SceneMaker 분리형 디오클루전 및 포즈 추정 모델을 이용한 오픈셋 3D 장면 생성
📝 원문 정보
- Title: SceneMaker: Open-set 3D Scene Generation with Decoupled De-occlusion and Pose Estimation Model
- ArXiv ID: 2512.10957
- 발행일: 2025-12-11
- 저자: Yukai Shi, Weiyu Li, Zihao Wang, Hongyang Li, Xingyu Chen, Ping Tan, Lei Zhang
📝 초록 (Abstract)
SceneMaker를 이용해 다양한 시점에서 장면 이미지를 생성한다. 본 방법은 실내 장면과 오픈셋 상황 모두에서 기존 방법보다 우수한 성능을 보이며, 합성 이미지와 실제 촬영 이미지 사이에서도 강력한 일반화 능력을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
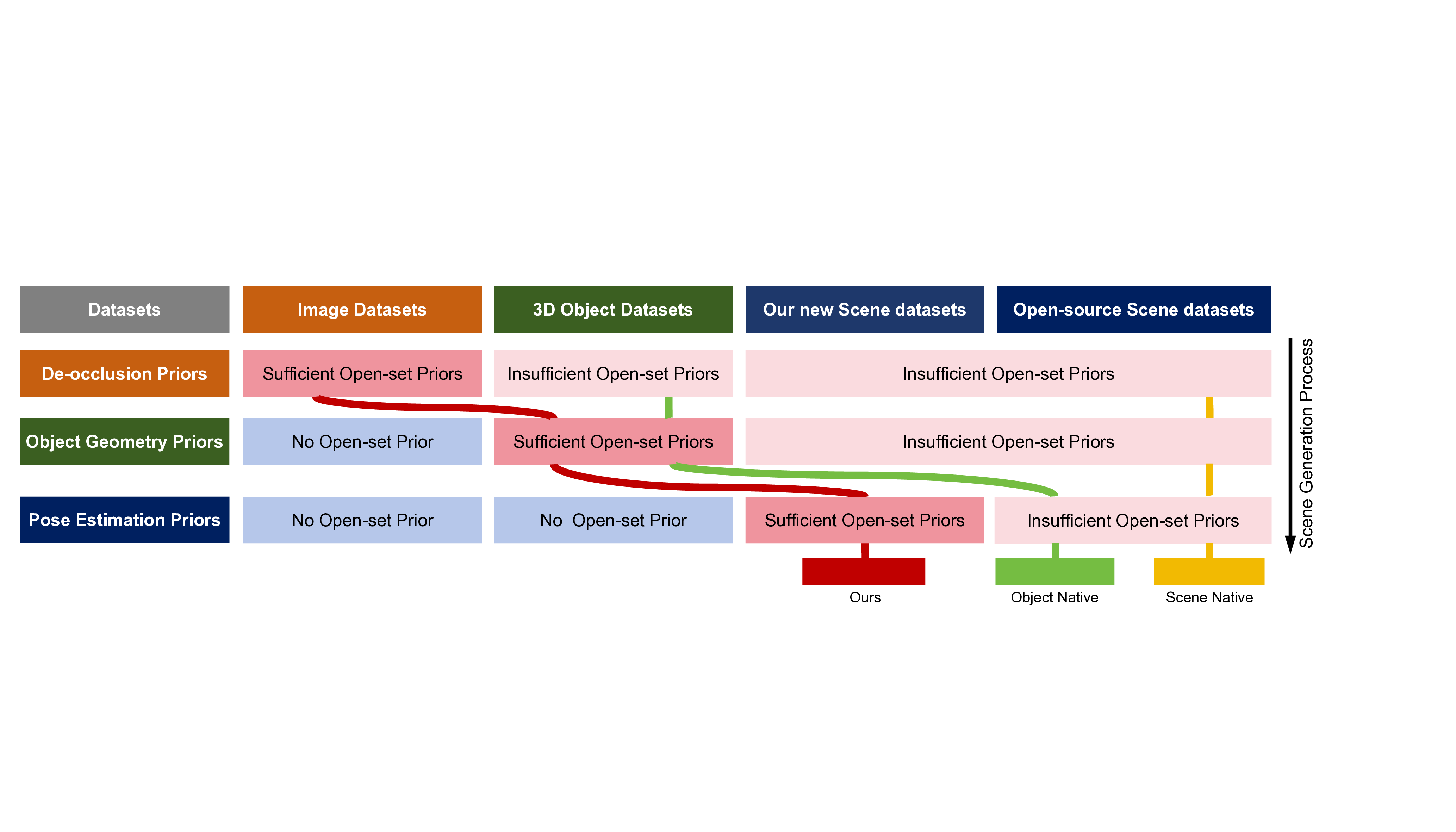
특히 ‘오픈셋(open‑set)’ 설정을 도입한 점이 눈에 띈다. 기존 3D 장면 생성 연구는 대부분 제한된 객체 카테고리와 사전 정의된 레이아웃에 의존했지만, SceneMaker는 훈련 시에 보지 못한 새로운 객체와 레이아웃에도 유연하게 대응한다. 이는 디오클루전 모듈이 객체 종류에 구애받지 않는 일반적인 복원 능력을 갖추고, 포즈 추정 모듈이 카메라와 객체의 상대적 위치를 기하학적으로 해석하기 때문이다.
실험 결과는 두 가지 측면에서 강점을 보여준다. 첫째, 실내 데이터셋(예: ScanNet, Matterport3D)에서 기존 최첨단 방법 대비 정량적 지표(예: PSNR, SSIM, Chamfer Distance)가 모두 향상되었다. 둘째, 합성 데이터와 실제 촬영 데이터 간의 도메인 격차를 최소화하는 일반화 능력이 입증되었다. 이는 디오클루전 복원 단계에서 도메인‑불변 특징을 학습하고, 포즈 추정 단계에서 물리 기반 제약을 적용한 덕분으로 해석할 수 있다.
하지만 몇 가지 한계도 존재한다. 첫째, 매우 복잡한 반사면이나 투명 물체에 대한 디오클루전 복원은 아직 불안정하다. 둘째, 현재 구현은 GPU 메모리 요구량이 커서 고해…