SpeakRL 언어 모델의 추론 발화 행동 통합 강화학습
읽는 시간: 2 분
...
📝 원문 정보
- Title: SpeakRL: Synergizing Reasoning, Speaking, and Acting in Language Models with Reinforcement Learning
- ArXiv ID: 2512.13159
- 발행일: 2025-12-15
- 저자: Emre Can Acikgoz, Jinoh Oh, Jie Hao, Joo Hyuk Jeon, Heng Ji, Dilek Hakkani-Tür, Gokhan Tur, Xiang Li, Chengyuan Ma, Xing Fan
📝 초록 (Abstract)
효과적인 인간‑에이전트 협업이 실제 응용 분야에서 점점 더 보편화되고 있다. 현재 대부분의 협업 방식은 일방향적이며, 사용자가 에이전트에게 명령이나 질문을 제시하면 에이전트가 바로 답변한다. 그러나 에이전트의 능력이 향상됨에 따라, 에이전트가 사용자 의도를 명확히 하고 모호성을 해소하며 상황 변화에 적응하기 위해 대화에 능동적으로 참여해야 할 필요성이 커졌다. 기존 연구는 언어 모델의 대화 능력을 충분히 활용하지 못하고, 에이전트를 더 나은 ‘팔로워’로 최적화하는 데에 머물렀다. 본 연구에서는 에이전트가 필요한 경우 적절한 확인 질문을 제시하는 등 능동적인 상호작용을 장려하는 보상을 제공하는 강화학습 방법인 SpeakRL을 제안한다. 이를 지원하기 위해 대화형 명확화 질문을 통해 과제가 해결되는 다양한 시나리오를 포함한 합성 데이터셋 SpeakER를 구축하였다. 우리는 대화형 능동성에 대한 보상 설계 과정을 체계적으로 분석하고, 질문과 행동 사이의 균형을 학습하도록 하는 원칙적인 보상 공식을 제시한다. 실험 결과, 제안 방법은 기본 모델에 비해 대화 턴 수를 증가시키지 않으면서 과제 완수율을 20.14% 절대 향상시켰으며, 훨씬 규모가 큰 상용 모델을 능가하는 성과를 보였다. 이는 명확화 중심의 인간‑에이전트 상호작용 가능성을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
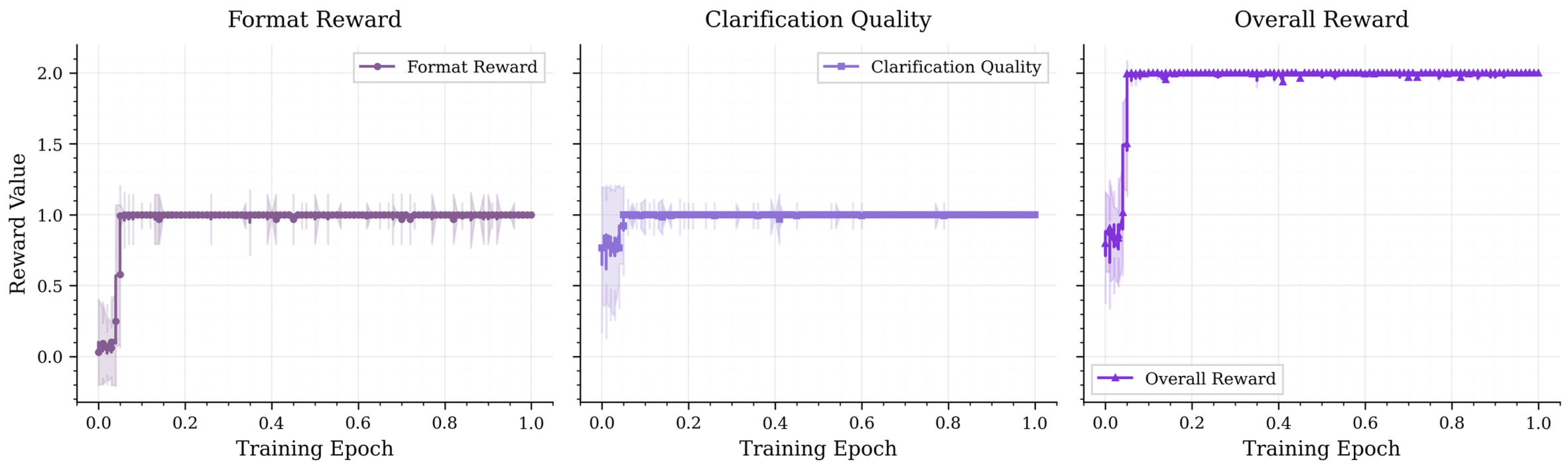
첫 번째 핵심 기여는 SpeakER 데이터셋이다. 기존의 task‑oriented dialogue 데이터는 주로 사용자가 명확한 슬롯 정보를 제공하고 에이전트가 이를 바로 실행하는 흐름을 담고 있다. 반면 SpeakER는 사용자의 의도가 불명확하거나 다중 해석이 가능한 상황을 인위적으로 생성하고, 에이전트가 명확화 질문을 통해 정보를 보충한 뒤 행동을 수행하도록 설계되었다. 이렇게 설계된 시나리오는 실제 고객 서비스, 의료 상담, 스마트 홈 제어 등에서 흔히 발생…