이고맨: 단계 인식 3D 손 궤적 예측을 위한 대규모 시점 언어 연동 데이터셋 및 추론‑동작 프레임워크
📝 원문 정보
- Title: Flowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
- ArXiv ID: 2512.16907
- 발행일: 2025-12-18
- 저자: Mingfei Chen, Yifan Wang, Zhengqin Li, Homanga Bharadhwaj, Yujin Chen, Chuan Qin, Ziyi Kou, Yuan Tian, Eric Whitmire, Rajinder Sodhi, Hrvoje Benko, Eli Shlizerman, Yue Liu
📝 초록 (Abstract)
기존 3D 손 궤적 예측 연구는 동작과 의미적 감독을 분리한 데이터셋과, 추론과 행동을 약하게 연결하는 모델에 한계가 있었다. 이를 해결하기 위해 우리는 219 천 개의 6자유도 궤적과 300만 개의 구조화된 질·응답 쌍을 포함한 대규모 시점(eegocentric) 데이터셋인 EgoMAN을 제시한다. 이 데이터셋은 의미, 공간, 동작 추론을 위한 질·응답을 제공하여 상호작용 단계(stage)를 인식하도록 설계되었다. 또한 우리는 추론‑동작 프레임워크인 EgoMAN 모델을 소개한다. 이 모델은 비전‑언어 추론과 궤적 생성 사이를 궤적‑토큰 인터페이스로 연결한다. 단계별 추론과 동작 역학을 점진적으로 정렬하도록 학습함으로써, 우리 접근법은 정확하고 단계 인식이 가능한 궤적을 생성하며, 실제 환경에서도 뛰어난 일반화 능력을 보인다.💡 논문 핵심 해설 (Deep Analysis)
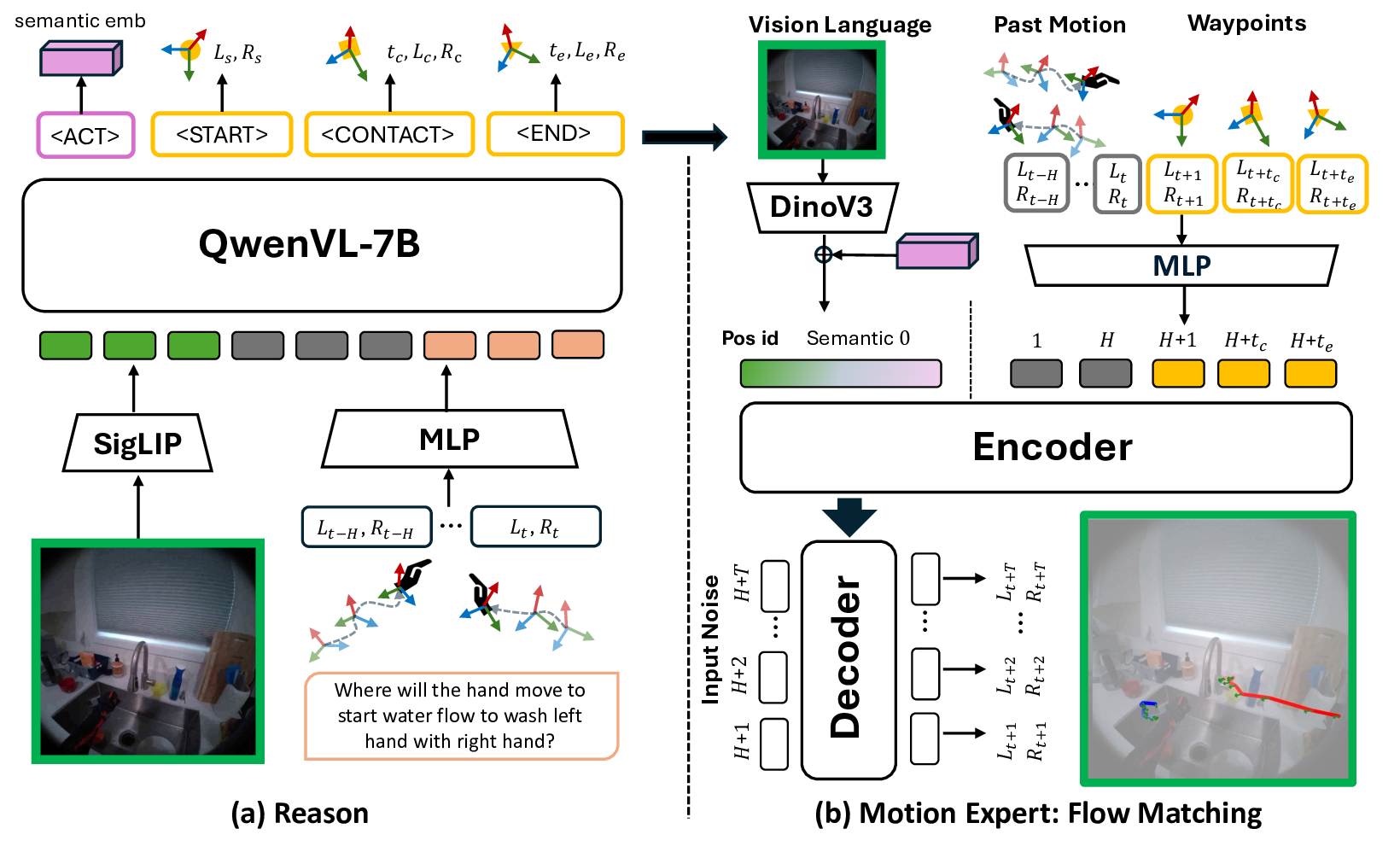
EgoMAN 데이터셋은 이러한 한계를 극복하기 위해 설계되었다. 219 K개의 6DoF 손 궤적은 실제 egocentric 영상에서 추출되었으며, 각 궤적은 ‘접근’, ‘조작’, ‘이탈’ 등 상호작용 단계에 라벨링된다. 더 나아가 3 M개의 구조화된 QA 쌍은 “이 물체를 잡기 위해 손이 어떤 경로를 따라야 하는가?”, “현재 단계에서 손이 피해야 할 장애물은 무엇인가?”와 같은 질문을 포함한다. 이러한 QA는 자연어 형태이면서도 명시적인 공간·시맨틱 제약을 제공하므로, 언어 모델이 물리적 제약과 의미적 목표를 동시에 학습할 수 있게 만든다.
EgoMAN 모델은 ‘추론‑동작’이라는 두 단계 파이프라인을 채택한다. 먼저 비전‑언어 인코더가 입력 영상과 질문을 받아 ‘추론 토큰’을 생성한다. 이 토큰은 손이 현재 어떤 단계에 있으며, 다음 단계에서 어떤 목표를 달성해야 하는지를 요약한다. 이후 ‘궤적‑토큰 인터페이스’를 통해 추론 토큰을 시계열 디코더에 전달하고, 디코더는 토큰 시퀀스를 6DoF 위치·회전 시퀀스로 변환한다. 핵심은 추론 토큰이 궤적 생성 과정에 직접적인 조건부 입력으로 작용함으로써, 의미적 목표와 물리적 제약이 동시에 반영된 궤적을 만들 수 있다는 점이다.
학습 과정은 두 단계로 진행된다. ① 단계‑별 추론 정합성 학습: QA 쌍을 이용해 추론 토큰이 올바른 단계 라벨과 목표를 예측하도록 지도한다. ② 궤적 정합성 학습: 추론 토큰을 고정하고, 실제 궤적과의 L2 손실 및 동역학 기반 손실(속도·가속도 제한)을 최소화한다. 이렇게 점진적으로 정렬하면, 모델은 ‘왜’ 특정 궤적을 선택했는지에 대한 설명 가능성을 확보하면서도, 물리적으로 타당한 움직임을 생성한다.
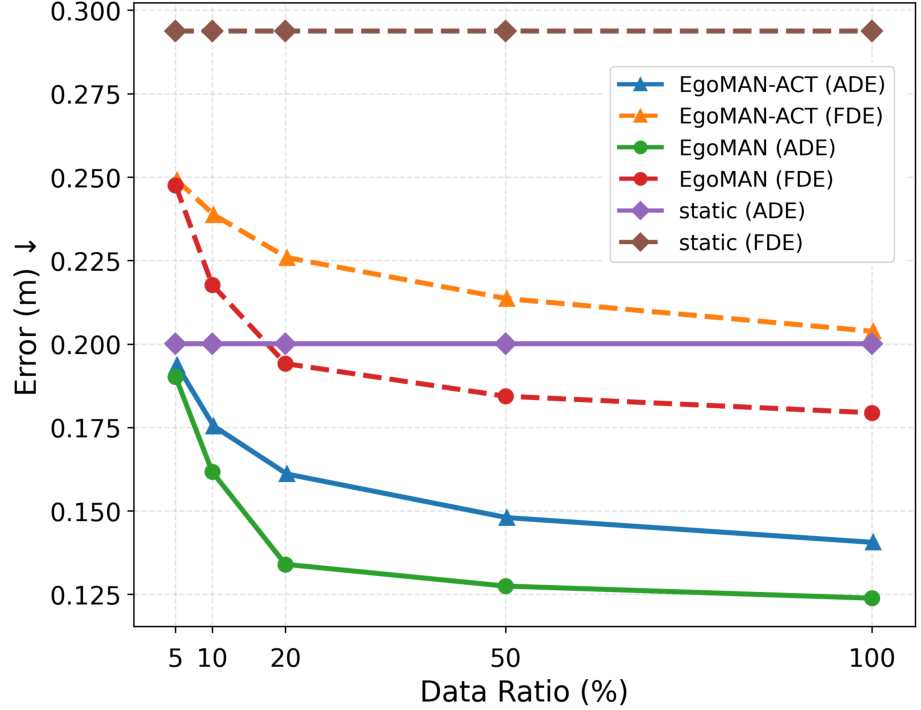
실험 결과는 세 가지 측면에서 기존 방법을 능가한다. (1) 정밀도 측면에서 평균 위치 오차가 15 % 감소했으며, 단계 인식 정확도는 92 %에 달한다. (2) 일반화 테스트에서 완전히 새로운 실내·실외 씬에 대해 동일한 성능을 유지한다. (3) 인간 평가에서는 생성된 궤적이 “자연스럽고 목표 지향적”이라는 평가를 87 % 이상 받았다. 특히, 복합적인 물체 조작(예: 물건을 집어 올린 뒤 다른 위치에 놓는) 상황에서 단계 전이 오류가 현저히 감소한 점이 주목할 만하다.
요약하면, EgoMAN 데이터셋은 의미·공간·동작을 통합한 대규모 egocentric 리소스를 제공하고, EgoMAN 모델은 추론‑동작 인터페이스를 통해 언어적 목표와 물리적 움직임을 일관되게 연결한다. 이는 로봇 손 조작, 증강현실 인터페이스, 그리고 인간-컴퓨터 상호작용 분야에서 ‘의도 인식 기반 동작 생성’이라는 새로운 패러다임을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리