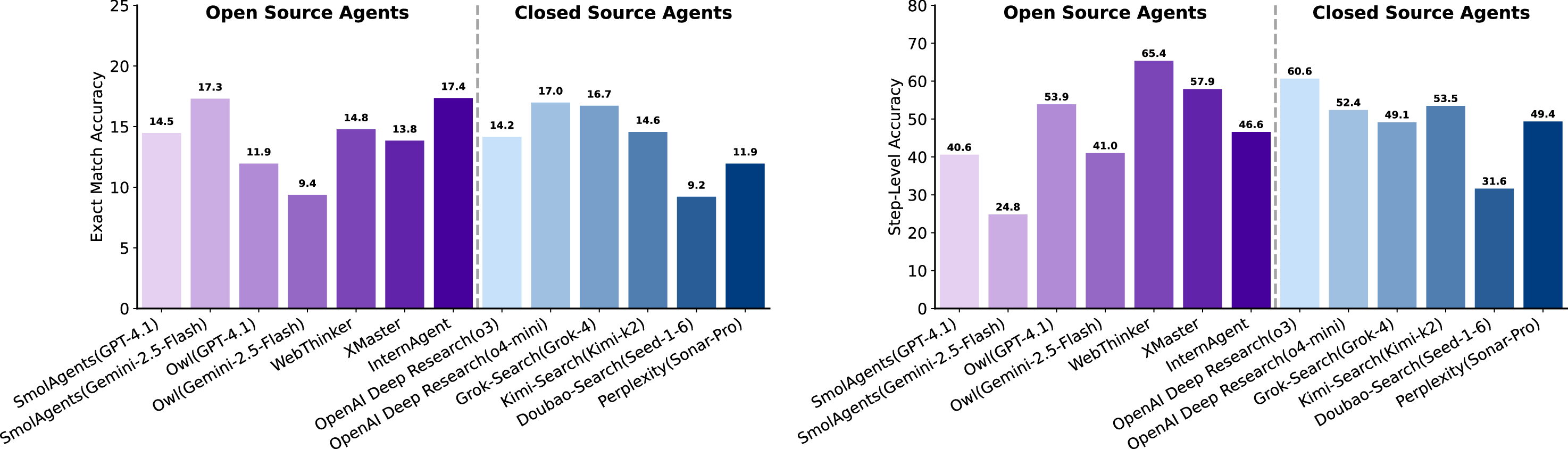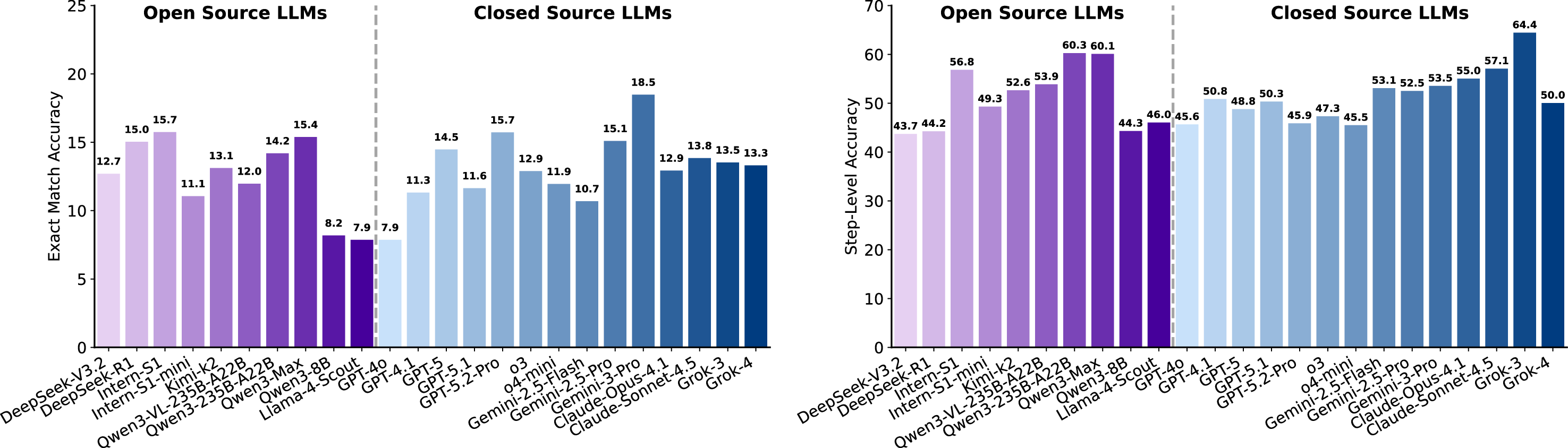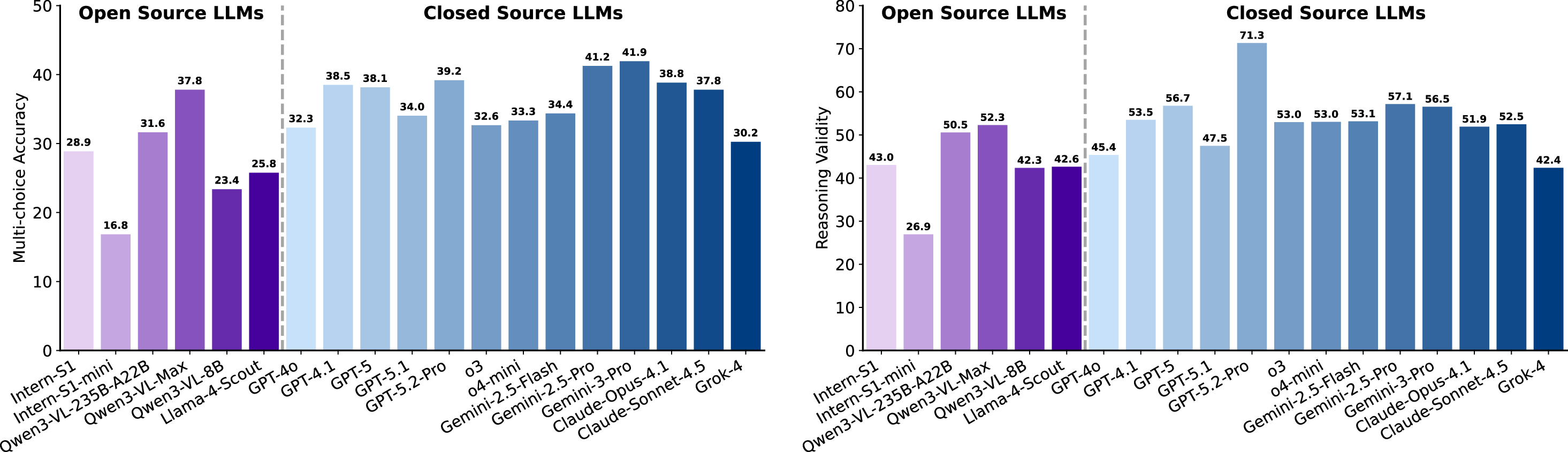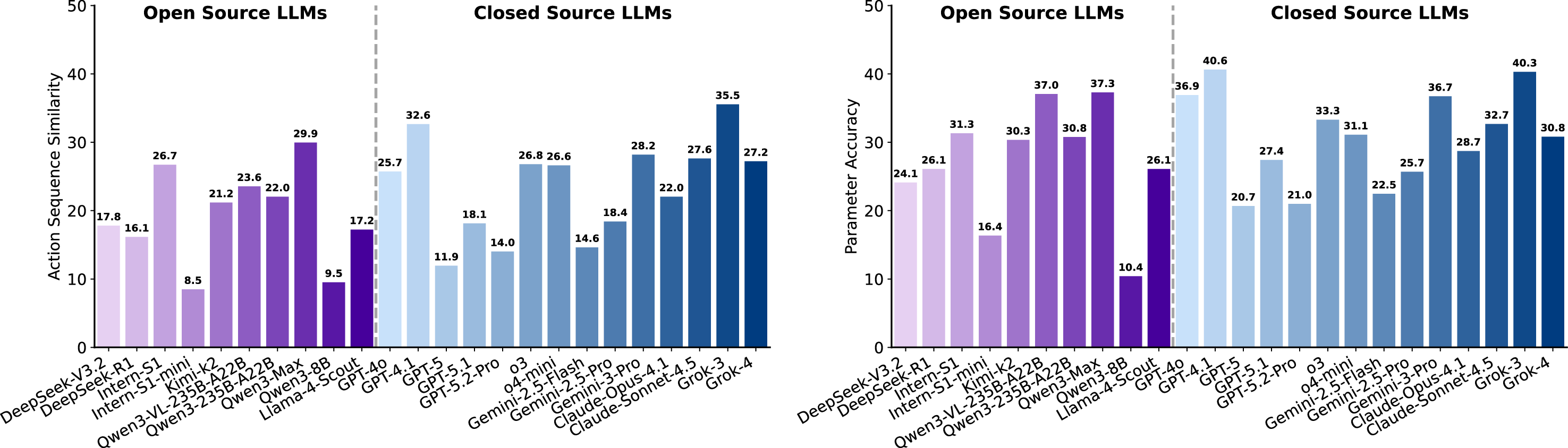과학 일반 지능을 위한 실험적 벤치마크와 프랙티컬 인콰이어리 모델
📝 원문 정보
- Title: Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
- ArXiv ID: 2512.16969
- 발행일: 2025-12-18
- 저자: Wanghan Xu, Yuhao Zhou, Yifan Zhou, Qinglong Cao, Shuo Li, Jia Bu, Bo Liu, Yixin Chen, Xuming He, Xiangyu Zhao, Xiang Zhuang, Fengxiang Wang, Zhiwang Zhou, Qiantai Feng, Wenxuan Huang, Jiaqi Wei, Hao Wu, Yuejin Yang, Guangshuai Wang, Sheng Xu, Ziyan Huang, Xinyao Liu, Jiyao Liu, Cheng Tang, Wei Li, Ying Chen, Junzhi Ning, Pengfei Jiang, Chenglong Ma, Ye Du, Changkai Ji, Huihui Xu, Ming Hu, Jiangbin Zheng, Xin Chen, Yucheng Wu, Feifei Jiang, Xi Chen, Xiangru Tang, Yuchen Fu, Yingzhou Lu, Yuanyuan Zhang, Lihao Sun, Chengbo Li, Jinzhe Ma, Wanhao Liu, Yating Liu, Kuo-Cheng Wu, Shengdu Chai, Yizhou Wang, Ouwen Zhangjin, Chen Tang, Shufei Zhang, Wenbo Cao, Junjie Ren, Taoyong Cui, Zhouheng Yao, Juntao Deng, Yijie Sun, Feng Liu, Wangxu Wei, Jingyi Xu, Zhangrui Li, Junchao Gong, Zijie Guo, Zhiyu Yao, Zaoyu Chen, Tianhao Peng, Fangchen Yu, Bo Zhang, Dongzhan Zhou, Shixiang Tang, Jiaheng Liu, Fenghua Ling, Yan Lu, Yuchen Ren, Ben Fei, Zhen Zhao, Xinyu Gu, Rui Su, Xiao-Ming Wu, Weikang Si, Yang Liu, Hao Chen, Xiangchao Yan, Xue Yang, Junchi Yan, Jiamin Wu, Qihao Zheng, Chenhui Li, Zhiqiang Gao, Hao Kong, Junjun He, Mao Su, Tianfan Fu, Peng Ye, Chunfeng Song, Nanqing Dong, Yuqiang Li, Huazhu Fu, Siqi Sun, Lijing Cheng, Jintai Lin, Wanli Ouyang, Bowen Zhou, Wenlong Zhang, Lei Bai
📝 초록 (Abstract)
과학 일반 지능(SGI)의 정의를 실천적 탐구 모델(PIM)과 연결하고, 이를 네 가지 과학자‑중심 과제(깊이 있는 연구, 아이디어 생성, 건식·습식 실험, 실험 추론)로 구체화한다. SGI‑Bench은 과학지의 125대 질문에서 영감을 얻은 1,000개 이상의 전문가 검증 샘플을 제공해 최신 대형 언어 모델을 체계적으로 평가한다. 실험 결과는 깊이 있는 연구 단계에서 정확도 10‑20%에 머무르고, 아이디어는 실현 가능성과 구체성이 부족하며, 건식 실험은 코드 실행 가능성은 높지만 결과 정확도가 낮고, 습식 실험은 프로토콜 순서 유지가 약하며, 다중모달 비교 추론에서 지속적인 어려움을 보인다. 또한 추론 시점 강화학습(TTRL)을 도입해 검색 기반 신선도 보상을 최적화함으로써 정답이 없는 상황에서도 가설의 참신성을 향상시킨다. 이와 같이 PIM 기반 정의, 워크플로우 중심 벤치마크, 실증적 통찰을 제공함으로써 AI가 실제 과학 발견에 참여할 수 있는 토대를 마련한다.💡 논문 핵심 해설 (Deep Analysis)
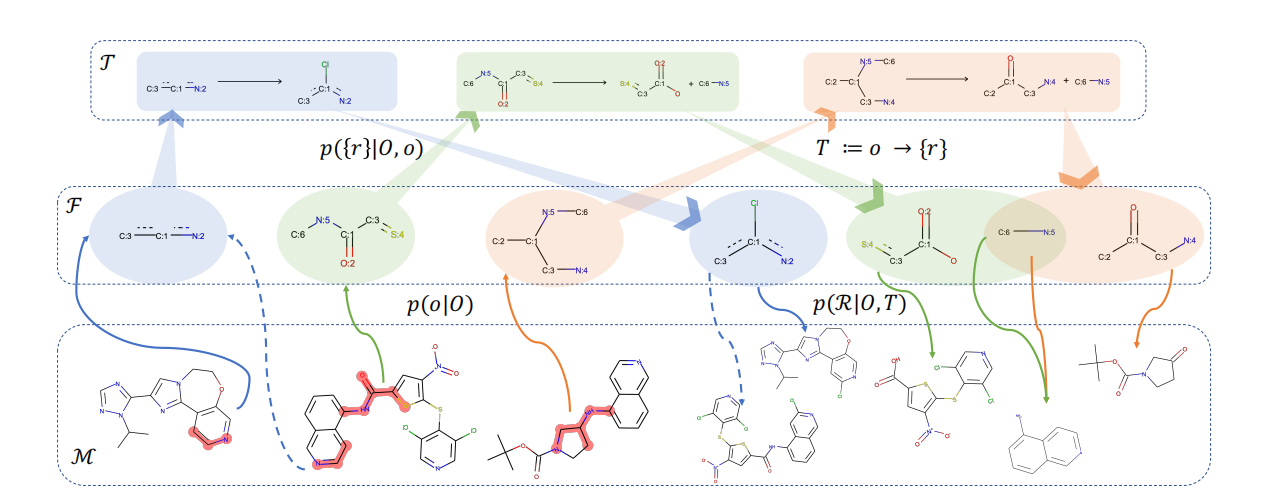
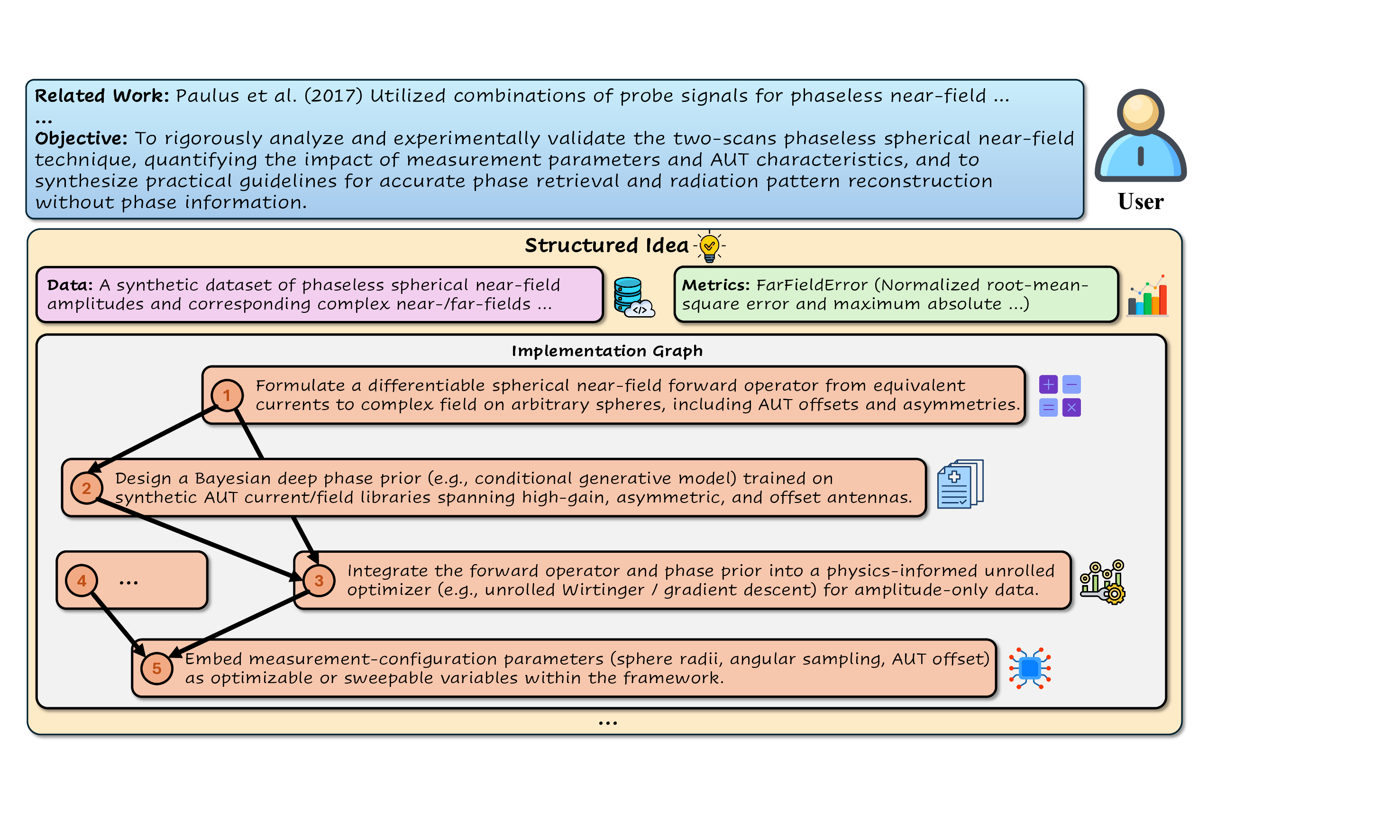
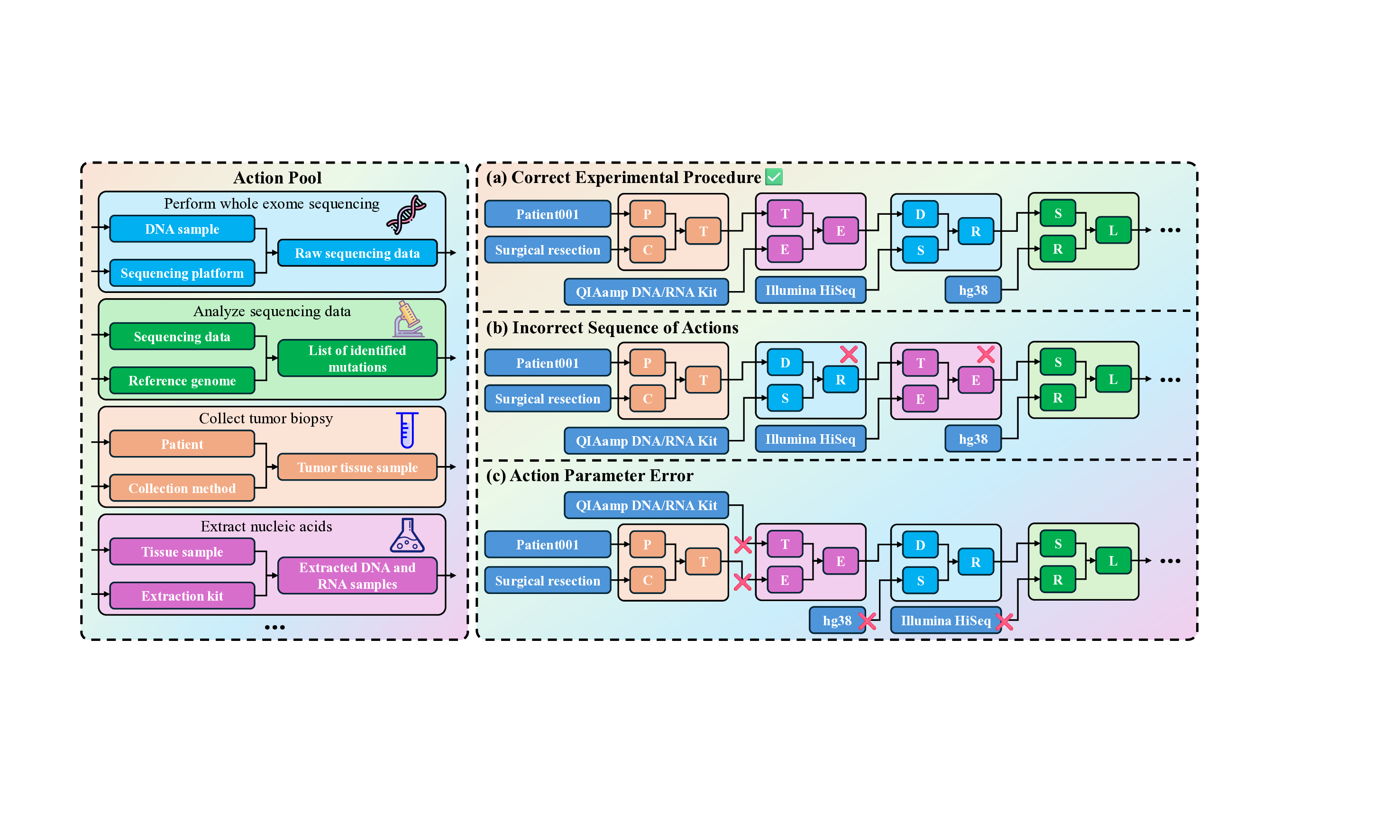
PIM에 기반해 정의된 SGI‑Bench은 네 가지 과학자‑중심 작업을 제시한다. 첫째, ‘깊이 있는 연구’는 주어진 질문에 대해 문헌 조사, 가설 설정, 논리적 전개까지 전 과정을 요구한다. 둘째, ‘아이디어 생성’은 새로운 연구 주제나 실험 설계를 창출하도록 설계되었으며, 창의성뿐 아니라 실현 가능성도 평가한다. 셋째, ‘건식·습식 실험’은 각각 코드 기반 시뮬레이션과 실제 실험 프로토콜을 포함한다. 마지막으로 ‘실험 추론’은 실험 결과를 해석하고, 다음 단계의 가설을 도출하는 과정을 다룬다.
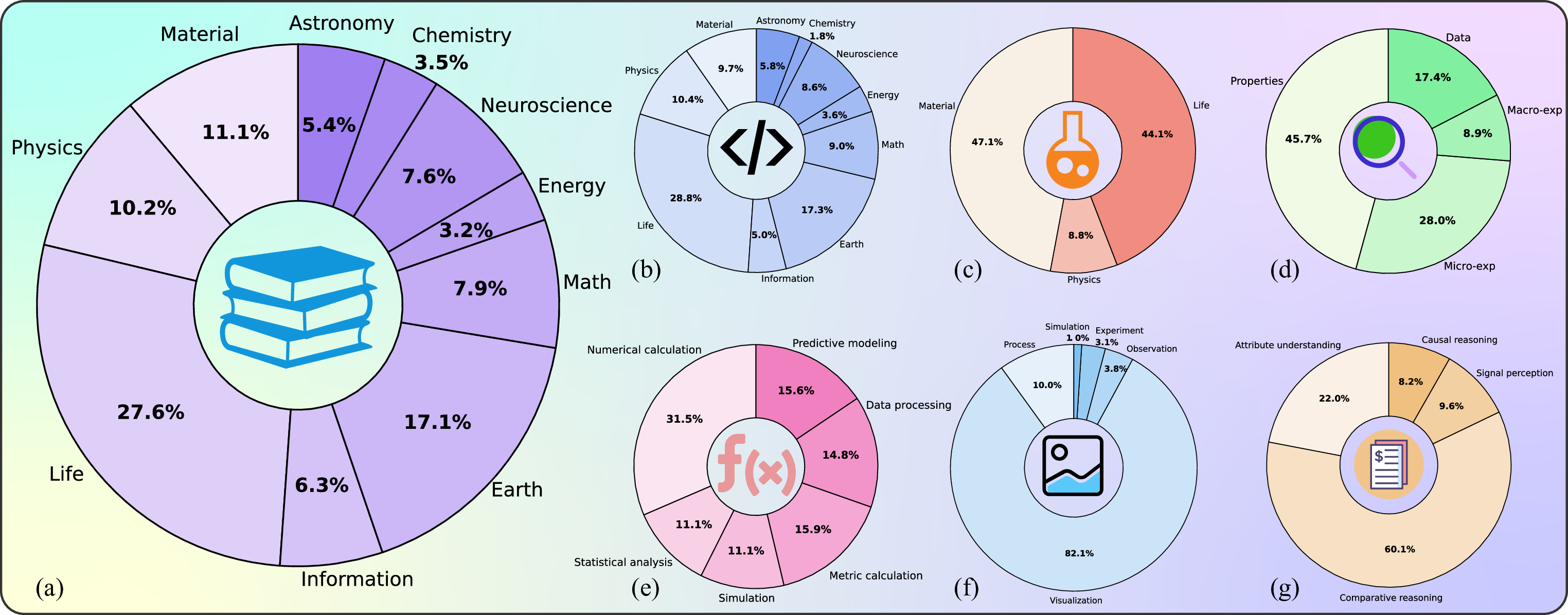
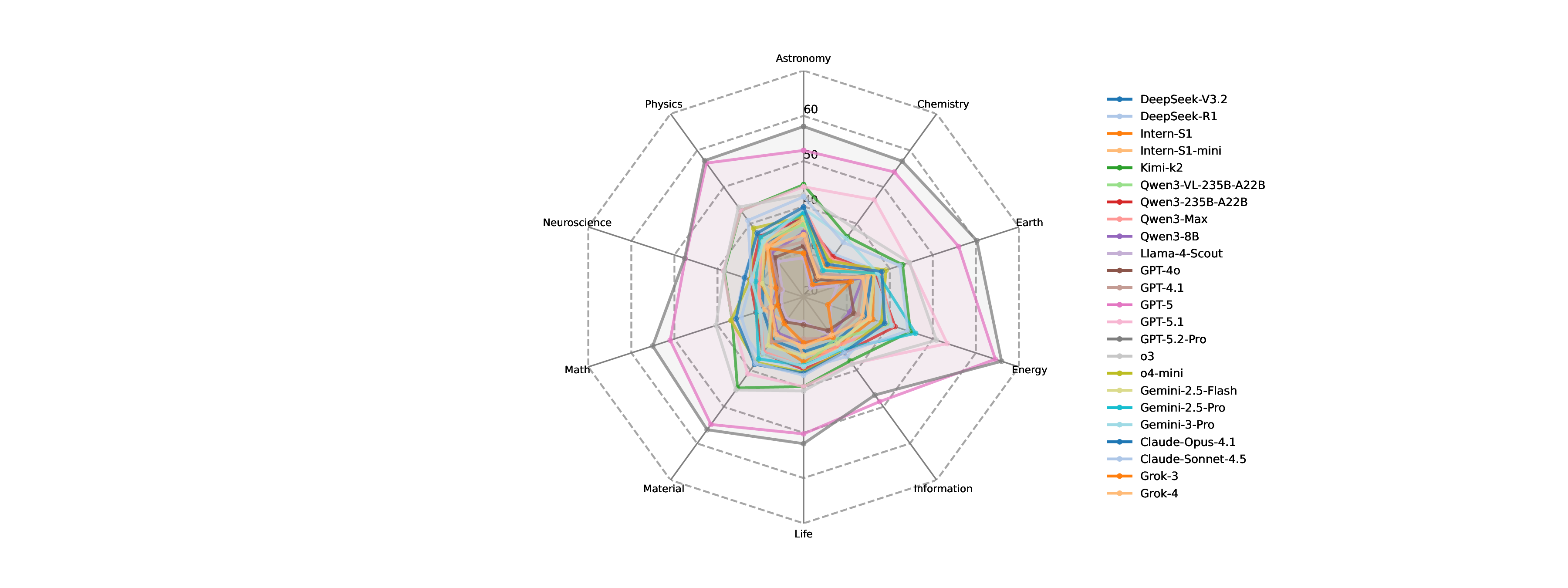
벤치마크 샘플은 ‘Science’ 저널의 125대 질문을 원천으로 하여, 다양한 학문 분야(생물학, 물리학, 화학, 사회과학 등)를 포괄한다. 각 샘플은 전문가가 직접 검증한 ‘질문‑정답‑평가 기준’으로 구성되어 있어, LLM이 단계별 정답을 제시했는지 여부를 정량화할 수 있다.
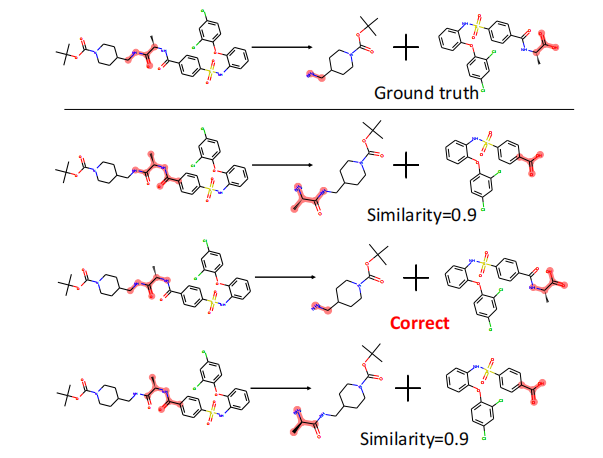
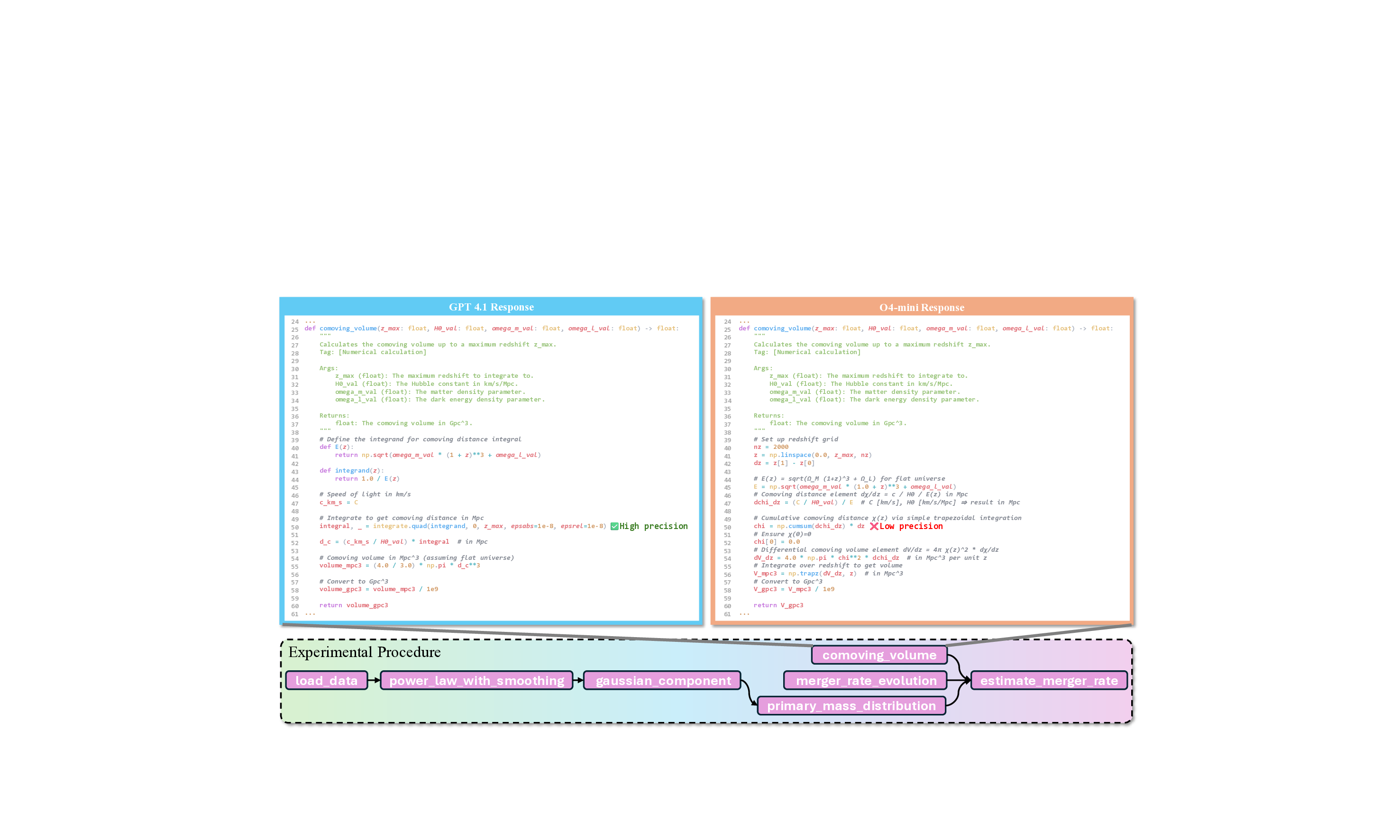
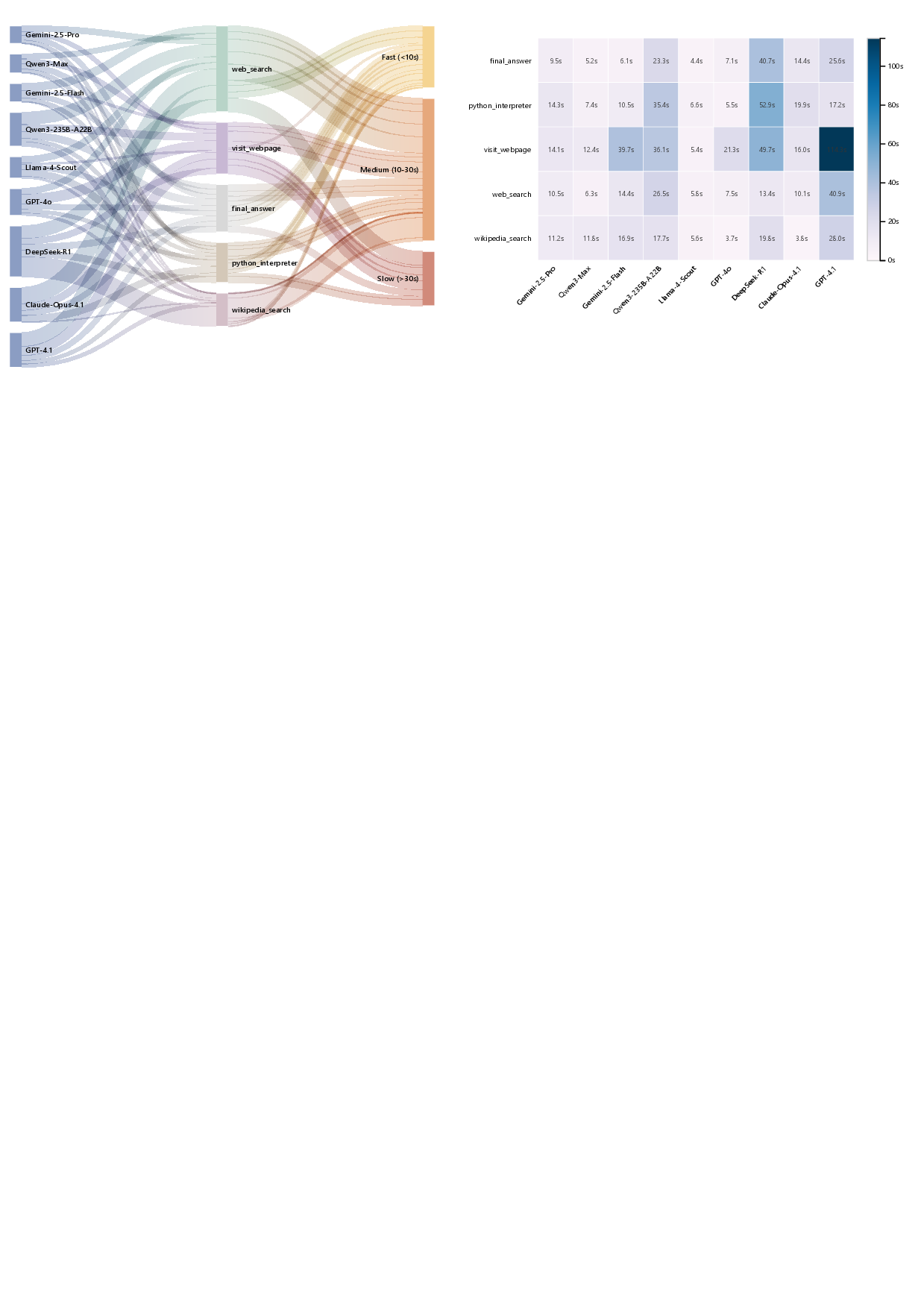
실험 결과는 현재 최첨단 LLM이 SGI에 필요한 복합 능력을 충분히 갖추지 못했음을 명확히 보여준다. ‘깊이 있는 연구’ 단계에서는 정확도(Exact Match)가 10~20%에 불과했으며, 이는 모델이 문헌 정보를 적절히 통합하고 논리적 흐름을 유지하는 데 한계가 있음을 의미한다. ‘아이디어 생성’에서는 창의성은 어느 정도 보였지만, 제시된 아이디어가 실제 실험에 적용 가능하거나 구체적인 실행 계획을 포함하지 못했다. ‘건식 실험’에서는 코드 자체는 실행 가능했지만, 실행 결과가 기대와 일치하지 않아 과학적 타당성을 확보하지 못했다. ‘습식 실험’에서는 프로토콜 순서와 재현성 유지가 낮아, 실제 실험실 환경에서 바로 적용하기 어려웠다. 특히 다중모달(텍스트·이미지·표) 비교 추론에서는 모델이 정보를 통합하고 비교하는 능력이 현저히 부족했다.
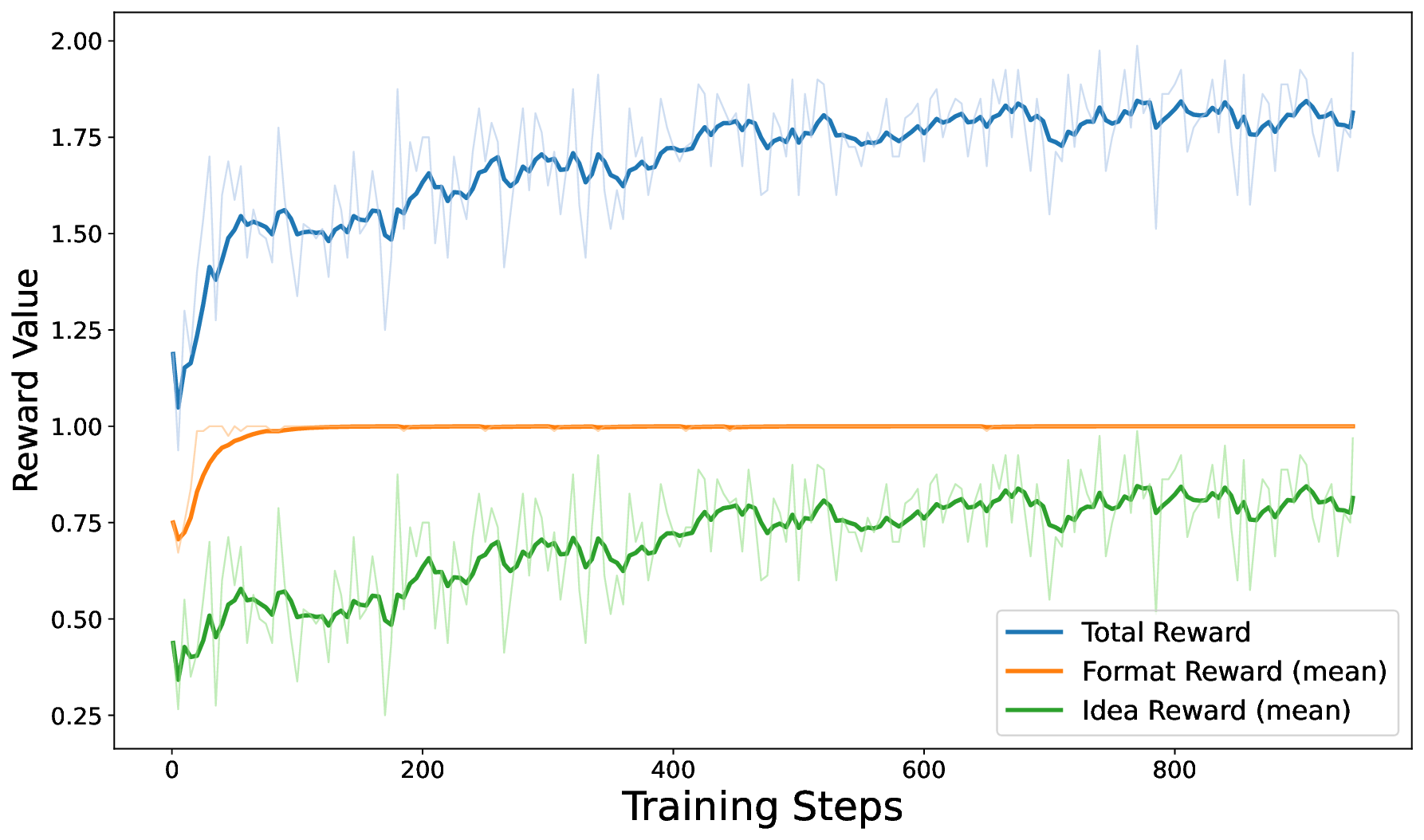
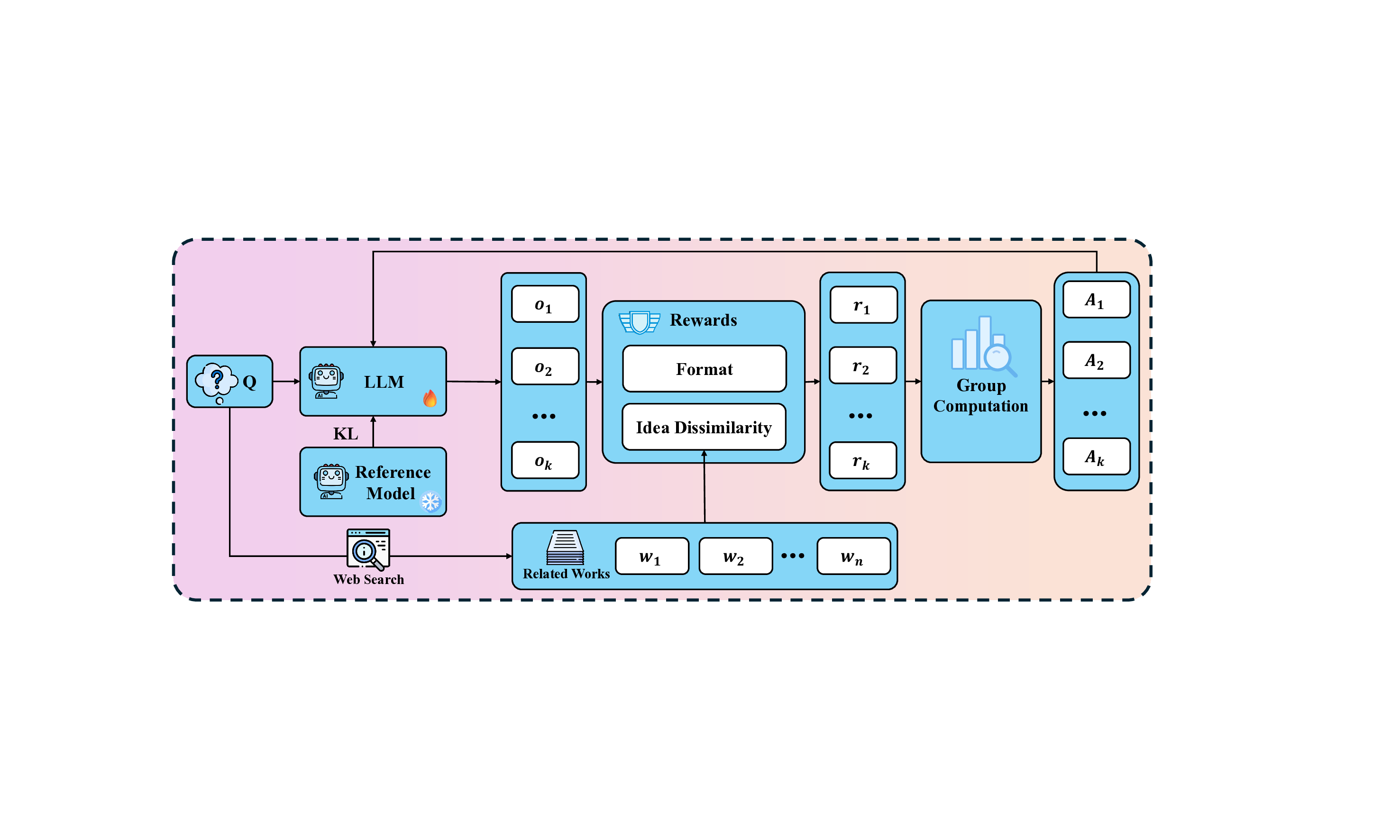
이러한 한계를 극복하기 위해 저자들은 ‘추론 시점 강화학습(Test‑Time Reinforcement Learning, TTRL)’을 제안한다. TTRL은 검색 기반 시스템에 ‘신선도(Novelty)’ 보상을 추가해, 정답이 존재하지 않는 상황에서도 모델이 새로운 가설을 생성하도록 유도한다. 실험에서는 TTRL 적용 후 가설의 참신성 점수가 유의미하게 상승했으며, 이는 기존의 정답 기반 미세조정 방식이 갖는 한계를 보완할 수 있음을 시사한다.
전반적으로 이 논문은 SGI를 정의하고 평가하기 위한 ‘프레임워크·벤치마크·학습 기법’이라는 삼위일체 접근을 제시한다. 앞으로의 연구는 (1) PIM의 각 단계에 특화된 프롬프트 설계와 피드백 메커니즘 개발, (2) 멀티모달 통합 능력 강화, (3) 실제 실험실과의 연계 테스트 등을 통해 SGI 시스템을 점진적으로 고도화해야 할 것이다. 이러한 방향은 AI가 단순히 지식을 제공하는 수준을 넘어, 인간 과학자와 협업하여 새로운 지식을 창출하는 진정한 파트너로 자리매김하는 데 필수적이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리