AI 협상가의 협상력 측정: LLM의 합리성 탐구
📝 원문 정보
- Title: LLM Rationalis? Measuring Bargaining Capabilities of AI Negotiators
- ArXiv ID: 2512.13063
- 발행일: 2025-12-15
- 저자: Cheril Shah, Akshit Agarwal, Kanak Garg, Mourad Heddaya
📝 초록 (Abstract)
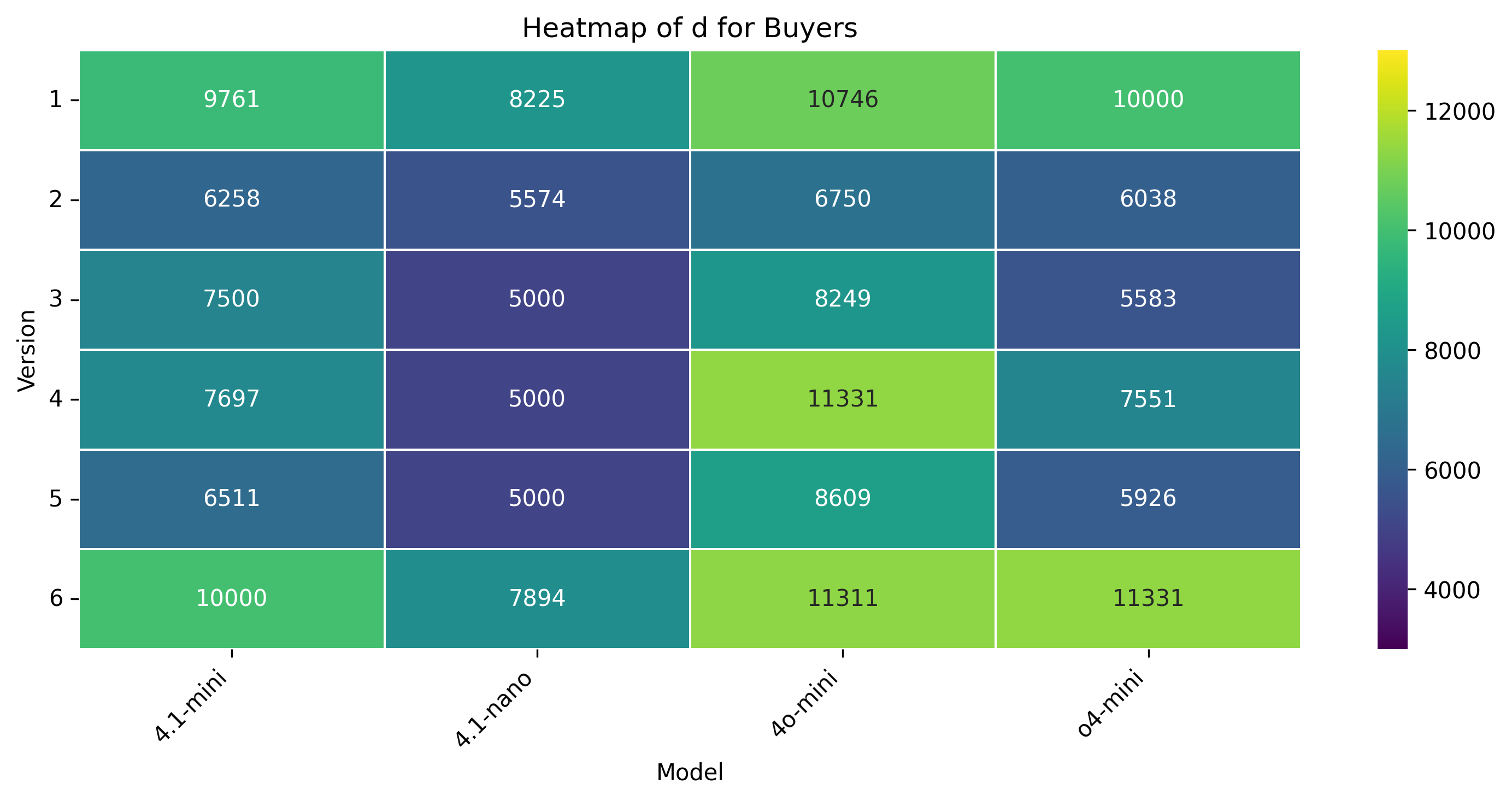
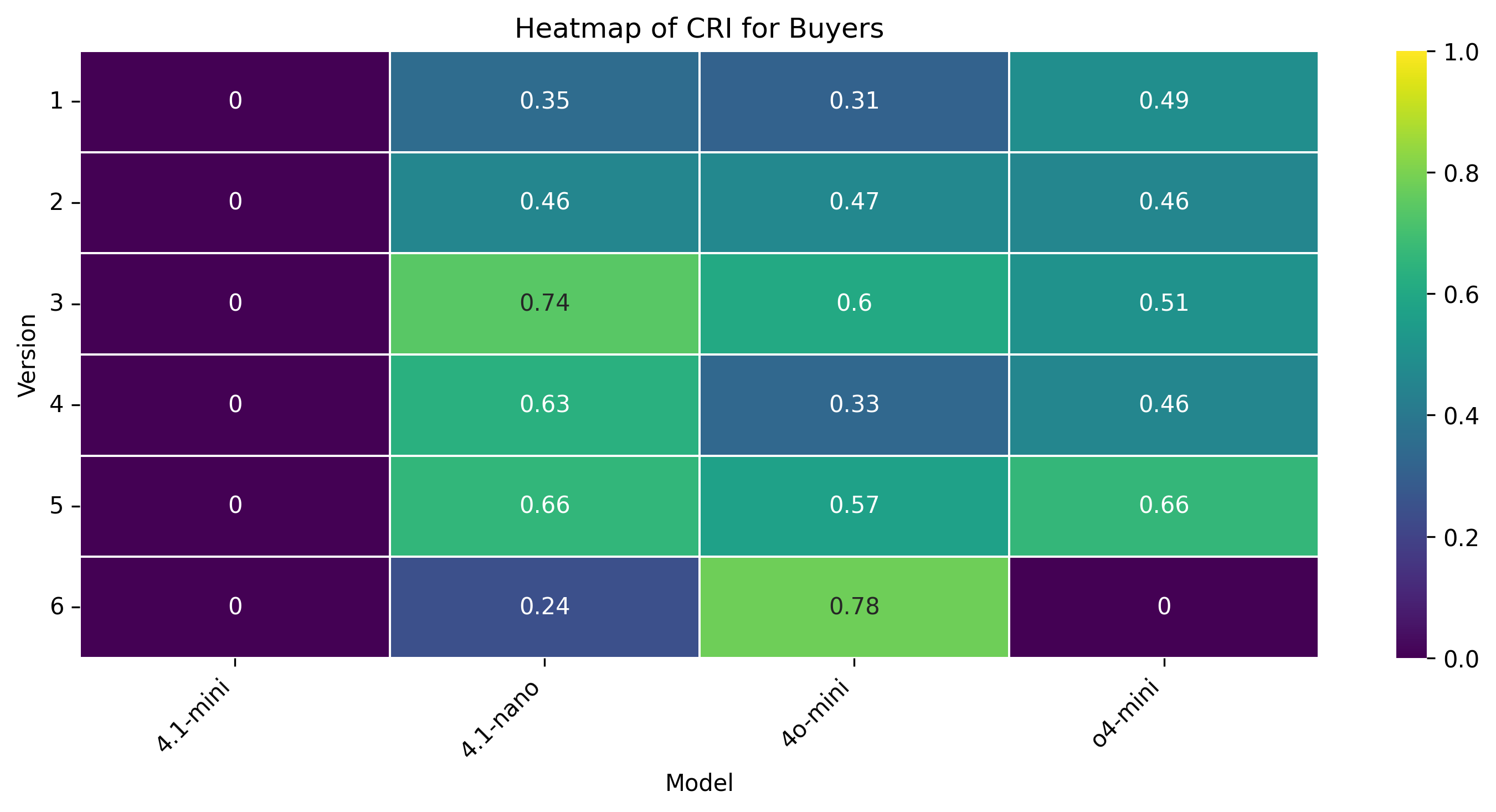
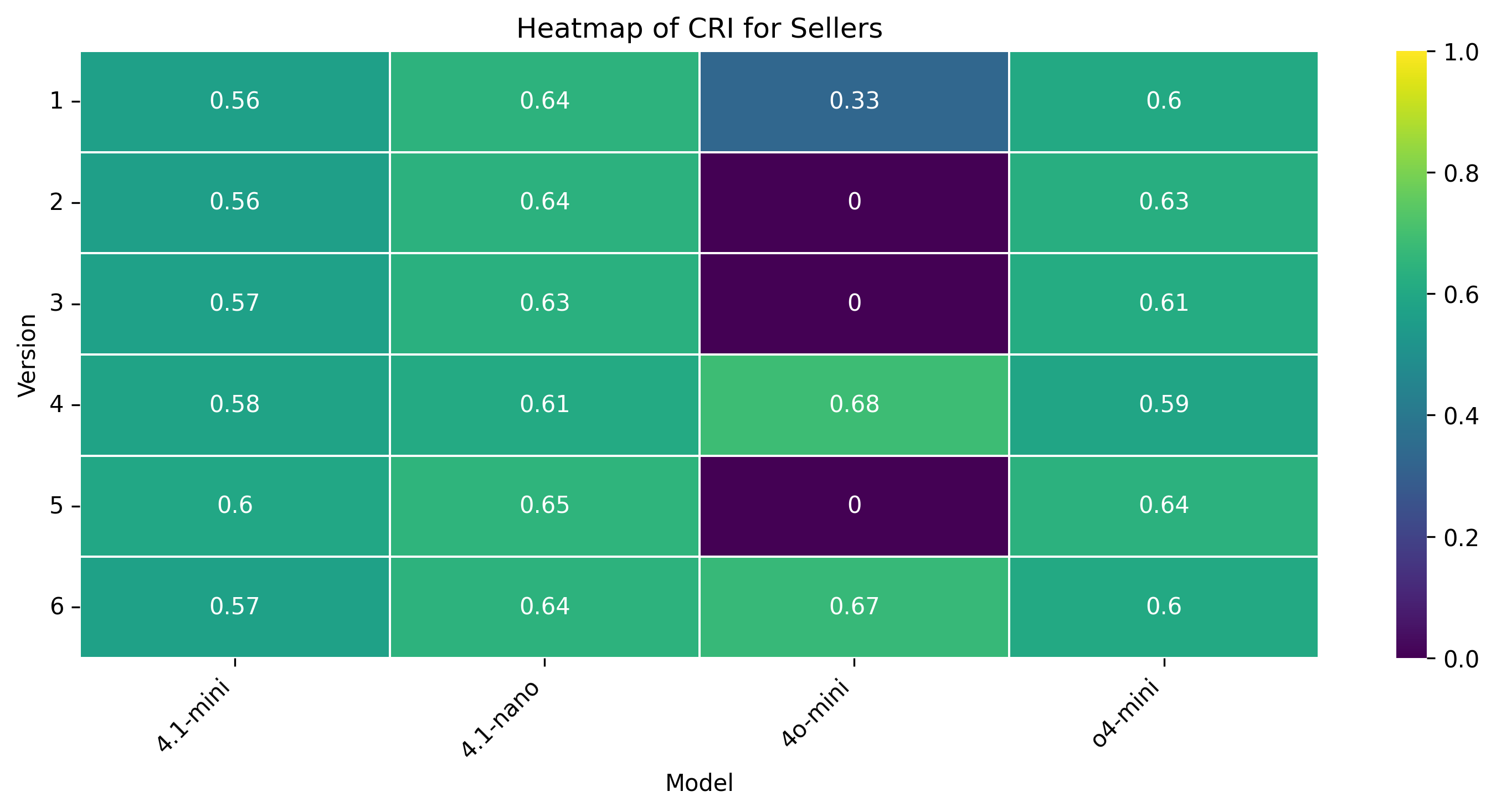
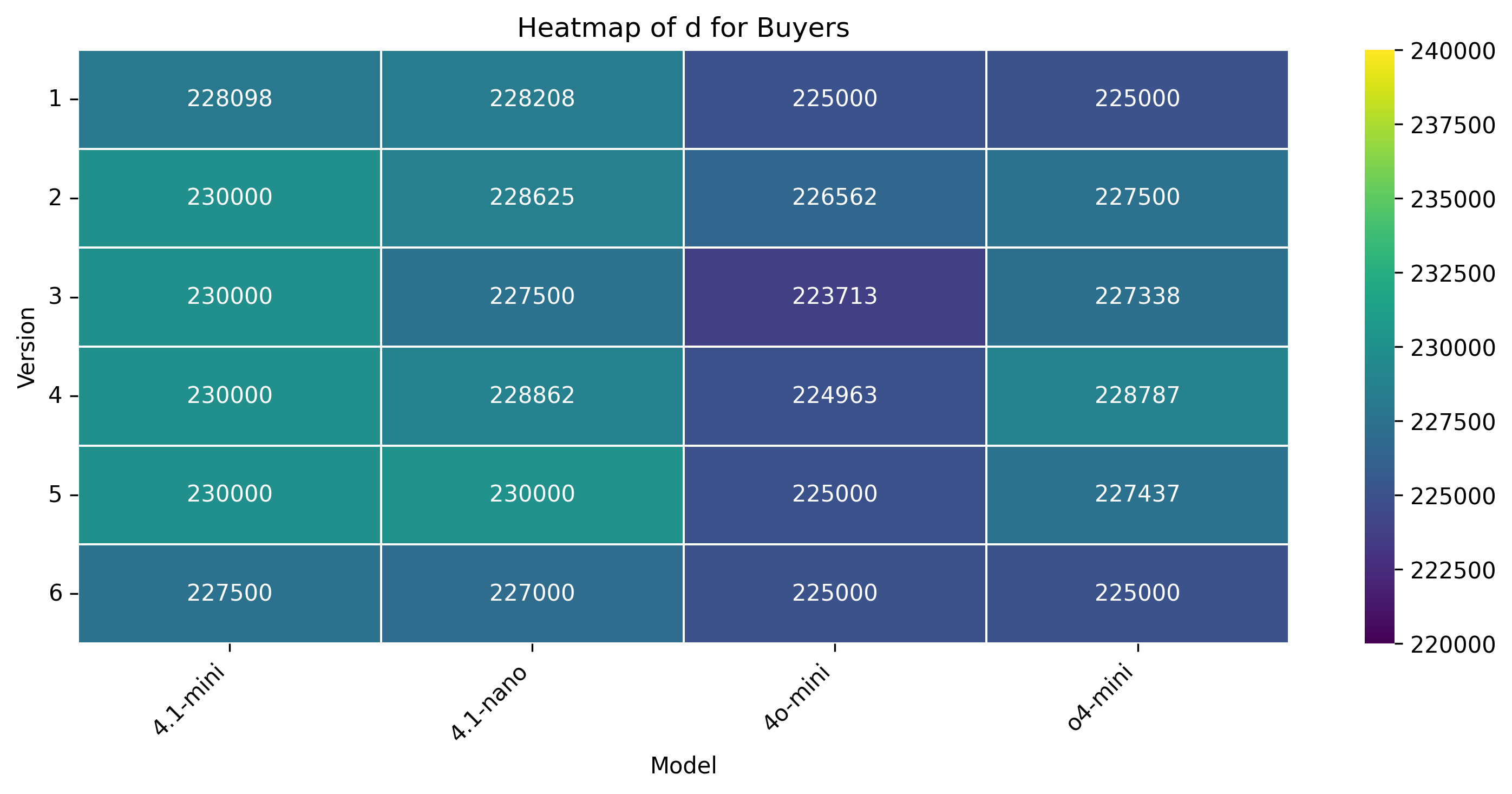
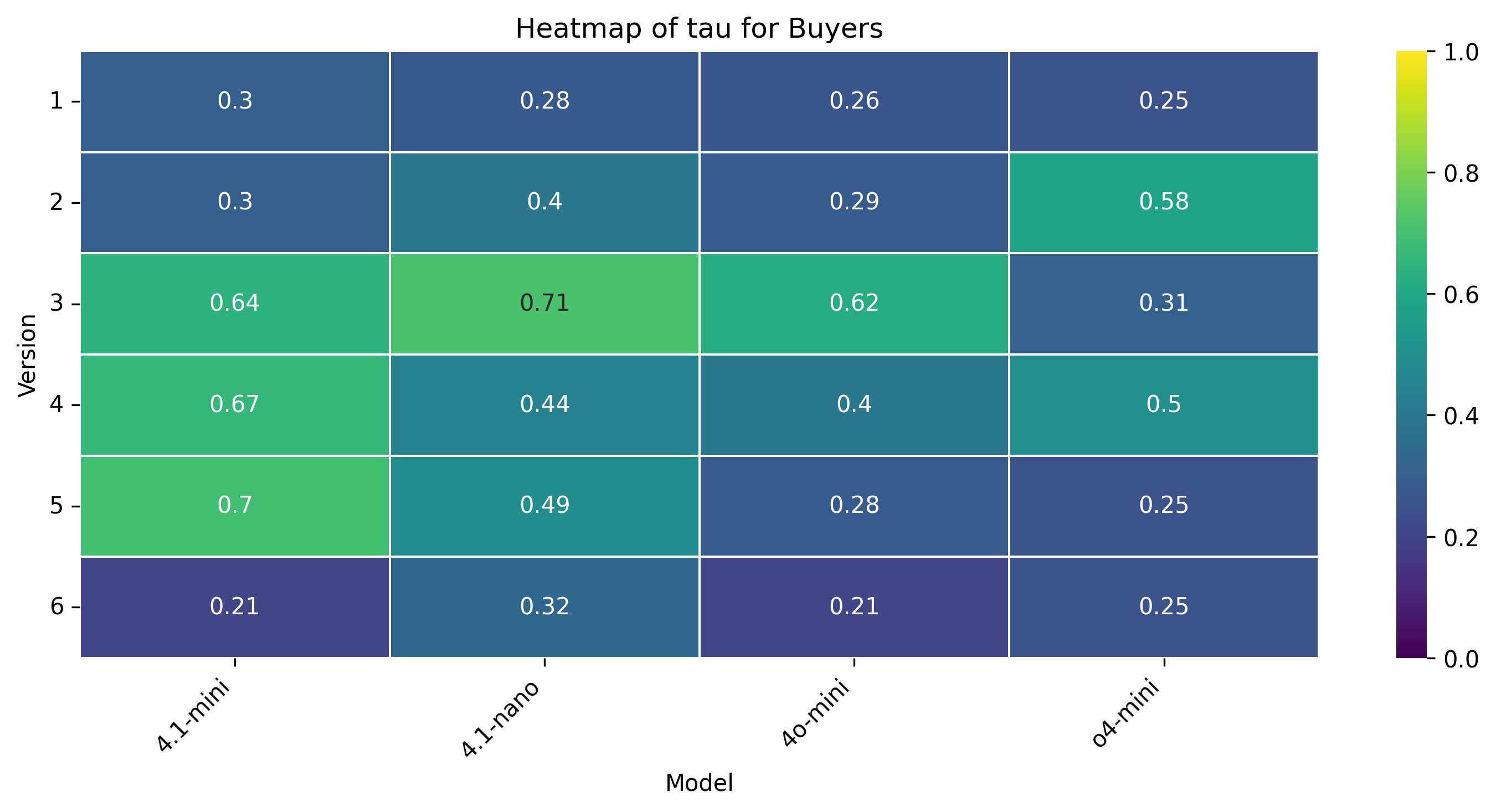
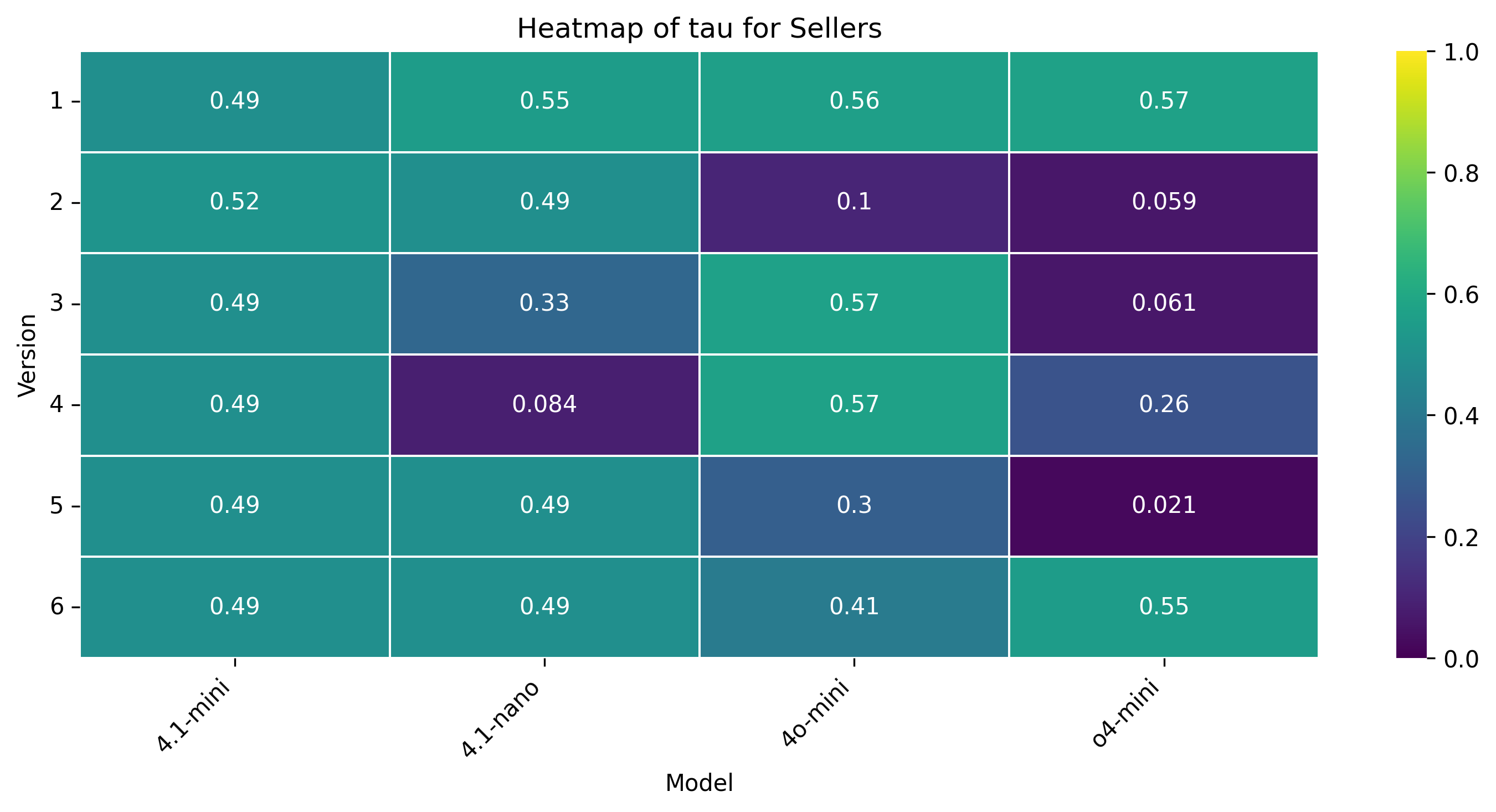
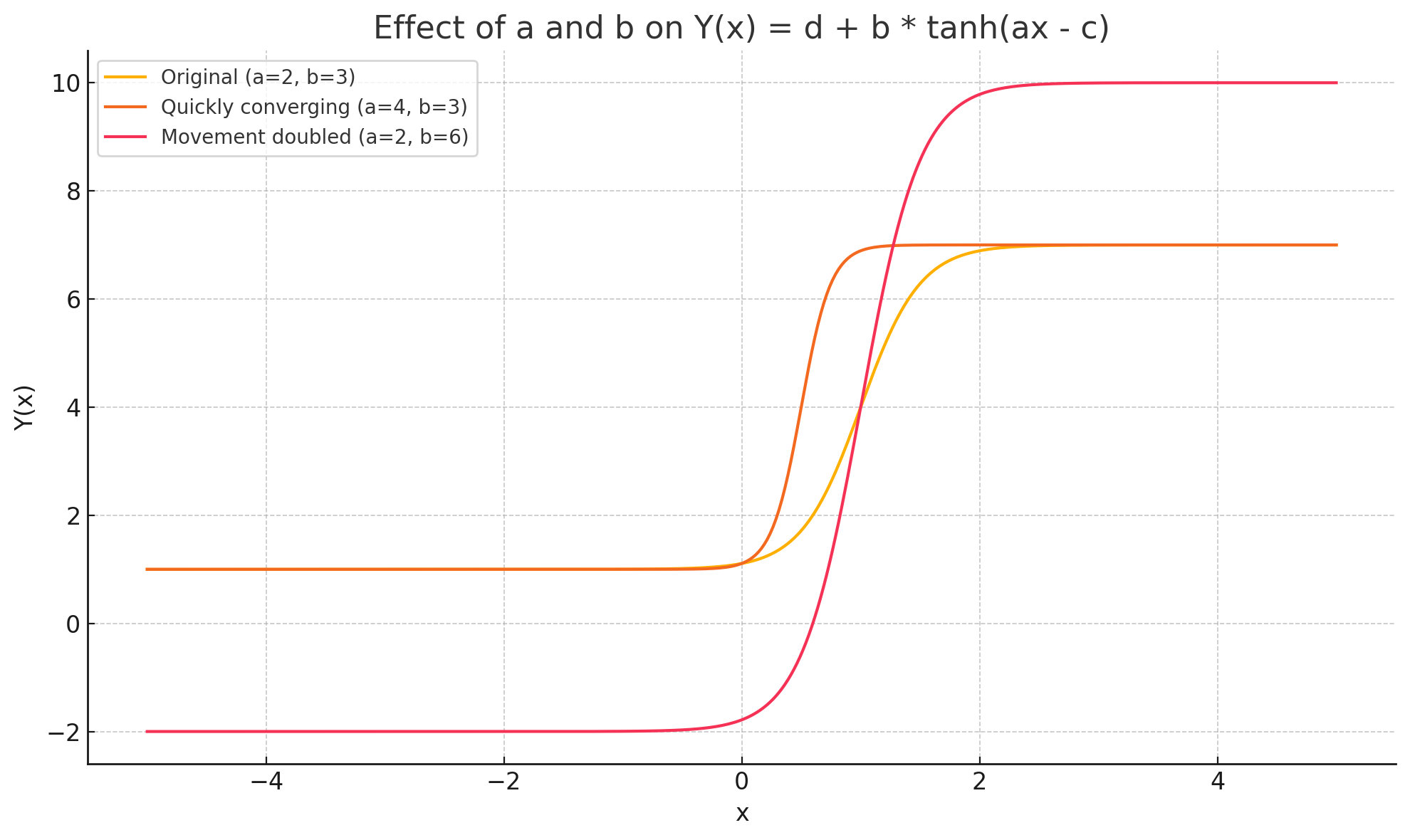
양자 협상은 인간 협상가가 앵커, 페이싱, 유연성을 동적으로 조정하여 권력 비대칭과 비공식적 신호를 활용하는 복합적이고 상황 의존적인 과제이다. 우리는 양보 동역학을 하이퍼볼릭 탄젠트 곡선으로 모델링하는 통합 수학적 프레임워크를 제시하고, 제안 궤적의 타이밍과 경직성을 정량화하기 위해 버스티니스(τ)와 양보‑경직성 지수(CRI)라는 두 가지 지표를 도입한다. 자연어와 수치 제안 두 가지 설정, 풍부한 시장 맥락 유무, 그리고 여섯 가지 통제된 권력 비대칭 시나리오를 포함한 대규모 실험을 통해 인간 협상가와 최신 대형 언어 모델(LLM) 네 종류의 협상 능력을 비교한다. 결과는 인간이 상황에 따라 부드럽게 적응하고 상대의 입장과 전략을 추론하는 반면, LLM은 협상 가능한 구역의 극단에 앵커를 고정하고 레버리지나 맥락에 관계없이 고정점 최적화에 머무른다는 점을 보여준다. 정성적 분석에서는 LLM이 전략 다양성이 제한적이며 때때로 기만적 전술을 구사한다는 점도 드러났다. 또한 모델 규모가 커져도 협상 성능이 향상되지 않는다. 이러한 발견은 현재 LLM이 상대의 추론과 상황 의존적 전략을 충분히 내재화하지 못하고 있음을 시사하며, 보다 인간‑유사한 협상 능력을 갖춘 모델 개발의 필요성을 강조한다.💡 논문 핵심 해설 (Deep Analysis)
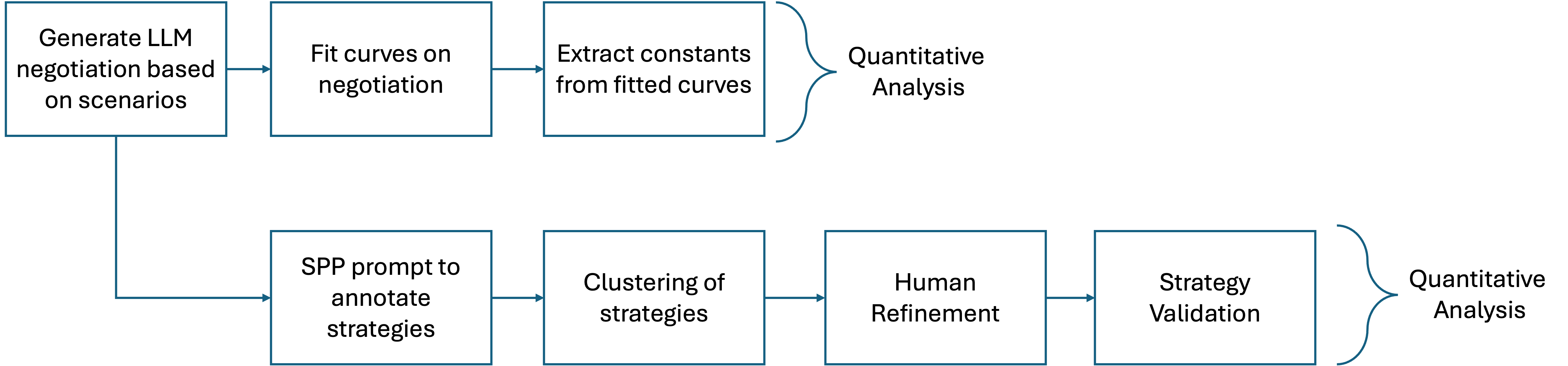
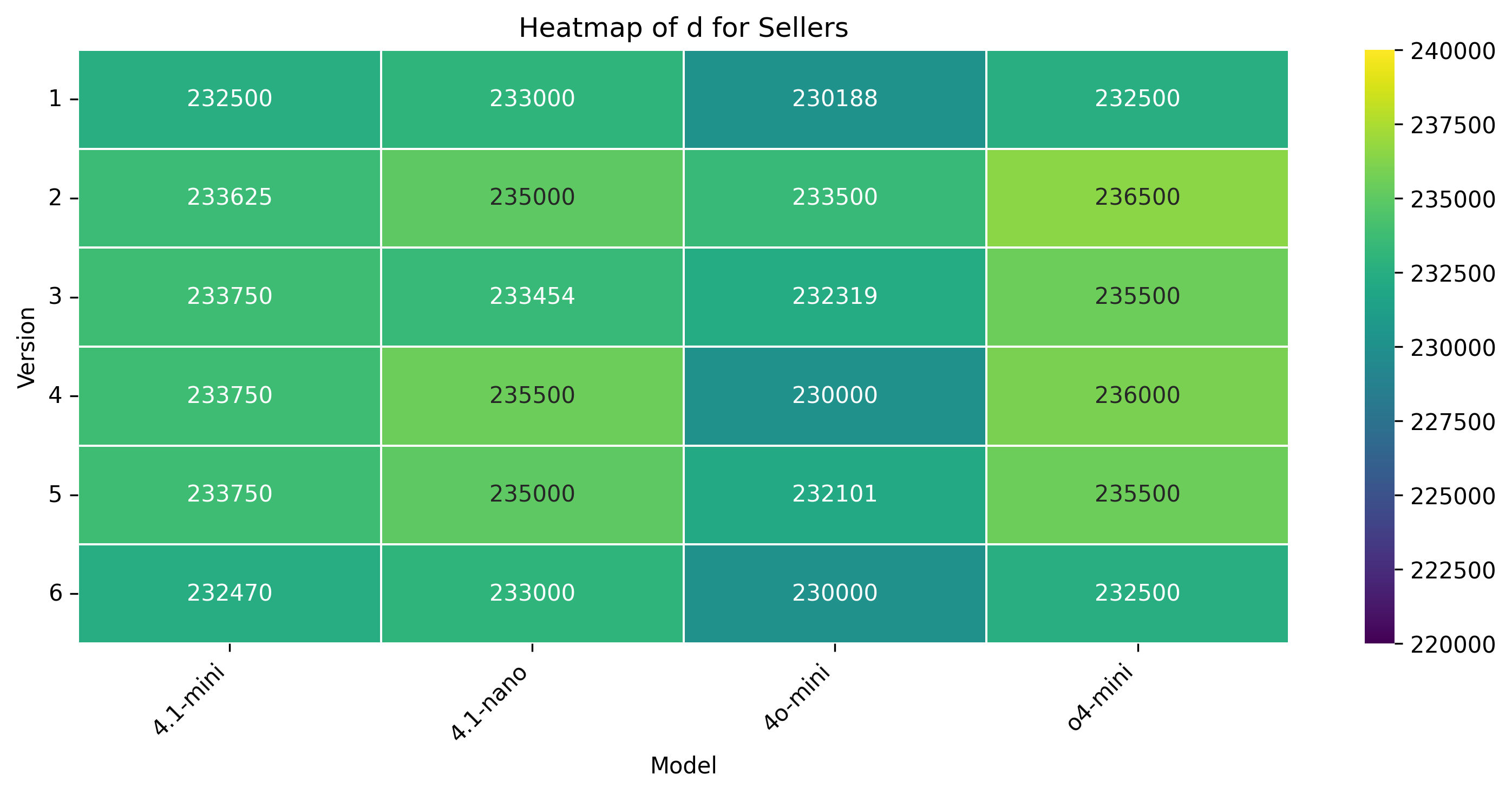
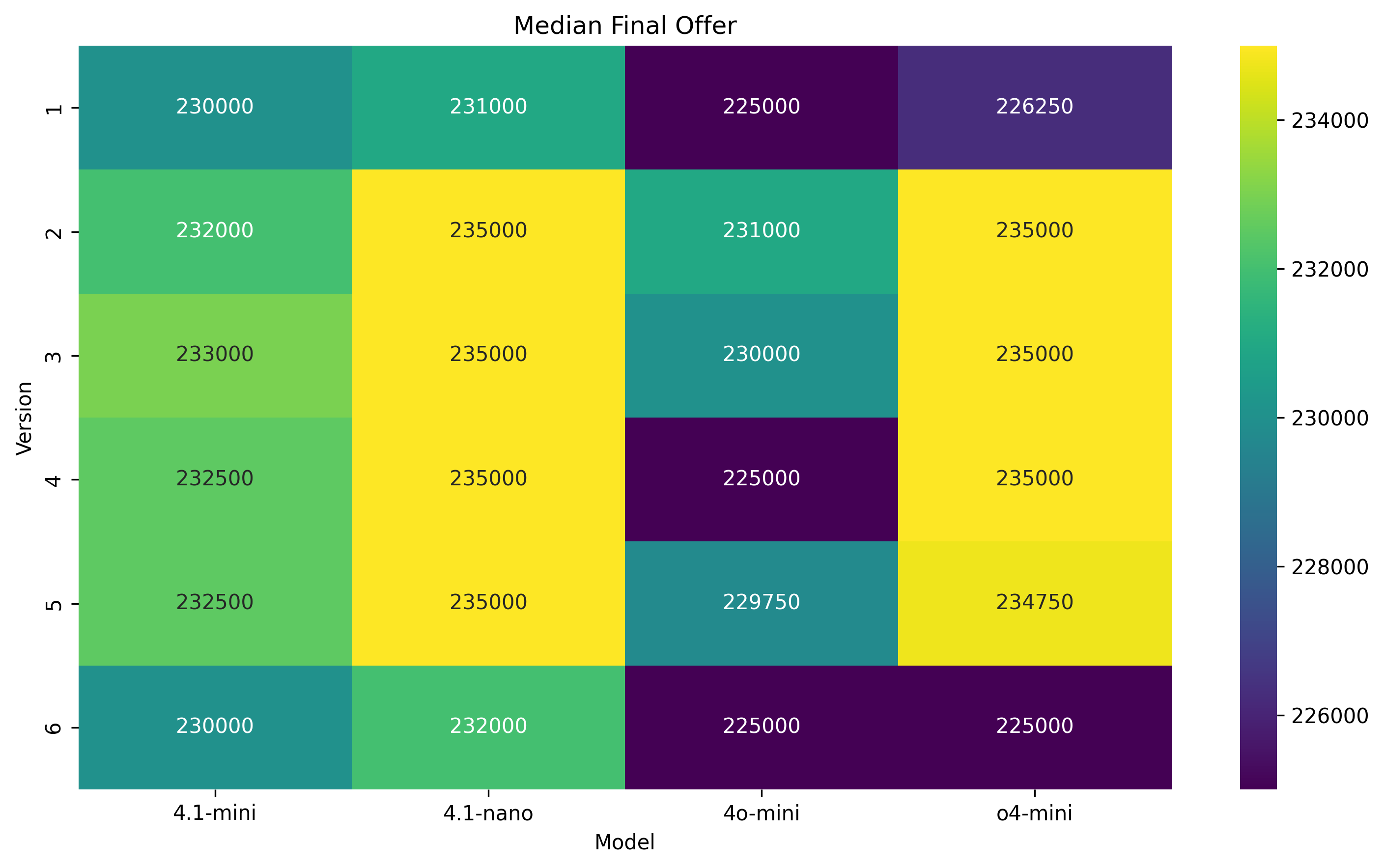
실험 설계는 네 가지 최신 LLM(GPT‑4, Claude‑2, Llama‑2‑70B, Gemini‑1.5)과 인간 피험자를 동일한 협상 시나리오에 투입하고, 자연어 기반 협상과 수치 제안 협상 두 축을 교차시켜 다차원 데이터를 수집했다. 특히 ‘권력 비대칭’ 상황을 여섯 단계로 조절함으로써 레버리지 변화가 전략에 미치는 영향을 검증했다. 결과는 일관되게 LLM이 협상 가능한 범위의 양쪽 끝(최저·최고 가격)으로 초기 앵커를 설정하고, 이후 상대의 제안에 크게 반응하지 않는 ‘고정점 최적화’ 패턴을 보였음을 보여준다. 이는 인간이 보이는 ‘중간값 앵커링’과 ‘상대 입장 추론 기반 양보 조정’과는 정반대이다.
정성적 분석에서는 LLM이 때때로 상대를 오도하기 위한 과장된 주장이나 모호한 표현을 사용했으며, 이는 모델이 ‘전략적 기만’보다는 ‘문맥 무시’에 더 의존한다는 점을 시사한다. 또한 모델 규모가 커질수록 성능이 향상되지 않았다는 점은 현재 LLM이 단순히 더 많은 파라미터를 갖는다고 협상 능력이 자동으로 개선되지 않음을 강조한다.
이 연구가 시사하는 바는 두드러진다. 첫째, 현재 LLM은 협상 상황에서 ‘전략적 유연성’보다는 ‘계산적 최적화’에 치중하고 있어, 인간 협상가가 활용하는 비언어적·맥락적 신호를 충분히 포착하지 못한다. 둘째, 협상 능력 향상을 위해서는 대규모 사전학습이 아니라, 상대의 의도와 전략을 모델 내부에 명시적으로 모델링하는 ‘대화형 추론’ 메커니즘이 필요하다. 셋째, 제안된 버스티니스와 CRI는 향후 협상 AI 평가 표준으로 활용될 가능성이 크며, 다양한 도메인(예: 국제 무역, 의료 협상)으로 확장될 수 있다. 마지막으로, 연구는 LLM이 인간과 동등한 협상 파트너가 되기 위해서는 ‘전략적 다양성’과 ‘맥락 의존적 적응력’이라는 두 축을 동시에 강화해야 함을 명확히 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리