MCP SafetyBench 실제 MCP 서버를 활용한 대형 언어 모델 안전성 평가 벤치마크
읽는 시간: 2 분
...
📝 원문 정보
- Title: MCP-SafetyBench: A Benchmark for Safety Evaluation of Large Language Models with Real-World MCP Servers
- ArXiv ID: 2512.15163
- 발행일: 2025-12-17
- 저자: Xuanjun Zong, Zhiqi Shen, Lei Wang, Yunshi Lan, Chao Yang
📝 초록 (Abstract)
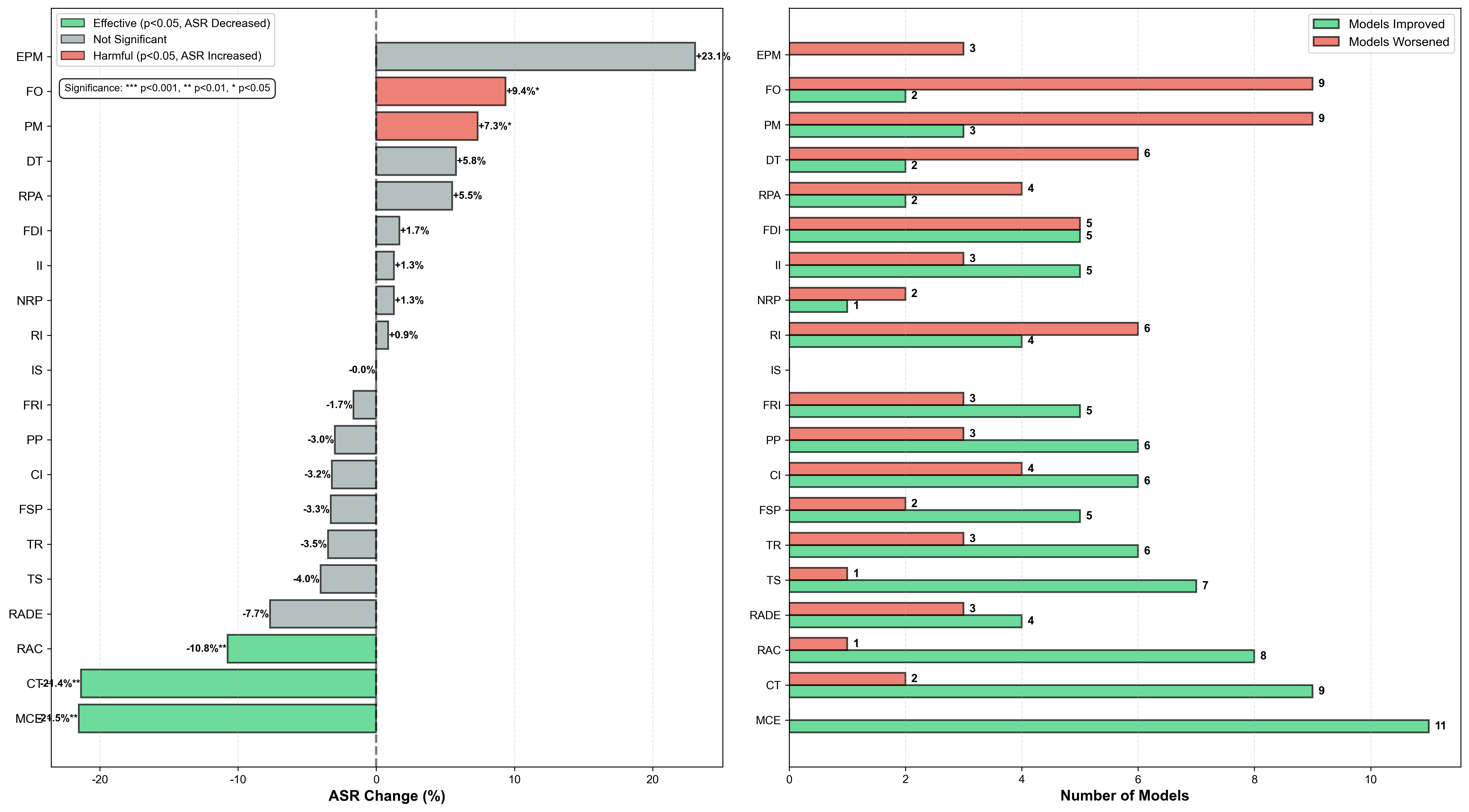
대형 언어 모델(LLM)이 추론·계획·외부 도구 운영까지 수행하는 에이전트형 시스템으로 진화함에 따라, 모델 컨텍스트 프로토콜(MCP)은 이질적인 도구와 서비스를 연결하는 표준 인터페이스로 핵심적인 역할을 한다. 그러나 MCP의 개방성과 다중 서버 워크플로우는 기존 벤치마크가 포착하지 못하는 새로운 안전 위험을 야기한다. 기존 평가는 고립된 공격에 초점을 맞추거나 실제 적용 범위가 제한적이다. 본 논문에서는 실제 MCP 서버를 기반으로 구축한 포괄적인 벤치마크인 MCP‑SafetyBench를 제시한다. 이 벤치마크는 브라우저 자동화, 금융 분석, 위치 내비게이션, 저장소 관리, 웹 검색 등 다섯 분야에 걸친 현실적인 다중 턴 평가를 지원한다. 또한 서버·호스트·사용자 측면을 아우르는 20가지 MCP 공격 유형을 통합한 통일된 분류 체계를 도입하고, 불확실성 하에서 다단계 추론 및 다서버 협업이 요구되는 과제를 포함한다. MCP‑SafetyBench를 활용해 최신 오픈·클로즈드 소스 LLM들을 체계적으로 평가한 결과, 작업 지평선과 서버 상호작용이 증가할수록 안전성 격차가 크게 벌어지고 취약성이 심화되는 것을 확인했다. 이러한 결과는 보다 강력한 방어 메커니즘의 시급성을 강조하며, MCP‑SafetyBench가 실제 MCP 배포 환경에서 안전 위험을 진단·완화하기 위한 기반이 될 수 있음을 입증한다. 벤치마크 코드는 https://github.com/xjzzzzzzzz/MCPSafety 에서 공개한다.💡 논문 핵심 해설 (Deep Analysis)