대규모 언어 모델 최적 일회성 프루닝을 위한 이차계획법 재구성
읽는 시간: 2 분
...
📝 원문 정보
- Title: OPTIMA: Optimal One-shot Pruning for LLMs via Quadratic Programming Reconstruction
- ArXiv ID: 2512.13886
- 발행일: 2025-12-15
- 저자: Mohammad Mozaffari, Samuel Kushnir, Maryam Mehri Dehnavi, Amir Yazdanbakhsh
📝 초록 (Abstract)
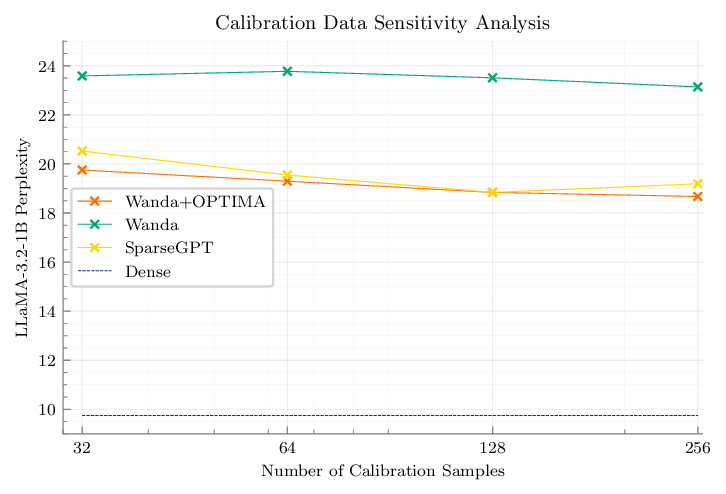
사후 훈련 모델 프루닝은 유망한 해결책이지만, 간단한 휴리스틱은 빠르지만 정확도가 크게 떨어지고, 원칙적인 공동 최적화 방법은 정확도를 회복하지만 현대 규모에서는 계산적으로 실현 불가능하다는 트레이드오프가 존재한다. SparseGPT와 같은 일회성 방법은 효율적인 근사 휴리스틱 가중치 업데이트를 적용함으로써 최적성 측면에서 실용적인 절충을 제공한다. 이러한 격차를 메우기 위해 우리는 OPTIMA를 제안한다. OPTIMA는 마스크 선택 후 레이어별 가중치 재구성을 공통 레이어 헤시안을 공유하는 독립적인 열별 이차계획문제(QP)로 정의한다. 이 QP들을 해결함으로써 추정된 헤시안에 대해 재구성 목표에 대한 열별 전역 최적 업데이트를 얻는다. 공유 헤시안 구조는 문제를 가속기에서 배치 처리하기에 매우 적합하게 만든다. 우리는 하나의 레이어당 헤시안을 한 번만 축적하고, 많은 작은 QP들을 병렬로 해결하는 가속기 친화적 QP 솔버를 구현하여, 파인튜닝 없이 단일 가속기에서 대규모 사후 훈련 프루닝을 가능하게 한다. OPTIMA는 기존 마스크 선택기와 통합되어 여러 LLM 패밀리와 희소도 구간에서 제로샷 성능을 일관되게 향상시키며, 최대 3.97%의 절대 정확도 개선을 달성한다. NVIDIA H100 기준으로 8B 파라미터 트랜스포머를 전체적으로 프루닝하는 데 40시간, 피크 메모리 60 GB를 사용한다. 이러한 결과는 일회성 사후 훈련 프루닝에 있어 새로운 최첨단 정확도‑효율성 트레이드오프를 설정한다.💡 논문 핵심 해설 (Deep Analysis)