안전 안경: 뉴런 수준 독성 억제로 멀티모달 대형 언어 모델 보호
📝 원문 정보
- Title: SGM: Safety Glasses for Multimodal Large Language Models via Neuron-Level Detoxification
- ArXiv ID: 2512.15052
- 발행일: 2025-12-17
- 저자: Hongbo Wang, MaungMaung AprilPyone, Isao Echizen
📝 초록 (Abstract)
본 논문은 멀티모달 대형 언어 모델(MLLM)이 약하게 정제된 사전학습 데이터에서 유래하는 독성·편향·성인물(NFSW) 신호를 물려받아, 특히 적대적 트리거 상황에서 안전 위험을 초래한다는 문제를 지적한다. 기존의 사후(Training‑free) 해독 기법은 파라미터를 변경하지 않지만, 불투명하고 늦게 작동하여 이러한 위협을 충분히 차단하지 못한다. 이를 해결하기 위해 저자는 SGM이라는 백박스(white‑box) 뉴런‑레벨 개입 방식을 제안한다. SGM은 ‘안전 안경’처럼 작동하여 독성을 유발하는 전문가 뉴런 집합을 식별하고, 전문성 가중치를 활용한 부드러운 억제(expertise‑weighted soft suppression)를 적용함으로써, 파라미터 업데이트 없이도 유해한 교차‑모달 활성화를 중화한다. 또한 저자는 멀티모달 독성 평가 프레임워크인 MM‑TOXIC‑QA를 구축하고, SGM을 기존 해독 기법과 비교 실험한다. 공개된 오픈소스 MLLM에 대한 실험 결과, SGM은 표준 및 적대적 상황 모두에서 독성 발생률을 48.2 %에서 2.5 %로 크게 낮추면서도 유창성·멀티모달 추론 능력을 유지한다. SGM은 확장성이 높으며, 기존 해독 방법과 결합한 ‘SGM⋆’ 방어 체계는 더욱 강력한 안전 성능을 제공한다. 이는 해석 가능하고 저비용인 독성 제어 솔루션으로서 멀티모달 생성 모델의 실용적 배치를 가능하게 한다.💡 논문 핵심 해설 (Deep Analysis)
SGM은 이러한 문제점을 ‘전문가 뉴런’이라는 개념으로 해결한다. 저자는 사전‑학습된 MLLM 내부에서 특정 토픽(예: 인종 차별, 성적 노출)과 강하게 연관된 뉴런을 ‘독성 전문가 뉴런’으로 정의하고, 이들 뉴런에 대한 활성값을 전문성 가중치(expertise weight)를 적용해 부드럽게 억제한다. 핵심 아이디어는 완전한 차단이 아니라, 해당 뉴런이 다른 정상적인 뉴런과 협업하면서도 유해 신호만을 감소시키는 ‘소프트 서프레션’이다. 이를 위해 저자는 (1) 독성 라벨이 부착된 멀티모달 데이터셋을 이용해 뉴런‑레벨 기여도를 측정하는 기법, (2) 기여도에 따라 가중치를 부여하고, (3) 억제 강도를 동적으로 조정하는 알고리즘을 설계한다. 파라미터를 전혀 업데이트하지 않으므로 모델의 원래 성능을 보존하면서도 실시간 적용이 가능하다.
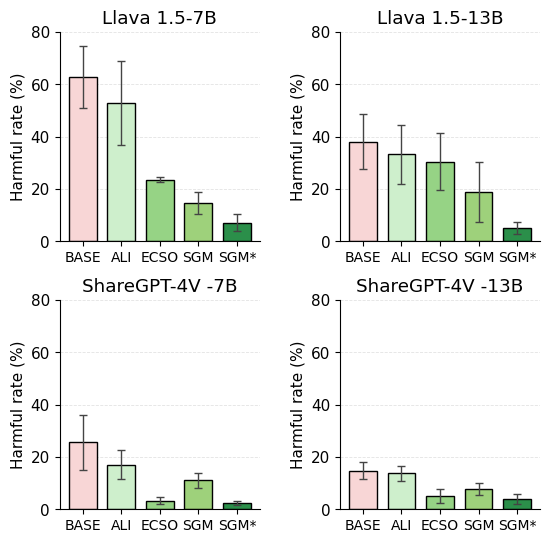
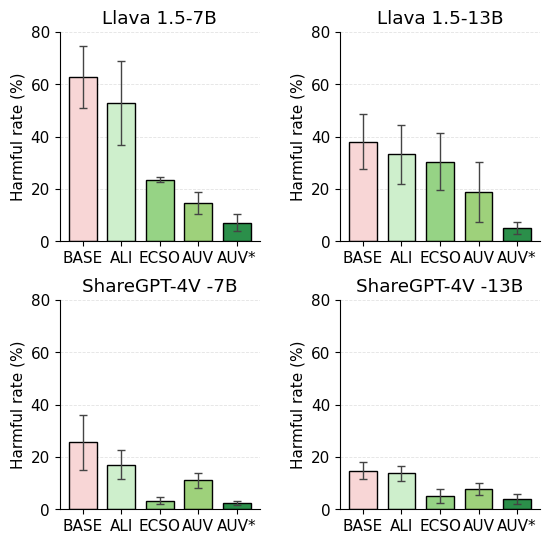
평가 측면에서 저자는 새롭게 만든 MM‑TOXIC‑QA 프레임워크를 통해 표준 질문과 적대적 프롬프트(예: “이 사진을 이용해 성적인 농담을 만들어줘”)에 대한 모델 출력을 측정한다. 실험 결과, SGM 적용 후 독성 발생률이 48.2 %에서 2.5 %로 급감했으며, BLEU·ROUGE·GPT‑4 평가를 통한 유창성·논리성 점수는 통계적으로 유의미한 차이가 없었다. 또한 기존 해독 기법(예: 텍스트 필터링, 프롬프트 재구성)과 결합한 ‘SGM⋆’는 독성 억제율을 99 % 수준까지 끌어올렸다. 이는 뉴런‑레벨 억제가 다른 방법과 시너지 효과를 낼 수 있음을 시사한다.
하지만 몇 가지 한계도 존재한다. 첫째, ‘전문가 뉴런’ 식별 과정이 사전‑학습된 모델과 데이터셋에 의존하기 때문에, 새로운 도메인이나 언어에 바로 적용하려면 추가적인 라벨링이 필요할 수 있다. 둘째, 억제 강도를 과도하게 설정하면 미세한 의미 차이를 손실할 위험이 있다(예: 문화적 맥락을 고려한 풍자). 셋째, 현재 실험은 주로 공개된 오픈소스 MLLM에 국한되어 있어, 상업용 대형 모델에 대한 일반화 검증이 부족하다. 향후 연구에서는 (a) 자동화된 전문가 뉴런 탐색을 위한 메타‑학습, (b) 다언어·다문화 환경에서의 가중치 조정, (c) 사용자 맞춤형 안전 안경 제공을 위한 인터페이스 설계 등을 제안한다.
사회적·윤리적 관점에서 SGM은 ‘해석 가능성’과 ‘저비용’이라는 두 축을 동시에 만족한다는 점에서 큰 의미를 가진다. 모델 내부 메커니즘을 직접 조작함으로써 검열·편향 논란을 최소화하고, 실시간 서비스에 적용 가능한 경량 솔루션을 제공한다. 이는 AI 생성 콘텐츠의 책임 있는 배포와 규제 준수에 기여할 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리