콘텐츠 인식형 광고 배너 레이아웃 생성 비전 언어 모델의 두 단계 사유 체인
📝 원문 정보
- Title: Content-Aware Ad Banner Layout Generation with Two-Stage Chain-of-Thought in Vision Language Models
- ArXiv ID: 2512.12596
- 발행일: 2025-12-14
- 저자: Kei Yoshitake, Kento Hosono, Ken Kobayashi, Kazuhide Nakata
📝 초록 (Abstract)
** 본 논문에서는 이미지 기반 광고 배너의 레이아웃을 생성하기 위해 비전‑언어 모델(VLM)을 활용하는 새로운 방법을 제안한다. 기존 광고 레이아웃 기법은 주로 배경 이미지의 시각적 살포도를 이용해 눈에 띄는 영역을 찾는 방식에 의존했지만, 이러한 접근법은 이미지의 세밀한 구도와 의미적 내용을 충분히 반영하지 못한다. 이를 극복하기 위해 제안된 방법은 VLM을 이용해 배경에 나타난 제품 및 기타 요소들을 인식하고, 이를 바탕으로 텍스트와 로고의 배치 위치를 결정한다. 레이아웃 생성 파이프라인은 두 단계로 구성된다. 첫 번째 단계에서는 VLM이 이미지를 분석해 객체 유형과 공간적 관계를 파악하고, 이를 토대로 텍스트 기반의 “배치 계획”을 생성한다. 두 번째 단계에서는 해당 계획을 HTML 형식의 코드로 변환하여 최종 레이아웃을 렌더링한다. 우리는 정량적·정성적 비교 실험을 통해 제안 방법의 효과를 검증했으며, 배경 이미지의 내용을 명시적으로 고려함으로써 기존 방법에 비해 현저히 높은 품질의 광고 레이아웃을 생성함을 입증하였다.**
💡 논문 핵심 해설 (Deep Analysis)
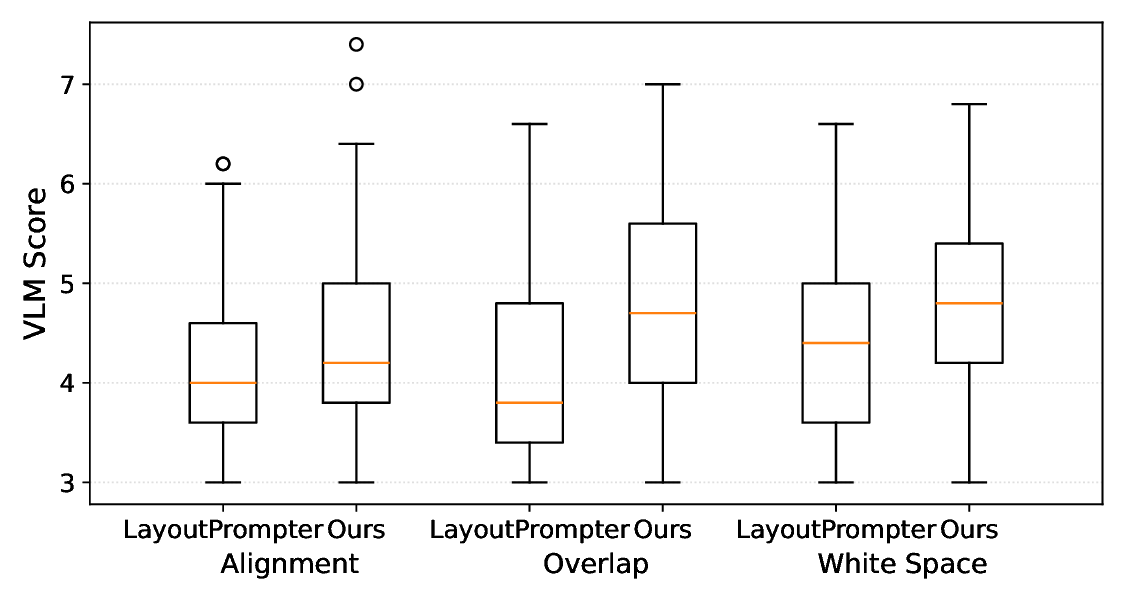
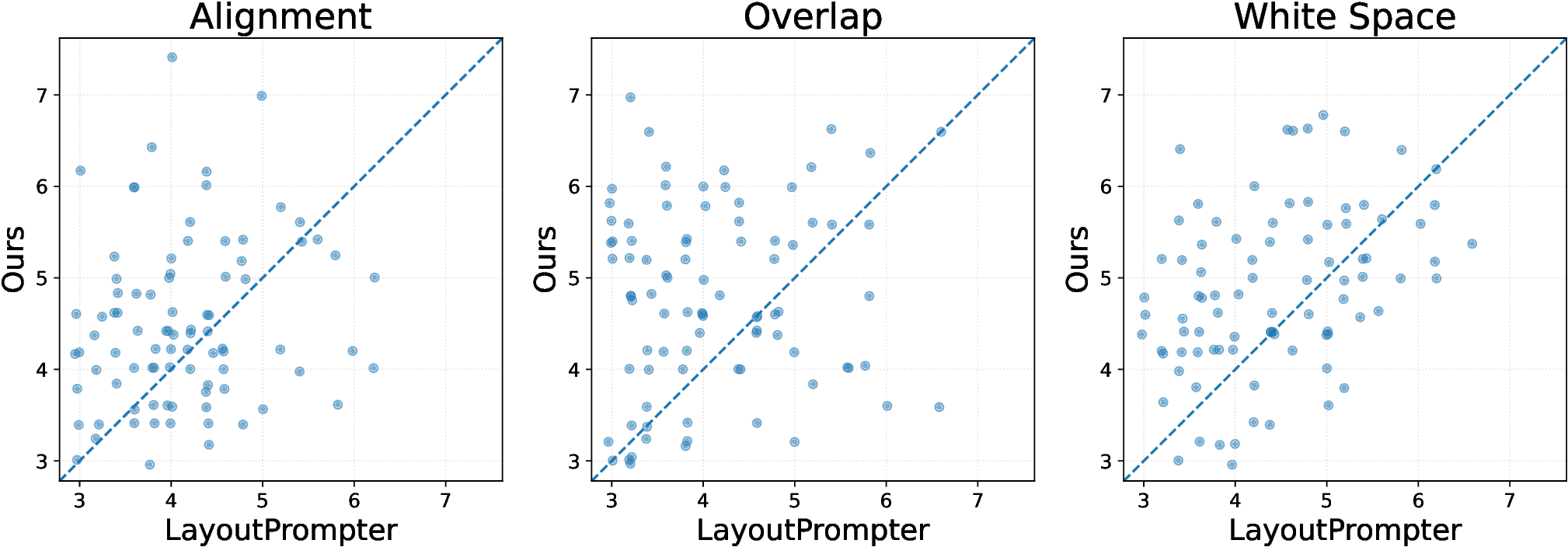
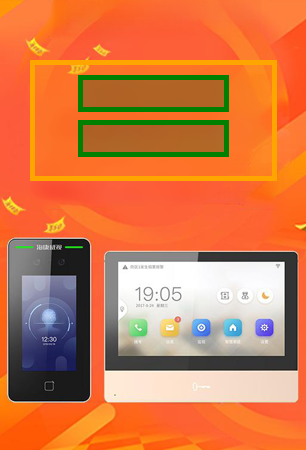
이 연구는 광고 디자인 자동화 분야에서 중요한 전환점을 제시한다. 기존의 살포도 기반 레이아웃 기법은 인간의 시각적 주의를 모방하려는 시도였으나, 이미지 내 객체의 의미적 역할을 무시함으로써 텍스트와 로고가 시각적으로 눈에 띄면서도 의미적으로 어울리지 않는 경우가 빈번했다. 본 논문은 이러한 한계를 비전‑언어 모델이라는 최신 멀티모달 인공지능 기술을 도입함으로써 근본적으로 해결한다. VLM은 이미지 인식과 자연어 이해를 동시에 수행할 수 있어, 배경에 포함된 제품, 인물, 풍경 등 다양한 객체를 정확히 식별하고, 그들 간의 공간적 관계(예: “제품이 왼쪽 상단에 위치”)를 텍스트 형태로 추출한다. 이 과정에서 “체인‑오브‑쏘트(Chain‑of‑Thought)” 방식을 두 단계에 걸쳐 적용한다는 점이 특히 눈에 띈다. 첫 단계에서 VLM이 복합적인 시각 정보를 논리적 텍스트 시퀀스로 변환함으로써, 인간 디자이너가 수행하는 ‘구성 요소 파악 → 배치 아이디어 도출’ 과정을 모방한다. 두 번째 단계에서는 이 텍스트 계획을 구조화된 HTML 코드로 변환해 실제 레이아웃을 구현한다. 이 두 단계 분리는 각각의 서브태스크에 최적화된 프롬프트와 모델 파라미터를 적용할 수 있게 해, 전체 파이프라인의 효율성과 정확성을 동시에 높인다.
실험 결과는 정량적 지표(예: 레이아웃 충돌 최소화, 가독성 점수)와 정성적 평가(전문 디자이너 설문) 모두에서 기존 살포도 기반 방법을 크게 앞선다. 특히, 배경 이미지와 텍스트·로고 간의 의미적 일관성이 크게 향상된 점이 강조된다. 이는 광고 효과 측면에서 중요한데, 소비자는 시각적 조화와 의미적 연결성을 동시에 인식하기 때문에, 본 방법이 실제 마케팅 캠페인에 적용될 경우 클릭률·전환율 상승으로 이어질 가능성이 높다.
하지만 몇 가지 한계도 존재한다. 첫째, VLM의 객체 인식 정확도가 낮은 경우(예: 복잡한 배경, 작은 물체) 배치 계획이 부정확해질 위험이 있다. 둘째, 현재 파이프라인은 HTML 기반 정적 레이아웃에 초점을 맞추고 있어, 동적 애니메이션이나 인터랙티브 요소를 포함한 현대적인 디지털 광고에는 추가적인 확장이 필요하다. 셋째, 프롬프트 설계와 체인‑오브‑쏘트 단계의 길이에 따라 모델 호출 비용이 크게 증가할 수 있어, 실시간 서비스 적용 시 비용 효율성 검토가 요구된다.
향후 연구 방향으로는 (1) 더 강건한 멀티모달 인식 모델을 도입해 복잡한 장면에서도 높은 정확도를 확보하고, (2) 레이아웃 최적화를 위한 강화학습 기반 피드백 루프를 구축해 자동으로 디자인 품질을 개선하며, (3) HTML 외에도 CSS·JavaScript 기반 인터랙티브 레이아웃 생성으로 확장하고, (4) 사용자 맞춤형 디자인 선호도를 반영한 퍼스널라이즈드 배치 계획을 구현하는 것이 제시된다. 이러한 발전은 광고 자동화뿐 아니라 UI/UX 디자인, 전시물 배치 등 다양한 시각‑언어 융합 응용 분야에 파급 효과를 미칠 것으로 기대된다.
**
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리