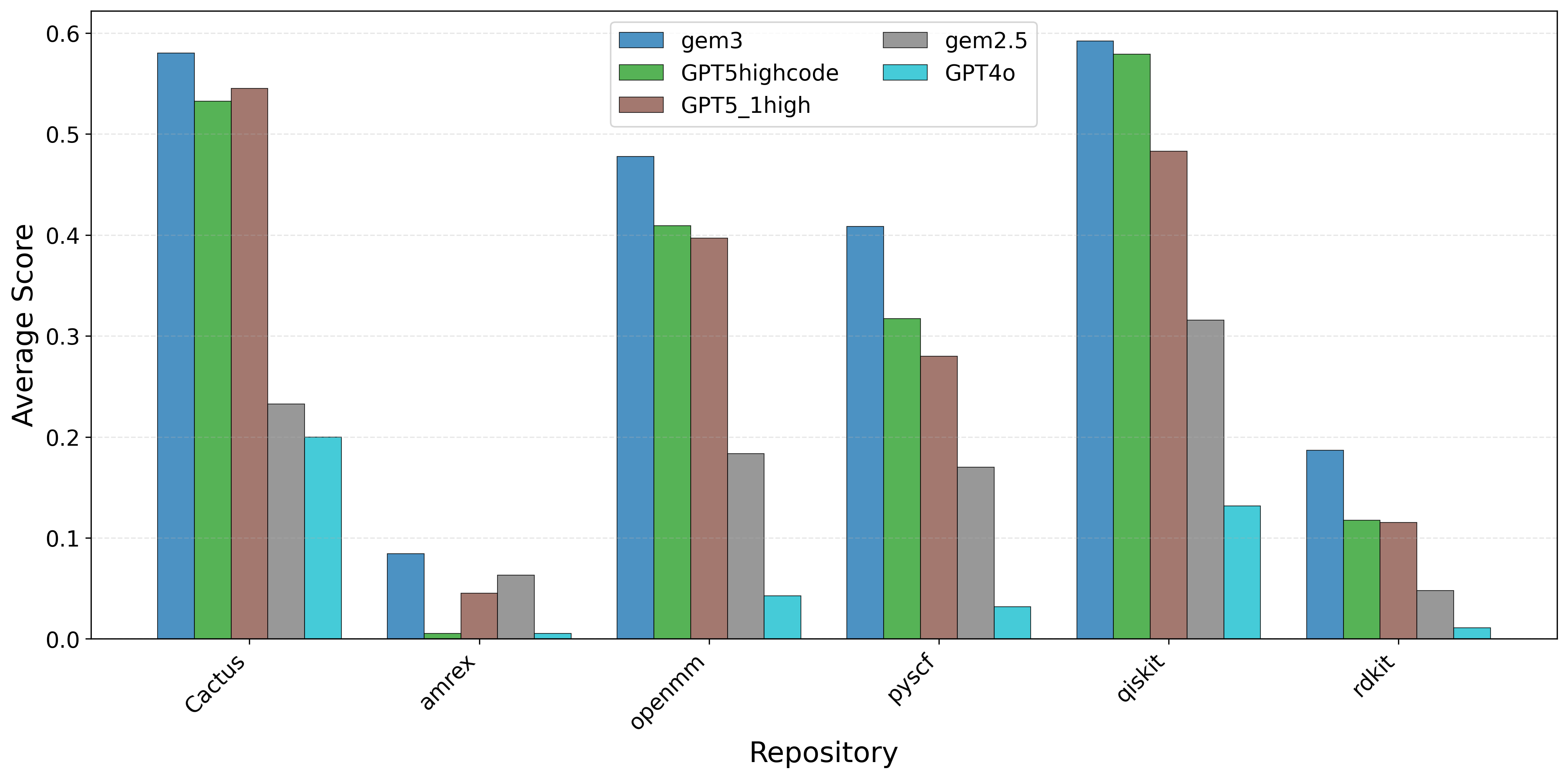
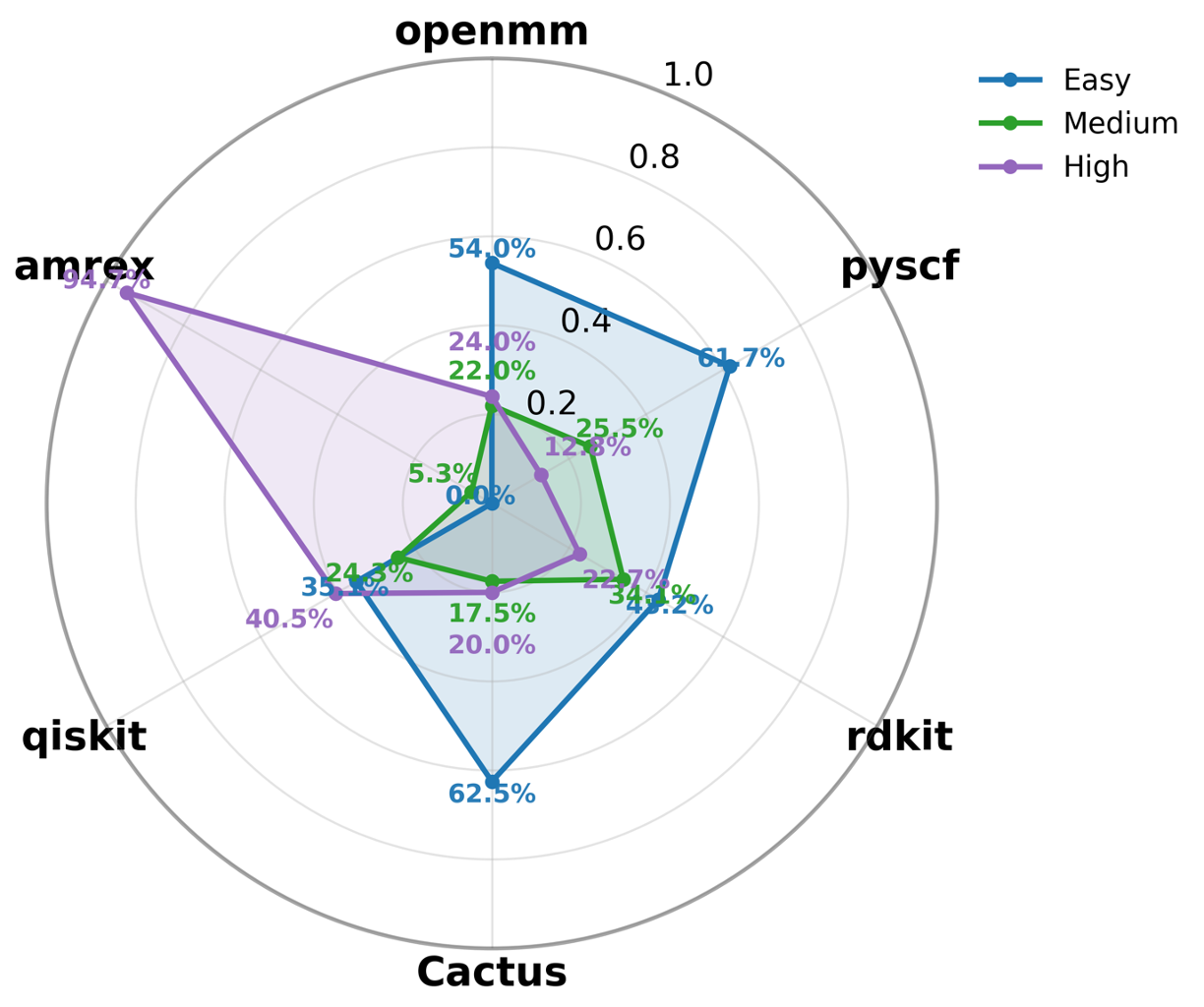
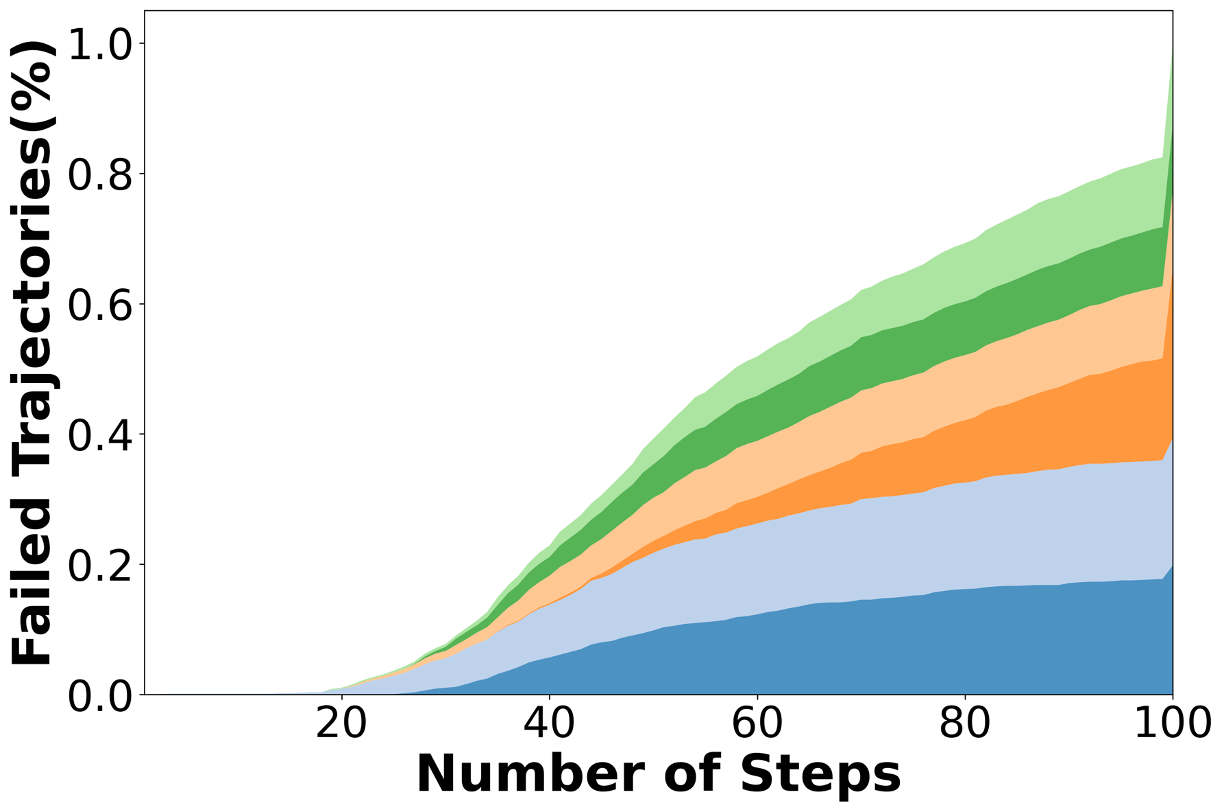
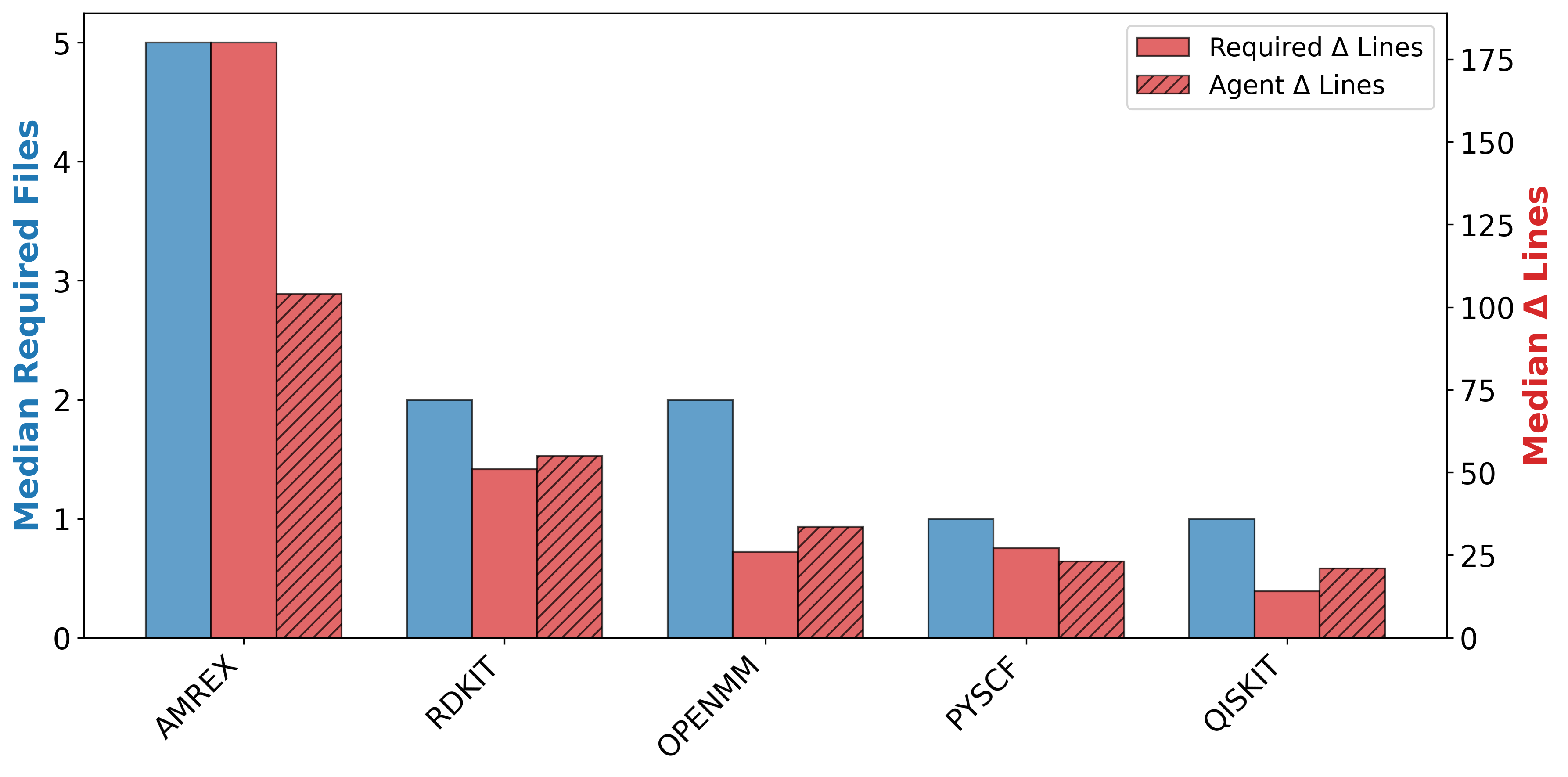
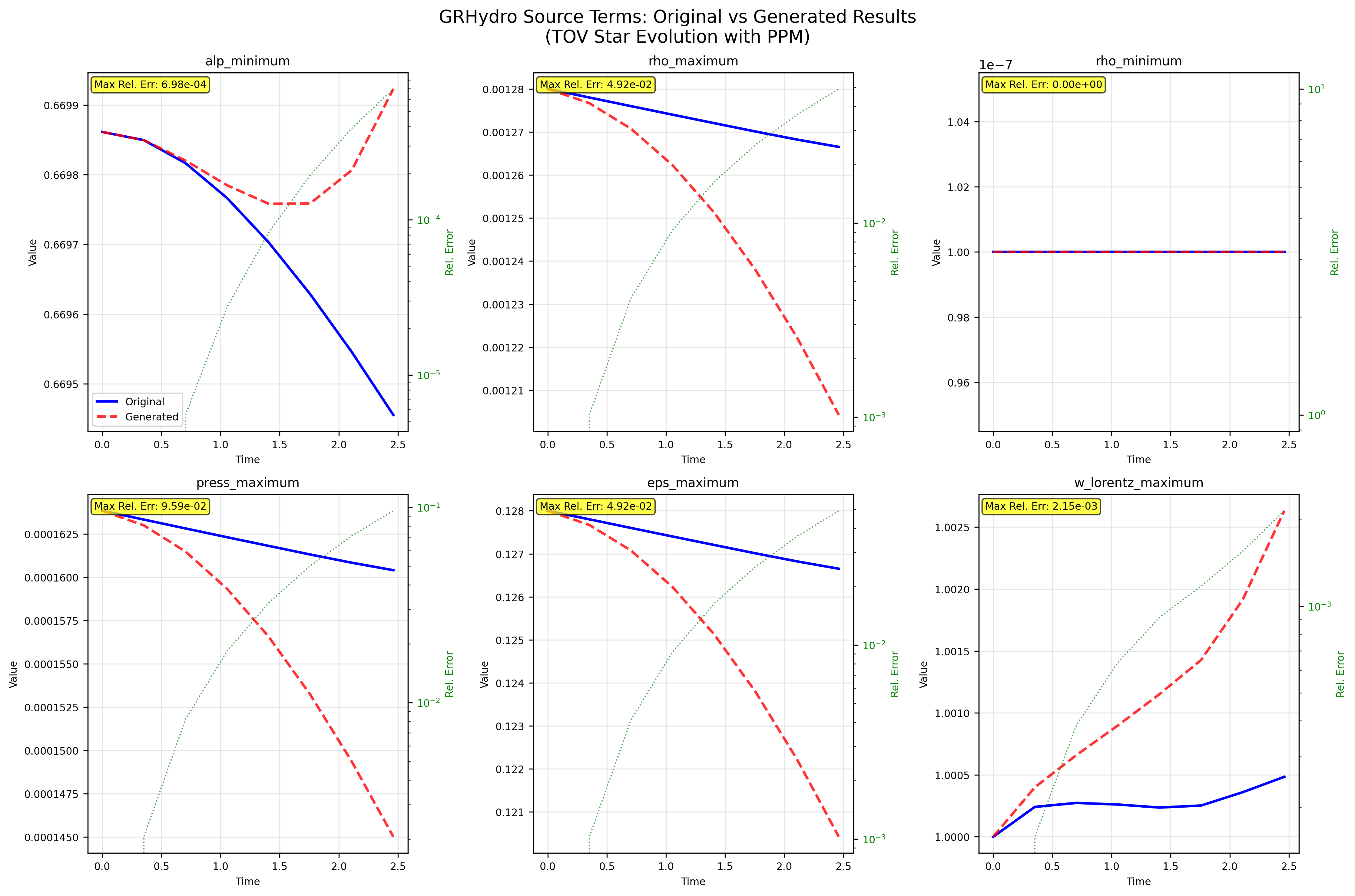
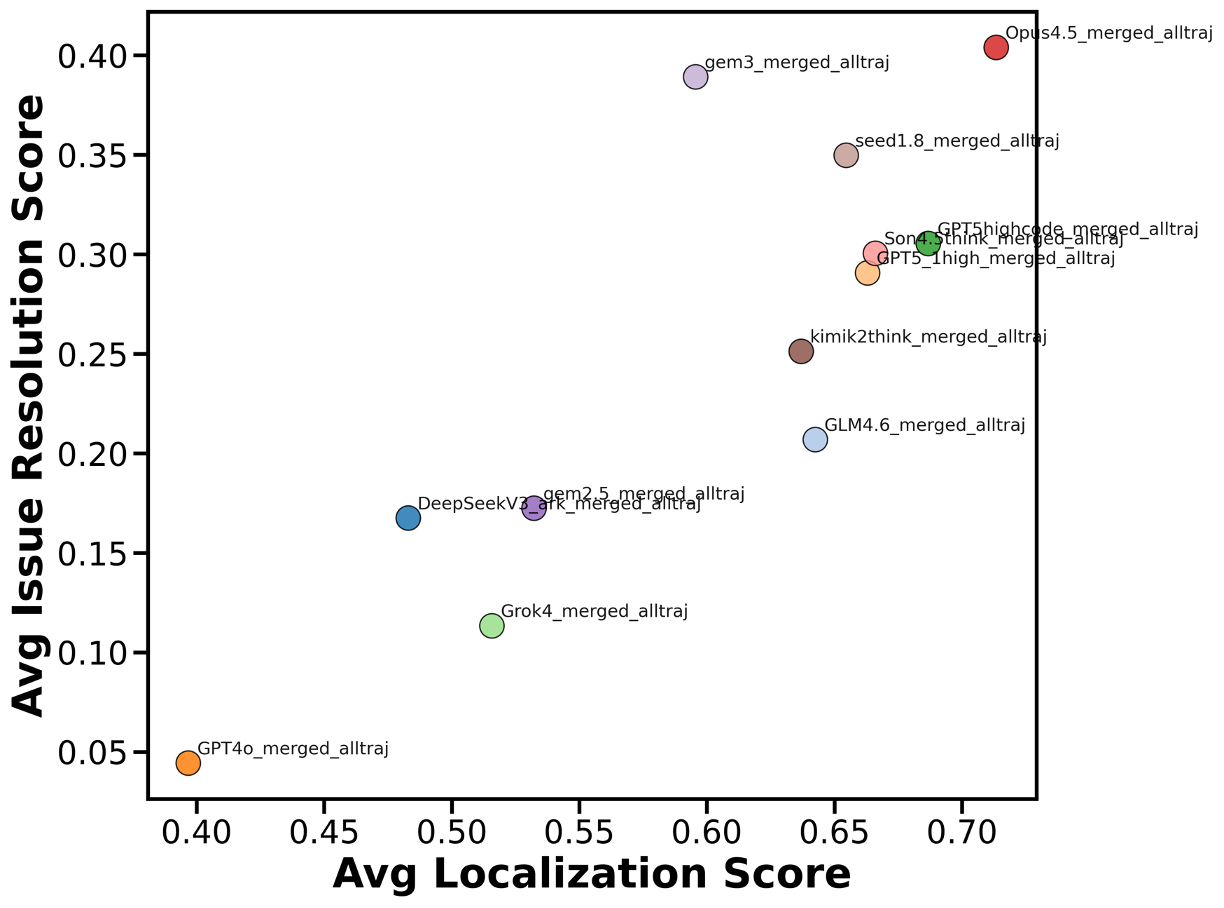
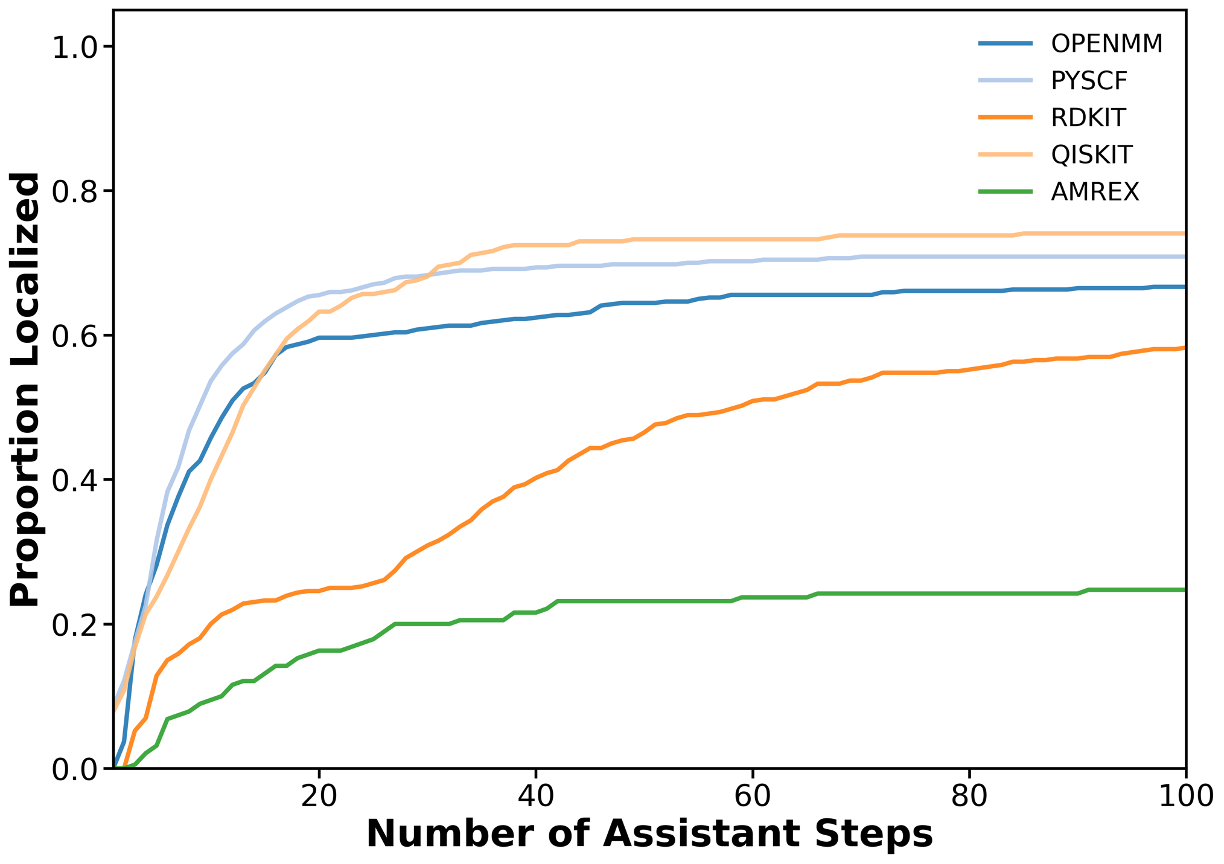
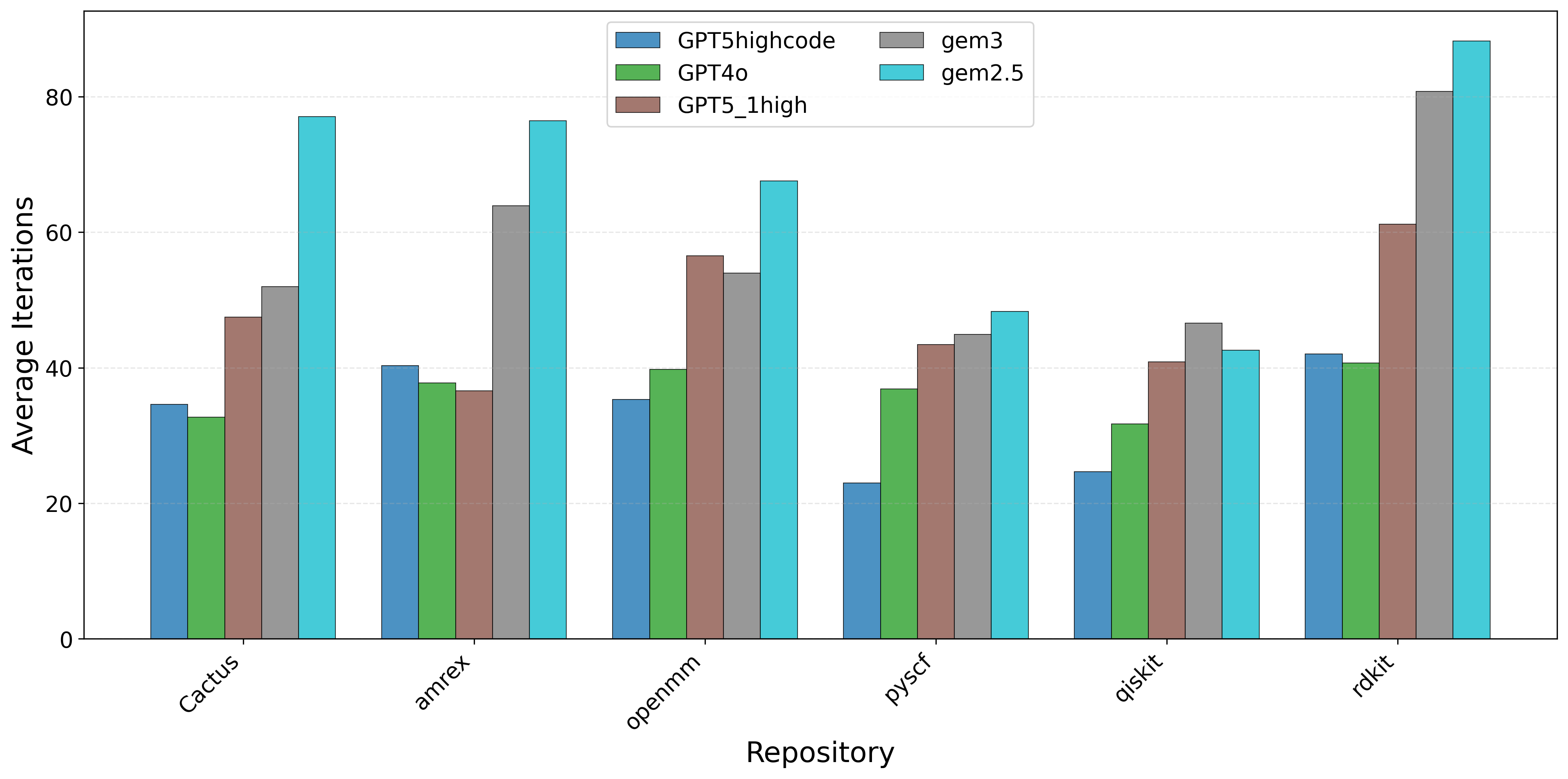
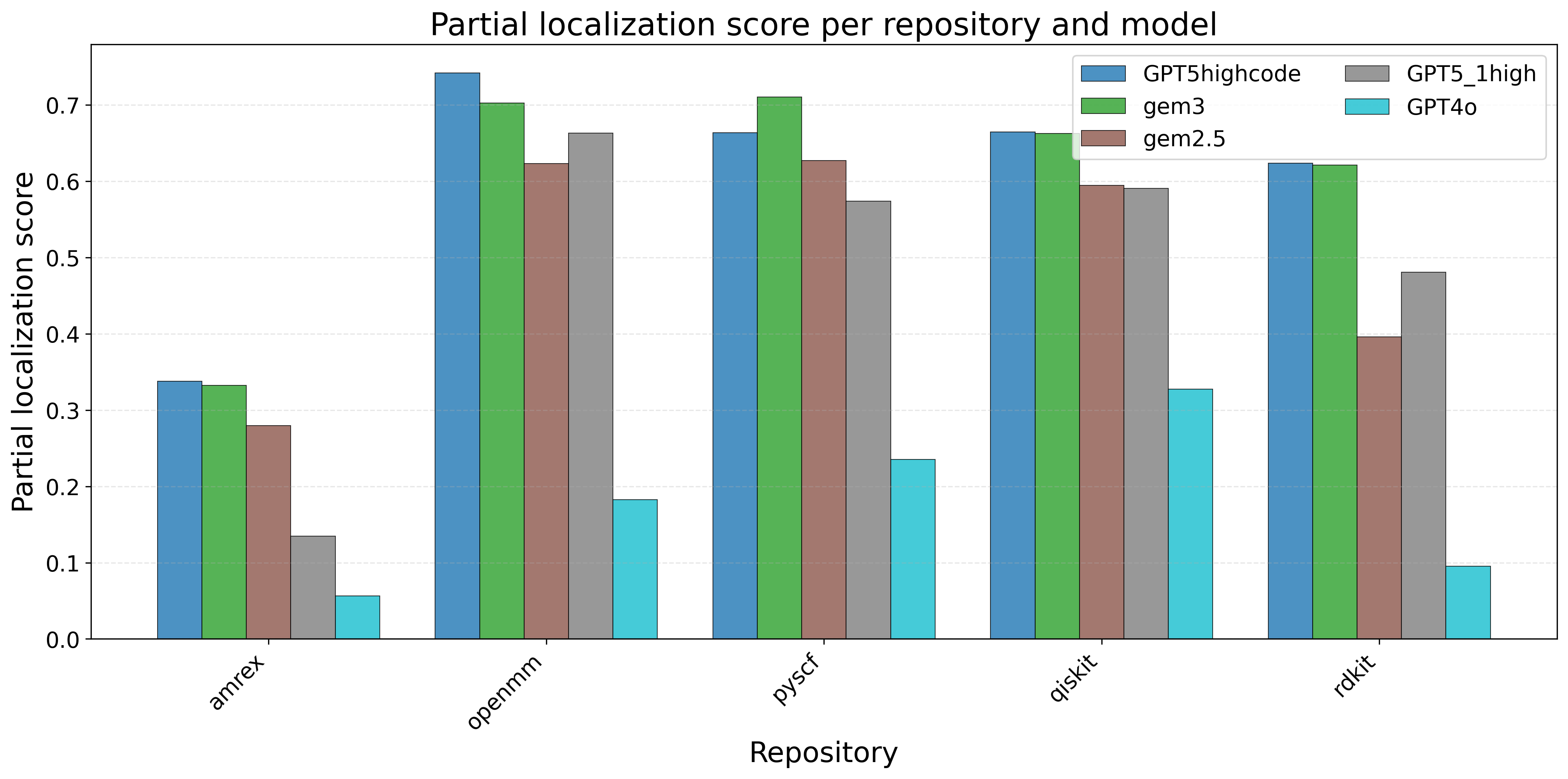
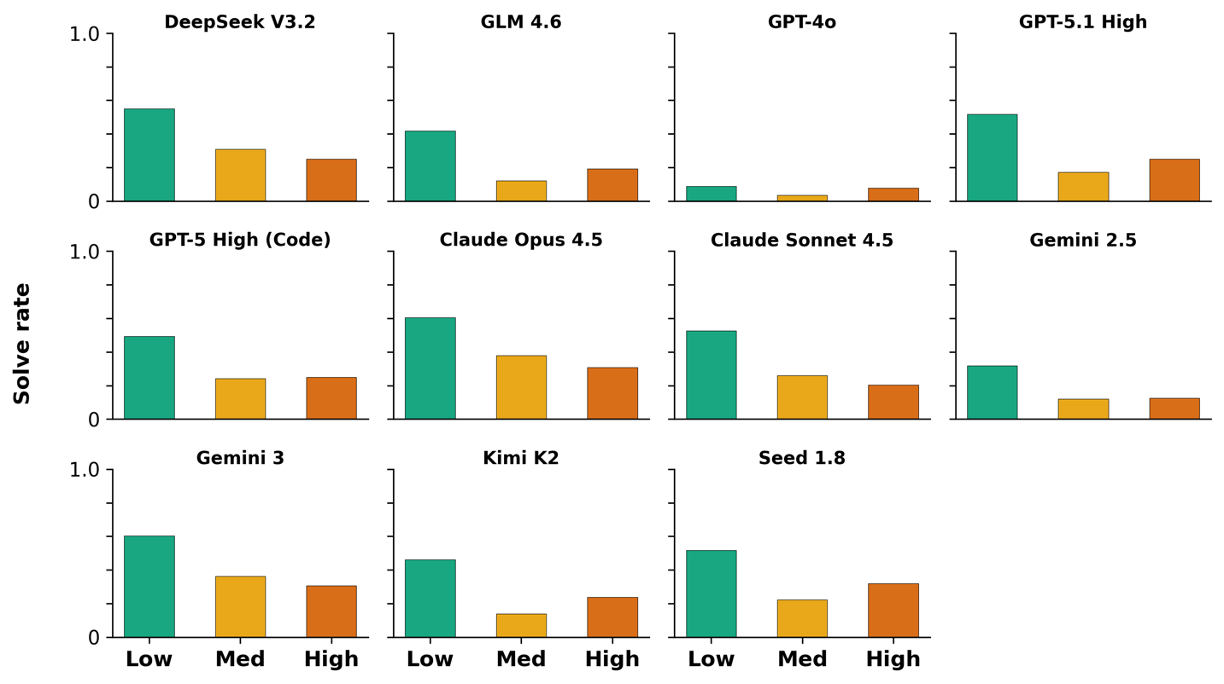
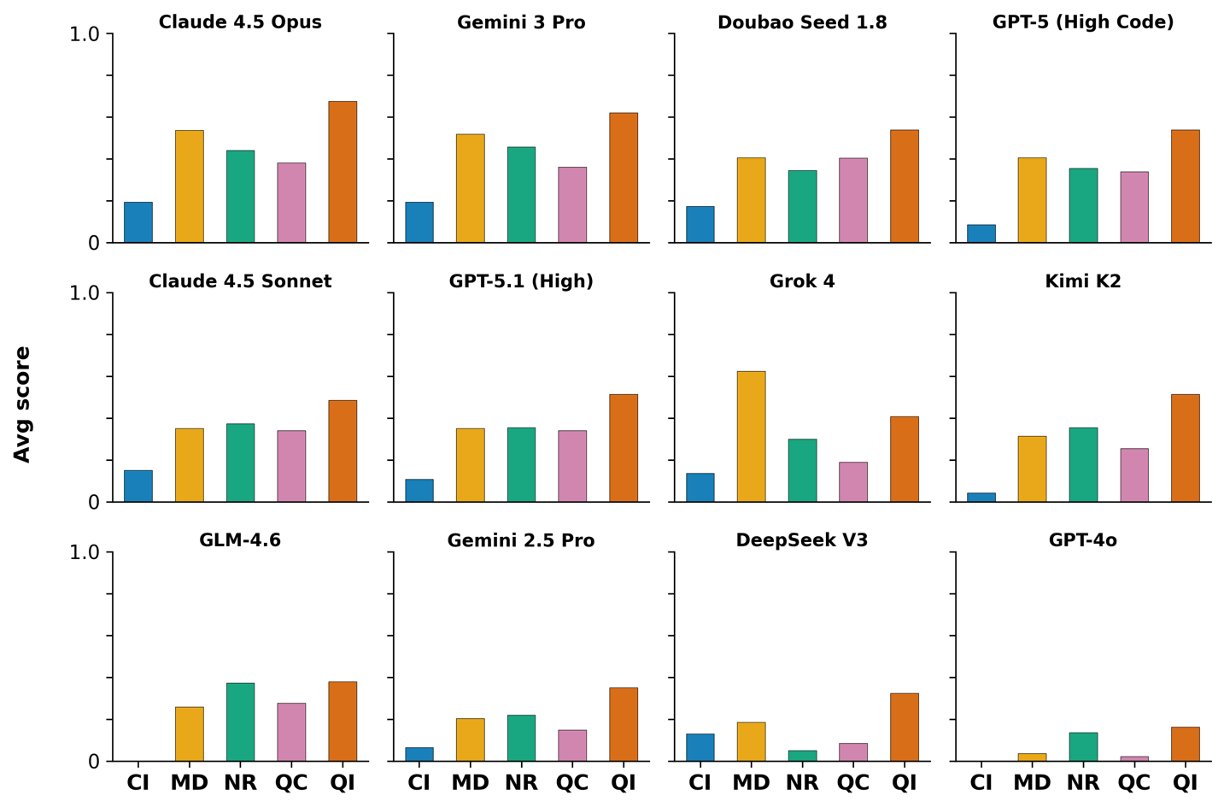
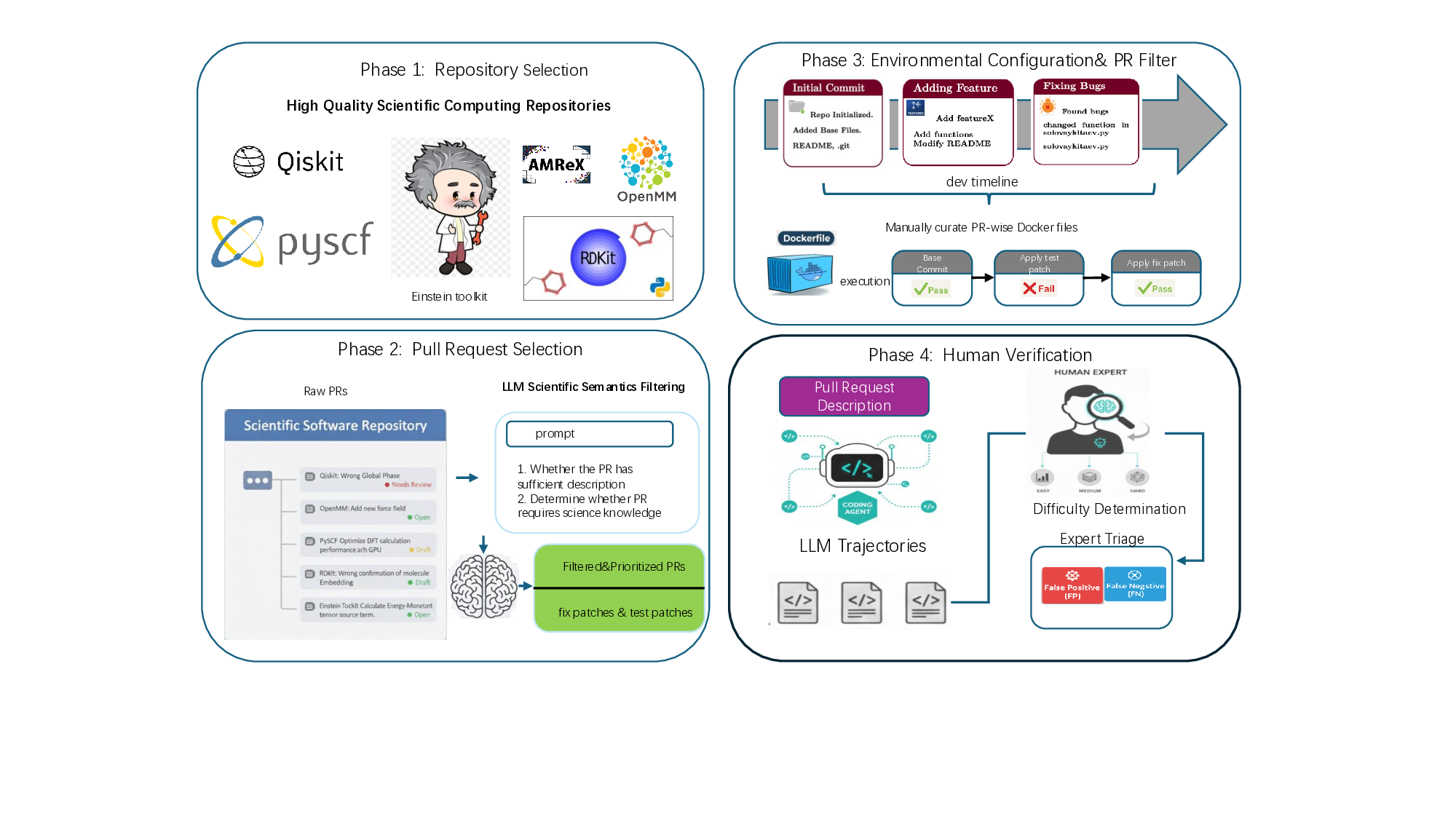
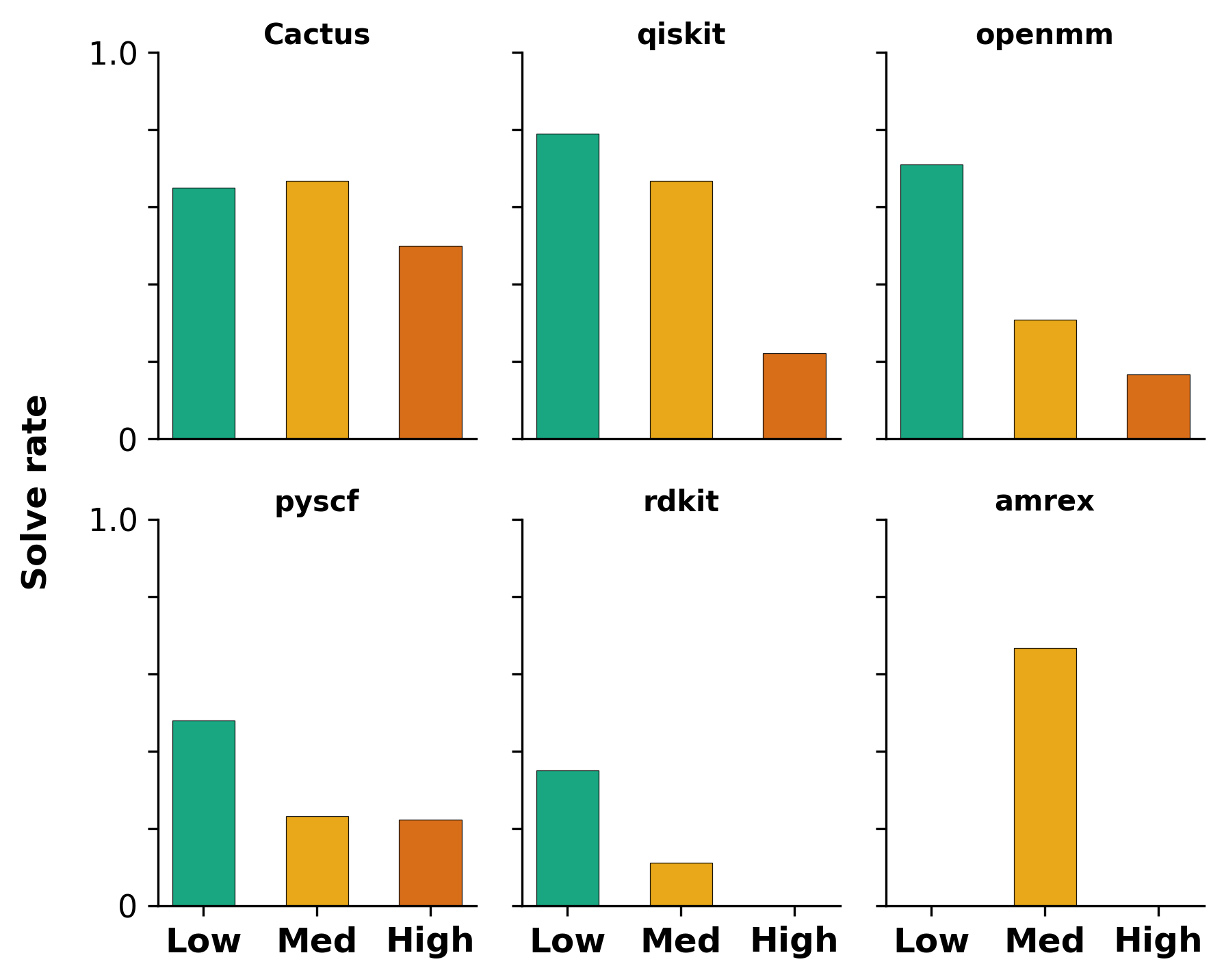
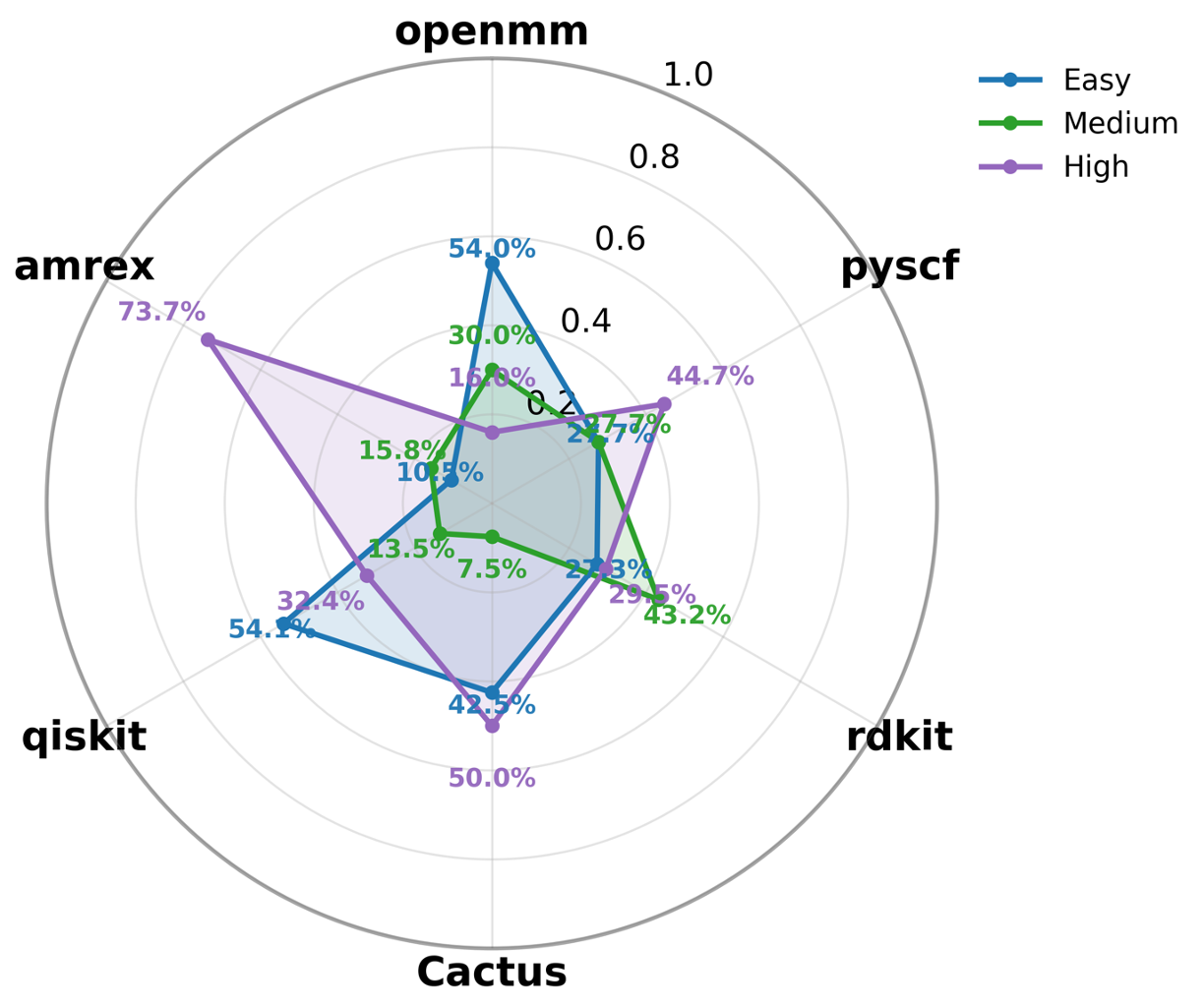
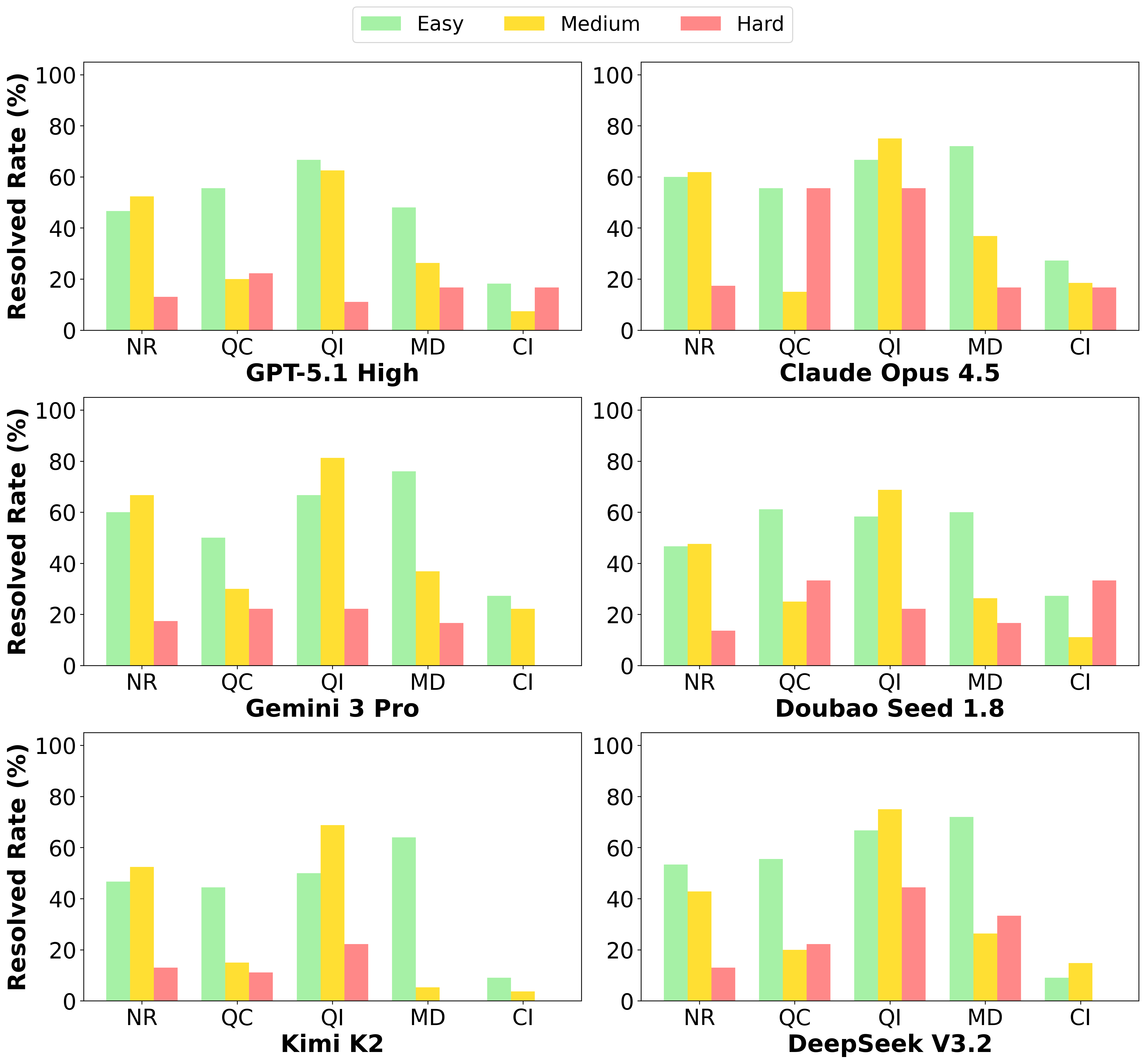
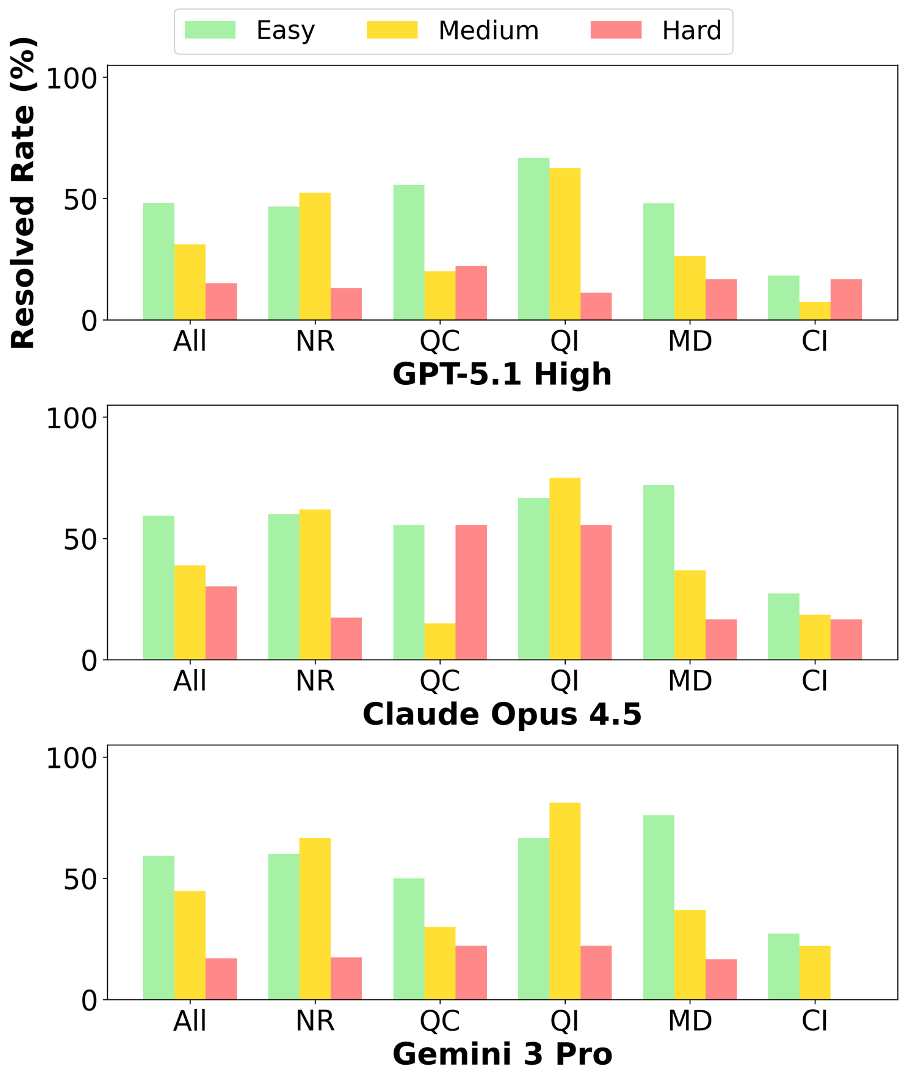
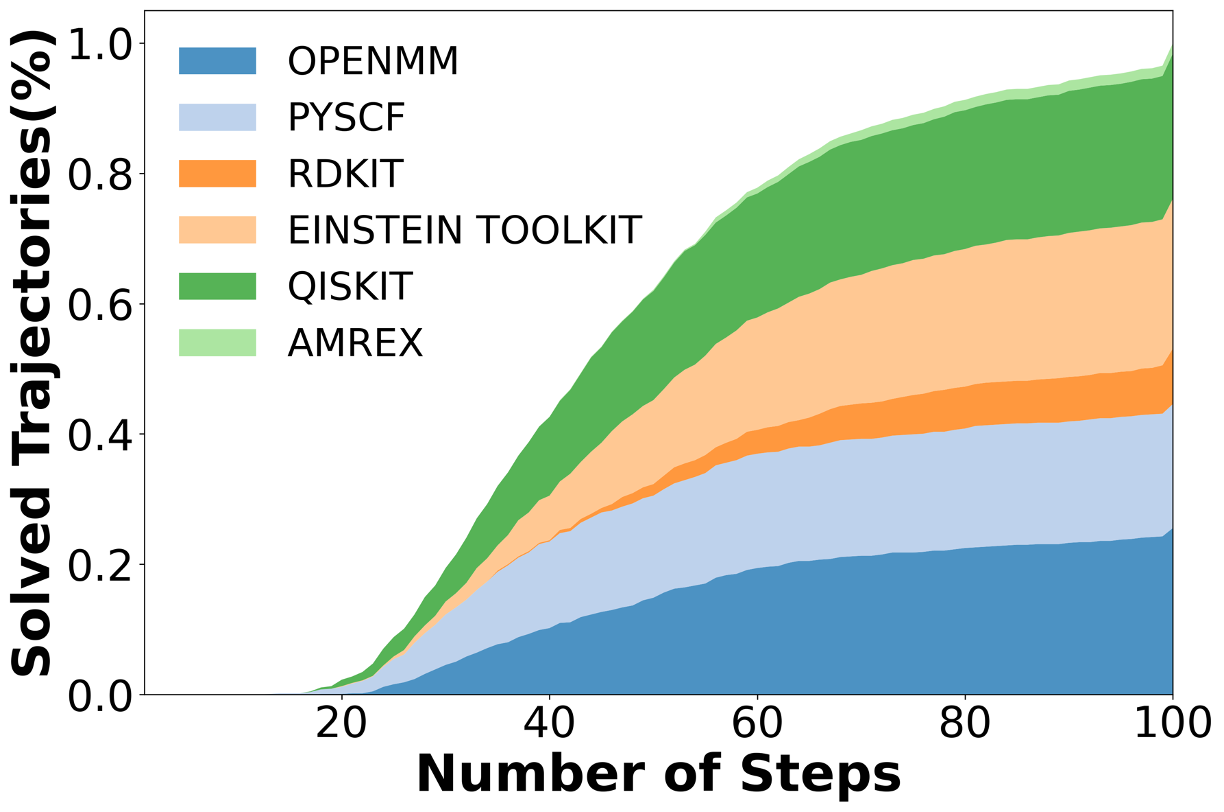
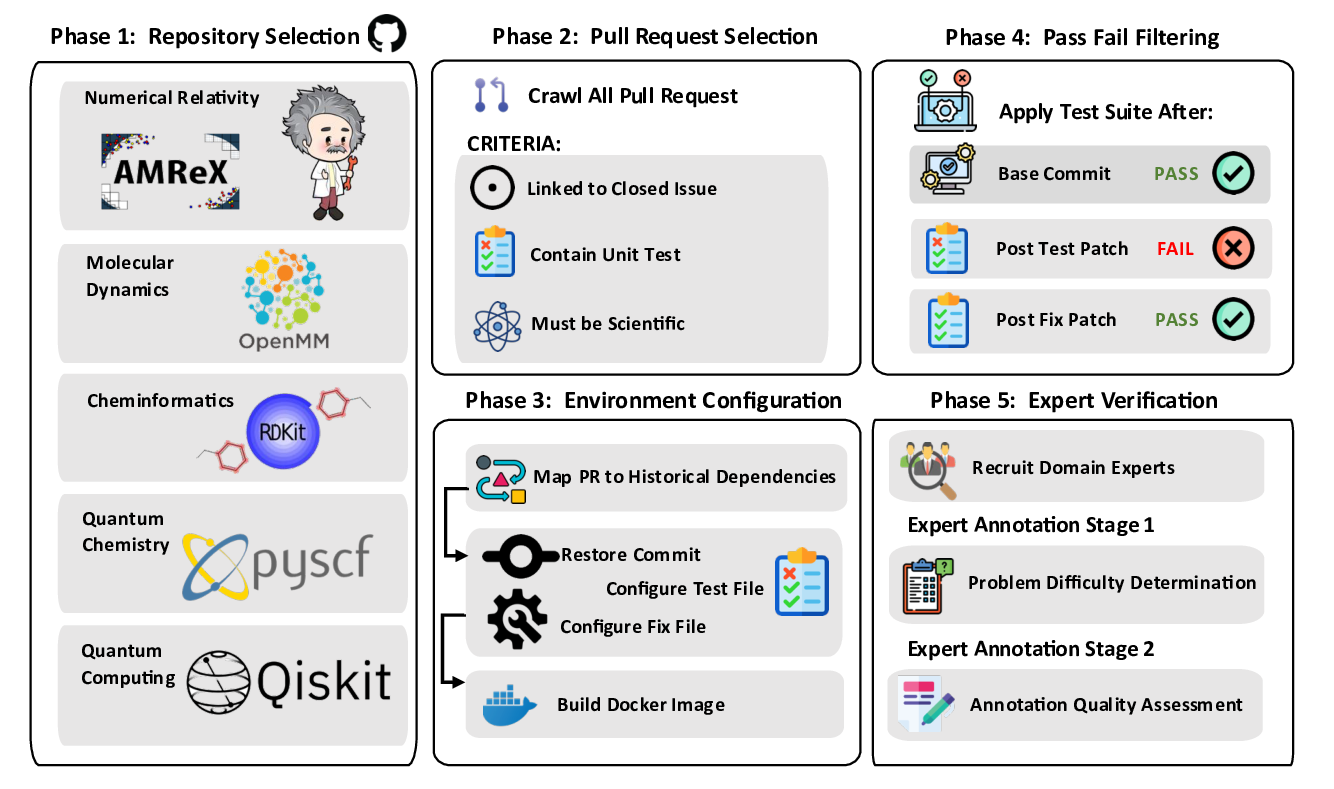
우리는 대형 언어 모델(LLM) 에이전트가 실제 연구 소프트웨어 생태계 내에서 과학 컴퓨팅 개발 에이전트로서 작동할 수 있는지를 평가하기 위한 대규모 벤치마크인 AInsteinBench을 소개한다. 기존의 과학적 추론 벤치마크가 개념적 지식에 초점을 맞추고, 소프트웨어 공학 벤치마크가 일반적인 기능 구현 및 이슈 해결에 중점을 두는 것과 달리, AInsteinBench은 생산 등급 과학 저장소에 기반한 엔드‑투‑엔드 과학 개발 환경에서 모델을 평가한다. 이 벤치마크는 양자 화학, 양자 컴퓨팅, 분자 동역학, 수치 상대성 이론, 유체 역학, 화학 정보학 등 여섯 개의 널리 사용되는 과학 코드베이스에서 유지관리자가 작성한 풀 리퀘스트를 추출해 만든 과제들로 구성된다. 모든 과제는 과학적 난이도, 충분한 테스트 커버리지, 난이도 보정 등을 보장하기 위해 다단계 필터링과 전문가 검토를 거쳐 신중히 선별된다. 실행 가능한 환경에서의 평가, 과학적으로 의미 있는 실패 모드, 테스트 기반 검증을 활용함으로써 AInsteinBench은 모델이 표면적인 코드 생성 수준을 넘어 실제 계산 과학 연구에 필요한 핵심 역량을 갖추었는지를 측정한다.💡 논문 핵심 해설 (Deep Analysis)
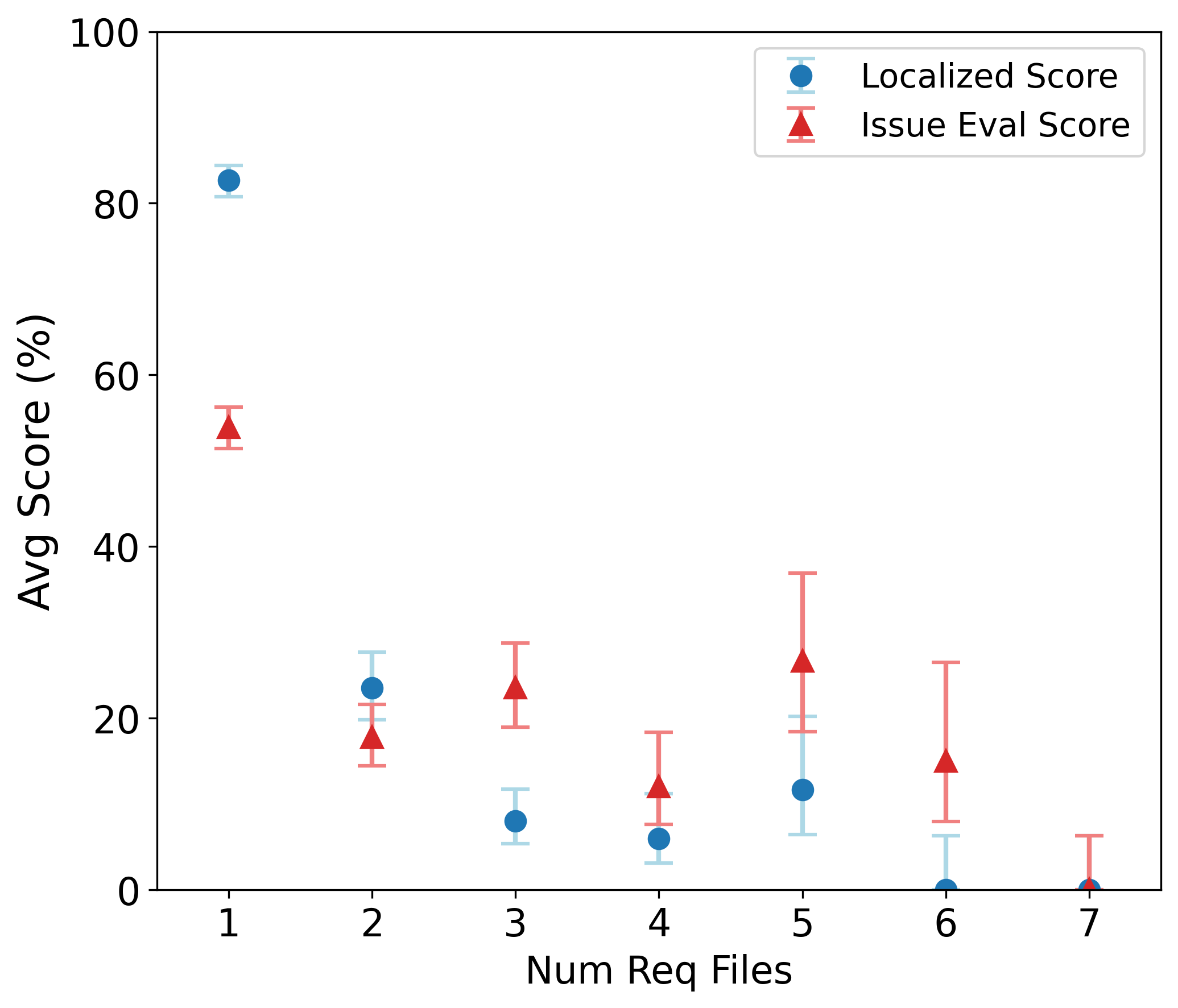
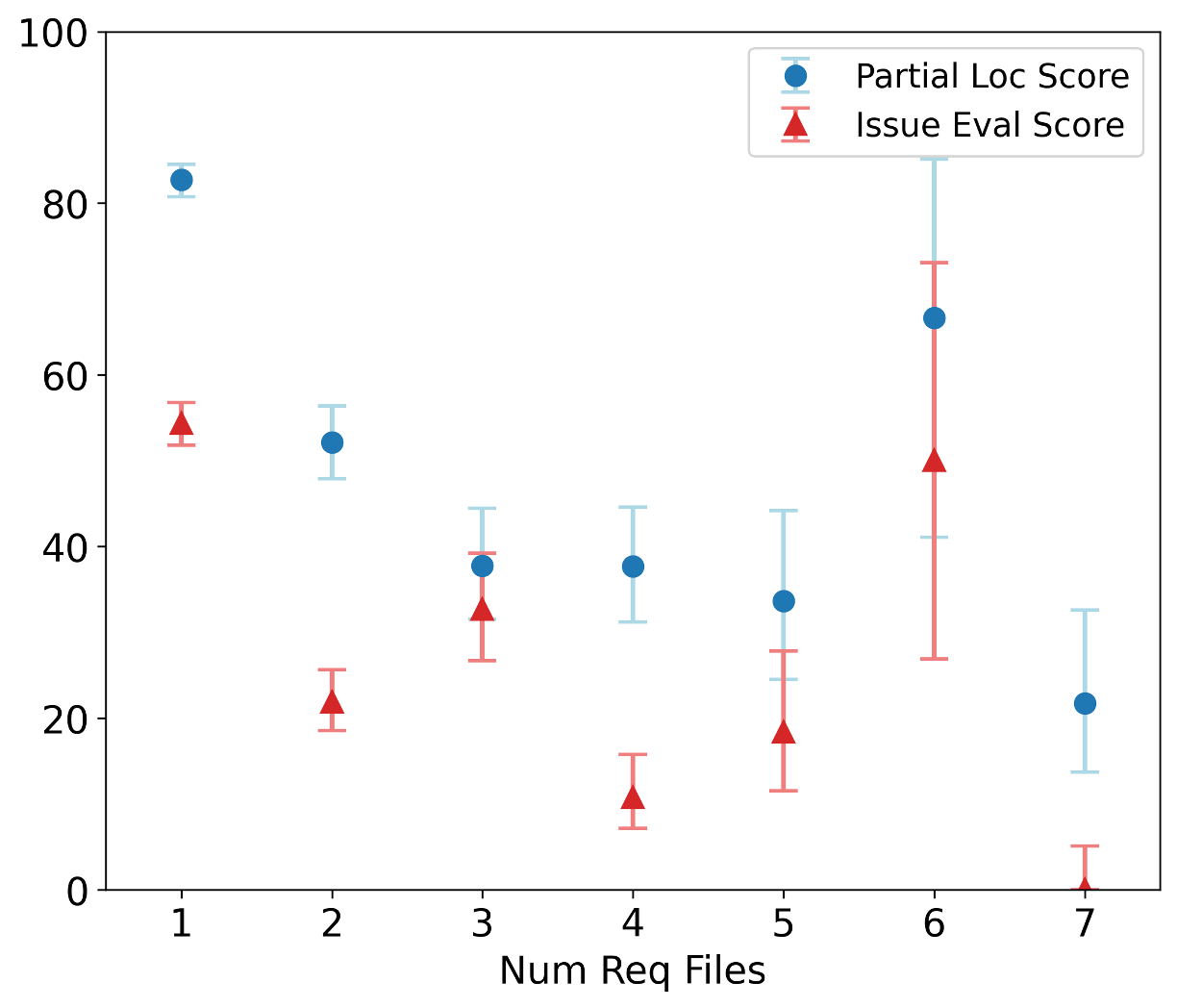
하지만 몇 가지 한계도 존재한다. 첫째, 풀 리퀘스트 기반 과제는 주로 기존 코드베이스에 대한 수정·추가에 초점을 맞추므로, 완전 새로운 알고리즘을 설계하거나 전혀 새로운 프로젝트를 시작하는 능력은 충분히 평가되지 않을 수 있다. 둘째, 현재 벤치마크는 테스트 스위트가 존재하는 경우에만 과제가 선정되므로, 테스트가 부족하거나 전혀 없는 레거시 코드에 대한 대응 능력은 간과된다. 셋째, 평가 환경이 컨테이너화된 실행 환경에 제한되기 때문에, 고성능 컴퓨팅(HPC) 클러스터에서 요구되는 MPI 설정, GPU 메모리 관리, 특수 파일 시스템 접근 등과 같은 실제 연구 인프라와의 연동 문제는 충분히 반영되지 않는다.
향후 연구 방향으로는 (1) “zero‑shot research project” 시나리오를 포함해 완전 새로운 코드베이스를 생성·구축하도록 하는 과제 추가, (2) 테스트가 미비한 레거시 코드에 대한 리팩터링·문서화 능력을 평가하는 서브벤치마크 도입, (3) HPC 환경·GPU 가속·분산 파일 시스템 등 실제 연구 인프라와의 통합 테스트를 지원하는 평가 파이프라인 구축이 제안된다. 이러한 확장은 AInsteinBench을 단순한 코드 생성 능력 평가를 넘어, 과학적 발견을 가속화할 수 있는 진정한 “AI 연구 조수”로서의 역할을 검증하는 포괄적인 플랫폼으로 발전시킬 수 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리