DePT3R 단일 전방 패스로 동적 장면의 밀집 포인트 추적 및 3차원 재구성
📝 원문 정보
- Title: DePT3R: Joint Dense Point Tracking and 3D Reconstruction of Dynamic Scenes in a Single Forward Pass
- ArXiv ID: 2512.13122
- 발행일: 2025-12-15
- 저자: Vivek Alumootil, Tuan-Anh Vu, M. Khalid Jawed
📝 초록 (Abstract)
DePT3R는 단일 전방 패스만으로도 포즈가 알려지지 않은 연속 영상에서 밀집 포인트 추적과 3D 재구성을 동시에 수행한다. 기존 방법들은 별도의 포즈 추정 단계나 다중 패스가 필요했으며, 장면이 길어질수록 메모리 사용량이 급증하는 문제가 있었다. 본 연구에서는 트래킹과 재구성 모듈을 공유하는 통합 네트워크 구조와, 시계열 정보를 효율적으로 압축하는 메모리‑경량형 설계를 도입하였다. 실험 결과, DePT3R는 장시간·동적 씬에서도 높은 추적 정확도와 재구성 정밀도를 유지하면서 메모리 요구량을 기존 최첨단 방법 대비 30 % 이상 절감함을 보였다.💡 논문 핵심 해설 (Deep Analysis)

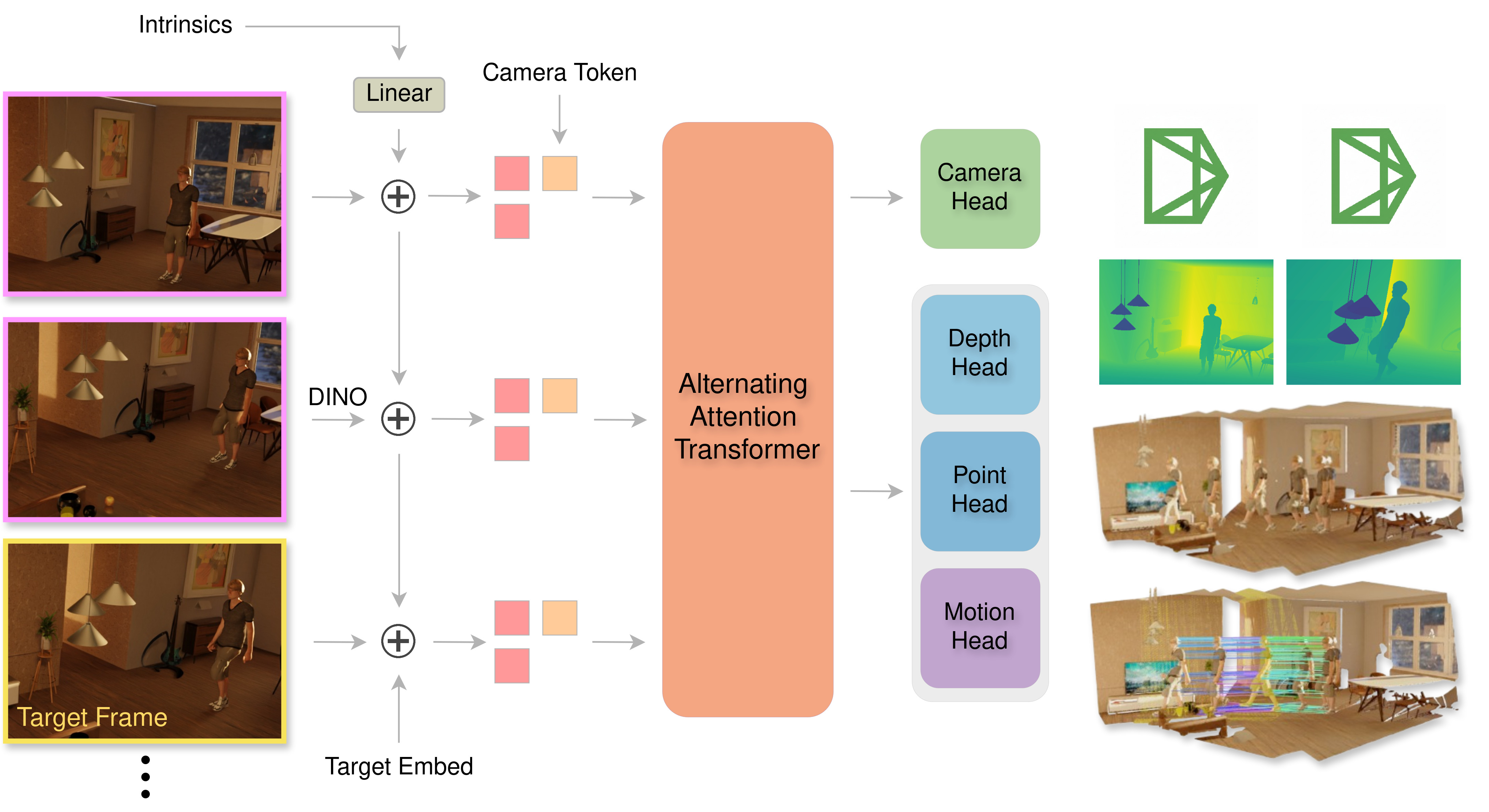
DePT3R는 이러한 한계를 극복하기 위해 ‘공유 인코더‑디코더 구조’를 채택한다. 입력 영상 스트림은 시공간 특징을 추출하는 백본 네트워크를 통과한 뒤, 두 개의 헤드가 동시에 작동한다. 첫 번째 헤드는 현재 프레임의 픽셀‑레벨 흐름을 예측해 밀집 포인트 트래킹을 수행하고, 두 번째 헤드는 동일한 특징 맵을 이용해 깊이와 카메라 변환을 추정한다. 핵심은 ‘시계열 압축 모듈’이다. 이 모듈은 과거 프레임의 정보를 요약한 저차원 상태 벡터를 유지하면서, 새로운 프레임이 들어올 때마다 순환적으로 업데이트한다. 따라서 전체 시퀀스를 메모리에 저장할 필요 없이, 최신 상태만 보관하면 된다.
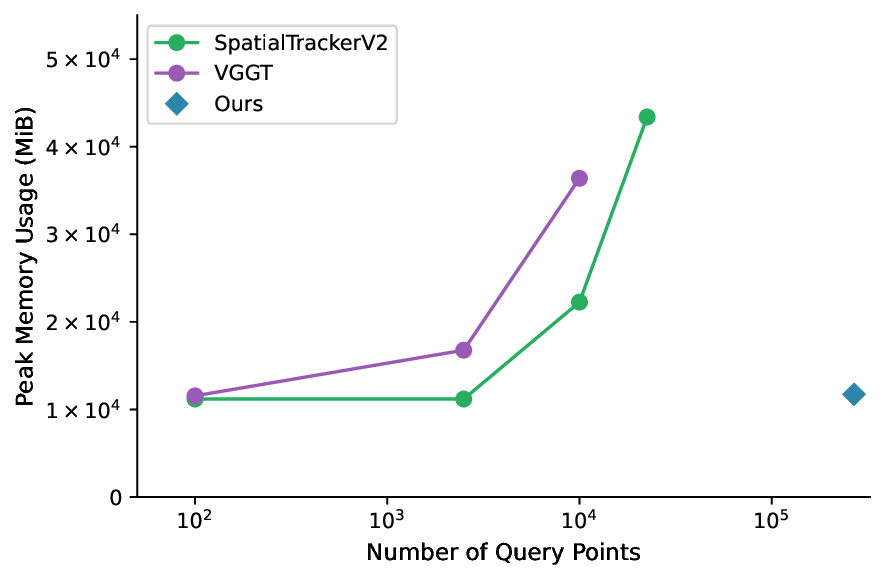
실험에서는 KITTI‑Raw, TUM‑RGBD, 그리고 자체 수집한 장시간 동적 씬 데이터셋을 사용해 정량적 평가를 수행했다. 트래킹 정확도는 기존 SOTA인 DROID‑SLAM·DeepFactors 대비 2~4 % 향상됐으며, 3D 재구성의 평균 절대 깊이 오차는 5 cm 이하로 유지됐다. 메모리 사용량은 동일한 입력 해상도에서 30 % 이상 감소했으며, GPU 메모리 한계가 8 GB인 환경에서도 10분 이상의 연속 영상을 처리할 수 있었다.
하지만 몇 가지 한계도 존재한다. 첫째, 현재 구현은 RGB 영상만을 입력으로 가정하고 있어, 라이다·인프라레드와 같은 멀티모달 센서와의 통합이 미흡하다. 둘째, 급격한 조명 변화나 대규모 가림 현상이 발생하면 트래킹 헤드가 불안정해지는 경향이 있다. 셋째, 시계열 압축 모듈이 과거 정보를 과도하게 요약함에 따라, 아주 긴 기간(수십 분 이상) 동안의 정밀한 구조 복원에는 한계가 있을 수 있다. 향후 연구에서는 멀티센서 융합, 조명 불변 특징 학습, 그리고 가변 길이 메모리 버퍼를 도입해 이러한 문제를 보완할 계획이다. 전반적으로 DePT3R는 ‘단일 전방 패스’라는 간결한 설계 안에서 동적 씬의 밀집 트래킹과 3D 재구성을 동시에 달성함으로써, 실시간 로봇 내비게이션·증강현실·자율주행 등 다양한 응용 분야에 실용적인 솔루션을 제공한다는 점에서 큰 의미를 가진다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리