DreamPRM 코드 함수 단계 프로세스 보상 모델과 라벨 보정
📝 원문 정보
- Title: DreamPRM-Code: Function-as-Step Process Reward Model with Label Correction for LLM Coding
- ArXiv ID: 2512.15000
- 발행일: 2025-12-17
- 저자: Ruiyi Zhang, Peijia Qin, Qi Cao, Pengtao Xie
📝 초록 (Abstract)
프로세스 보상 모델(PRM)은 테스트 시 스케일링을 통해 대형 언어 모델(LLM)을 향상시키는 핵심 기술로 자리 잡았지만, 코드 분야에서는 단계별 분해가 의미 있게 이루어지지 않고 몬테카를로 방식으로 생성된 부분 라벨의 노이즈가 많아 효과가 제한적이었다. 본 연구에서는 함수 자체를 추론 단계로 간주하고, 체인‑오브‑펑션(Chain‑of‑Function) 프롬프트 전략을 적용해 모듈식 코드 생성을 유도함으로써 PRM을 수학적 추론 과제와 유사하게 학습·활용할 수 있는 코딩 전용 PRM인 DreamPRM‑Code를 제안한다. 라벨 노이즈 문제를 해결하기 위해 DreamPRM‑Code는 깨끗한 최종 솔루션 단위 테스트 라벨을 활용하는 메타러닝 기반 보정 메커니즘을 도입하고, 이중 최적화(bi‑level optimization)를 통해 중간 라벨을 정제한다. 테스트‑타임 스케일링에 적용한 결과, DreamPRM‑Code는 LiveCodeBench에서 80.9%의 pass@1을 기록하며 최신 성능을 달성했고, OpenAI o4‑mini를 능가하였다.💡 논문 핵심 해설 (Deep Analysis)
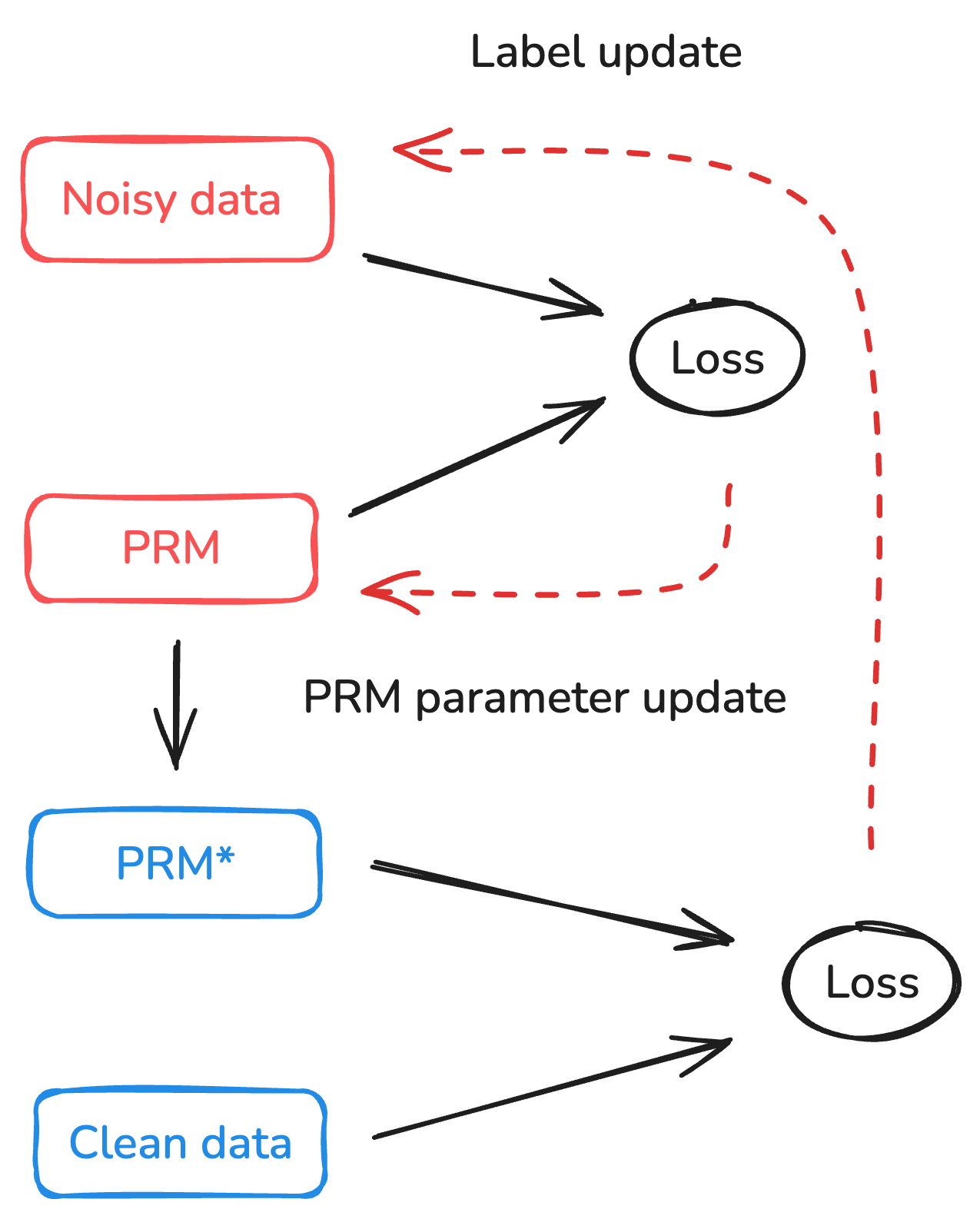
두 번째 문제는 라벨 노이즈이다. 기존 연구에서는 Monte‑Carlo 샘플링을 통해 부분 정답을 생성하고 이를 라벨로 사용했지만, 이러한 라벨은 종종 실제 의도와 어긋나거나 불완전한 경우가 많다. DreamPRM‑Code는 메타러닝 기반의 라벨 보정 메커니즘을 도입한다. 구체적으로, 깨끗한 최종 솔루션에 대한 단위 테스트 결과를 “청정 라벨”로 활용하고, 이 라벨을 상위 목표로 삼아 이중 최적화(바이레벨 최적화)를 수행한다. 외부(상위) 최적화는 최종 테스트 통과율을 최대화하도록 파라미터를 조정하고, 내부(하위) 최적화는 중간 단계 라벨을 해당 상위 목표에 맞게 재조정한다. 이 과정은 EM‑like 알고리즘과 유사하게 라벨을 점진적으로 정제해 나가며, 라벨 노이즈를 크게 감소시킨다.
실험 결과는 설득력 있다. LiveCodeBench라는 대규모 코딩 벤치마크에서 DreamPRM‑Code는 80.9%의 pass@1을 기록했으며, 이는 최신 상용 모델인 OpenAI o4‑mini(약 78% 수준)를 능가한다. 특히 테스트‑타임 스케일링 단계에서 PRM을 적용했을 때 성능 향상이 두드러졌는데, 이는 중간 단계 보상이 전체 코드 품질을 향상시키는 데 기여했음을 시사한다. 또한, 라벨 보정 메커니즘이 없을 경우 성능이 3~5% 포인트 하락하는 것으로 보고되어, 메타러닝 기반 정제의 효과가 실증적으로 입증되었다.
이 논문은 코드 생성 분야에 PRM을 성공적으로 적용한 최초 사례라 할 수 있다. 함수‑단계라는 새로운 추론 단위와 메타러닝 기반 라벨 보정이라는 두 축을 통해, 기존의 “흑백 라벨” 의존성을 탈피하고 보다 정교한 단계별 피드백 루프를 구축했다. 앞으로는 더 복잡한 멀티‑파일 프로젝트나 인터랙티브 코딩 환경에도 이 접근법을 확장할 여지가 크며, PRM과 RLHF를 결합한 하이브리드 학습 프레임워크의 기반이 될 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리