Title: Evaluating Metrics for Safety with LLM-as-Judges
ArXiv ID: 2512.15617
발행일: 2025-12-17
저자: Kester Clegg, Richard Hawkins, Ibrahim Habli, Tom Lawton
📝 초록 (Abstract)
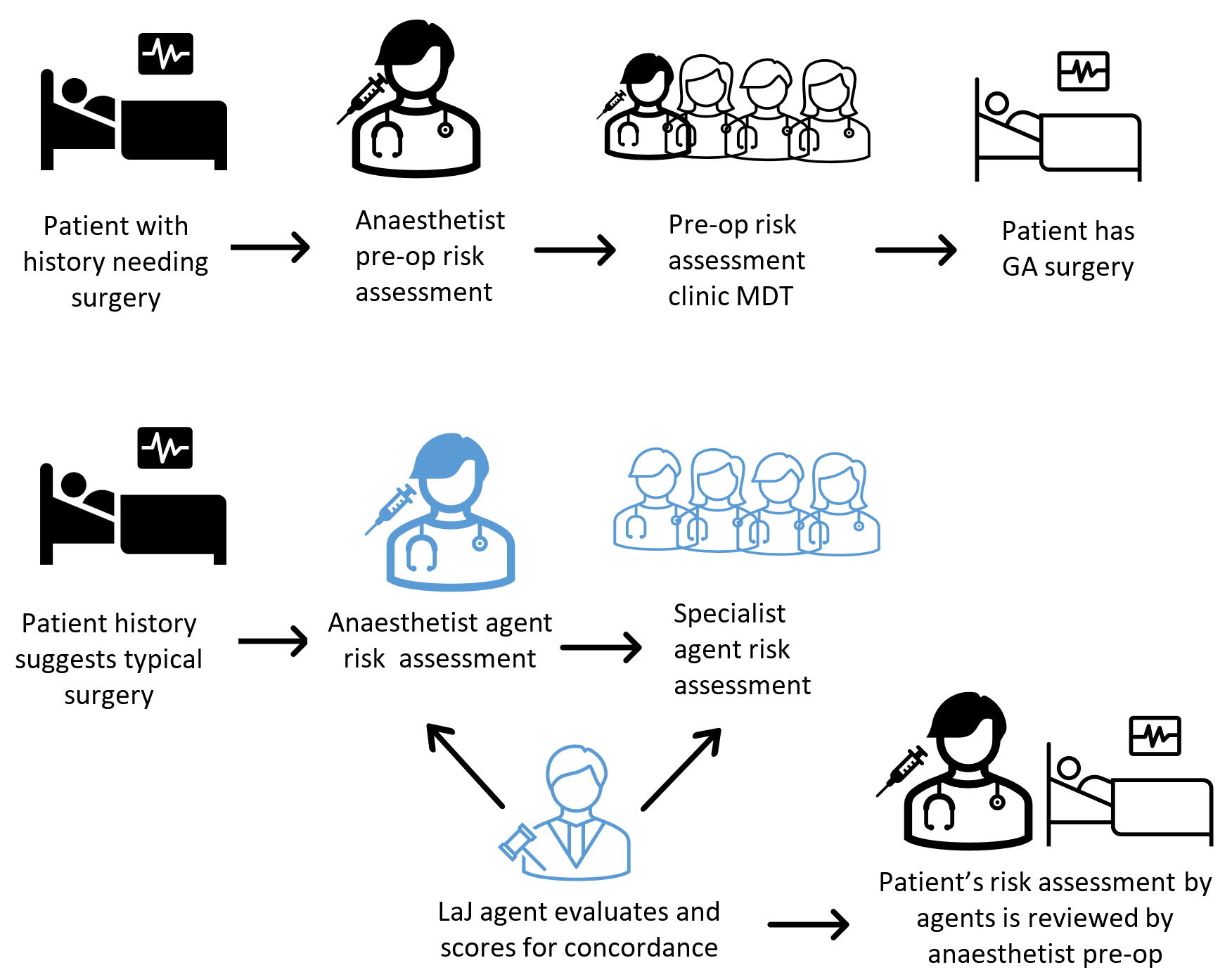
LLM(대형 언어 모델)은 다양한 입력 및 생성 작업에 지능적으로 대응하기 위해 텍스트 처리 파이프라인에 점점 더 많이 활용되고 있다. 이는 인력 부족이나 프로세스 복잡성으로 인해 기존 정보 흐름이 병목 현상을 겪던 인간 역할을 대체할 가능성을 열어준다. 그러나 LLM은 실수를 저지르며, 일부 처리 역할은 안전에 직접적인 영향을 미친다. 예를 들어, 수술 후 환자 관리 triage를 병원 의뢰서 기반으로 수행하거나, 원자력 시설에서 작업팀의 현장 접근 일정을 업데이트하는 경우가 있다. 이러한 안전‑중요 작업에 LLM을 도입하려면 어떻게 안전하고 신뢰할 수 있게 만들 수 있을까? 본 논문은 증강 생성 프레임워크나 그래프 기반 기법에 대한 수행 주장보다는, LLM‑as‑Judge(LaJ) 평가자를 활용한 프로세스에서 얻는 평가 증거의 유형에 초점을 맞춘 안전성 논증이 필요하다고 주장한다. 많은 자연어 처리 과제에서 결정론적 평가를 얻기 어렵지만, 가중된 지표들의 바구니를 채택하고 오류 심각도를 정의하는 컨텍스트 민감성을 활용하며, 평가자 간 일치도가 낮을 때 인간 검토를 트리거하는 신뢰 임계값을 설계함으로써 평가 단계의 오류 위험을 낮출 수 있다.
💡 논문 핵심 해설 (Deep Analysis)
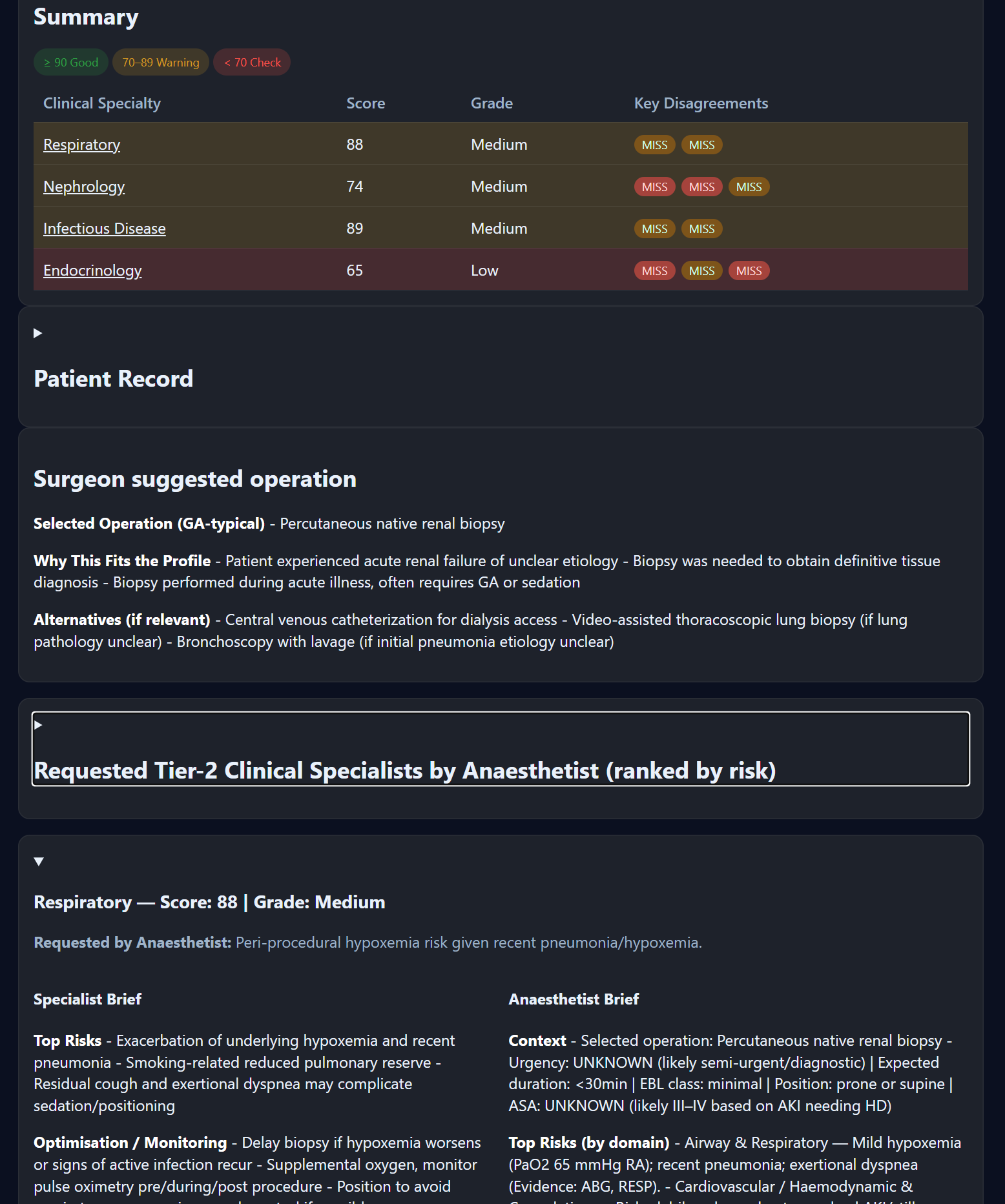
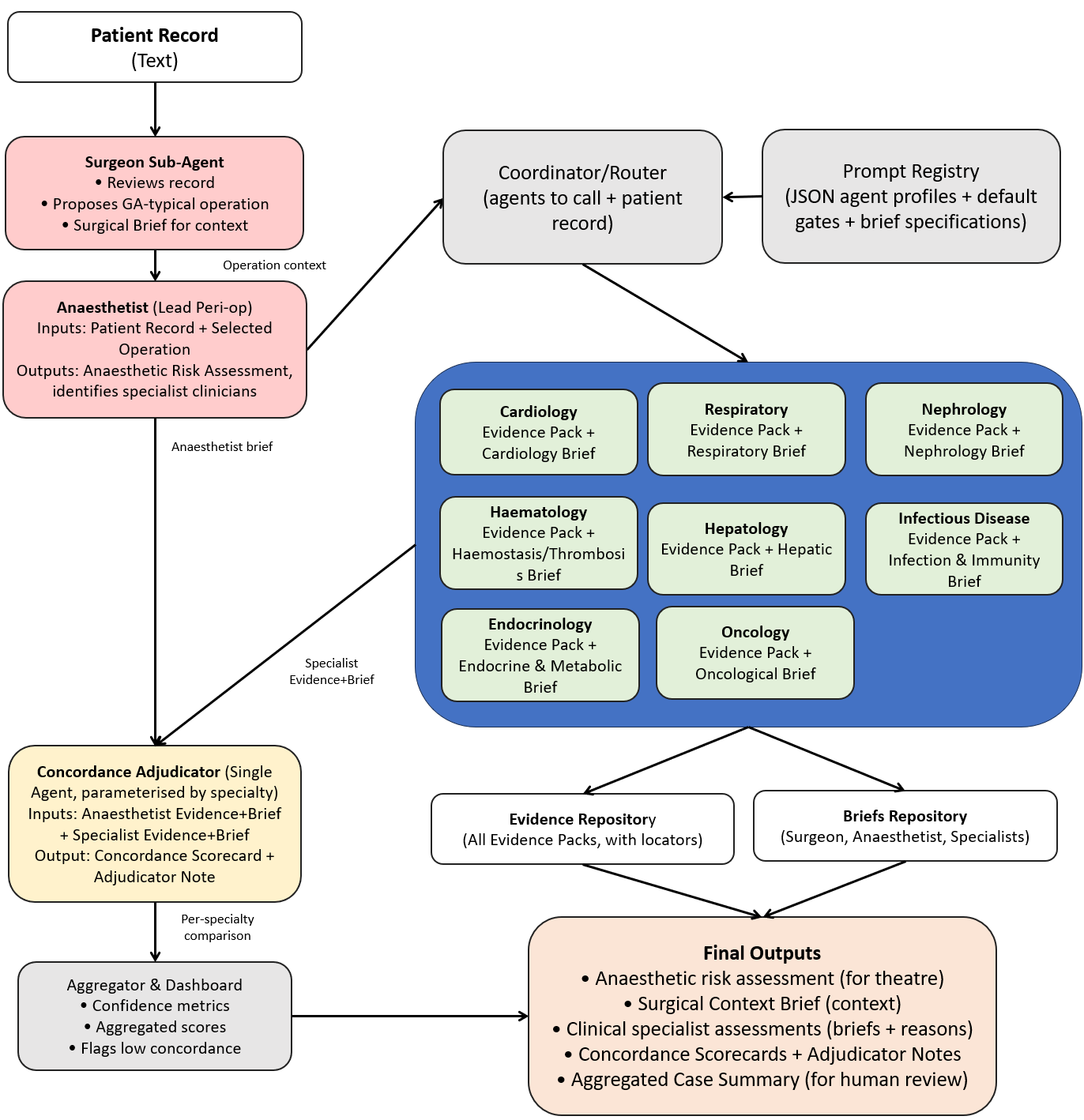
본 논문은 LLM을 인간의 안전‑중요 역할에 대체·보조 도구로 적용하려는 시도에서 가장 핵심적인 문제인 ‘평가 신뢰성’에 초점을 맞춘다. 전통적인 NLP 평가에서는 정확도, F1 점수와 같은 단일 지표가 흔히 사용되지만, 이러한 지표는 모델이 실제 운영 환경에서 발생할 수 있는 복합적인 오류 유형을 포착하는 데 한계가 있다. 특히 의료 triage나 원자력 현장 접근 관리와 같이 오류 하나가 심각한 결과를 초래할 수 있는 도메인에서는, “오류의 심각도”와 “오류 발생 빈도”를 구분하여 평가해야 한다는 점이 강조된다. 논문이 제안하는 ‘가중된 지표 바구니(weighted metric basket)’는 여러 평가 차원을 동시에 고려한다는 점에서 혁신적이다. 예를 들어, 정답 일치율, 컨텍스트 적합성, 위험도 기반 가중치, 그리고 인간 검토 필요성을 예측하는 신뢰 점수 등을 조합함으로써, 단일 지표가 놓칠 수 있는 미묘한 오류를 포착한다. 또한 LaJ 평가자 간의 ‘합의도(concordance)’를 메타‑지표로 활용해, 합의가 낮은 경우 자동으로 인간 검토를 호출하는 ‘신뢰 임계값(threshold)’ 메커니즘을 도입한다. 이는 인간‑기계 협업 시스템에서 흔히 논의되는 ‘human‑in‑the‑loop’ 원칙을 정량적으로 구현한 사례라 할 수 있다. 한편, 논문은 LaJ 자체가 또 다른 LLM이므로, 평가자 간 편향 전이와 오류 증폭 가능성을 인지하고, 다중 모델·다중 프롬프트 전략을 통해 편향을 상쇄하려는 방안을 제시한다. 이러한 접근은 “LLM이 스스로를 평가한다”는 메타‑평가 구조가 갖는 근본적인 불확실성을 최소화하고, 실제 운영 시 위험을 사전에 감지·완화할 수 있는 실용적인 프레임워크를 제공한다. 따라서 본 연구는 LLM을 안전‑중요 시스템에 도입하려는 조직에게, 평가 설계 단계에서부터 위험 관리 원칙을 체계화하는 로드맵을 제시한다는 점에서 큰 의의를 가진다.
📄 논문 본문 발췌 (Translation)
LLM(대형 언어 모델)은 다양한 입력 및 생성 작업에 지능적으로 대응하기 위해 텍스트 처리 파이프라인에 점점 더 많이 활용되고 있다. 이는 인력 부족이나 프로세스 복잡성으로 인해 기존 정보 흐름이 병목 현상을 겪던 인간 역할을 대체할 가능성을 열어준다. 그러나 LLM은 실수를 저지르며, 일부 처리 역할은 안전에 직접적인 영향을 미친다. 예를 들어, 수술 후 환자 관리 triage를 병원 의뢰서 기반으로 수행하거나, 원자력 시설에서 작업팀의 현장 접근 일정을 업데이트하는 경우가 있다. 이러한 안전‑중요 작업에 LLM을 도입하려면 어떻게 안전하고 신뢰할 수 있게 만들 수 있을까? 본 논문은 증강 생성 프레임워크나 그래프 기반 기법에 대한 수행 주장보다는, LLM‑as‑Judge(LaJ) 평가자를 활용한 프로세스에서 얻는 평가 증거의 유형에 초점을 맞춘 안전성 논증이 필요하다고 주장한다. 많은 자연어 처리 과제에서 결정론적 평가를 얻기 어렵지만, 가중된 지표들의 바구니를 채택하고 오류 심각도를 정의하는 컨텍스트 민감성을 활용하며, 평가자 간 일치도가 낮을 때 인간 검토를 트리거하는 신뢰 임계값을 설계함으로써 평가 단계의 오류 위험을 낮출 수 있다.