과학 발견을 위한 대형 언어 모델 평가: 시나리오‑기반 다중‑수준 벤치마크
📝 원문 정보
- Title: Evaluating Large Language Models in Scientific Discovery
- ArXiv ID: 2512.15567
- 발행일: 2025-12-17
- 저자: Zhangde Song, Jieyu Lu, Yuanqi Du, Botao Yu, Thomas M. Pruyn, Yue Huang, Kehan Guo, Xiuzhe Luo, Yuanhao Qu, Yi Qu, Yinkai Wang, Haorui Wang, Jeff Guo, Jingru Gan, Parshin Shojaee, Di Luo, Andres M Bran, Gen Li, Qiyuan Zhao, Shao-Xiong Lennon Luo, Yuxuan Zhang, Xiang Zou, Wanru Zhao, Yifan F. Zhang, Wucheng Zhang, Shunan Zheng, Saiyang Zhang, Sartaaj Takrim Khan, Mahyar Rajabi-Kochi, Samantha Paradi-Maropakis, Tony Baltoiu, Fengyu Xie, Tianyang Chen, Kexin Huang, Weiliang Luo, Meijing Fang, Xin Yang, Lixue Cheng, Jiajun He, Soha Hassoun, Xiangliang Zhang, Wei Wang, Chandan K. Reddy, Chao Zhang, Zhiling Zheng, Mengdi Wang, Le Cong, Carla P. Gomes, Chang-Yu Hsieh, Aditya Nandy, Philippe Schwaller, Heather J. Kulik, Haojun Jia, Huan Sun, Seyed Mohamad Moosavi, Chenru Duan
📝 초록 (Abstract)
대형 언어 모델(LLM)이 과학 연구에 점점 더 많이 활용되고 있지만, 기존 과학 벤치마크는 맥락이 없는 지식만을 시험하고 과학적 발견을 이끄는 반복적 추론, 가설 생성, 관찰 해석 등을 간과한다. 본 연구는 생물학, 화학, 재료 과학, 물리학 분야의 실제 연구 프로젝트를 전문가가 정의하고, 이를 모듈식 연구 시나리오로 분해한 뒤 검증된 질문을 샘플링하는 시나리오‑기반 벤치마크를 제안한다. 평가 프레임워크는 (i) 시나리오와 연결된 질문 수준의 정확도와 (ii) 프로젝트 수준의 성과—즉 모델이 검증 가능한 가설을 제시하고, 시뮬레이션·실험을 설계·실행하며, 결과를 해석해 가설을 재정립하는 능력—두 단계로 구성된다. 최신 LLM들을 이 두‑단계 과학 발견 평가(SDE) 프레임워크에 적용한 결과, 일반 과학 벤치마크 대비 일관된 성능 격차가 나타났으며, 모델 규모와 추론 능력의 확대가 수익 감소를 보였다. 또한 서로 다른 제공업체의 최상위 모델들 사이에 공통적인 약점이 드러났다. 연구 시나리오마다 성능 변동이 커서, 과학 발견 프로젝트별 최적 모델 선택이 달라지는 등 현재 LLM들은 아직 일반적인 과학 “초지능”과는 거리가 멀다. 그럼에도 불구하고, 개별 시나리오 점수가 낮아도 전체 프로젝트에서는 의미 있는 성과를 보이는 경우가 있어, 가이드된 탐색과 우연성(serendipity)의 역할을 강조한다. SDE 프레임워크는 과학 발견과 직접 연관된 재현 가능한 벤치마크를 제공하며, 문제 정의, 데이터 다양화, 도구 활용 학습, 과학적 추론을 위한 강화학습 등 LLM 개발을 과학 발견 지향으로 전환하기 위한 실용적인 로드맵을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
논문에서 제시한 두 단계 평가—질문‑레벨 정확도와 프로젝트‑레벨 성과—는 서로 보완적인 역할을 한다. 질문‑레벨 평가는 기존 벤치마크와 직접 비교가 가능해, 모델 규모·학습 데이터·추론 기법이 “기본 과학 지식”에 미치는 영향을 정량화한다. 반면 프로젝트‑레벨 평가는 LLM을 ‘과학적 파트너’로서 실제 연구 흐름에 투입했을 때 나타나는 종합적인 성공률을 측정한다. 여기서 중요한 점은 모델이 가설을 제시하고, 시뮬레이션·실험을 설계·실행하고, 결과를 해석해 가설을 수정하는 전 과정을 자동화한다는 것이다. 이는 현재 대부분의 LLM 연구가 “정답 맞추기”에 머무는 것과는 근본적으로 다른 접근이다.
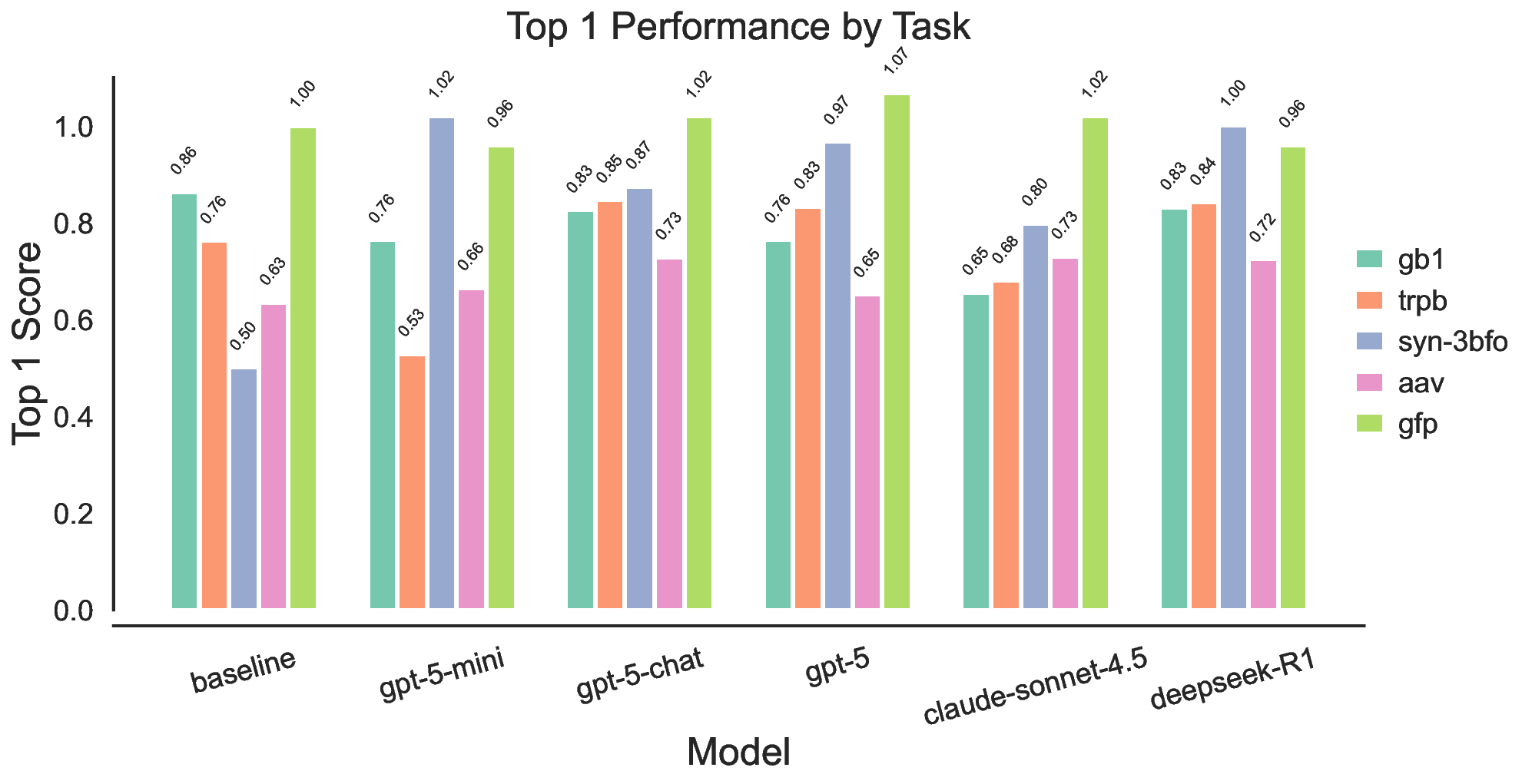
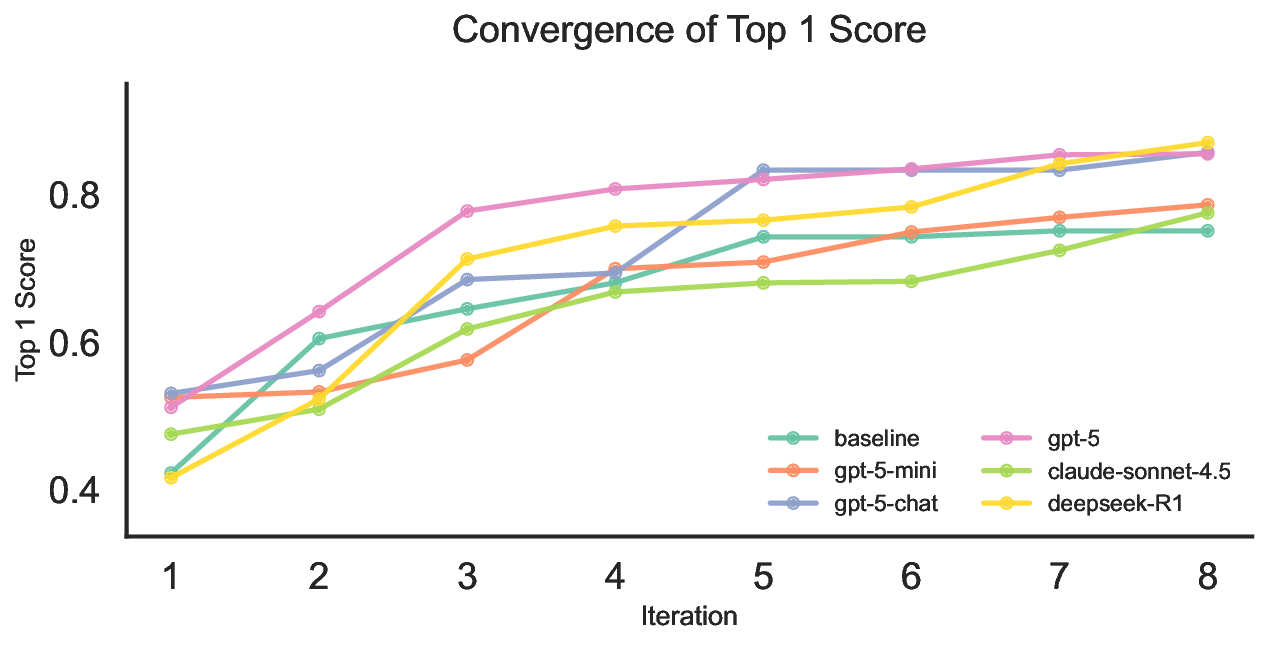
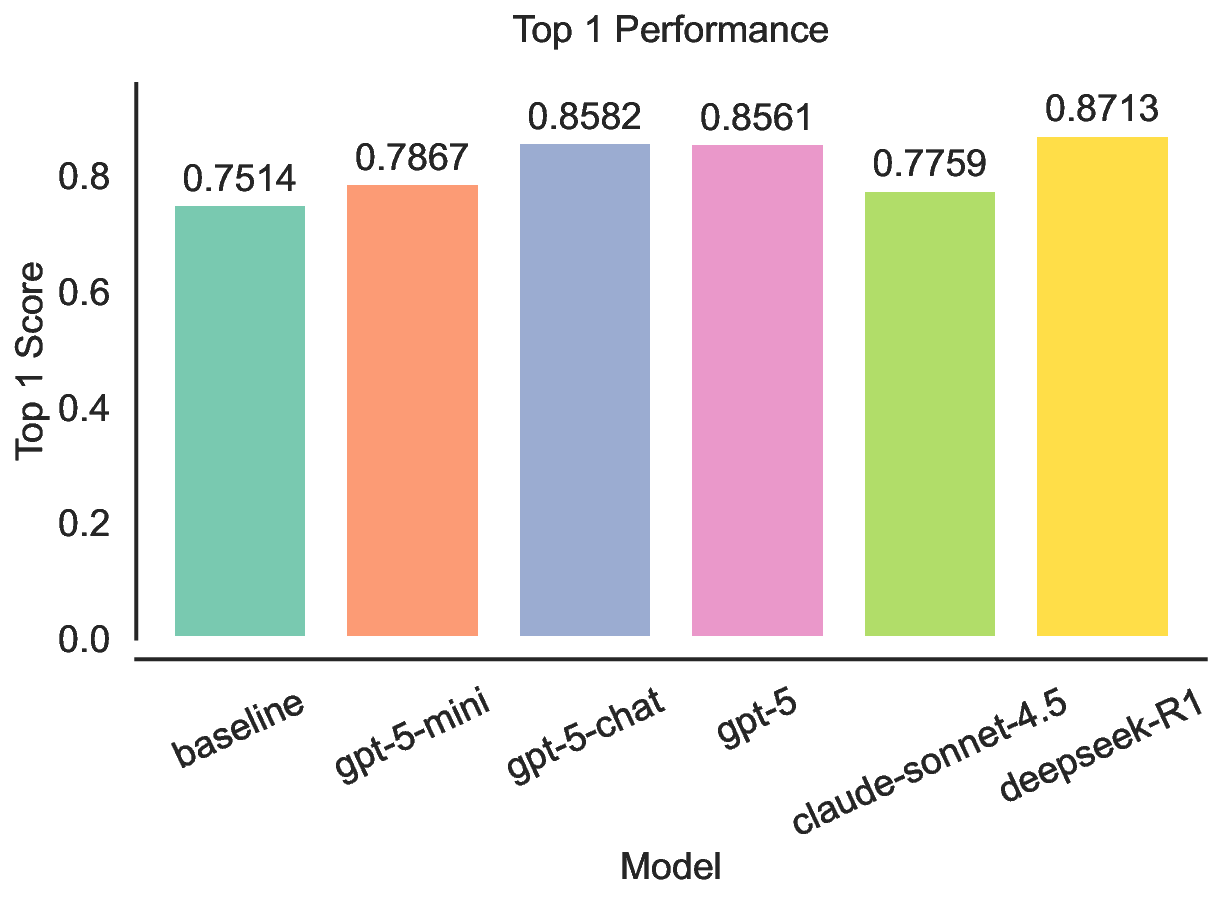
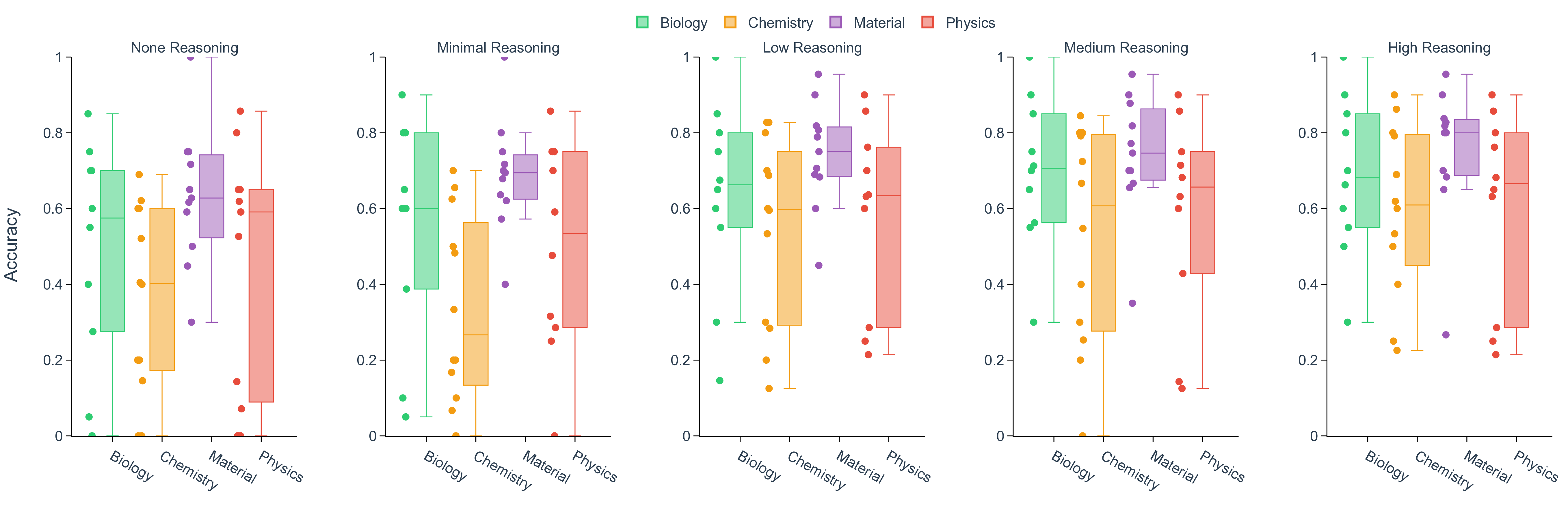
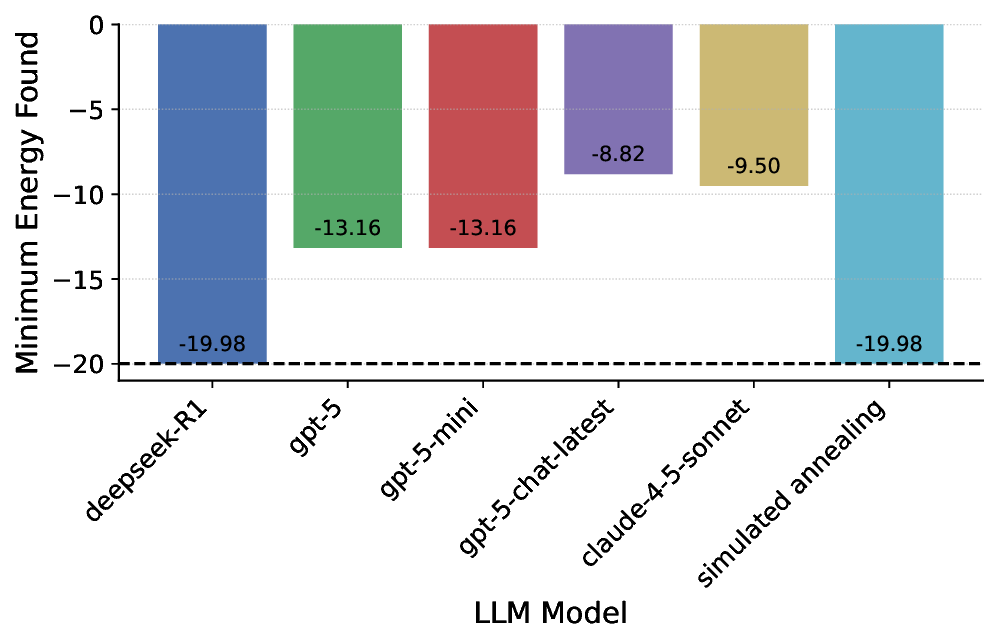
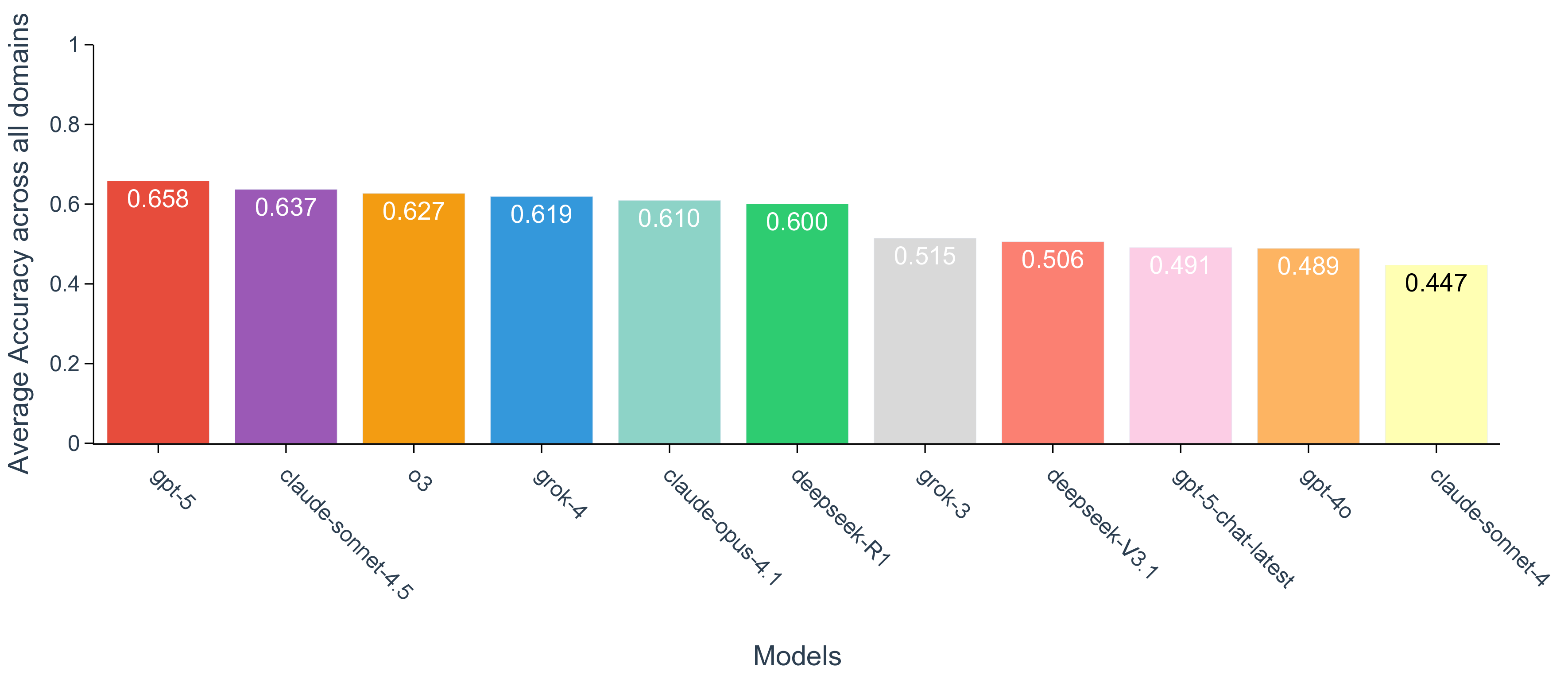
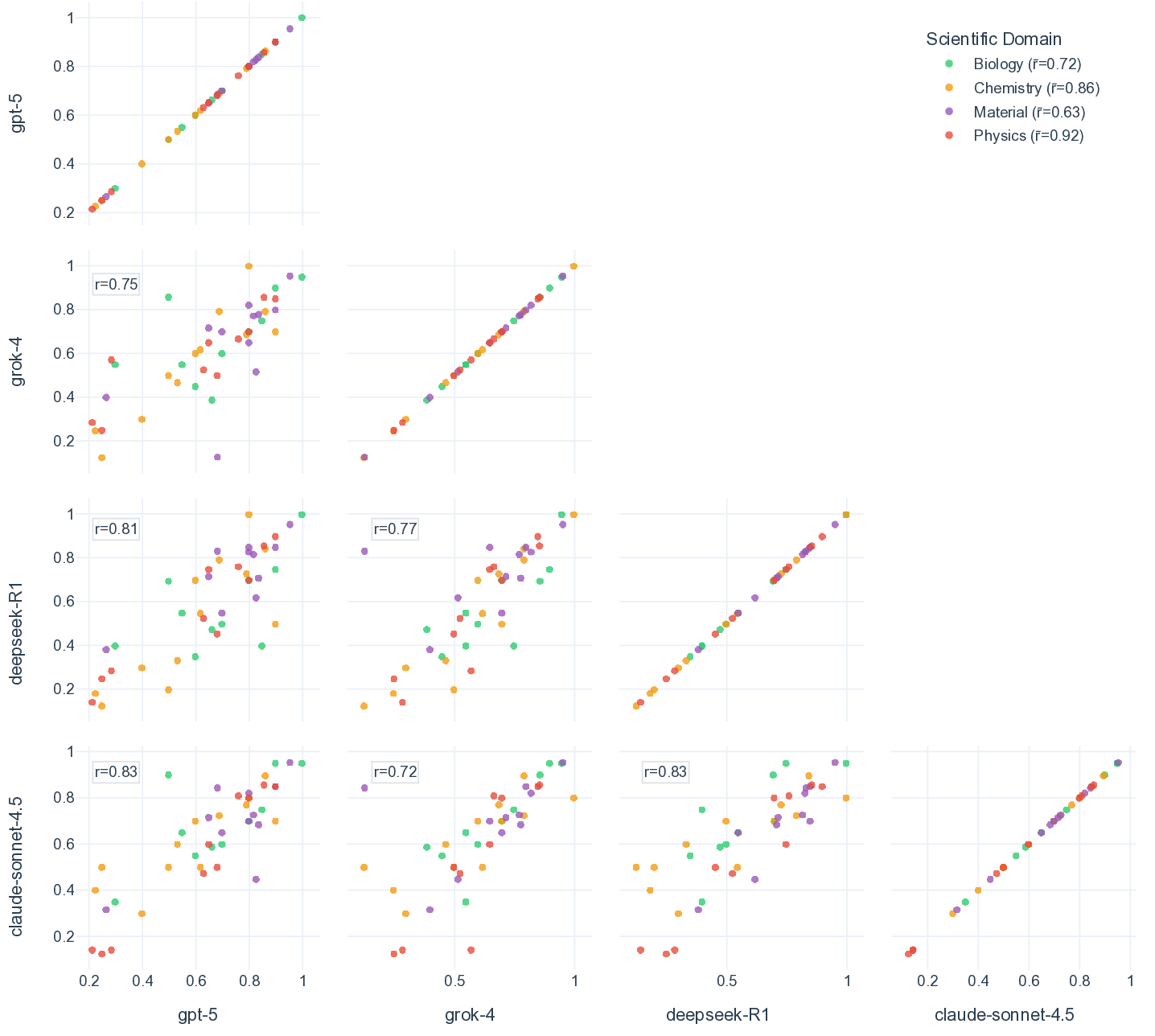
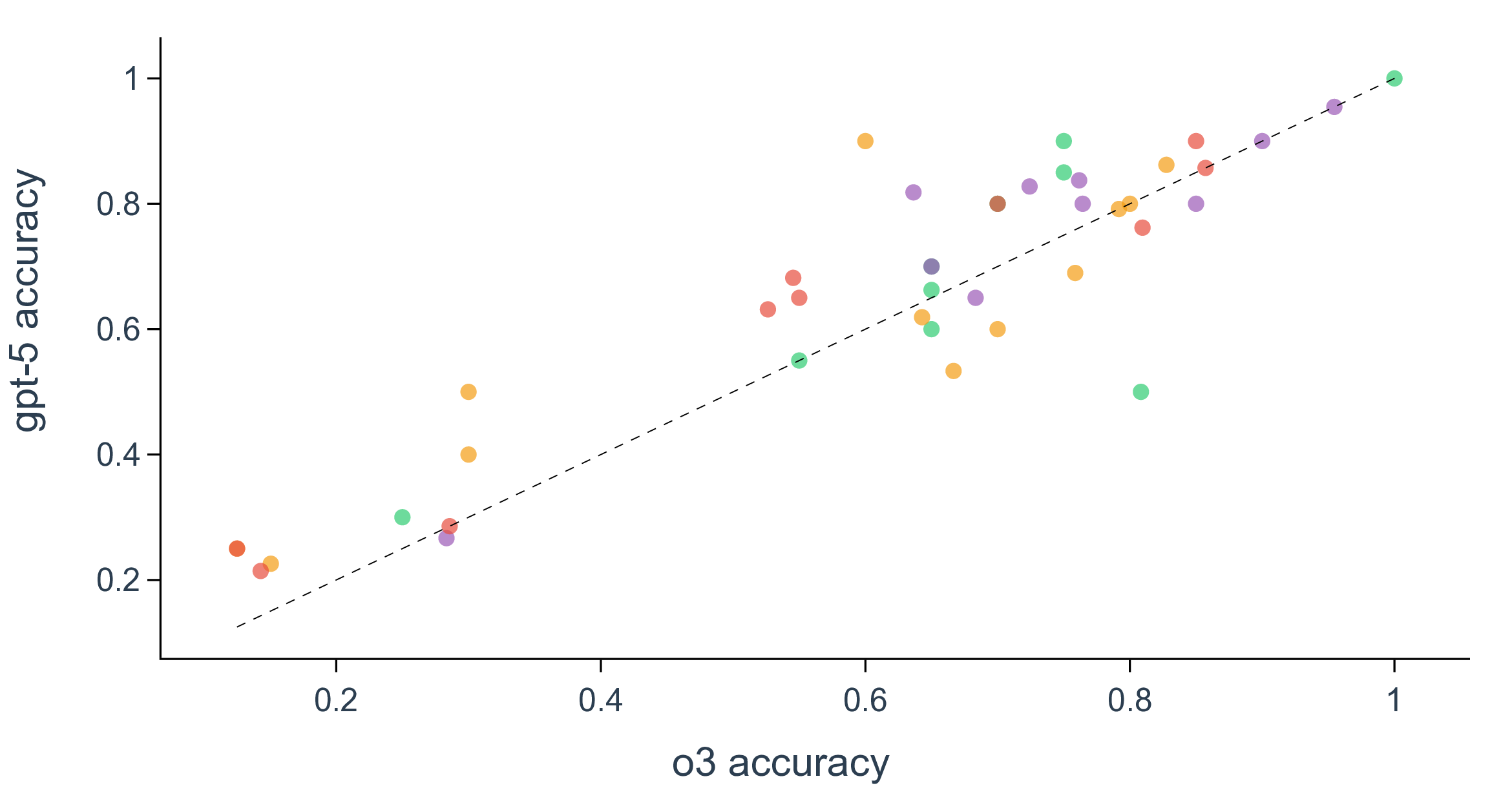
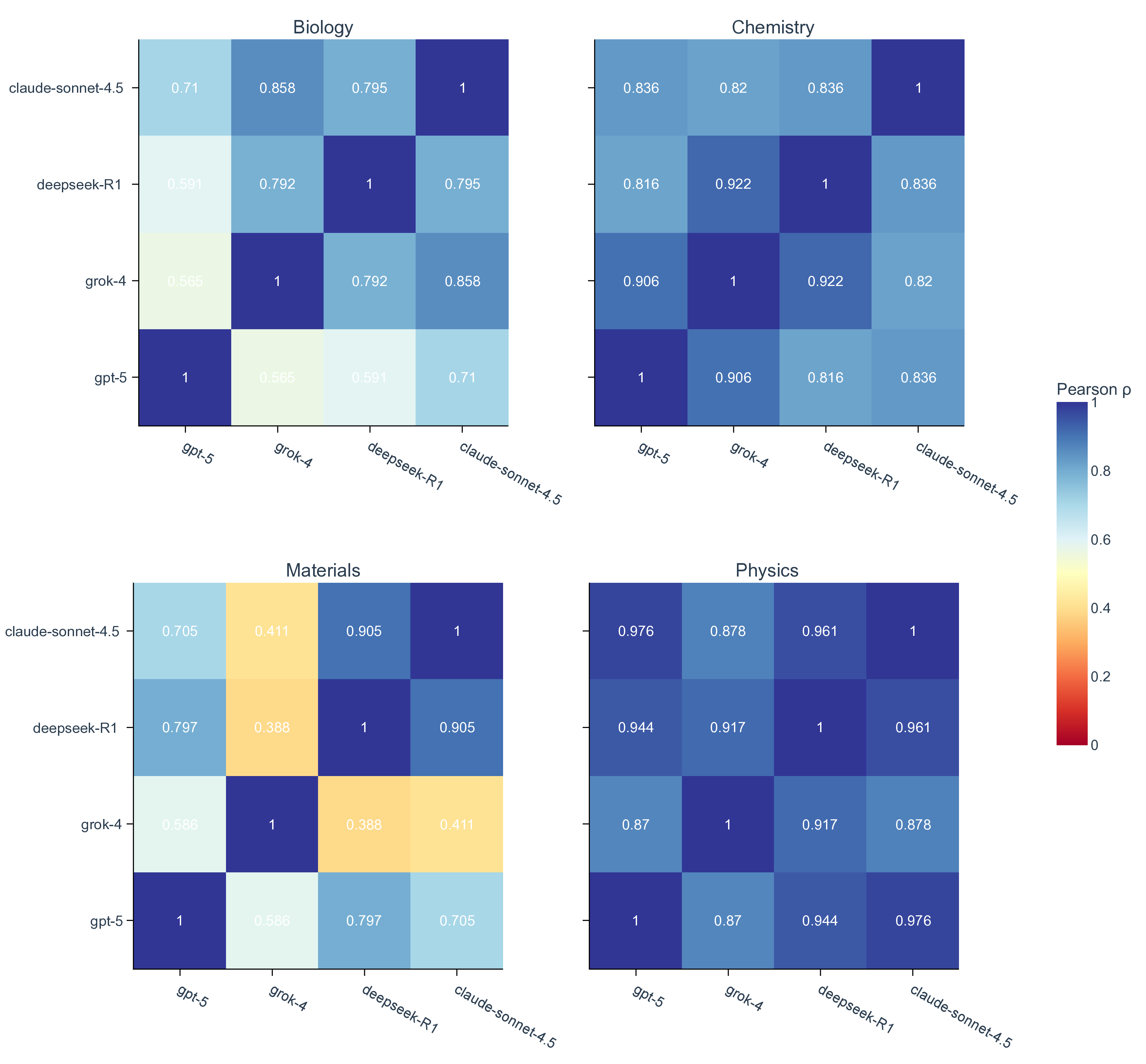
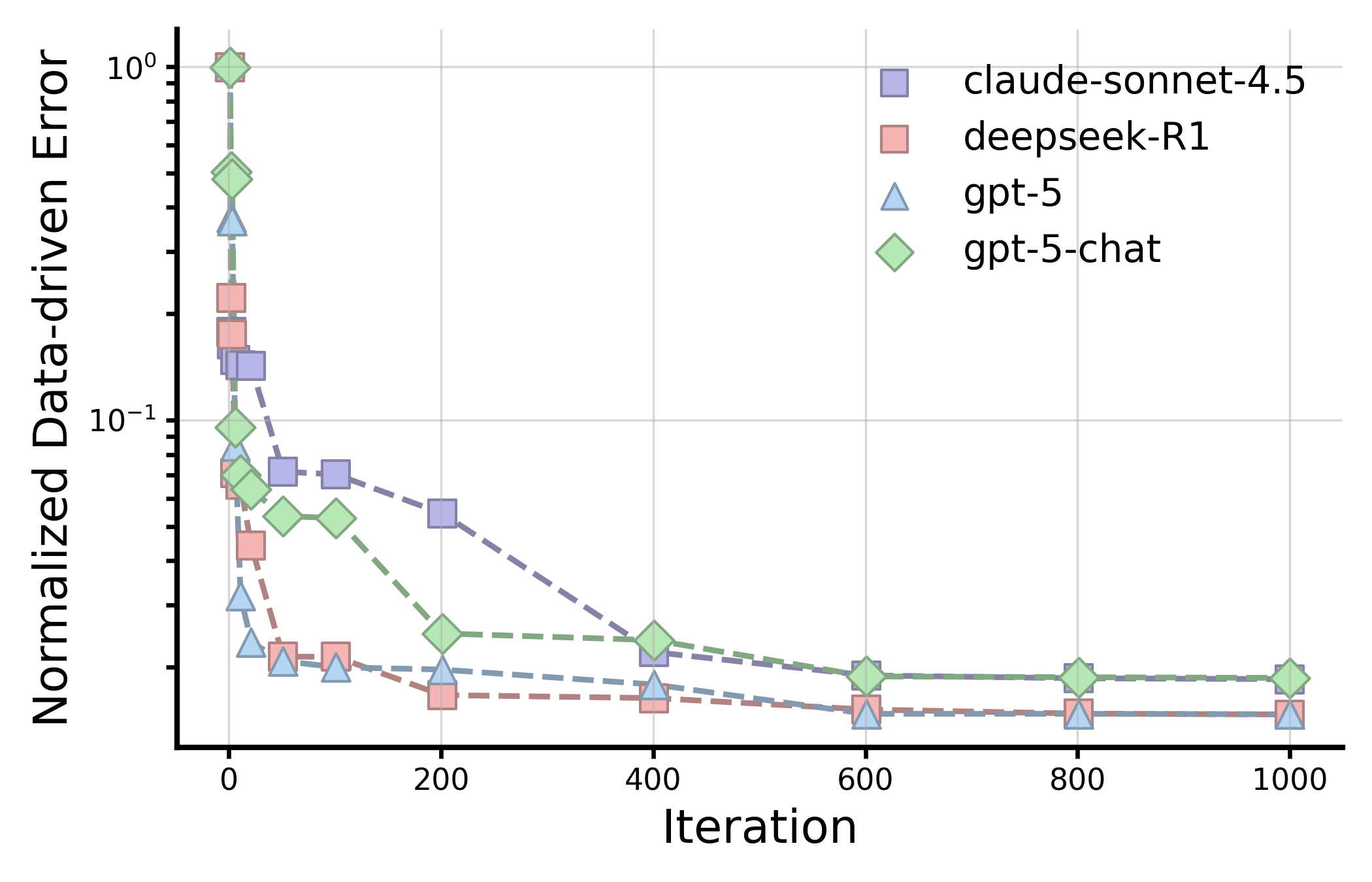
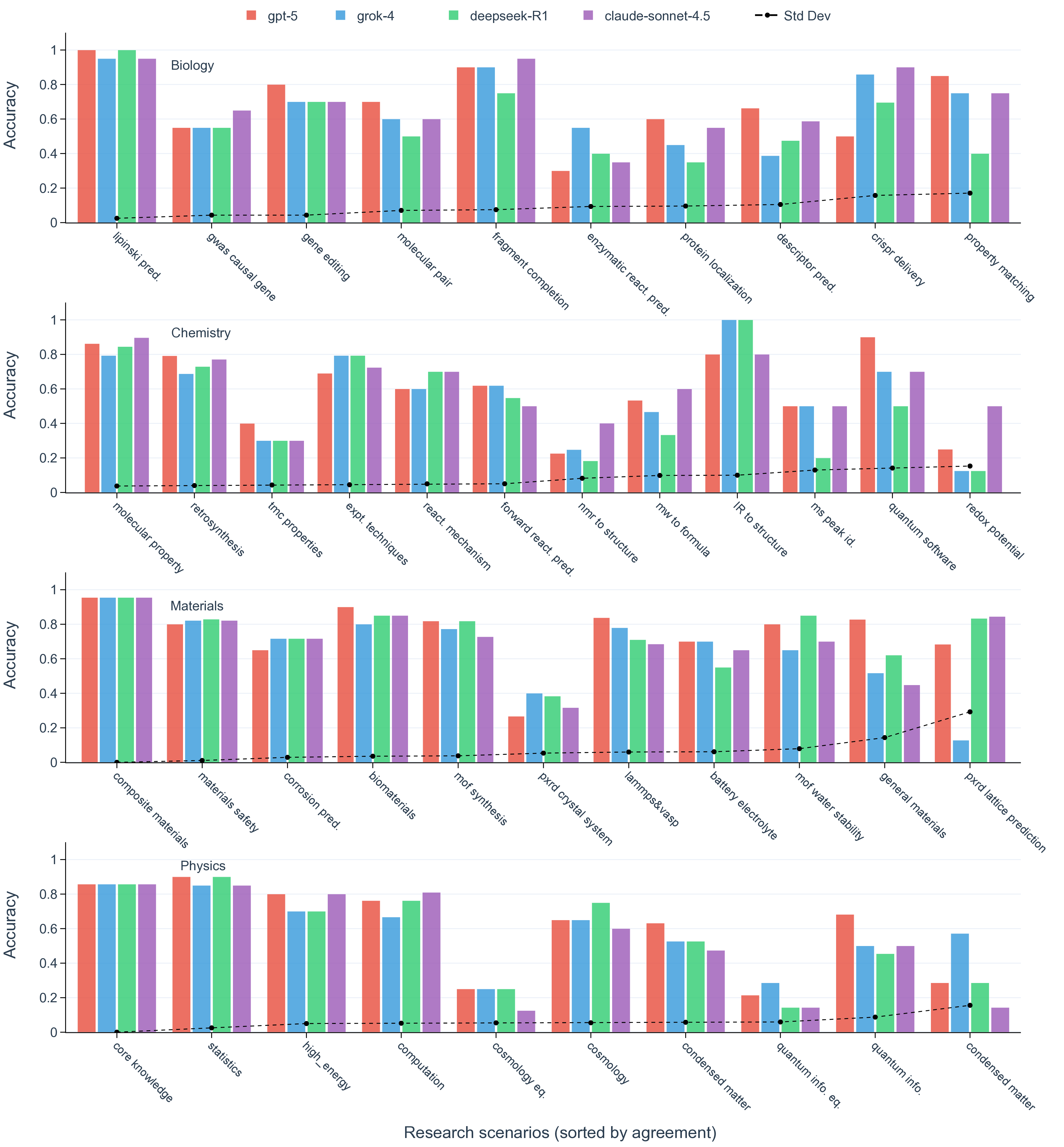
실험 결과는 몇 가지 핵심 인사이트를 제공한다. 첫째, 최신 모델들(gpt‑5, Claude‑sonnet‑4.5, Grok‑4 등)이 일반 과학 퀴즈에서는 높은 정확도를 보이지만, 시나리오‑연계 질문에서는 여전히 60~80% 수준에 머물러 있다. 이는 모델이 ‘맥락 없는 지식’은 잘 활용하지만, ‘연구 맥락’과 ‘다단계 추론’이 요구되는 상황에서는 한계가 있음을 의미한다. 둘째, 모델 규모를 키우거나 체인‑오브‑생각(Chain‑of‑Thought) 같은 추론 기법을 적용해도 성능 향상이 점점 감소한다(수익 감소 현상). 이는 단순히 파라미터를 늘리는 전략만으로는 과학적 발견 능력을 크게 끌어올릴 수 없다는 경고이다. 셋째, 서로 다른 제공업체의 최상위 모델들 사이에 공통된 약점—예를 들어, 복합 물질의 전자 구조 해석, 실험 설계 시 변수 선택 오류, 시뮬레이션 결과의 통계적 해석 부족—이 발견되었다. 이는 현재 LLM 개발이 데이터와 아키텍처 중심으로 진행되는 반면, ‘과학적 방법론’ 자체를 학습시키는 체계가 부족함을 시사한다.
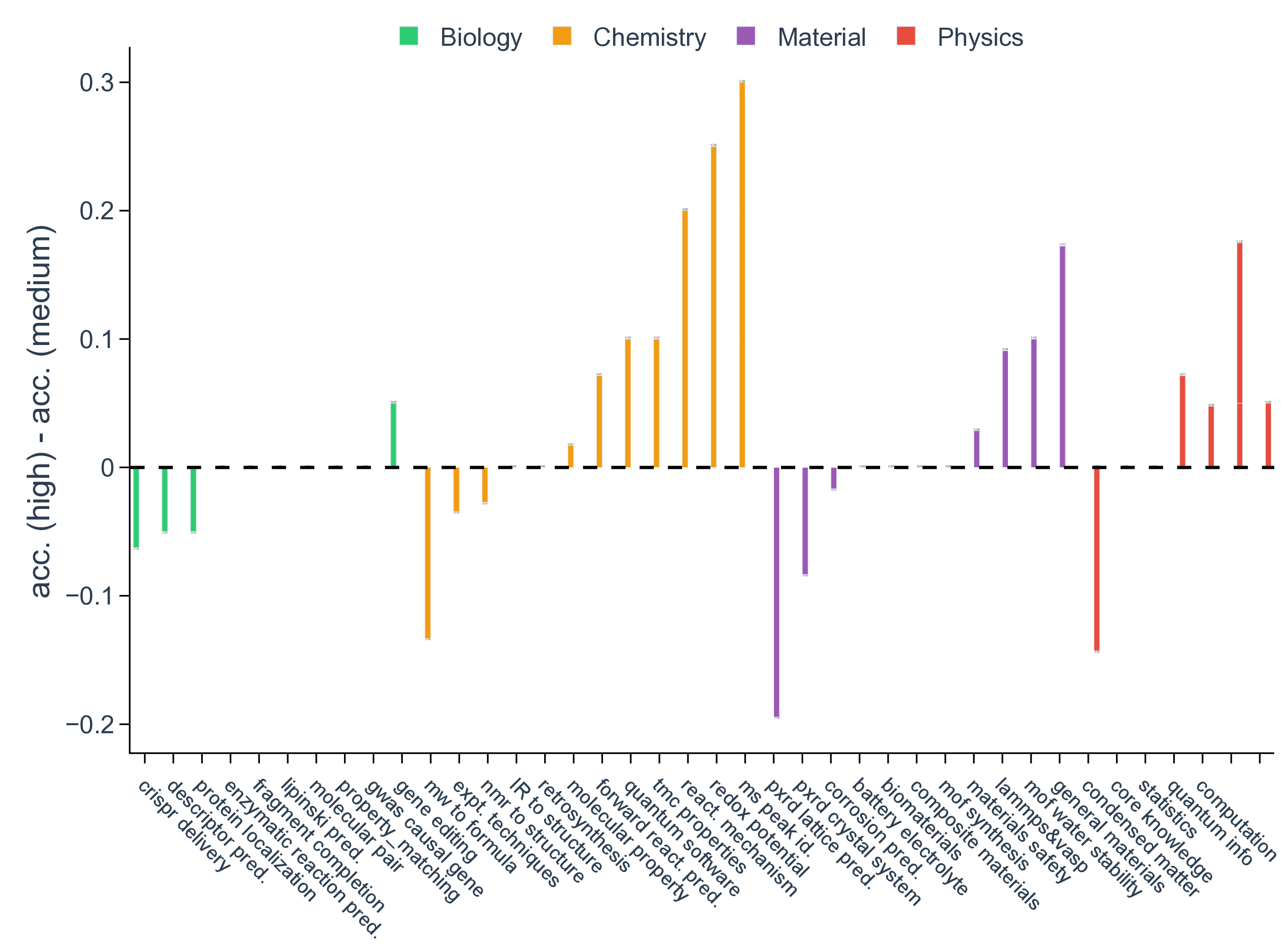
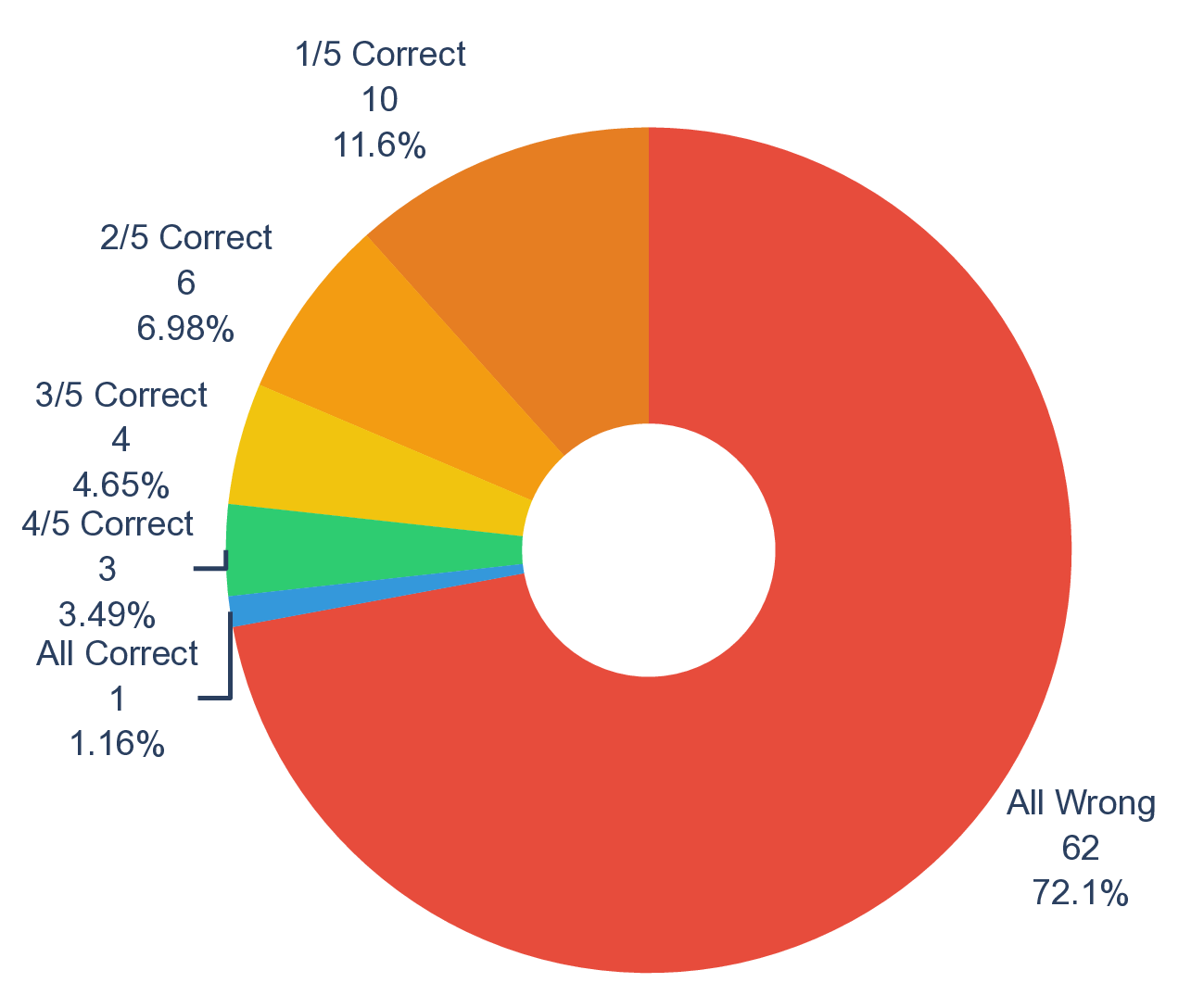
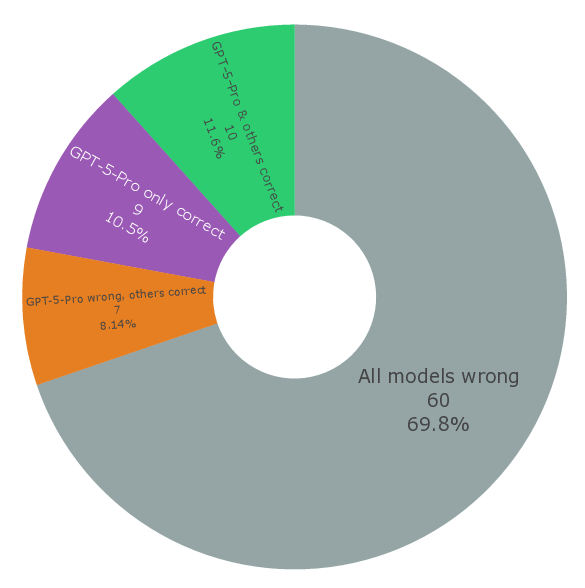
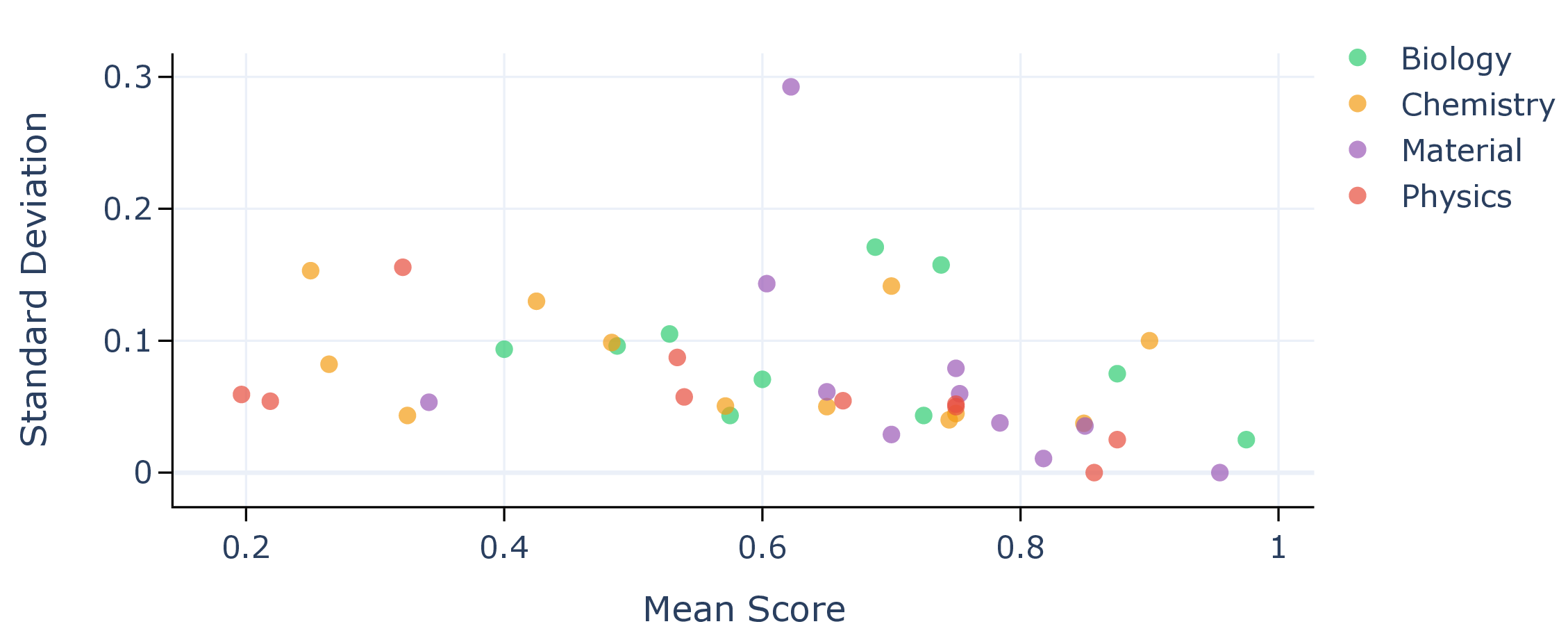
또한, 시나리오별 성능 변동이 크다는 점은 “모델 선택”이 프로젝트 특성에 따라 달라져야 함을 보여준다. 어떤 프로젝트에서는 낮은 질문‑레벨 점수에도 불구하고 전체 흐름에서 의미 있는 가설을 도출하거나, 예상치 못한 실험 아이디어를 제시하는 경우가 있었다. 이는 인간 연구자가 ‘우연히(serendipity)’ 새로운 아이디어를 얻는 과정과 유사하며, LLM이 완전 자동화된 탐색보다 인간과의 협업을 통해 더 큰 가치를 창출할 수 있음을 암시한다.
마지막으로, 저자들은 향후 연구 로드맵을 네 가지 축으로 제시한다. (1) 문제 정의와 가설 생성에 특화된 데이터셋 구축, (2) 실험·시뮬레이션 도구와의 통합을 통한 멀티모달 학습, (3) 과학적 추론을 강화하는 RLHF(Reinforcement Learning from Human Feedback) 전략, (4) 다양한 분야·데이터 소스를 포괄하는 ‘데이터 다양화’ 정책이다. 이러한 제안은 현재 LLM이 “지식 저장소”를 넘어 “과학적 사고 파트너”로 진화하기 위한 구체적인 방향을 제시한다.
요약하면, 이 논문은 LLM을 과학적 발견에 적용하기 위한 평가 패러다임을 근본적으로 재정의하고, 현재 모델들의 한계와 향후 발전 경로를 명확히 제시한다. 연구자와 기업이 LLM을 실제 연구에 도입하려는 경우, 단순히 질문‑정답 정확도만 보는 것이 아니라, 프로젝트‑수준의 전체 파이프라인 성능을 검증하는 SDE 프레임워크를 채택하는 것이 필수적이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리