프리픽스 탐색을 이용한 초저지연 유해 콘텐츠 검출
📝 원문 정보
- Title: Prefix Probing: Lightweight Harmful Content Detection for Large Language Models
- ArXiv ID: 2512.16650
- 발행일: 2025-12-18
- 저자: Jirui Yang, Hengqi Guo, Zhihui Lu, Yi Zhao, Yuansen Zhang, Shijing Hu, Qiang Duan, Yinggui Wang, Tao Wei
📝 초록 (Abstract)
대형 언어 모델을 안전에 민감한 실제 서비스에 적용할 때는 검출 정확도, 추론 지연시간, 배포 비용 사이의 삼중 트레이드오프가 존재한다. 본 논문은 “프리픽스 프로빙”이라는 블랙박스 기반 유해 콘텐츠 검출 기법을 제안한다. 이 방법은 “동의·실행” 프리픽스와 “거부·안전” 프리픽스의 조건부 로그 확률을 비교하고, 프리픽스 캐싱을 활용해 검출 오버헤드를 첫 토큰 지연 수준으로 낮춘다. 추론 단계에서는 프리픽스에 대한 단일 로그 확률 계산만 수행해 유해성 점수를 산출하고 임계값을 적용하므로 추가 모델 호출이나 다단계 추론이 필요하지 않다. 또한, 정보량이 높은 프리픽스를 자동으로 탐색하는 효율적인 프리픽스 구성 알고리즘을 설계해 판별력을 크게 향상시켰다. 광범위한 실험 결과, 프리픽스 프로빙은 외부 안전 모델에 필적하는 검출 성능을 보이면서도 계산 비용이 최소에 가깝고 별도 모델 배포가 필요 없다는 실용성을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
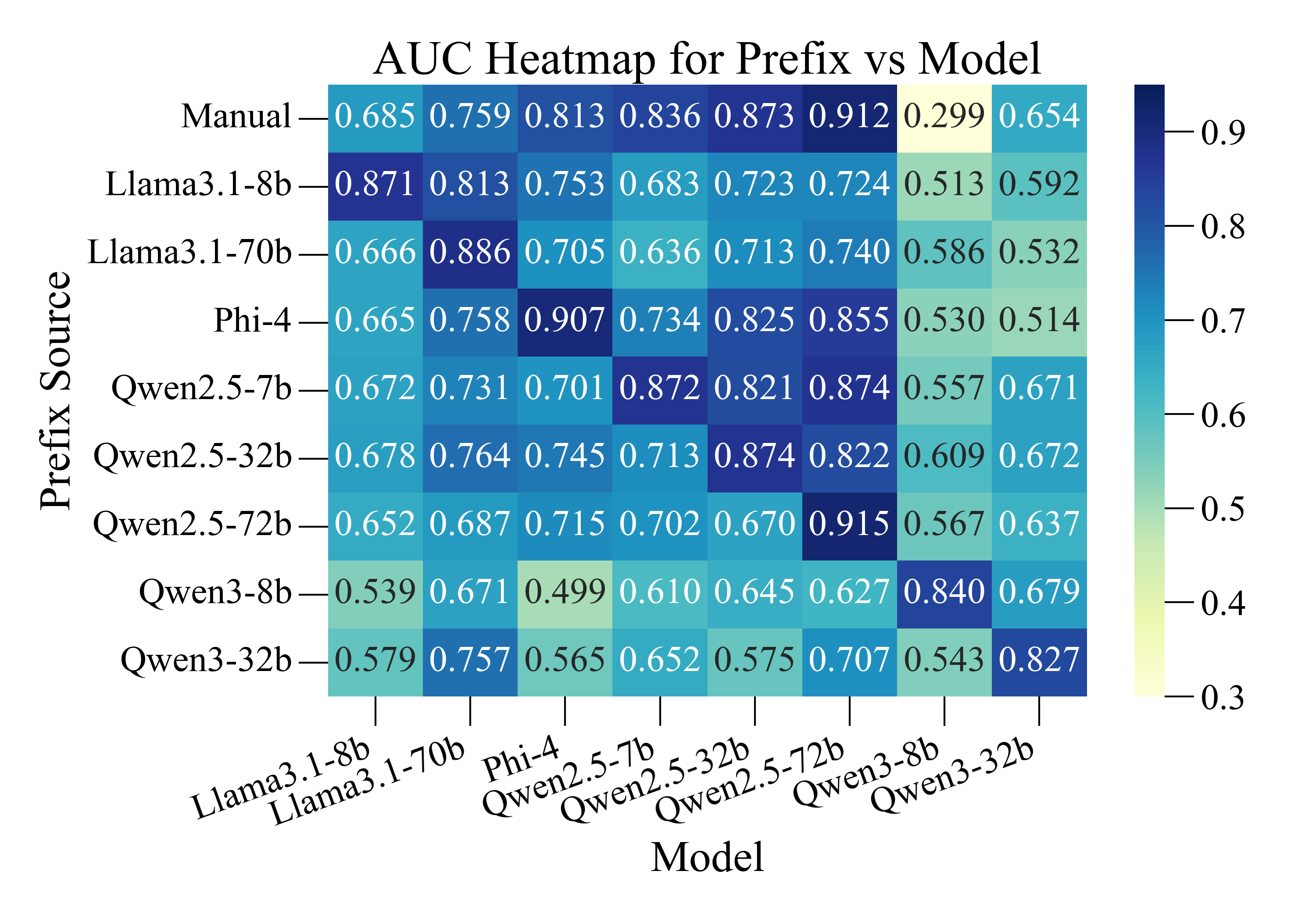
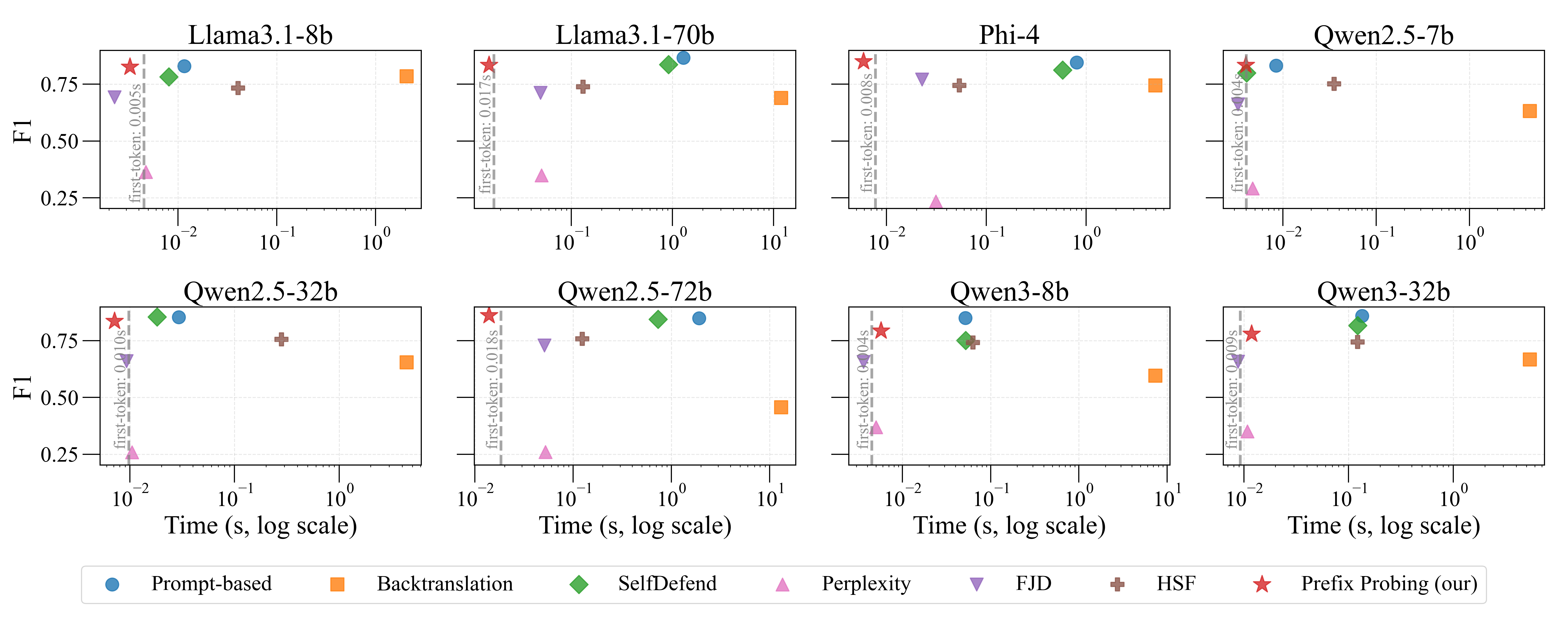
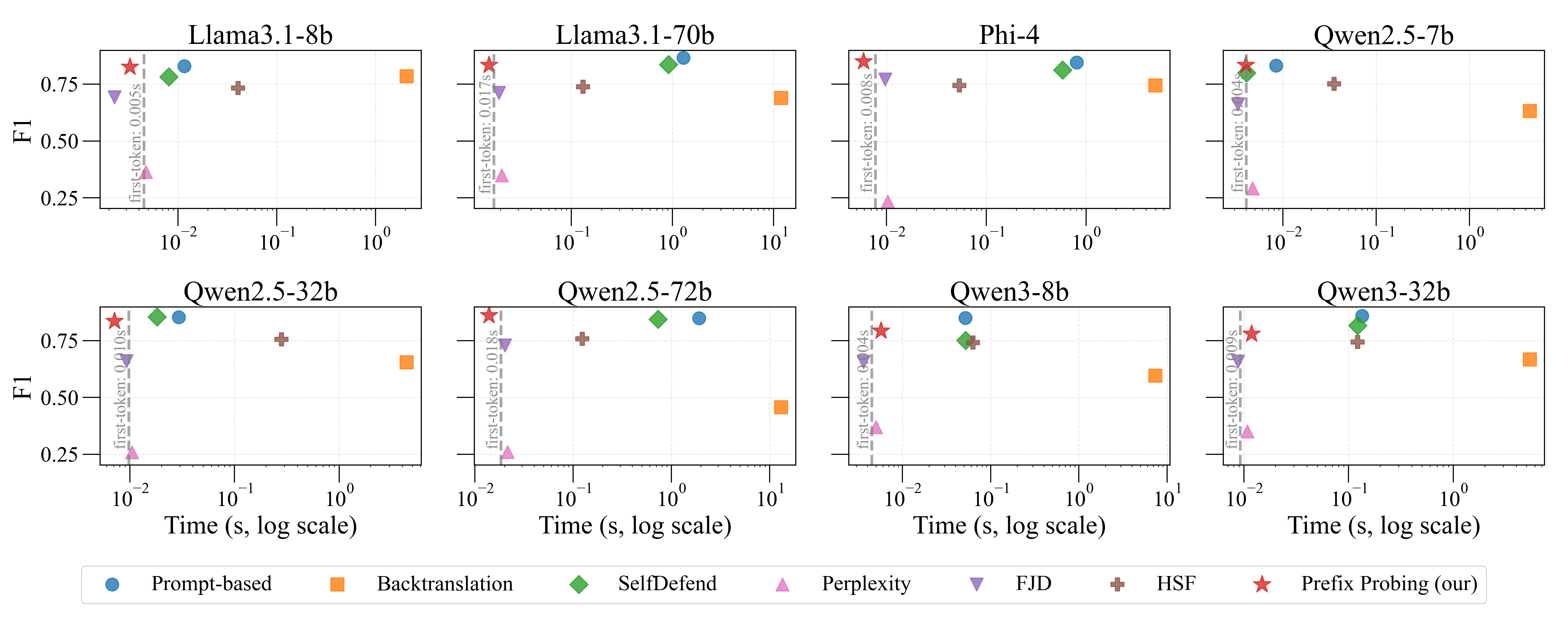
‘프리픽스 프로빙’은 이러한 한계를 극복하기 위해 조건부 로그 확률이라는 아주 기본적인 언어 모델 내부 신호만을 활용한다. 구체적으로, “나는 요청을 수행한다”(동의·실행)와 “나는 요청을 거부한다”(거부·안전)와 같은 두 종류의 프리픽스를 미리 정의하고, 입력 문장이 주어졌을 때 각각의 프리픽스가 이어질 확률을 모델이 계산하도록 한다. 두 확률의 비율 혹은 차이를 유해성 점수로 변환하고, 사전에 정해진 임계값을 초과하면 유해 콘텐츠로 판단한다. 여기서 중요한 점은 프리픽스 자체만을 캐시해 두면, 실제 추론 시에는 모델이 첫 토큰을 생성하는 과정과 동일한 비용만으로 로그 확률을 얻을 수 있다는 것이다. 즉, 기존에 “프리픽스 → 로그 확률 → 판단”이라는 2단계 연산이 “첫 토큰 생성 비용만”으로 압축된다.
프리픽스의 선택도 성능에 큰 영향을 미친다. 저자는 프리픽스 자동 탐색 알고리즘을 제안한다. 이 알고리즘은 대규모 안전 데이터셋을 이용해 후보 프리픽스 집합을 생성하고, 각 프리픽스가 유해/비유해 샘플을 구분하는 정보 이득(Information Gain)을 평가한다. 정보 이득이 높은 프리픽스는 최종 후보로 선정되며, 다수의 프리픽스를 조합해 앙상블 형태의 점수를 산출함으로써 단일 프리픽스보다 강인한 판별력을 확보한다. 탐색 과정은 한 번 수행하면 재사용 가능하므로, 배포 후에는 추가 비용이 전혀 들지 않는다.
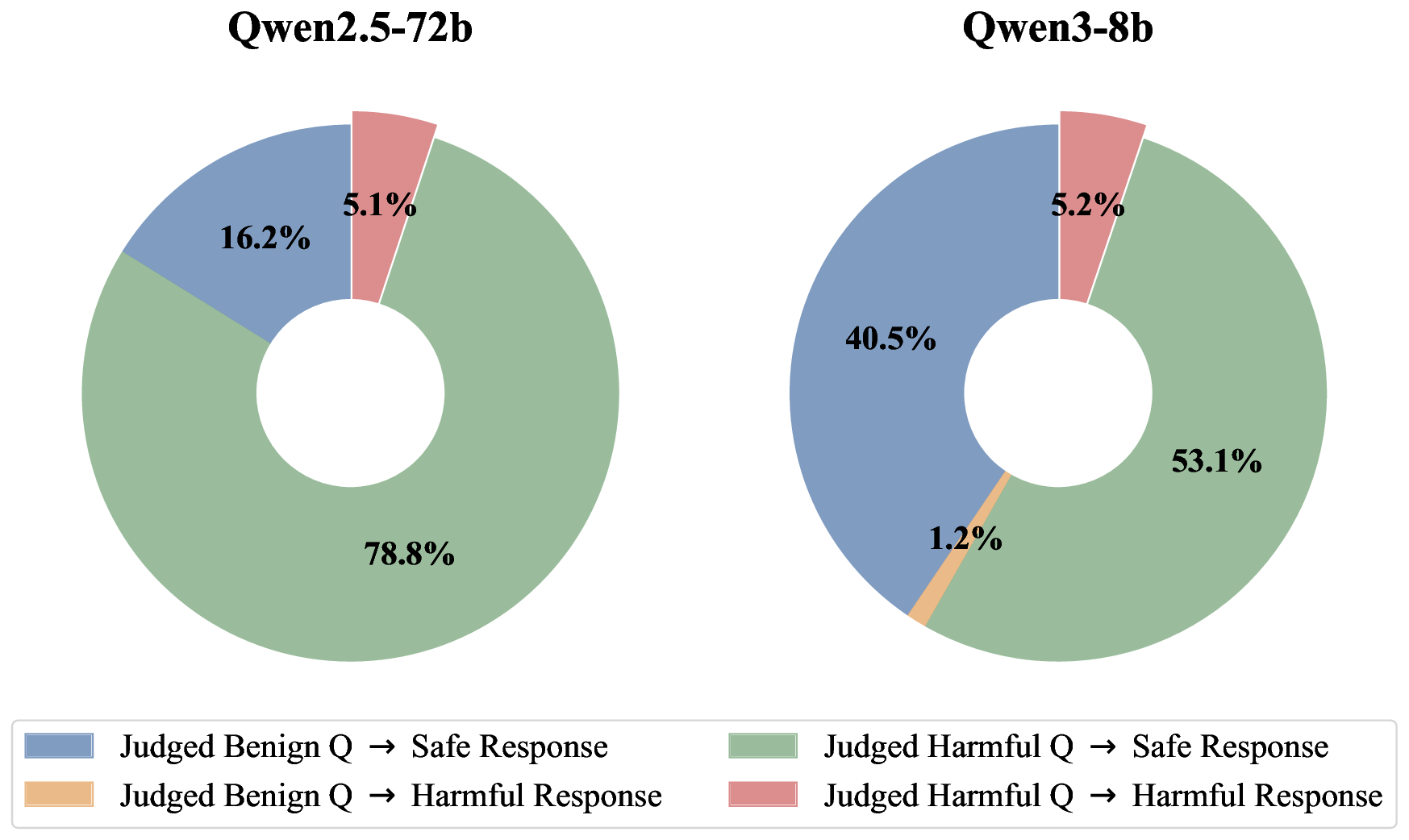
실험에서는 대표적인 외부 안전 모델(예: OpenAI Moderation, Perspective API)과 비교했을 때, AUROC, F1-score 등 주요 지표에서 거의 동등한 성능을 보였다. 동시에 평균 추론 지연은 1~2 ms 수준으로, 일반적인 LLM의 첫 토큰 생성 시간과 거의 차이가 없으며, GPU 메모리 사용량도 기존 모델에 비해 0% 증가한다. 이는 특히 엣지 디바이스나 저사양 서버 환경에서 큰 장점으로 작용한다. 또한, 별도 모델을 배포·업데이트할 필요가 없으므로 운영 비용과 보안 관리 부담이 크게 감소한다.
요약하면, 프리픽스 프로빙은 (1) 극소량의 연산만으로 유해성을 판단, (2) 자동 프리픽스 설계를 통해 높은 판별력 확보, (3) 배포·운영 비용 최소화라는 세 축을 동시에 만족시키는 실용적인 솔루션이다. 향후 연구에서는 프리픽스의 다국어 확장, 도메인 특화 프리픽스 자동 생성, 그리고 적대적 공격에 대한 내성을 평가하는 방향으로 발전시킬 여지가 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리