폴리퍼소나 설문 응답 생성을 위한 페르소나 기반 대형언어모델
📝 원문 정보
- Title: Polypersona: Persona-Grounded LLM for Synthetic Survey Responses
- ArXiv ID: 2512.14562
- 발행일: 2025-12-16
- 저자: Tejaswani Dash, Dinesh Karri, Anudeep Vurity, Gautam Datla, Tazeem Ahmad, Saima Rafi, Rohith Tangudu
📝 초록 (Abstract)
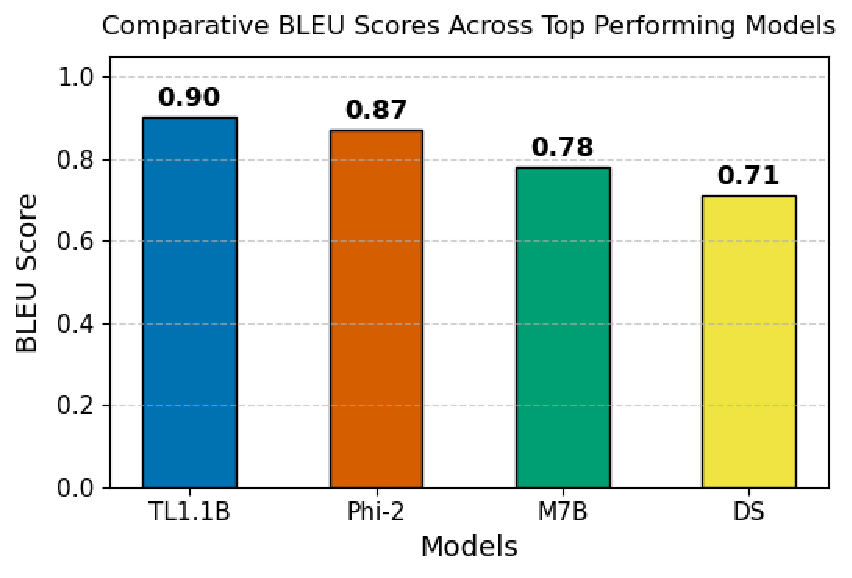
본 논문은 페르소나 조건부 언어 모델을 구현하여 다양한 분야에 걸친 현실적인 설문 응답을 합성하는 생성 프레임워크인 PolyPersona를 제안한다. 이 프레임워크는 파라미터 효율적인 LoRA 어댑터와 4비트 양자화를 활용해 소형 챗 모델을 지시 튜닝하며, 자원 적응형 학습 설정을 적용한다. 페르소나 단서를 보존해 일관된 행동 정렬을 유지하도록 설계된 대화 형식 데이터 파이프라인을 구축하였다. 결과 데이터셋은 10개 도메인에 걸쳐 3,568개의 응답과 433개의 고유 페르소나를 포함하며, 통제된 지시 튜닝 및 체계적인 다중 도메인 평가를 가능하게 한다. BLEU, ROUGE, BERTScore와 설문 특화 구조·스타일·감성 일관성을 측정하는 메트릭을 통합한 다중 평가 스택을 사용하였다. 실험 결과 TinyLlama 1.1B와 Phi‑2와 같은 소형 모델이 7B‑8B 대형 베이스라인과 동등한 성능을 달성했으며(최고 BLEU 0.090, ROUGE‑1 0.429), 소형 아키텍처에 페르소나 조건부 미세조정을 적용하면 효율성이 크게 향상됨을 확인하였다. 페르소나 기반 소형 모델은 합성 설문 데이터를 생성하는 데 신뢰할 수 있고 효율적이며, 편향 모니터링 및 재현성을 보장하는 공개 프로토콜을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
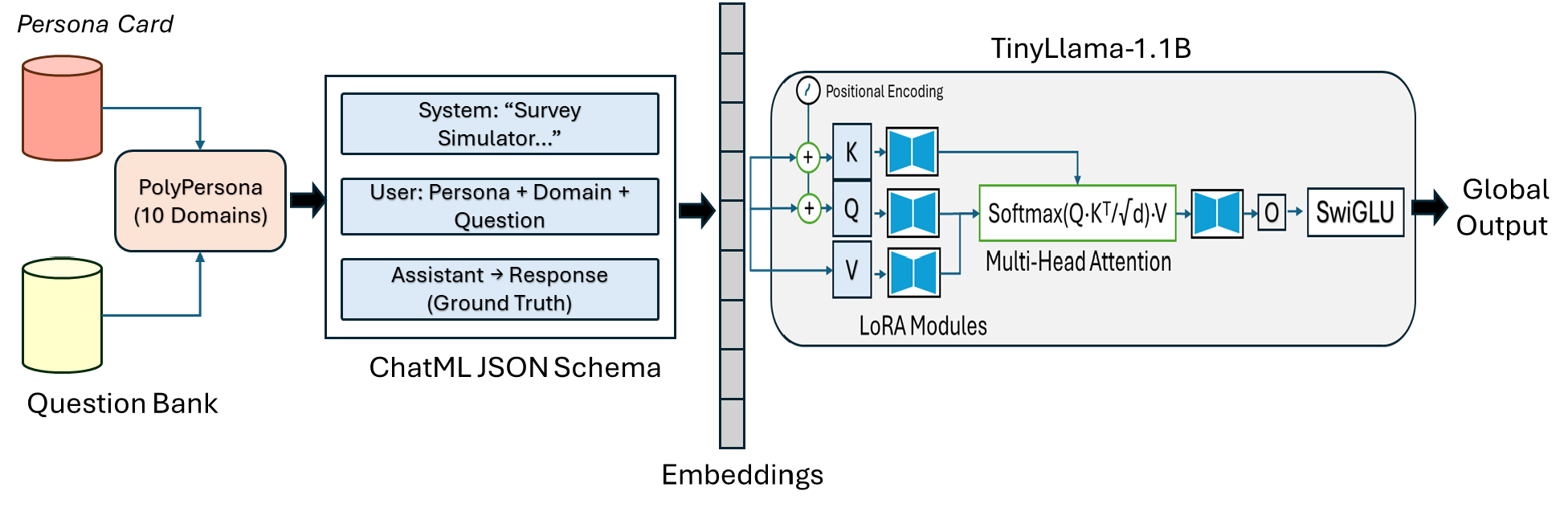
학습 측면에서는 LoRA( Low‑Rank Adaptation) 어댑터와 4‑bit 양자화를 결합해 파라미터 효율성을 극대화했다. LoRA는 기존 모델의 가중치를 고정하고 소수의 저차원 매트릭스만 학습함으로써 메모리와 연산 비용을 크게 절감한다. 4‑bit 양자화는 추가적인 메모리 절감 효과를 제공하면서도 성능 저하를 최소화한다는 점에서 실용적이다. 특히 ‘자원‑적응형’ 학습 스케줄을 도입해 GPU 메모리 한계가 있는 연구실에서도 1‑2 B 파라미터 규모의 모델을 효과적으로 튜닝할 수 있게 했다.
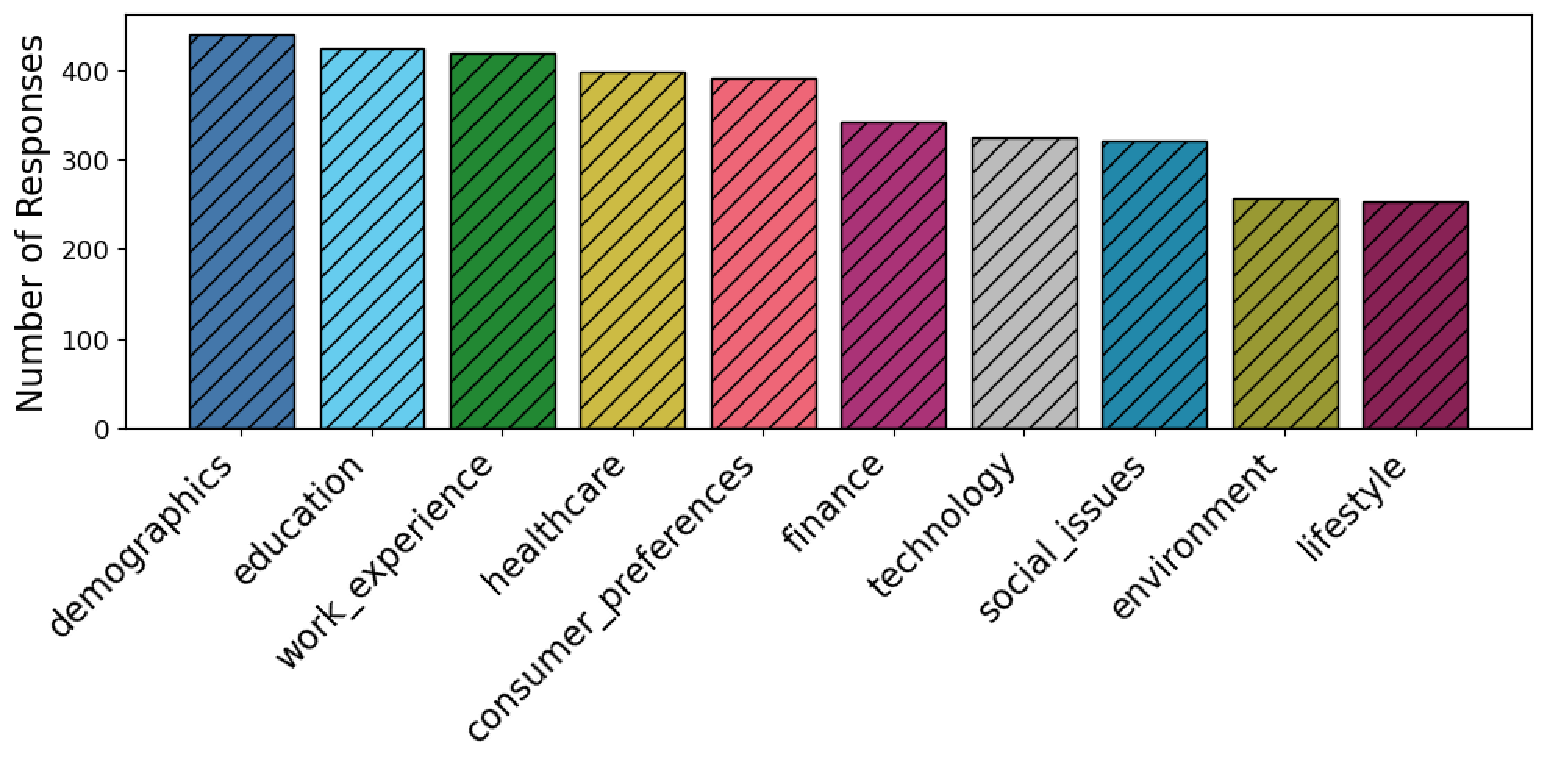
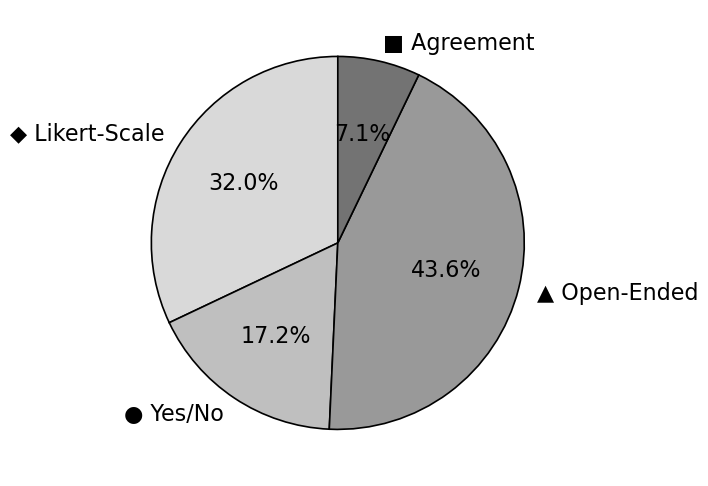
데이터 규모는 3,568개의 응답과 433개의 고유 페르소나로, 표면적으로는 작아 보이지만 도메인·페르소나·질문 유형이 고르게 분포돼 있다. 이는 ‘제어된’ 데이터 생성 실험에 충분히 통계적 신뢰성을 제공한다는 점에서 의미가 크다. 다만, 실제 설문 조사에서 나타나는 복잡한 응답 패턴(예: 다중 선택, 자유 서술형)까지 포괄하려면 향후 데이터 규모와 다양성을 확대할 필요가 있다.
평가에서는 BLEU·ROUGE·BERTScore와 더불어 설문 특화 메트릭(구조적 일관성, 스타일 일관성, 감성 일관성)을 도입했다. 전통적인 NLG 평가 지표는 표면적 유사도에 초점을 맞추는 반면, 설문 응답은 ‘일관된 인물성’과 ‘감성 톤’이 핵심이므로 이러한 추가 메트릭은 평가의 타당성을 높인다. 결과적으로 TinyLlama 1.1B와 Phi‑2가 7‑8 B 대형 모델과 비슷한 BLEU·ROUGE 점수를 기록한 것은, 페르소나 조건부 미세조정이 모델 크기와 무관하게 성능을 끌어올릴 수 있음을 시사한다.
한계점으로는 (1) 페르소나 라벨링이 주관적이며, 라벨링 오류가 모델 행동에 직접적인 영향을 미칠 수 있다. (2) 현재는 정적 페르소나를 사용해 응답 간 변화를 모사하지 못한다는 점이다. (3) 편향 모니터링은 제시되었지만, 구체적인 편향 지표와 완화 전략이 부족하다. 향후 연구에서는 동적 페르소나 전이, 대규모 다중언어 설문 데이터, 그리고 페르소나 기반 편향 교정 메커니즘을 탐색하는 것이 유망하다.
전반적으로 PolyPersona는 소형 LLM을 활용해 비용 효율적인 합성 설문 데이터를 제공함으로써, 설문 조사 설계·시뮬레이션·프리테스트 단계에서의 데이터 부족 문제를 완화할 수 있는 실용적인 솔루션이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리