연속 구조 토큰을 활용한 통합 시퀀스·구조 언어 모델 HDProt
읽는 시간: 2 분
...
📝 원문 정보
- Title: HD-Prot: A Protein Language Model for Joint Sequence-Structure Modeling with Continuous Structure Tokens
- ArXiv ID: 2512.15133
- 발행일: 2025-12-17
- 저자: Yi Zhou, Haohao Qu, Yunqing Liu, Shanru Lin, Le Song, Wenqi Fan
📝 초록 (Abstract)
단백질은 서열과 구조가 일관된 이중성을 갖는다. 방대한 서열 데이터는 이산 토큰으로 쉽게 표현될 수 있어 단백질 언어 모델(pLM)의 급속한 발전을 이끌었다. 그러나 연속적인 구조 정보를 효과적으로 통합하는 것은 여전히 과제로 남아 있다. 기존 방법들은 언어 모델 프레임워크에 맞추기 위해 구조를 이산화하는데, 이는 미세한 정보를 손실시키고 다중모달 pLM의 성능을 제한한다. 본 논문에서는 구조를 벡터 양자화 없이 고충실도 연속 잠재공간으로 표현하는 연속 토큰을 도입함으로써 이러한 문제를 해결한다. 구체적으로, 우리는 이산 pLM 위에 연속값 확산 헤드를 얹은 하이브리드 확산 언어 모델 HDProt을 제안한다. 이 모델은 이산 토큰(서열)과 연속 토큰(구조)을 동시에 다루며, 흡수형 확산 과정을 통해 두 모달리티 간의 토큰 의존성을 포착한다. 서열에 대해서는 범주형 예측, 구조에 대해서는 연속 확산을 이용해 토큰별 분포를 추정한다. 광범위한 실험에서 HDProt은 무조건적인 서열·구조 공동 생성, 모티프 스캐폴딩, 구조 예측, 역접힘 등 다양한 과제에서 최첨단 다중모달 pLM에 필적하는 성능을 보였으며, 제한된 연산 자원에서도 경쟁력을 입증하였다. 이는 하나의 언어 모델 아키텍처 안에서 범주형과 연속형 분포를 동시에 추정할 수 있음을 시사한다. 코드와 데이터는 https://github.com/EchoChou990919/hdprot 에서 공개한다.💡 논문 핵심 해설 (Deep Analysis)
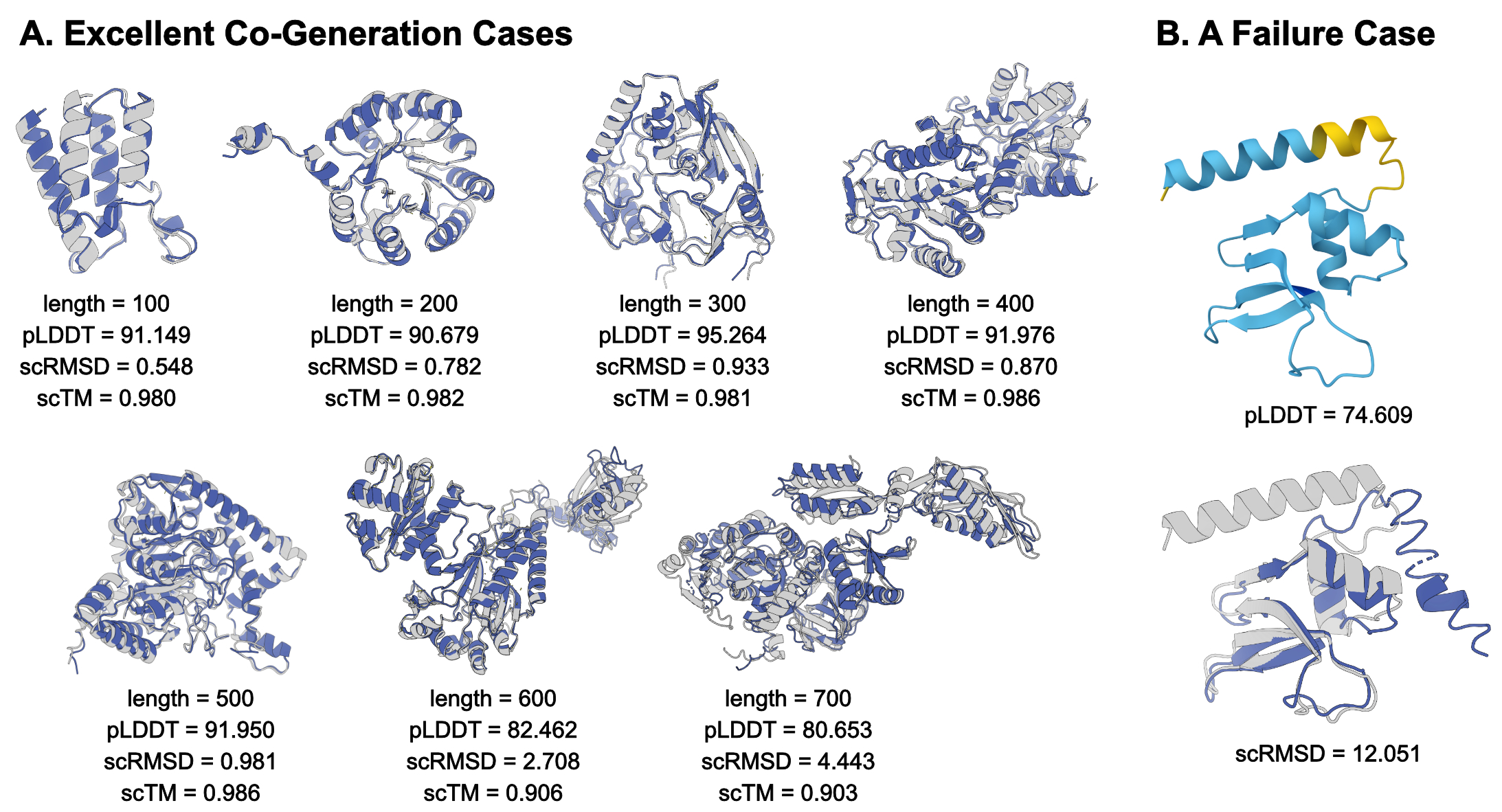
HDProt은 이러한 한계를 피하기 위해 ‘연속 구조 토큰’을 도입한다. 구체적으로, 구조 정보를 고차원 연속 잠재공간에 매핑한 뒤, 이를 확산 모델(diffusion model)의 샘플링 과정에 직접 삽입한다. 확산 …