텍스트가 우세한 이유 시각이 의료 다중모달 판단을 저해한다
읽는 시간: 2 분
...
📝 원문 정보
- Title: Why Text Prevails: Vision May Undermine Multimodal Medical Decision Making
- ArXiv ID: 2512.13747
- 발행일: 2025-12-15
- 저자: Siyuan Dai, Lunxiao Li, Kun Zhao, Eardi Lila, Paul K. Crane, Heng Huang, Dongkuan Xu, Haoteng Tang, Liang Zhan
📝 초록 (Abstract)
대형 언어 모델(LLM)의 급속한 발전으로 고성능 다중모달 대형 언어 모델(MLLM)이 시각‑언어 과제에서 인상적인 제로샷 능력을 보여주고 있다. 그러나 생의학 분야에서는 최첨단 MLLM조차도 기본적인 의료 의사결정(MDM) 과제에서 한계를 드러낸다. 본 연구는 두 가지 어려운 데이터셋을 이용해 이 한계를 조사한다. 첫째는 정상, 경도인지장애, 치매로 구분되는 3단계 알츠하이머병(AD) 분류로, 영상 간 차이가 시각적으로 미묘하다. 둘째는 MIMIC‑CXR의 흉부 X‑레이 이미지에 대해 14개의 비상호배타적 질환을 동시에 분류하는 작업이다. 실험 결과, 텍스트 전용 추론이 시각 전용 또는 시각‑텍스트 결합보다 일관되게 우수했으며, 다중모달 입력은 종종 텍스트만 사용할 때보다 성능이 떨어졌다. 이를 개선하기 위해 세 가지 전략을 탐색했다: (1) 이유가 주석된 예시를 활용한 인‑컨텍스트 학습, (2) 시각 캡셔닝 후 텍스트 전용 추론, (3) 분류 감독을 이용한 비전 타워의 소수 샷 파인튜닝. 연구 결과는 현재 MLLM이 충분히 근거 있는 시각 이해를 갖추지 못했음을 보여주며, 의료 분야에서 다중모달 의사결정을 강화하기 위한 유망한 방향을 제시한다.💡 논문 핵심 해설 (Deep Analysis)
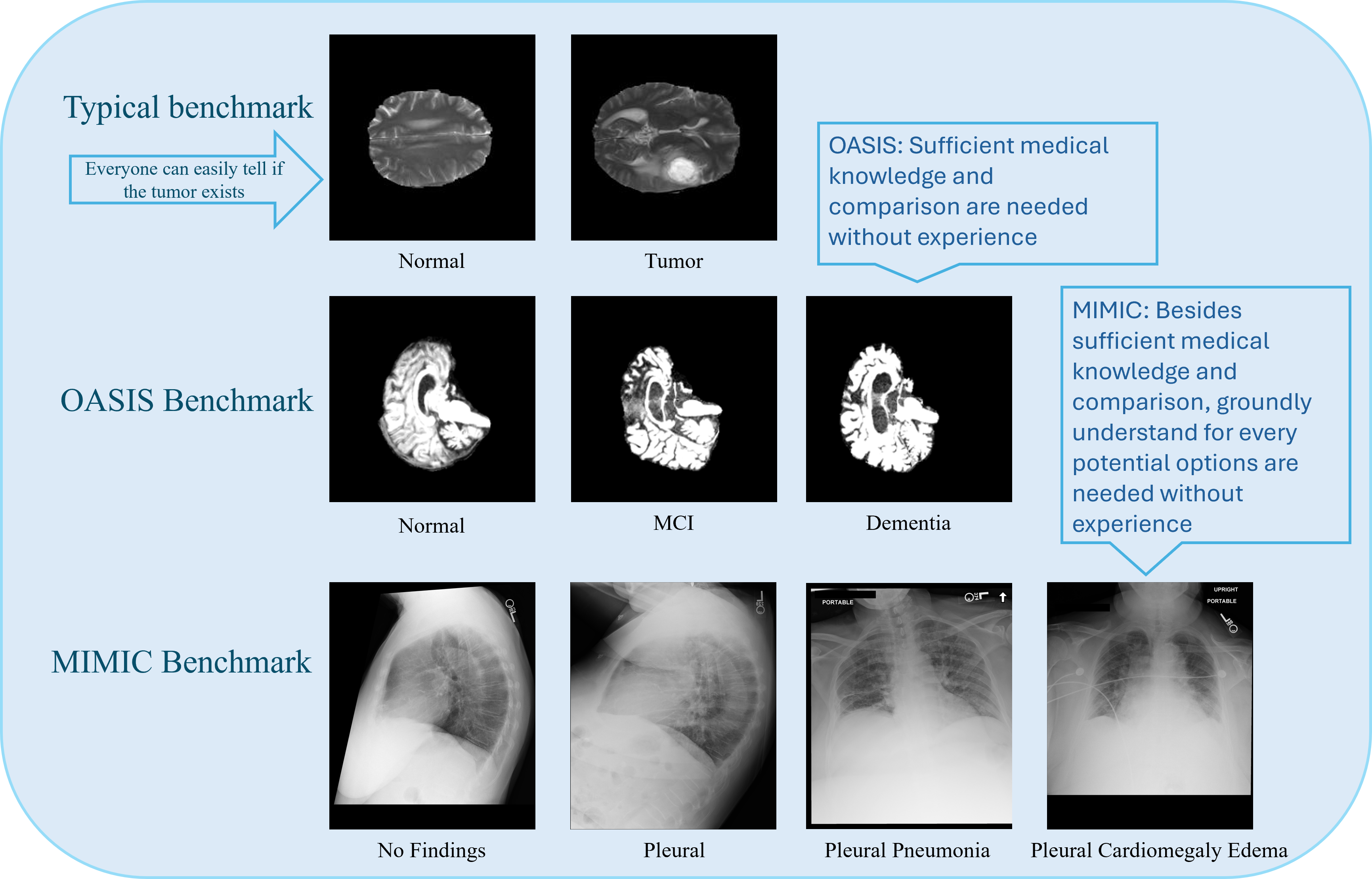
실험에서는 “vision‑only”, “text‑only”, “vision‑text” 세 가지 입력 모드를 동일한 MLLM 아키텍처에 적용했으며, 성능 평가는 정확도, F1 점수 등 표준 메트릭을 사용했다. 놀랍…